- 下载完数据集后,需要将Makefile中的数据集路径替换成你自己的路径
- 对于stylegan需要提前运行
make resource/image产生不同分辨率的图片
使用比较简单的GAN结构
- Generator: 4个 (Linear+BatchNorm1d+LeakyReLU) + Linear + Tanh
- Discriminator: 2个(Linear+LeakyReLU) + Linear + Sigmoid
- Loss: BCELoss
make image/gan生成结果位于image/gan只能看出是模糊的符号,如下图

Reference:
LSGAN的结构参考了jittor lsgan教程,其中的结构如下图
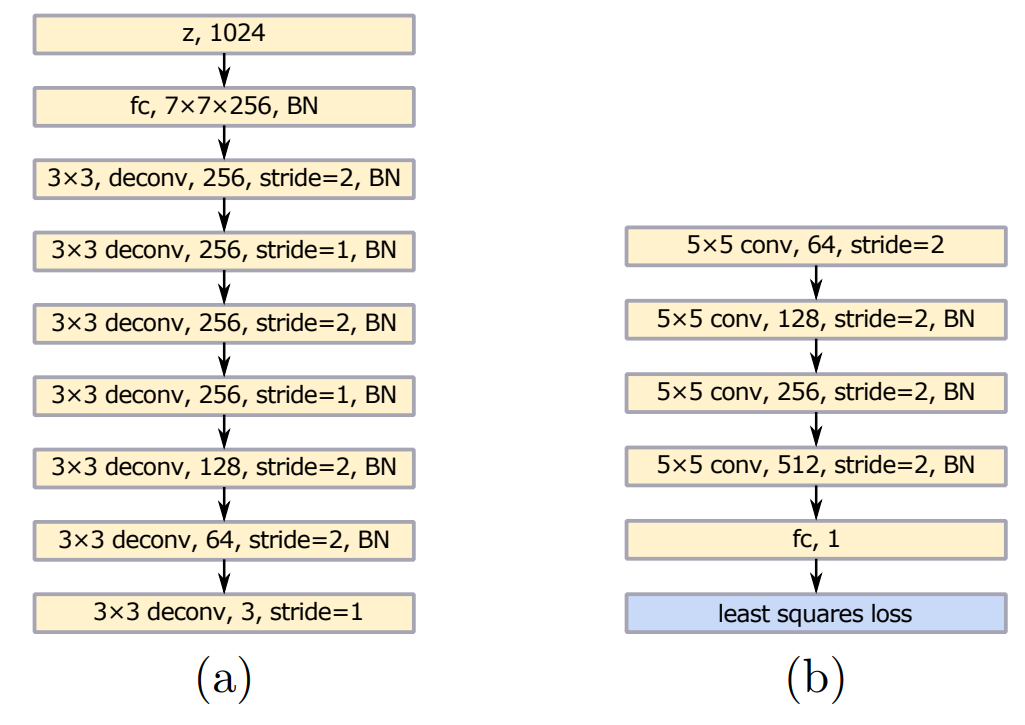
- Loss: 最小平方差(Least Sqaure)
这个我训练了两次,第一次make image/lsgan/0,模型文件位于image/lsgan/0/D.pkl和image/lsgan/0/G.pkl,之后make image/lsgan/1会自动加载前面的模型文件进行训练。
生成结果可以看出是符号,但是和字符差距较大,如下图

-
upsample模块
We replace the nearest-neighbor up/downsampling in both networks with bilinear sampling, which we implement by lowpass filtering the activations with a separable 2nd order binomial filter after each upsampling layer and before each downsampling layer.
使用bilinear sampleing和filter;每一层后面跟随smooth(实现上为
blur模块) -
为了保证Generator与Discriminator之间的良性竞争,ProGAN指出需要使得各个卷积层以相似的速度进行学习。为了达到equlized learnig rate,ProGAN采用了与He initialization相似的方法,也就是将每个层的权重乘以其权重参数量。而且不仅仅是初始化权重时这么做,在训练过程的每次forwarding时都进行此操作。
$$W=W_{orig}\times \sqrt{\frac{2}{fan_in}}$$ -
隐空间插值
-
loss函数使用jittor的step,隐含先对梯度置零,然后求导,但是和源代码稍有差异,源代码是对每部分的loss_i求梯度,然后加在一起。
#前面产生了不同的分辨率图片后,可以运行
make image/stylegan
#产生图片
make image/style/generate训练30000次后的生成结果如下图,其实也看不出符号的样子,虽然训练了很多次,反复训练6次,前5次10000次迭代,最后一次30000次迭代。可能是代码有问题,但是比对并没有发现是哪里出了错误,找不到bug放弃了。模型文件为580M左右,放置在清华云盘,可以下载到image/stylegan/checkpoint/010000.model进行使用。

-
A Style-Based Generator Architecture for Generative Adversarial Networkshttps://arxiv.org/abs/1812.04948