





Phoenix provides MLOps and LLMOps insights at lightning speed with zero-config observability. Phoenix provides a notebook-first experience for monitoring your models and LLM Applications by providing:
- LLM Traces - Trace through the execution of your LLM Application to understand the internals of your LLM Application and to troubleshoot problems related to things like retrieval and tool execution.
- LLM Evals - Leverage the power of large language models to evaluate your generative model or application's relevance, toxicity, and more.
- Embedding Analysis - Explore embedding point-clouds and identify clusters of high drift and performance degradation.
- RAG Analysis - Visualize your generative application's search and retrieval process to identify problems and improve your RAG pipeline.
- Structured Data Analysis - Statistically analyze your structured data by performing A/B analysis, temporal drift analysis, and more.
Table of Contents
- Installation
- LLM Traces
- LLM Evals
- Embedding Analysis
- Retrieval-Augmented Generation Analysis
- Structured Data Analysis
- Deploying Phoenix
- Breaking Changes
- Community
- Thanks
- Copyright, Patent, and License
Install Phoenix via pip or or conda as well as any of its subpackages.
pip install arize-phoenix[evals]Note
The above will install Phoenix and its evals subpackage. To just install phoenix's evaluation package, you can run pip install arize-phoenix-evals instead.
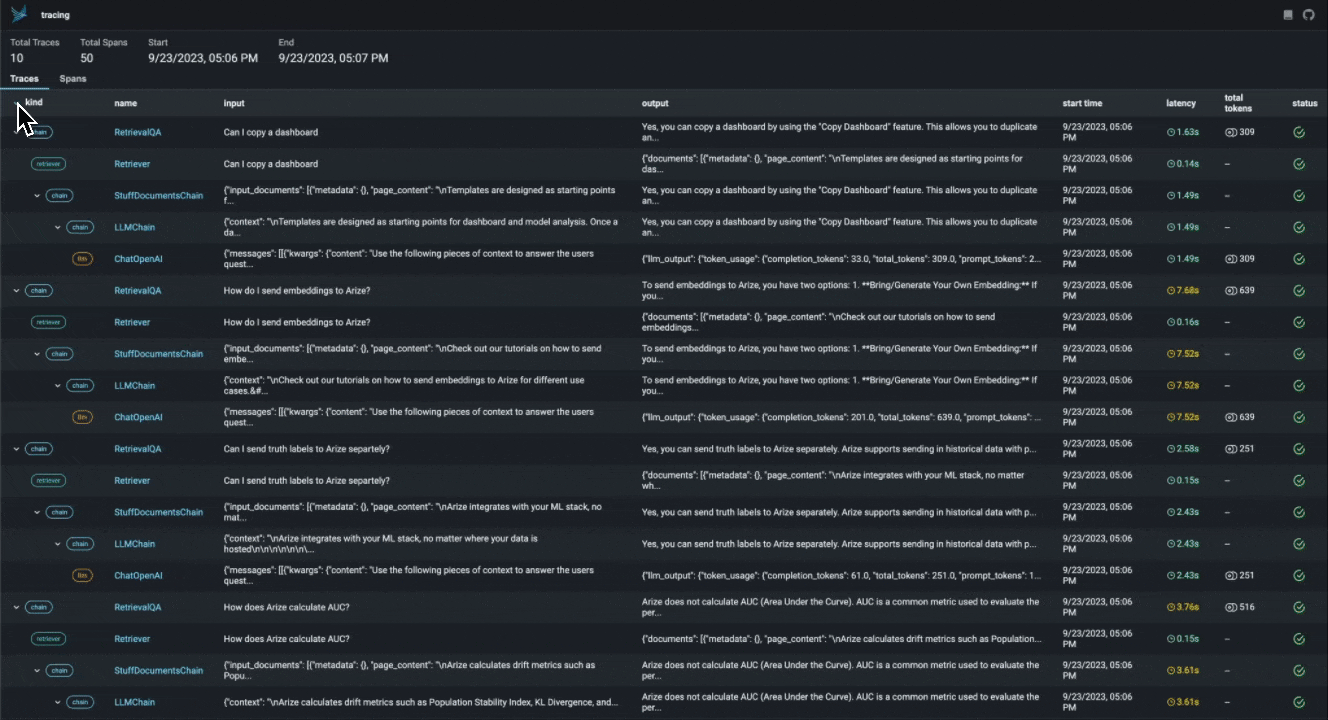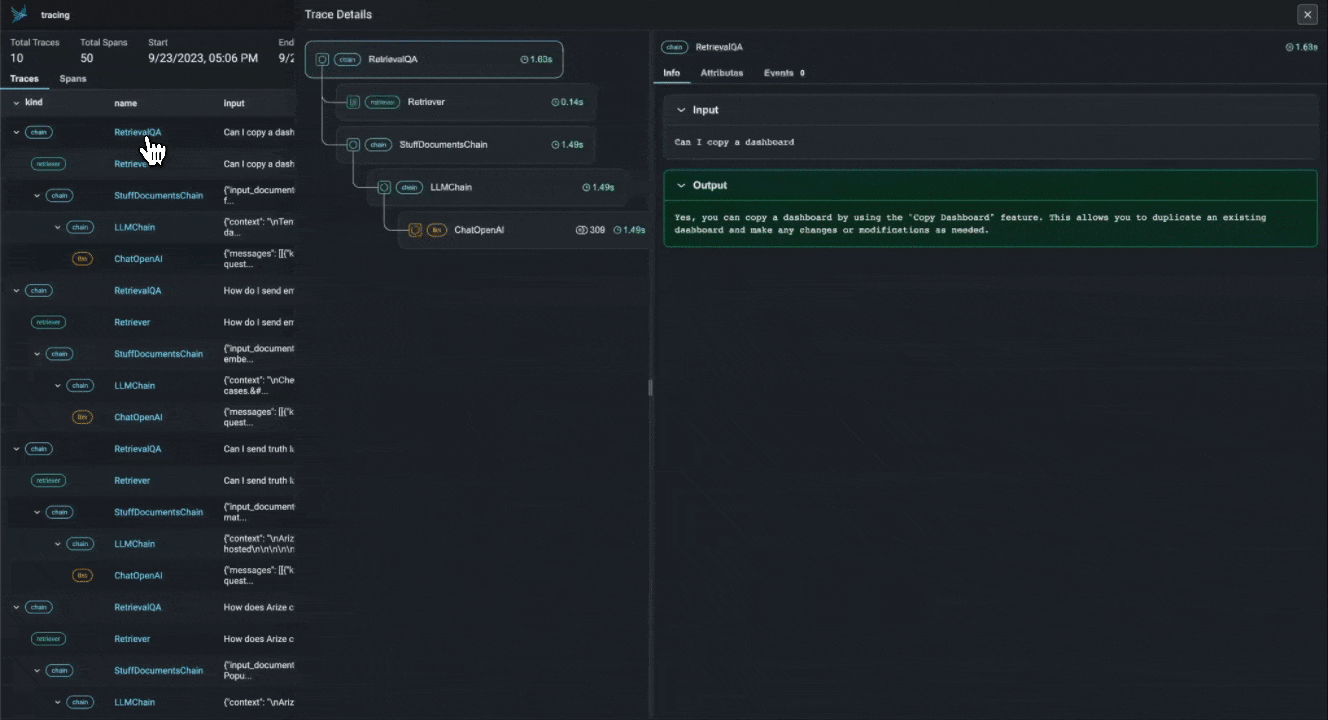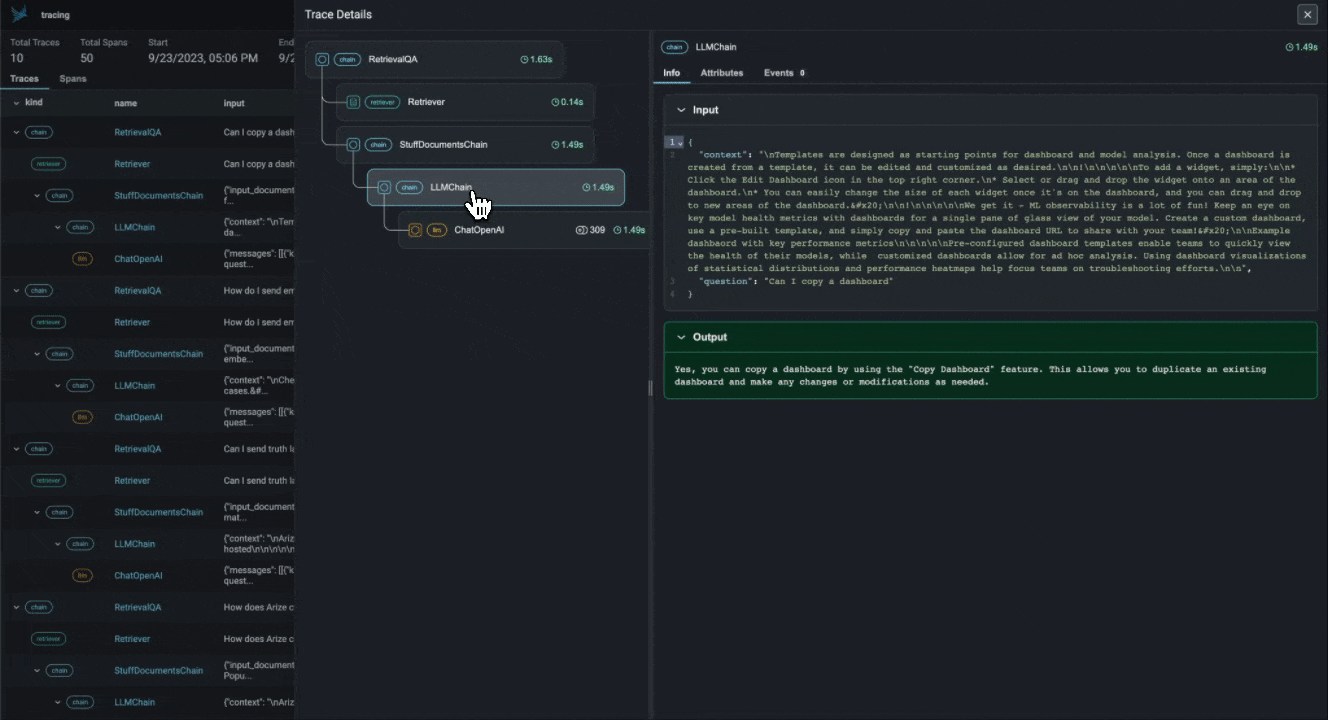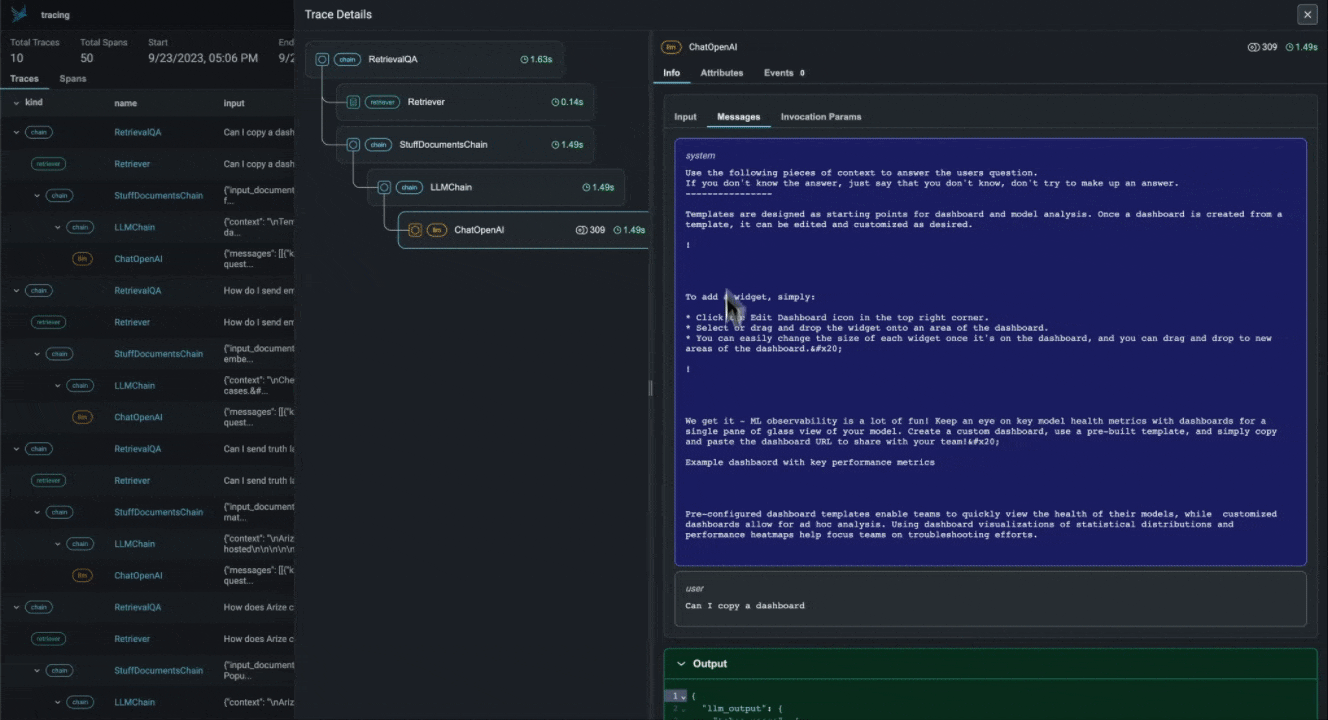
With the advent of powerful LLMs, it is now possible to build LLM Applications that can perform complex tasks like summarization, translation, question and answering, and more. However, these applications are often difficult to debug and troubleshoot as they have an extensive surface area: search and retrieval via vector stores, embedding generation, usage of external tools and so on. Phoenix provides a tracing framework that allows you to trace through the execution of your LLM Application hierarchically. This allows you to understand the internals of your LLM Application and to troubleshoot the complex components of your applicaition. Phoenix is built on top of the OpenInference tracing standard and uses it to trace, export, and collect critical information about your LLM Application in the form of spans. For more details on the OpenInference tracing standard, see the OpenInference Specification


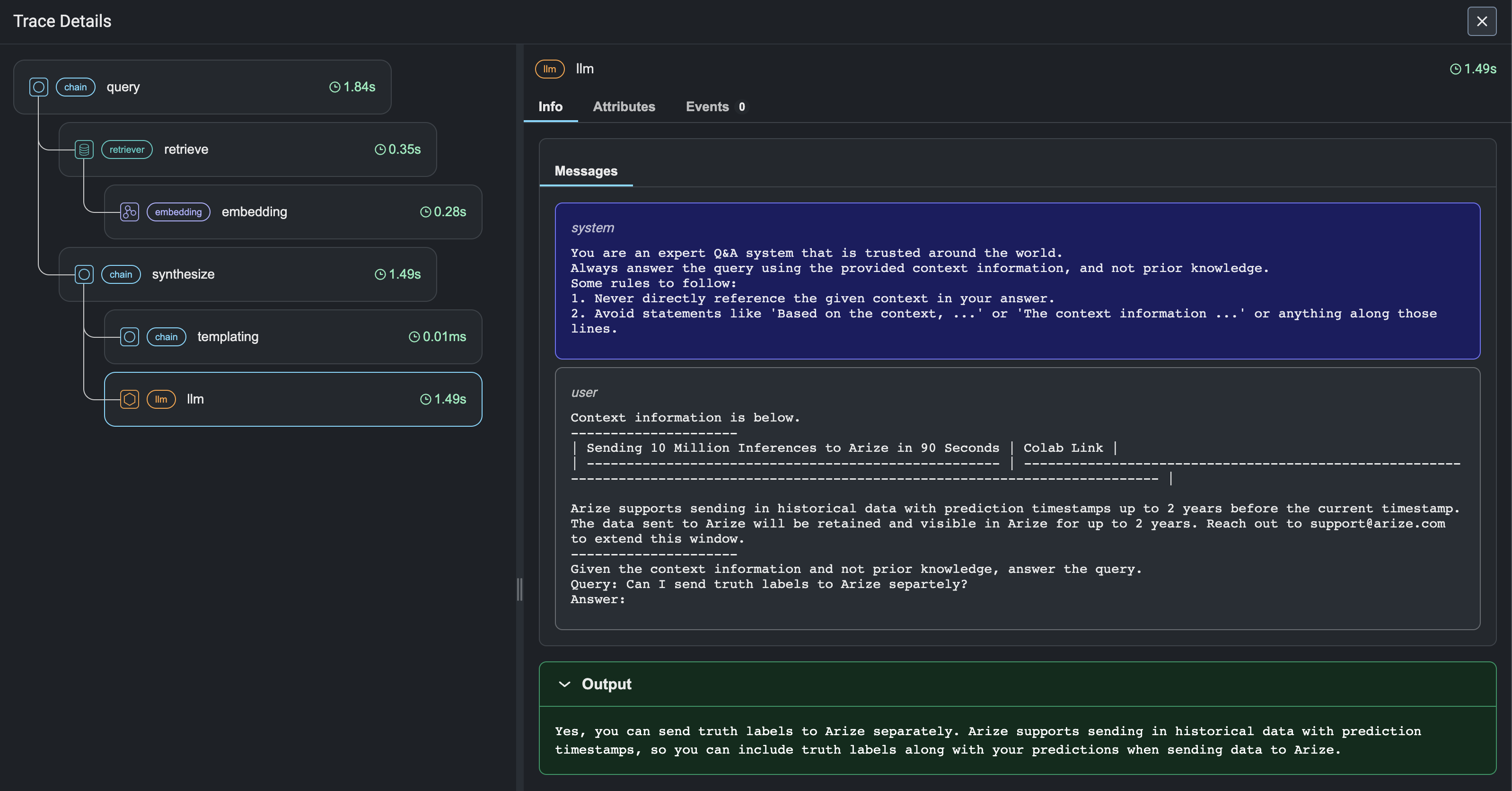
To extract traces from your LlamaIndex application, you will have to add Phoenix's OpenInferenceTraceCallback to your LlamaIndex application. A callback (in this case an OpenInference Tracer) is a class that automatically accumulates spans that trac your application as it executes. The OpenInference Tracer is a tracer that is specifically designed to work with Phoenix and by default exports the traces to a locally running phoenix server.
# Install phoenix as well as llama_index and your LLM of choice
pip install "arize-phoenix[evals]" "openai>=1" "llama-index>=0.10.3" "openinference-instrumentation-llama-index>=1.0.0" "llama-index-callbacks-arize-phoenix>=0.1.2" llama-index-llms-openaiLaunch Phoenix in a notebook and view the traces of your LlamaIndex application in the Phoenix UI.
import os
import phoenix as px
from llama_index.core import (
Settings,
VectorStoreIndex,
SimpleDirectoryReader,
set_global_handler,
)
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# To view traces in Phoenix, you will first have to start a Phoenix server. You can do this by running the following:
session = px.launch_app()
# Once you have started a Phoenix server, you can start your LlamaIndex application and configure it to send traces to Phoenix. To do this, you will have to add configure Phoenix as the global handler
set_global_handler("arize_phoenix")
# LlamaIndex application initialization may vary
# depending on your application
Settings.llm = OpenAI(model="gpt-4-turbo-preview")
Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# Load your data and create an index. Note you usually want to store your index in a persistent store like a database or the file system
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
# Query your LlamaIndex application
query_engine.query("What is the meaning of life?")
query_engine.query("Why did the cow jump over the moon?")
# View the traces in the Phoenix UI
px.active_session().url
To extract traces from your LangChain application, you will have to add Phoenix's OpenInference Tracer to your LangChain application. A tracer is a class that automatically accumulates traces as your application executes. The OpenInference Tracer is a tracer that is specifically designed to work with Phoenix and by default exports the traces to a locally running phoenix server.
# Install phoenix as well as langchain and your LLM of choice
pip install arize-phoenix langchain openai
Launch Phoenix in a notebook and view the traces of your LangChain application in the Phoenix UI.
import phoenix as px
import pandas as pd
import numpy as np
# Launch phoenix
session = px.launch_app()
# Once you have started a Phoenix server, you can start your LangChain application with the OpenInferenceTracer as a callback. To do this, you will have to instrument your LangChain application with the tracer:
from phoenix.trace.langchain import LangChainInstrumentor
# By default, the traces will be exported to the locally running Phoenix server.
LangChainInstrumentor().instrument()
# Initialize your LangChain application
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.retrievers import KNNRetriever
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
documents_df = pd.read_parquet(
"http://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/llm/context-retrieval/langchain-pinecone/database.parquet"
)
knn_retriever = KNNRetriever(
index=np.stack(documents_df["text_vector"]),
texts=documents_df["text"].tolist(),
embeddings=OpenAIEmbeddings(),
)
chain_type = "stuff" # stuff, refine, map_reduce, and map_rerank
chat_model_name = "gpt-3.5-turbo"
llm = ChatOpenAI(model_name=chat_model_name)
chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type=chain_type,
retriever=knn_retriever,
)
# Instrument the execution of the runs with the tracer. By default the tracer uses an HTTPExporter
query = "What is euclidean distance?"
response = chain.run(query, callbacks=[tracer])
# By adding the tracer to the callbacks of LangChain, we've created a one-way data connection between your LLM application and Phoenix.
# To view the traces in Phoenix, simply open the UI in your browser.
session.url
Phoenix provides tooling to evaluate LLM applications, including tools to determine the relevance or irrelevance of documents retrieved by retrieval-augmented generation (RAG) application, whether or not the response is toxic, and much more.
Phoenix's approach to LLM evals is notable for the following reasons:
- Includes pre-tested templates and convenience functions for a set of common Eval “tasks”
- Data science rigor applied to the testing of model and template combinations
- Designed to run as fast as possible on batches of data
- Includes benchmark datasets and tests for each eval function
Here is an example of running the RAG relevance eval on a dataset of Wikipedia questions and answers:
# Install phoenix as well as the evals subpackage
pip install 'arize-phoenix[evals]' ipython matplotlib openai pycm scikit-learnfrom phoenix.evals import (
RAG_RELEVANCY_PROMPT_TEMPLATE,
RAG_RELEVANCY_PROMPT_RAILS_MAP,
OpenAIModel,
download_benchmark_dataset,
llm_classify,
)
from sklearn.metrics import precision_recall_fscore_support, confusion_matrix, ConfusionMatrixDisplay
# Download the benchmark golden dataset
df = download_benchmark_dataset(
task="binary-relevance-classification", dataset_name="wiki_qa-train"
)
# Sample and re-name the columns to match the template
df = df.sample(100)
df = df.rename(
columns={
"query_text": "input",
"document_text": "reference",
},
)
model = OpenAIModel(
model="gpt-4",
temperature=0.0,
)
rails =list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values())
df[["eval_relevance"]] = llm_classify(df, model, RAG_RELEVANCY_PROMPT_TEMPLATE, rails)
#Golden dataset has True/False map to -> "irrelevant" / "relevant"
#we can then scikit compare to output of template - same format
y_true = df["relevant"].map({True: "relevant", False: "irrelevant"})
y_pred = df["eval_relevance"]
# Compute Per-Class Precision, Recall, F1 Score, Support
precision, recall, f1, support = precision_recall_fscore_support(y_true, y_pred)To learn more about LLM Evals, see the Evals documentation.
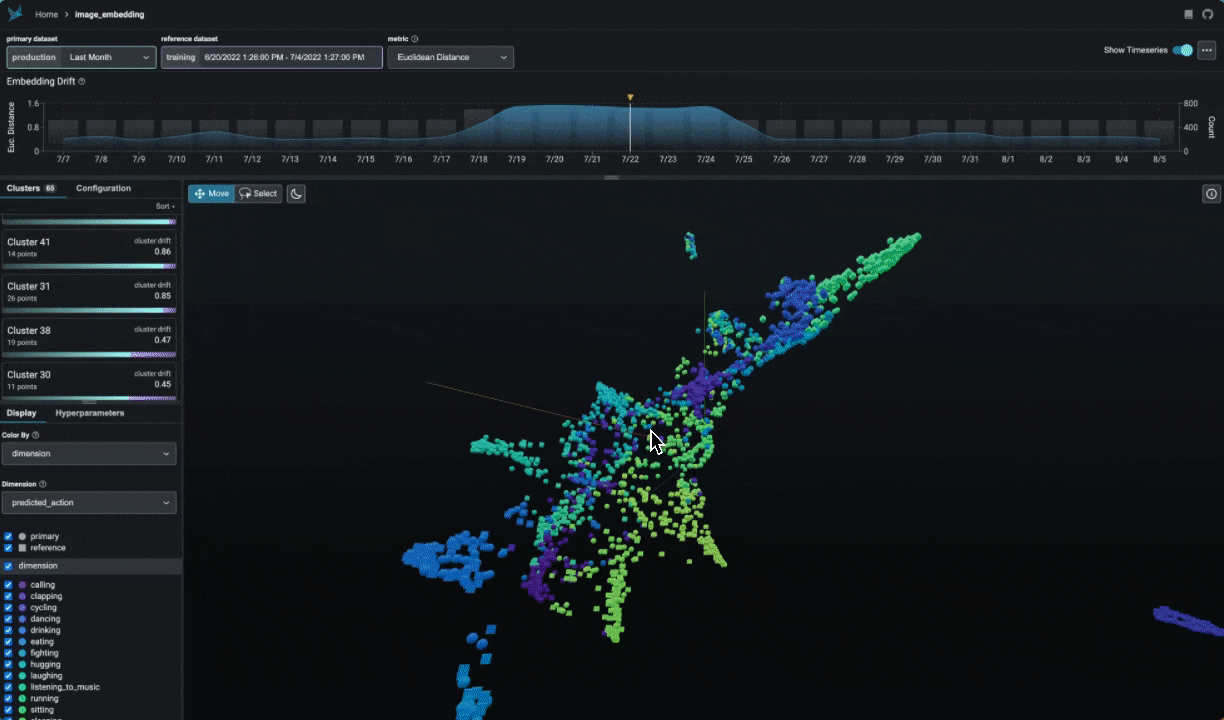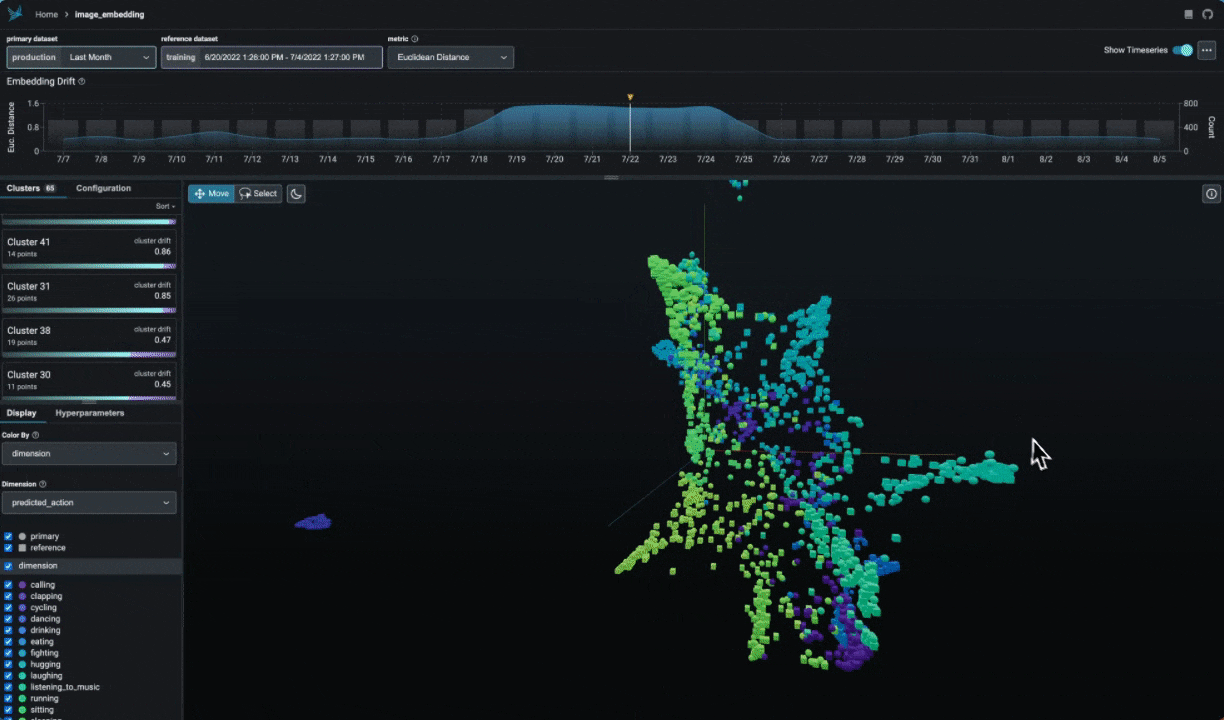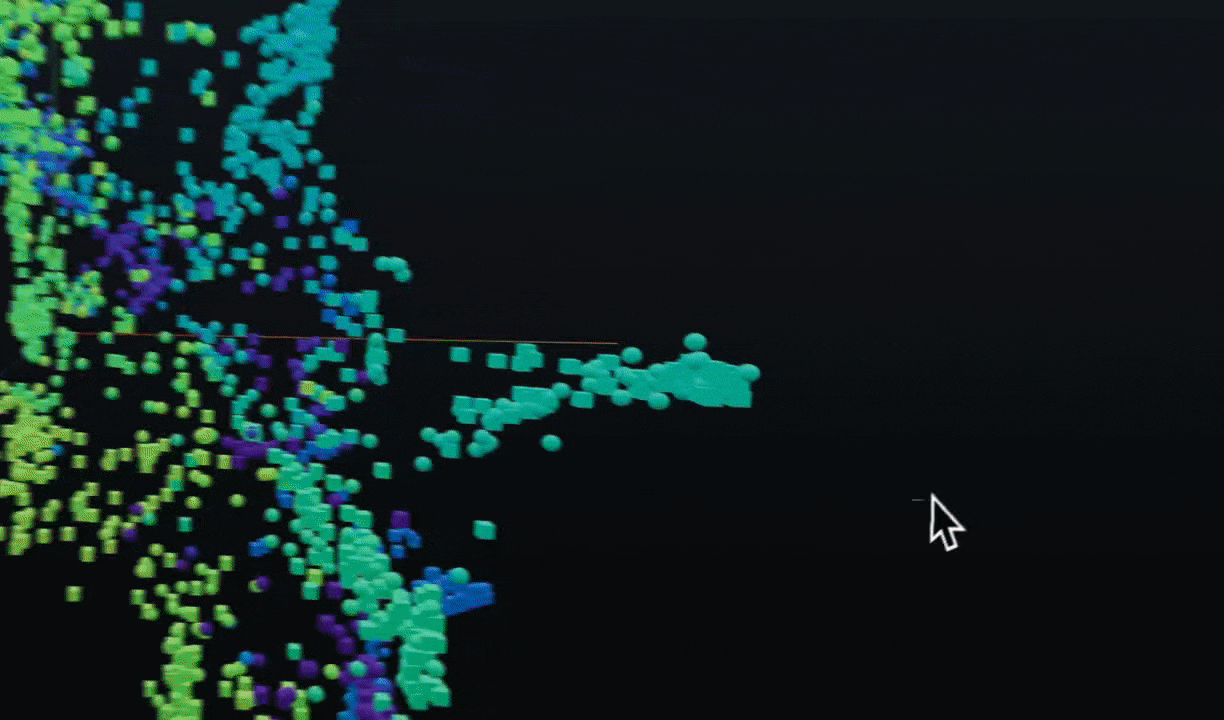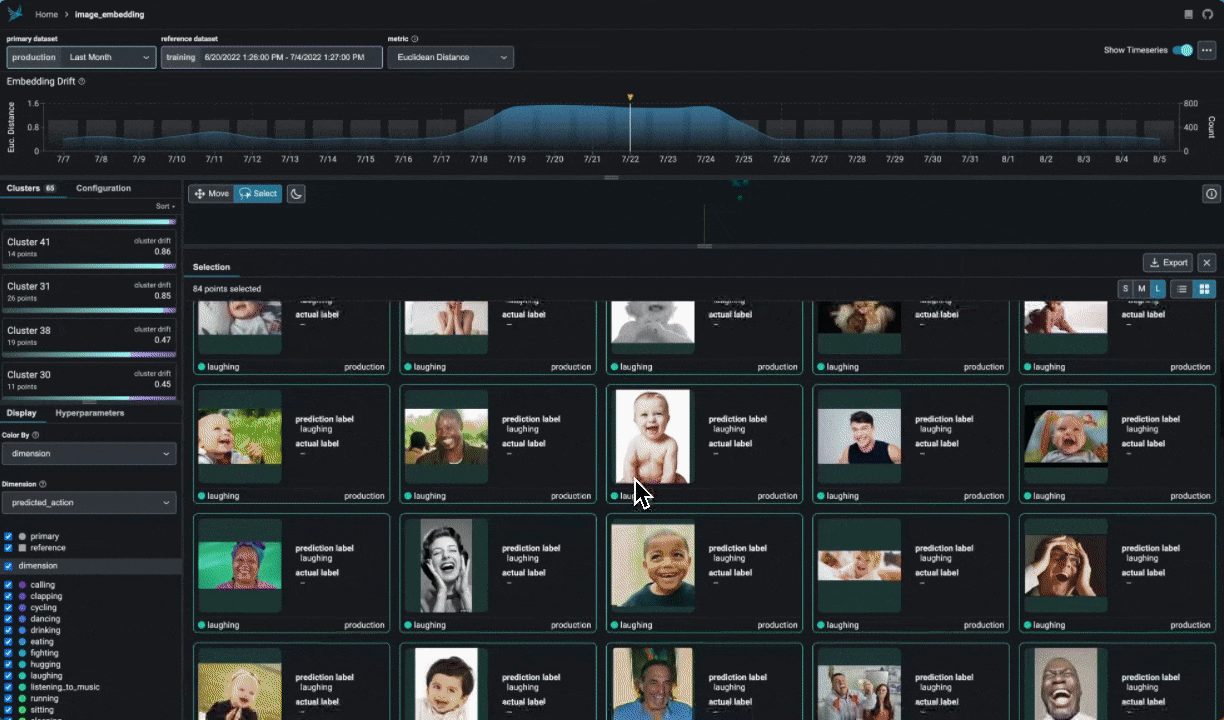
Explore UMAP point-clouds at times of high drift and performance degredation and identify clusters of problematic data.
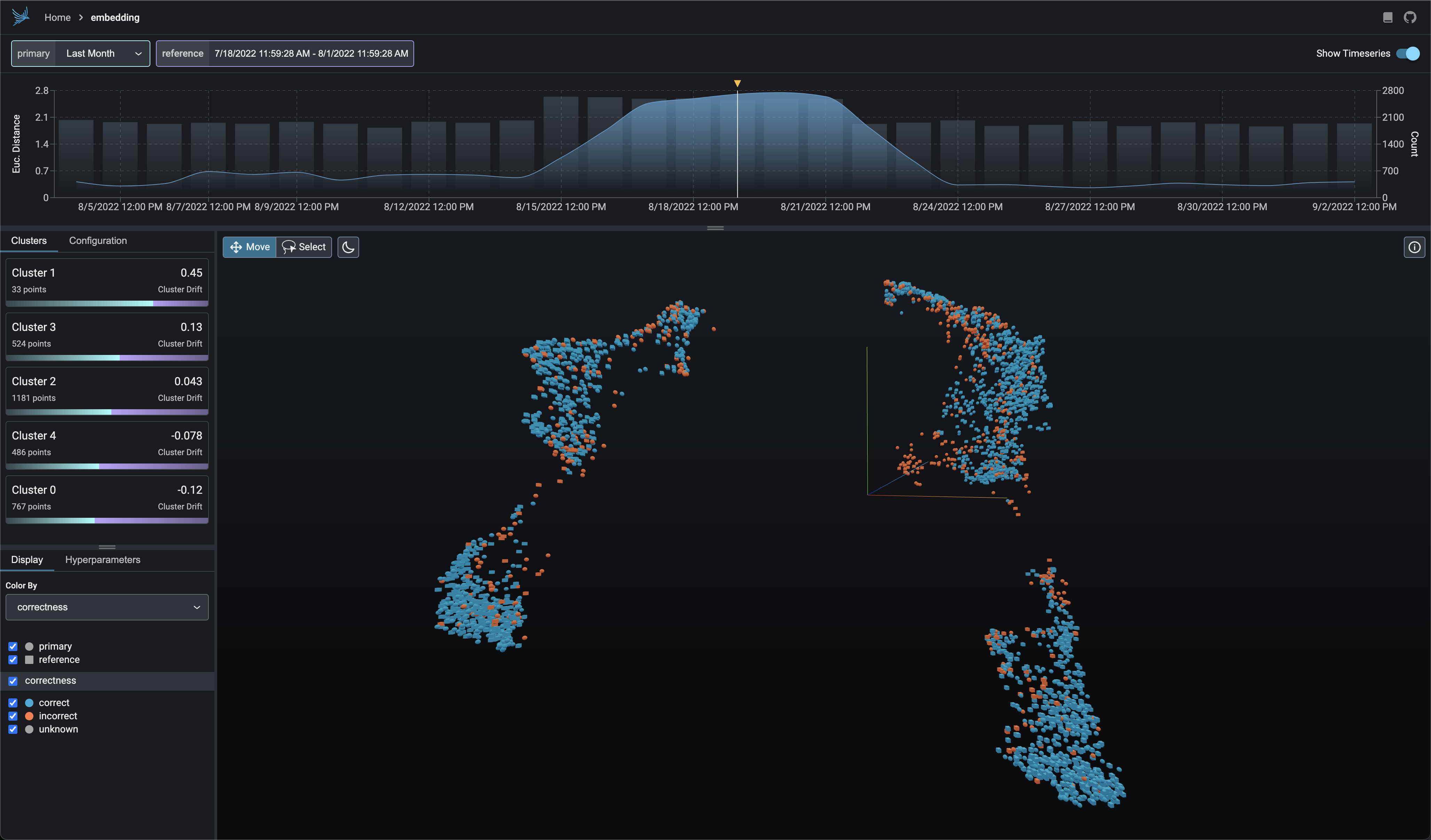
Embedding analysis is critical for understanding the behavior of you NLP, CV, and LLM Apps that use embeddings. Phoenix provides an A/B testing framework to help you understand how your embeddings are changing over time and how they are changing between different versions of your model (prod vs train, champion vs challenger).
# Import libraries.
from dataclasses import replace
import pandas as pd
import phoenix as px
# Download curated datasets and load them into pandas DataFrames.
train_df = pd.read_parquet(
"https://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/cv/human-actions/human_actions_training.parquet"
)
prod_df = pd.read_parquet(
"https://storage.googleapis.com/arize-assets/phoenix/datasets/unstructured/cv/human-actions/human_actions_production.parquet"
)
# Define schemas that tell Phoenix which columns of your DataFrames correspond to features, predictions, actuals (i.e., ground truth), embeddings, etc.
train_schema = px.Schema(
prediction_id_column_name="prediction_id",
timestamp_column_name="prediction_ts",
prediction_label_column_name="predicted_action",
actual_label_column_name="actual_action",
embedding_feature_column_names={
"image_embedding": px.EmbeddingColumnNames(
vector_column_name="image_vector",
link_to_data_column_name="url",
),
},
)
prod_schema = replace(train_schema, actual_label_column_name=None)
# Define your production and training datasets.
prod_ds = px.Dataset(prod_df, prod_schema)
train_ds = px.Dataset(train_df, train_schema)
# Launch Phoenix.
session = px.launch_app(prod_ds, train_ds)
# View the Phoenix UI in the browser
session.urlColor your UMAP point-clouds by your model's dimensions, drift, and performance to identify problematic cohorts.
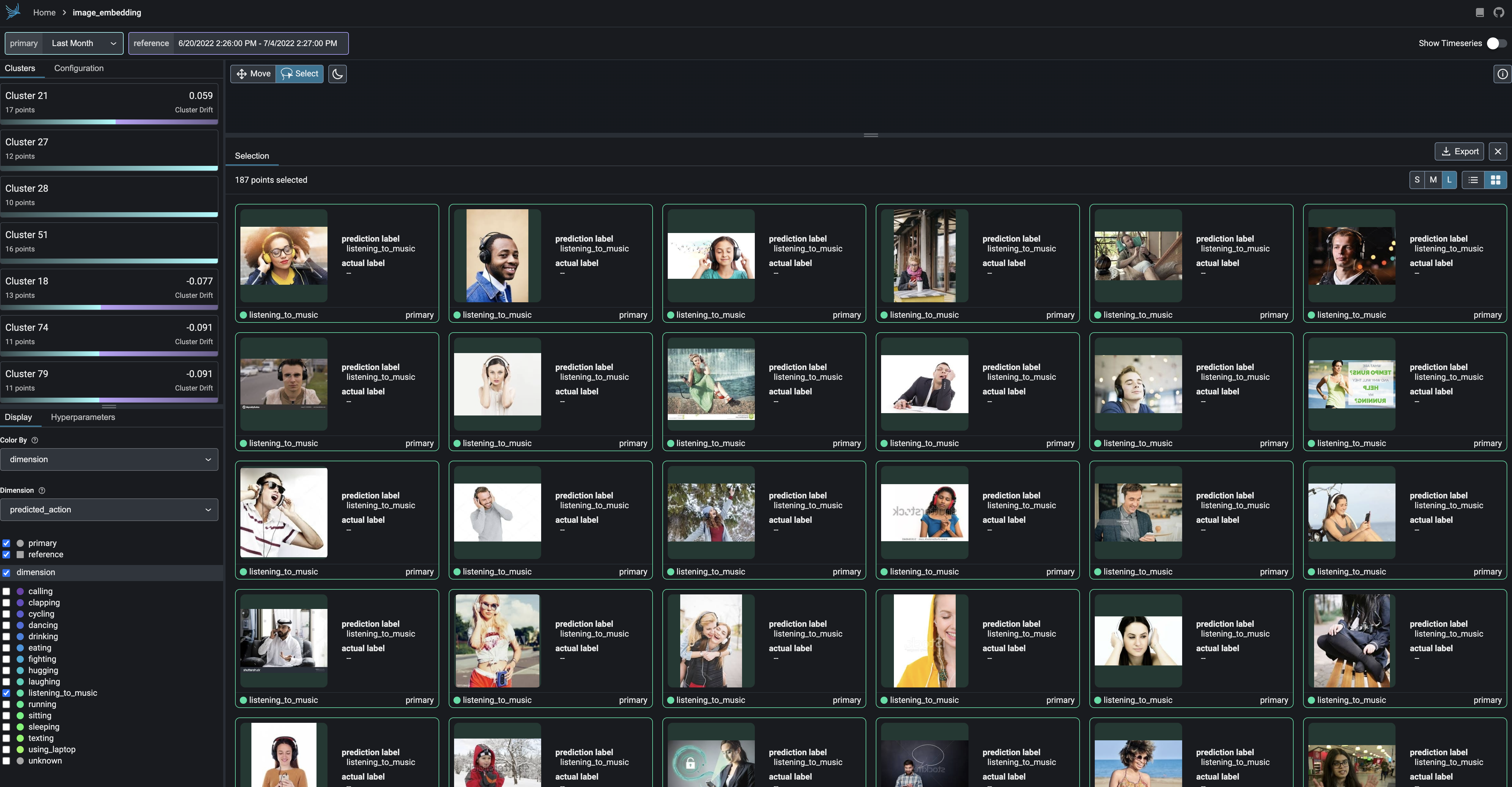
Break-apart your data into clusters of high drift or bad performance using HDBSCAN
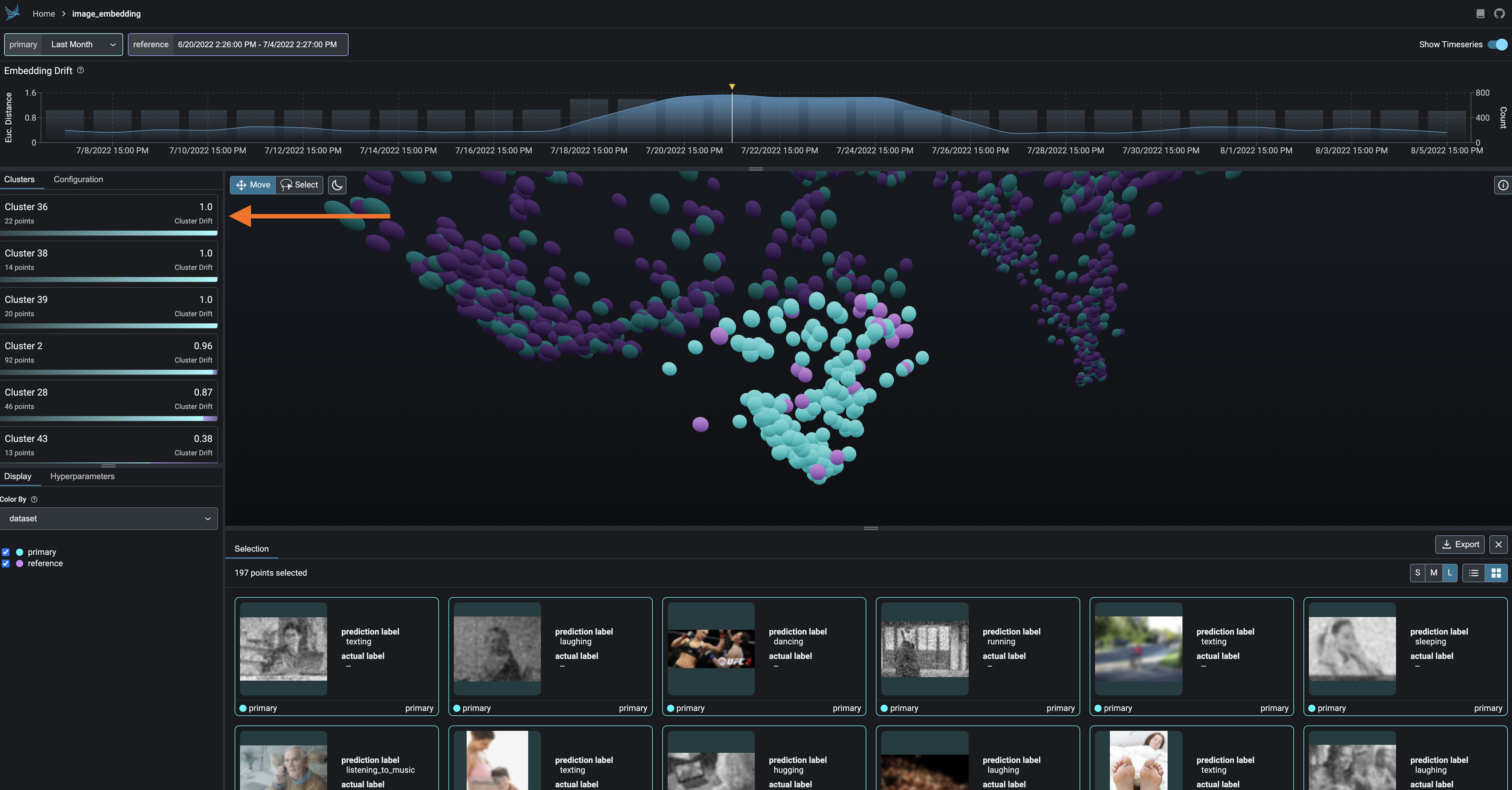
Export your clusters to parquet files or dataframes for further analysis and fine-tuning.

Search and retrieval is a critical component of many LLM Applications as it allows you to extend the LLM's capabilities to encompass knowledge about private data. This process is known as RAG (retrieval-augmented generation) and often times a vector store is leveraged to store chunks of documents encoded as embeddings so that they can be retrieved at inference time.
To help you better understand your RAG application, Phoenix allows you to upload a corpus of your knowledge base along with your LLM application's inferences to help you troubleshoot hard to find bugs with retrieval.
Phoenix provides a suite of tools for analyzing structured data. These tools allow you to perform A/B analysis, temporal drift analysis, and more.
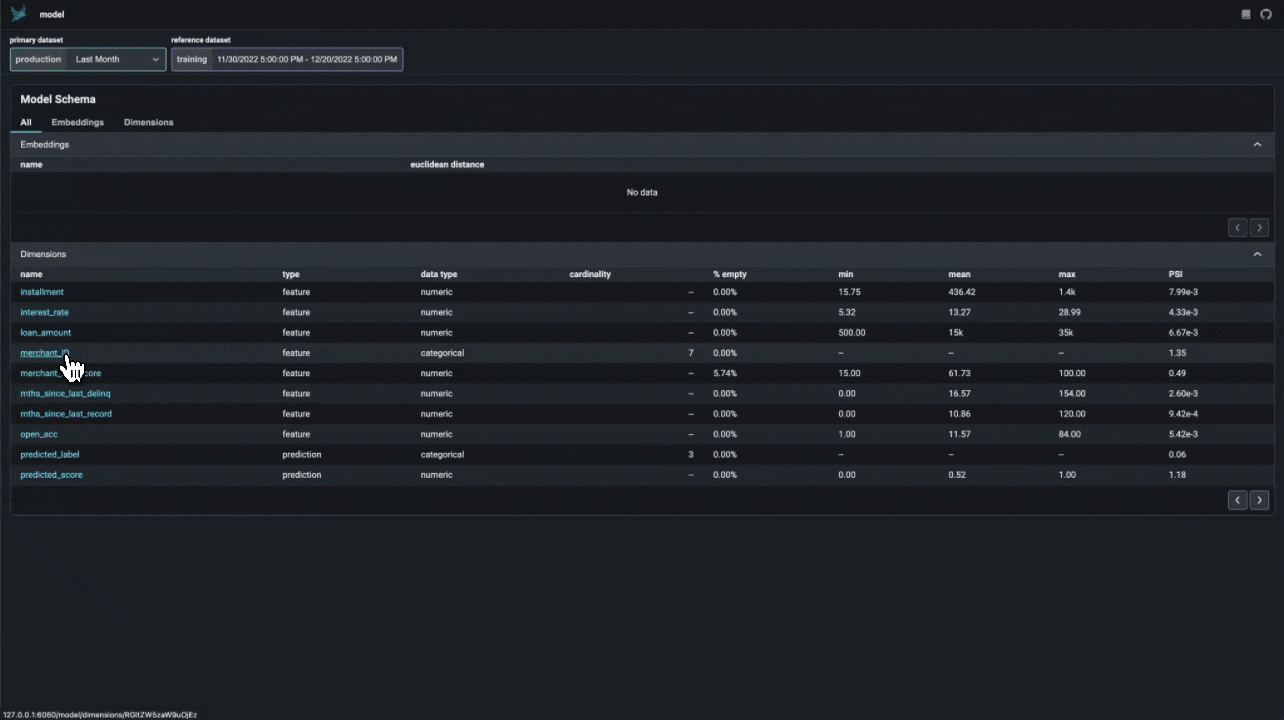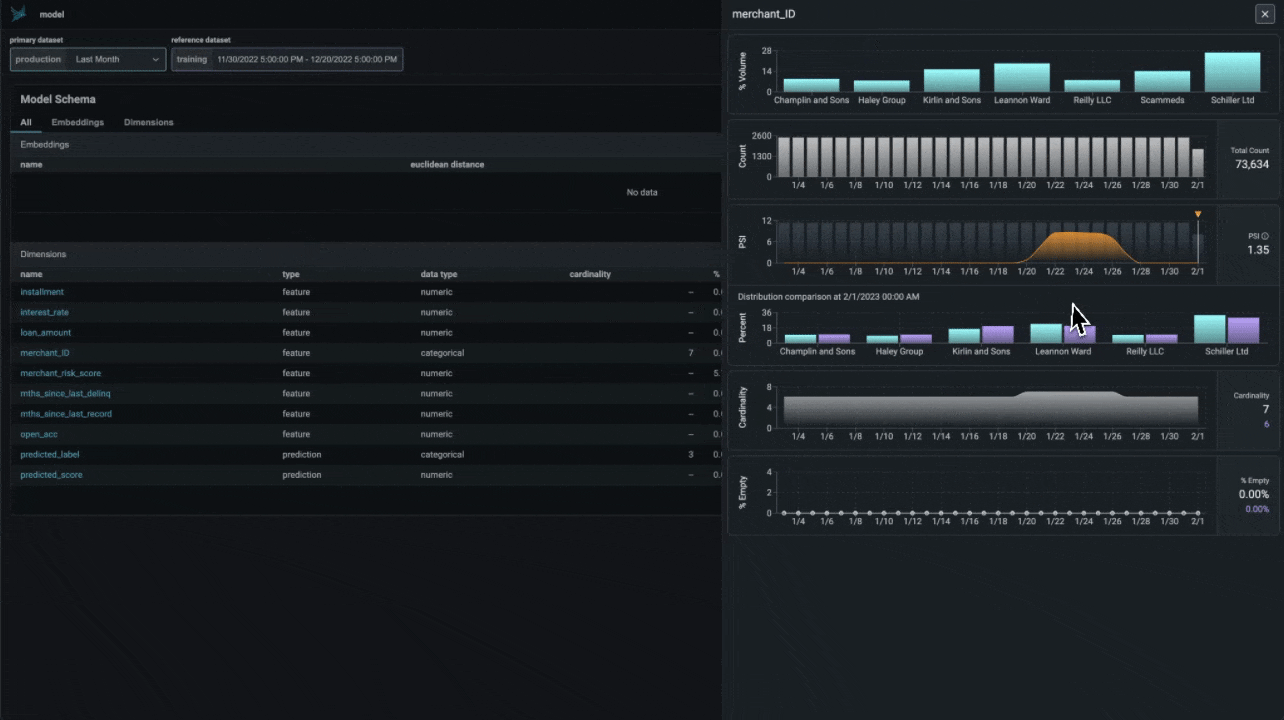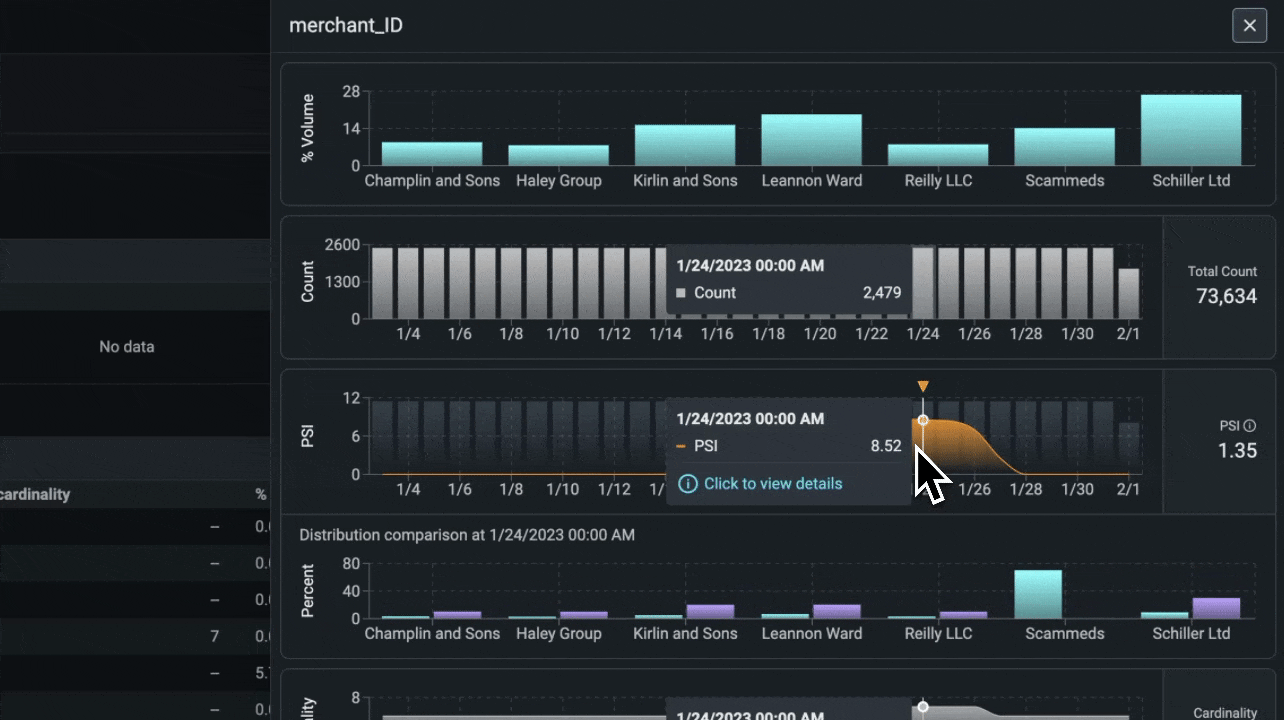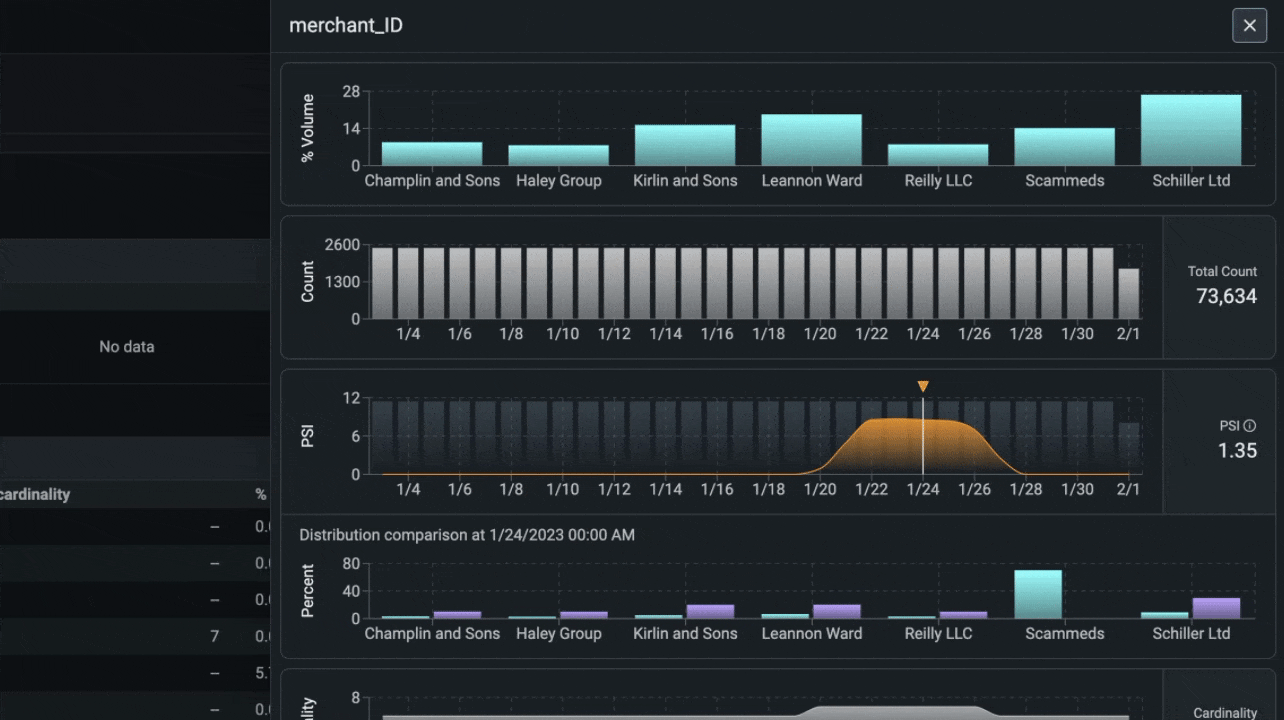
import pandas as pd
import phoenix as px
# Perform A/B analysis on your training and production datasets
train_df = pd.read_parquet(
"http://storage.googleapis.com/arize-assets/phoenix/datasets/structured/credit-card-fraud/credit_card_fraud_train.parquet",
)
prod_df = pd.read_parquet(
"http://storage.googleapis.com/arize-assets/phoenix/datasets/structured/credit-card-fraud/credit_card_fraud_production.parquet",
)
# Describe the data for analysis
schema = px.Schema(
prediction_id_column_name="prediction_id",
prediction_label_column_name="predicted_label",
prediction_score_column_name="predicted_score",
actual_label_column_name="actual_label",
timestamp_column_name="prediction_timestamp",
feature_column_names=feature_column_names,
tag_column_names=["age"],
)
# Define your production and training datasets.
prod_ds = px.Dataset(dataframe=prod_df, schema=schema, name="production")
train_ds = px.Dataset(dataframe=train_df, schema=schema, name="training")
# Launch Phoenix for analysis
session = px.launch_app(primary=prod_ds, reference=train_ds)

Phoenix's notebook-first approach to observability makes it a great tool to utilize during experimentation and pre-production. However at some point you are going to want to ship your application to production and continue to monitor your application as it runs. Phoenix is made up of two components that can be deployed independently:
- Trace Instrumentation: These are a set of plugins that can be added to your application's startup process. These plugins (known as instrumentations) automatically collect spans for your application and export them for collection and visualization. For phoenix, all the instrumentors are managed via a single repository called OpenInference
- Trace Collector: The Phoenix server acts as a trace collector and application that helps you troubleshoot your application in real time. You can pull the latest images of Phoenix from the Docker Hub
In order to run Phoenix tracing in production, you will have to follow these following steps:
- Setup a Server: your LLM application to run on a server (examples)
- Instrument: Add OpenInference Instrumentation to your server
- Observe: Run the Phoenix server as a side-car or a standalone instance and point your tracing instrumentation to the phoenix server
For more information on deploying Phoenix, see the Phoenix Deployment Guide.
see the migration guide for a list of breaking changes.
Join our community to connect with thousands of machine learning practitioners and ML observability enthusiasts.
- 🌍 Join our Slack community.
- 💡 Ask questions and provide feedback in the #phoenix-support channel.
- 🌟 Leave a star on our GitHub.
- 🐞 Report bugs with GitHub Issues.
- 🐣 Follow us on twitter.
- 💌️ Sign up for our mailing list.
- 🗺️ Check out our roadmap to see where we're heading next.
- 🎓 Learn the fundamentals of ML observability with our introductory and advanced courses.
- UMAP For unlocking the ability to visualize and reason about embeddings
- HDBSCAN For providing a clustering algorithm to aid in the discovery of drift and performance degradation
Copyright 2023 Arize AI, Inc. All Rights Reserved.
Portions of this code are patent protected by one or more U.S. Patents. See IP_NOTICE.
This software is licensed under the terms of the Elastic License 2.0 (ELv2). See LICENSE.