sync2es可以将腾讯云TDSQL中的数据实时同步到Elasticsearch(7.x)。注意,普通mysql服务并不适用。
首先使用mysqldump同步原始数据,再读取CKAFKA中的队列消息实时同步到Elasticsearch中。
实时同步数据流为:TDSQL -> CKAFKA -> sync2es -> Elasticsearch
我们使用了腾讯云的TDSQL,但是腾讯云唯一提供可用的实时导出数据流只有CKAFKA这一个渠道(binlog不可用,因为有多台实例)。于是如果我们想将数据导入到ES或者其他数据源,必须得自己开发中间件,别无他法。
- 进入CKAFKA中,新建一个
topic。如果对于数据同步的准确性要求高,建议设置分区数(partition)为1。 - 进入MariaDB的菜单,找到数据同步模块(别问我为什么TDSQL的数据同步放到了MariaDB里面,),新建同步任务,将数据投递到刚刚创建的
topic中。
- 安装好
mysqldump - 从Release中下载最新版的源码,或者编译好的jar包
- 将config文件夹复制到jar包同目录。
- 将
/config/application-test.yml下的配置文件修改成自己对应的配置文件 - 执行
java -jar sync2es.jar --spring.profiles.active = test运行程序 - 访问
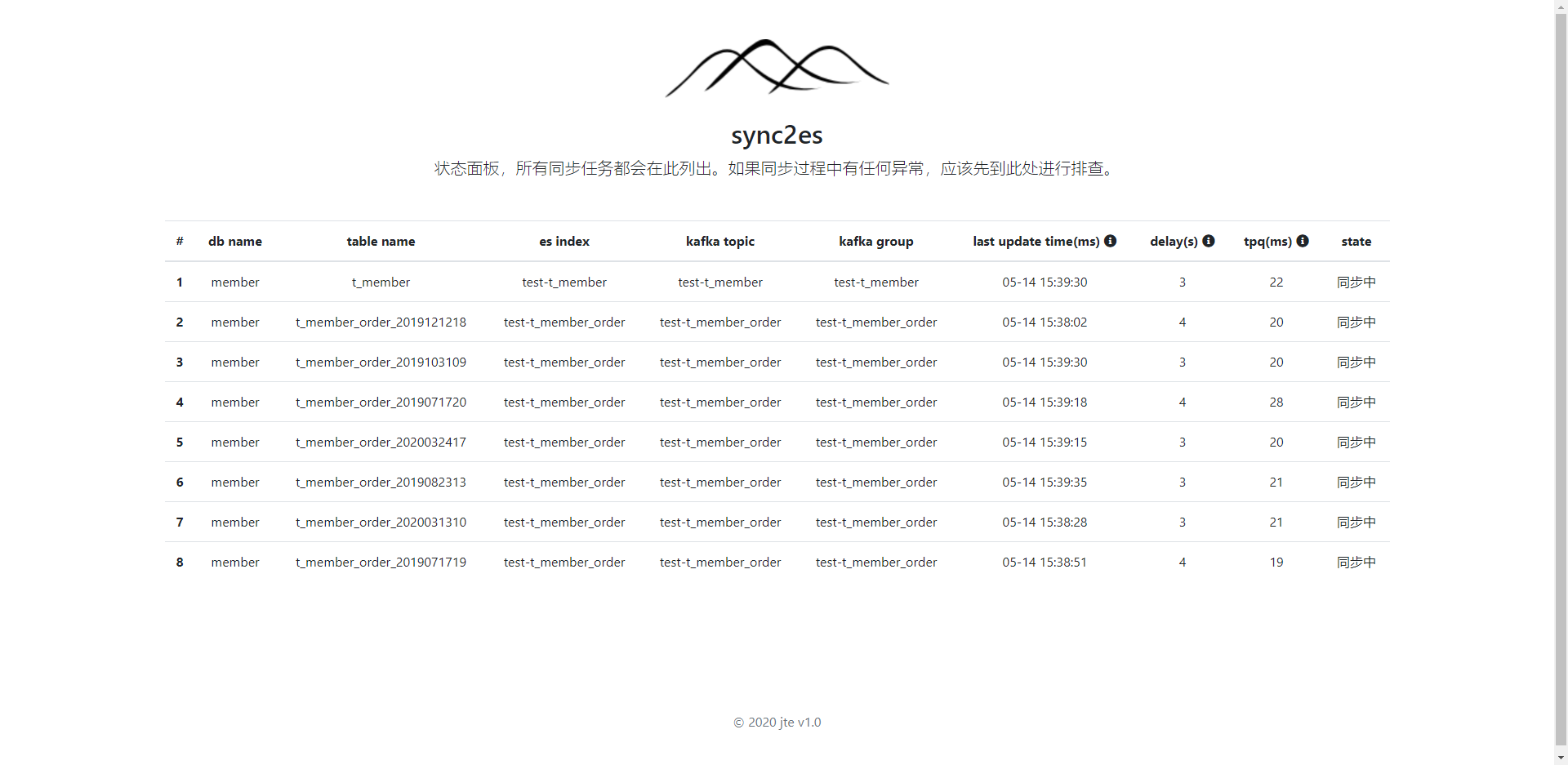
http://127.0.0.1:9070查看同步状态
错误的配置可能会导致项目启动报错。配置文件采用yml格式,不熟悉的同学可以先学习一下。
#【必填】同步目标elasticsearch的基本配置
elasticsearch:
uris: 192.168.10.208:9200
username: elastic
password: changeme
#【必填】腾讯云CKAFKA配置
kafka:
adress: 127.0.0.1:32768
#【必填】tdsql配置,可以配置多个数据库
mysql:
datasources:
-
db-name: jte_pms_member
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&useSSL=false&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&useOldAliasMetadataBehavior=true&allowMultiQueries=true&serverTimezone=Hongkong
username: test
password: test
driver-class-name: com.mysql.cj.jdbc.Driver
#【必填】配置同步到elasticsearch的基本规则
sync2es:
#【选填】mysqldump工具的地址
mysqldump: D:\program\mysql-5.7.25-winx64\bin\mysqldump.exe
#【选填】监控告警(www.wangfengta.com),只有填写了此参数才能开启监控告警,具体配置参考下面章节
alert:
secret: aaaa
app-id: bbbb
delay-template-id: cccc
idle-template-id: dddd
error-template-id: eeee
# 规则比较灵活,可以配置多个
sync-config-list:
-
#【必填】要同步的TDSQL数据库名称
db-name: member
#【必填】要同步的表名,支持正则表达式,多个表名用逗号分隔
sync-tables: "t_member,t_member_order_[0-9]{10}"
#【选填】延迟超过60秒,将会触发告警
max-delay-in-second: 60
#【选填】超过120分钟没接收到同步消息,将会触发告警
max-idle-in-minute: 120
#【选填】告警发生180分钟后,如果未恢复,则再次告警
next-trigger-alert-in-minute: 180
mq:
# 监听的CKAFKA的topic名称
topic-name: test-t_member
#【选填】消费者使用的topicGroup,如果不填写,则随机生成。每次重启本应用都会从kafka的"earliest"处开始读取。
topic-group: local-test-consumer-group
#【选填】此处可以配置TDSQL到elasticsearch的映射规则
rules:
-
# 匹配此rule的表名,支持正则表达式
table: t_member_order_[0-9]{10}
# 自定义es的index名称
index: t_member_order
# 自定义同步到es的字段名称和字段类型(es的类型),字段类型请参考类:com.jte.sync2es.model.es.EsDateType
map: '{"group_code":"groupCode","user_code":",integer"}'
# 字段过滤,多个字段用逗号分隔。如果有值,则只保留这里填写的字段。
field-filter: "user_id,user_name"- 当tdsql的表中存在数据,且es中index不存在或者index中无document时才会dump原始数据同步到es。
- es的index默认命名规则为“数据库名-表名”,es那边的字段名和tdsql保持一致。默认所有同步过去的名称都会转化为小写。
- 一旦同步过程中发生任何错误,该任务会停止继续同步,防止数据错乱。其他正常的任务可继续执行,不影响。
- sync2es会将数据库中的主键当作es中document的主键。碰到复合主键时,多个主键使用“_”符号隔开。
- 在es中的更新和删除操作都是通过es的主键来定位document
- CKAFKA创建topic时,一定要将
max.message.bytes设置为最大值8MB。否则流量高峰时会有TDSQL投递消息到CKAFKA失败的情况发生。 - CKAFKA创建topic时,将
retention.ms也就是“topic维度的消息保留时间”设置到一个合适的值。不然丢了消息也找不回来。不过不能太大,因为硬盘堆积满了之后,ckafa将不再接受生产者新投递的消息。 - 延迟告警的设置最好大于10秒,因为本身就有3-4秒的延迟。
- 建议每个表都单独建立一个同步任务,并且用不同的topic。这样可以隔离故障,降低时同步延迟。
- 目前TDSQL只支持将数据投递到第一个partition,所以做集群部署没有任何意义(如果不理解这句话可以深入学习一下kafka),暂时不支持集群部署。可以向腾讯云提工单,支持界面上配置投递到多个partition。如果腾讯云愿意做更新,我这边也会支持集群部署。
- CKAFKA中每一条msg都对应数据库中一行被修改的记录,这意味着当你一次修改很多行记录时,同步延迟会加大。
- 不同的机器性能不一样,要算每个TOPIC的QPS,可以通过控制面板的tpq参数计算。也就是1000(ms)/tpq=QPS。
因为腾讯云本身对外提供的接口能力不足,导致我们做功能的时候不得不做一些取舍和限制才能保证数据的准确。限制如下:
- 对于正在同步的表,暂不支持删除已有字段。
- 对于正在同步的表,新增字段必须加到表的末尾,千万不能插到表已有字段中间。
- 对于正在同步的表,新增字段暂不支持同步到es端。
- 当TDSQL扩容新增物理节点时,数据同步将会异常。
- 新建同步服务时,填写可以正则表达式。但是在同步过程中,新建分表,即使分表能匹配到正则表达式,也不能加入到同步任务中。
- ckafka最多接受投递任务大小为8MB,但是TDSQL这边有几率一次投递超过50MB。这会导致同步任务中断。
- 表中必须要有主键。(这个限制和腾讯云无关)
对于1、2点的限制原因是腾讯云投递过来的消息并不包含字段名称信息,所以一旦修改表结构,那么投递过来的值将无法和对应的字段匹配上。所以一旦违规操作,将会导致es端数据混乱。
对于第4、5、6点限制,腾讯云反馈已有开发计划,但是不知什么时候会上线。如果已经上线可以提issue告知。
建议大家都去提提工单,让腾讯云加强这方面的功能。
- 如何判断同步成功?
可以通过count来比较记录的数量,也可以用关键指标(如余额、订单金额)“求和”看两端是否一致。
- 如果同步途中要新增字段怎么办?
目前只能重新开一个同步任务,并且使用新的es index。
- 其他版本的es能够使用吗?
目前只测试了7.x版本,其他版本可以自己试一试。
- 同步途中失败了,导致同步停止了该怎么办?
首先确定是否是sync2es的代码问题,如果是解析逻辑有问题,则需要修改bug。如果是es端发生问题,可以重启sync2es重新同步。怕消息有丢失的话,可以到CKAFKA控制台重新设置消费者的位置(可按时间)。如果是同步任务本身有问题,则需要新建同步任务,或工单联系腾讯云。
本项目基于spring boot 2.x,充分利用了spring的生态。非常利于扩展和二次开发。如果感兴趣或者需要对接腾讯云其他数据源,可基于本项目进行扩展。
本项目起源于我们自己 金天鹅 内部的项目需求,所以非常感谢公司的支持。