Speehgraph is a Python module to perform speech graphs analysis used in Automated speech analysis for psychosis evaluation
The easy way to install is using pip, doing:pip install git+https://github.com/facuzeta/speechgraph/
After install...
import speechgraph
some_large_text= "The campaign brought ... I began by making up my mind..."
ngraph = speechgraph.naiveGraph() # create a Naive graph
sgraph = speechgraph.stemGraph() # create a Stem Graph
pgraph = speechgraph.posGraph() # create a Part of Speech Graph
print ngraph.analyzeText(some_large_text)
{'LSC': 3, 'L1': 1, 'number_of_edges': 408, 'degree_average': 3.6106194690265485,
'degree_std': 5.694172814468919, 'LCC': 1, 'PE': 16, 'L2': 12, 'L3': 66}
print sgraph.analyzeText(text)
{'LSC': 3, 'L1': 0, 'number_of_edges': 408, 'degree_average': 3.6756756756756759,
'degree_std': 5.7401104333196953, 'LCC': 1, 'PE': 16, 'L2': 12, 'L3': 66}
print pgraph.analyzeText(text)
{'LSC': 1, 'L1': 20, 'number_of_edges': 422, 'degree_average': 32.46153846153846,
'degree_std': 38.308696310599657, 'LCC': 1, 'PE': 65, 'L2': 1098, 'L3': 77666}
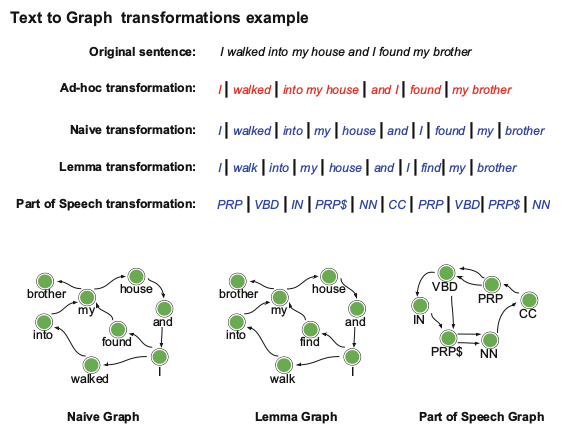
Naive Graph consisted in splitting the text into words without any transformation. A node was created for every distinct word and two nodes are connected by an edge if they correspond to consecutive words.
Stem Grah consisted in splitting plain text using the same procedures as in the Naive Graph, but after word stemming. With this transformation two different words may have the same stem (e.g love, loved and loving have the same stem: love).
Part of Speech Graph consisted in changing the words of the plain text with their Part of Speech tags (category of words or lexical items).