Image recomendation system base on image description using an autoencoder architecture with convolutional neural networks (CNN).
The used architecture was an Autoencoder, we will use it to generate a lower dimension latent vector that corresponds with the image description of a clothe.
Each low dimension representation of an image will be used as its description, the we will compare these descriptors to recommend similar images.
- Autoencoder_Xception.ipynb: Jupyter notebook with the main code used for training the CNNs and plotting the different results.
- GeneracionBinarioDataset.ipynb: Jupyter notebook with the code used for generating the binary of the dataset.
- GenerateImages: Code for loading the saved models and generating graphics.
- Results_XXXdim: Folder with the results of the training for an Autoencoder with a latent vector of XXX dimensions.
Each code Notebook is self explained. To execute the different trainings we used Google Colaboratory with Google Drive for loading the binary file and saving the output plots of each training.
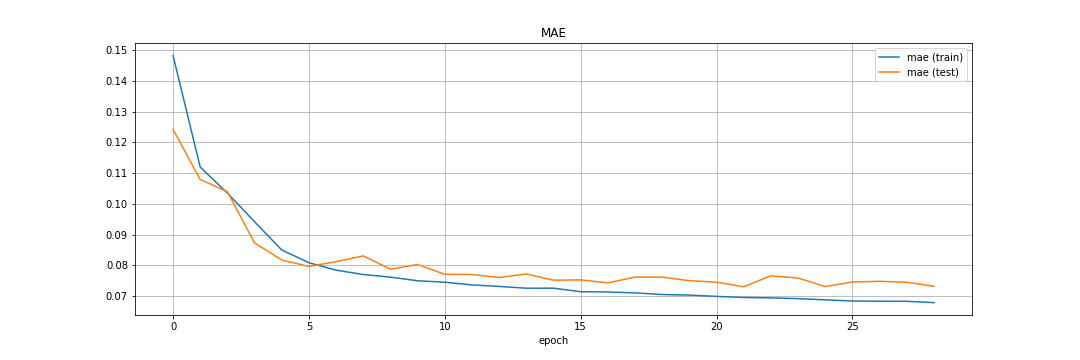
Below we will show the results of the main architecture that we used, that was the one that had 3 latent dimensions.
Below it is presented the evolution of the reconstruction of test images.


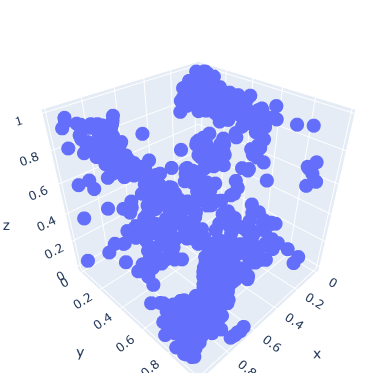
Because the latent dimension is 3, we can plot how the images are distributed in a three dimensional space.
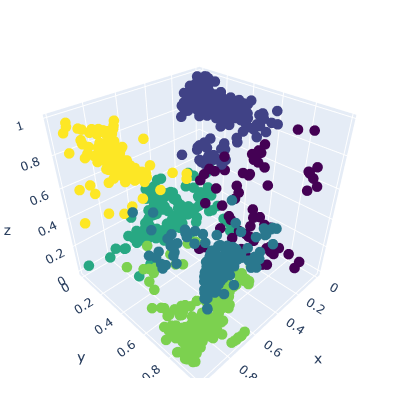
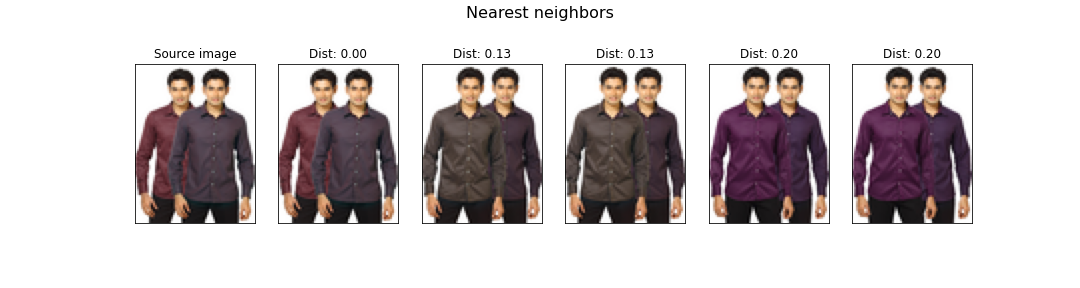
Below are presented the results of different methods for recommending similar images.
The clustering method used was KMeans with 6 clusters. The clusters are displayed below.
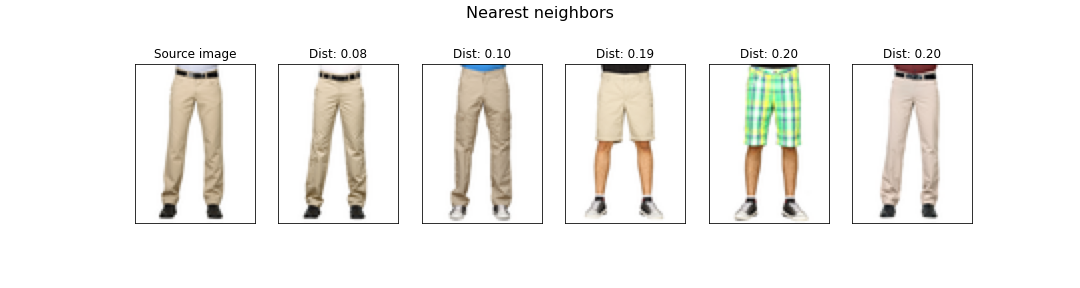
The recomendation based on these clusters is the following.




The dataset Fashion Product Images Dataset was used for the training of the networks was obtained from Kaggle, it contains approximately 44200 different images of clothes. Besides it cointains the different tags for differentiate each type of clothe we will not use them, because the objective of the work is to do an unsupervised learning.
First we tried to download and charge each time the whole dataset from Kaggle, but this operation was very slow because each image was treated individually.
Then we tried to save a .zip file with the content of the dataset an download it for each training, this process was also very slow and consumed too much time.
Finally we decided to generate a binary file that could be efficiently loaded, the generation of this file is described in GeneracionBinarioDataset.ipynb file.