John Snow Labs' NLU is a Python library for applying state-of-the-art text mining, directly on any dataframe, with a single line of code. As a facade of the award-winning Spark NLP library, it comes with 1000+ of pretrained models in 100+ , all production-grade, scalable, and trainable and everything in 1 line of code.
See how easy it is to use any of the thousands of models in 1 line of code, there are hundreds of tutorials and simple examples you can copy and paste into your projects to achieve State Of The Art easily.

This 1 line let's you visualize and play with 1000+ SOTA NLU & NLP models in 200 languages for Named Entitiy Recognition, Dependency Trees & Parts of Speech, Classification for 100+ problems, Text Summarization & Question Answering using T5 , Translation with Marian, Text Similarity Matrix using BERT, ALBERT, ELMO, XLNET, ELECTRA with other of the 100+ wordembeddings and much more using Streamlit .
streamlit run https://raw.githubusercontent.com/JohnSnowLabs/nlu/master/examples/streamlit/01_dashboard.py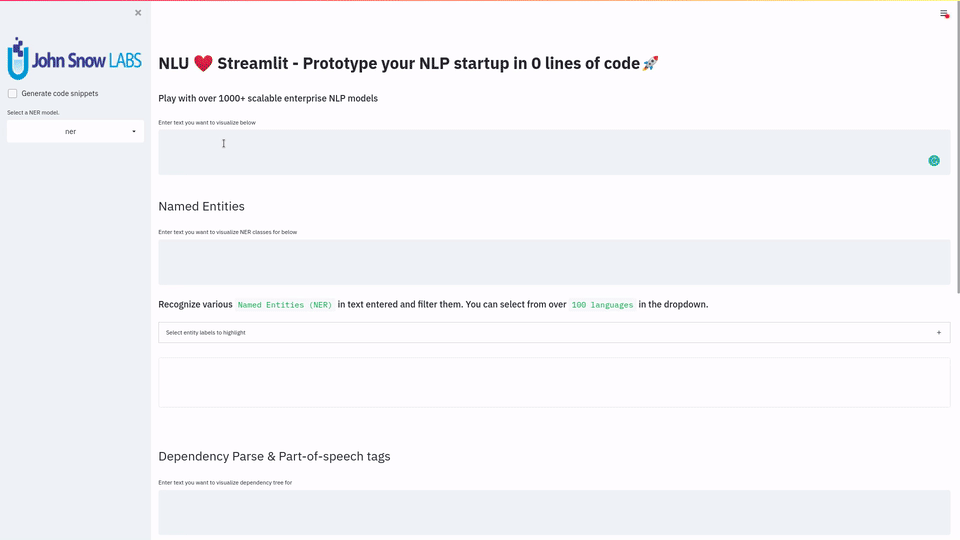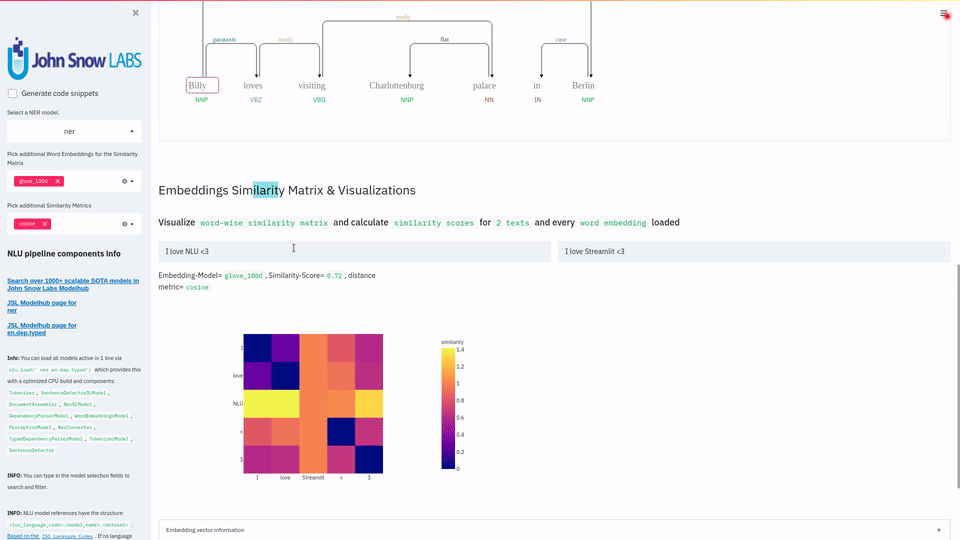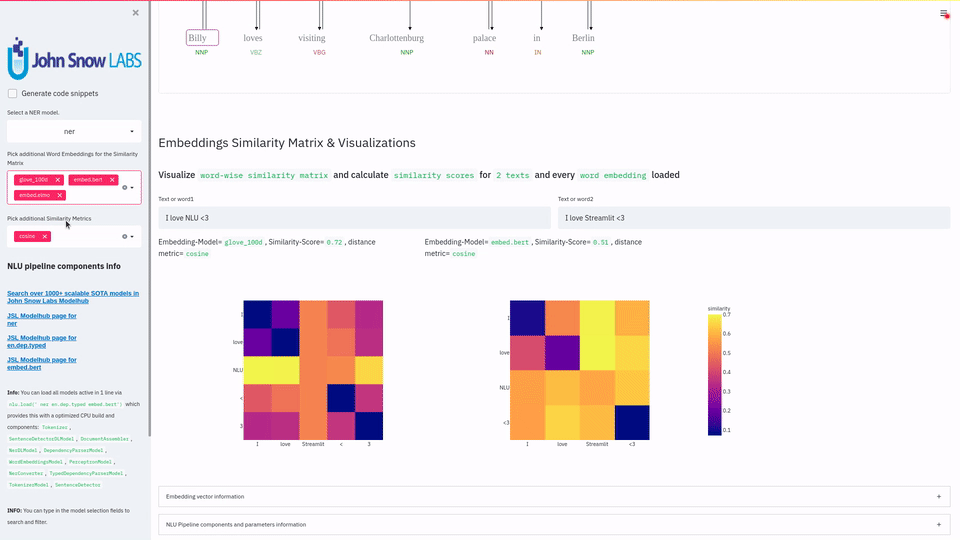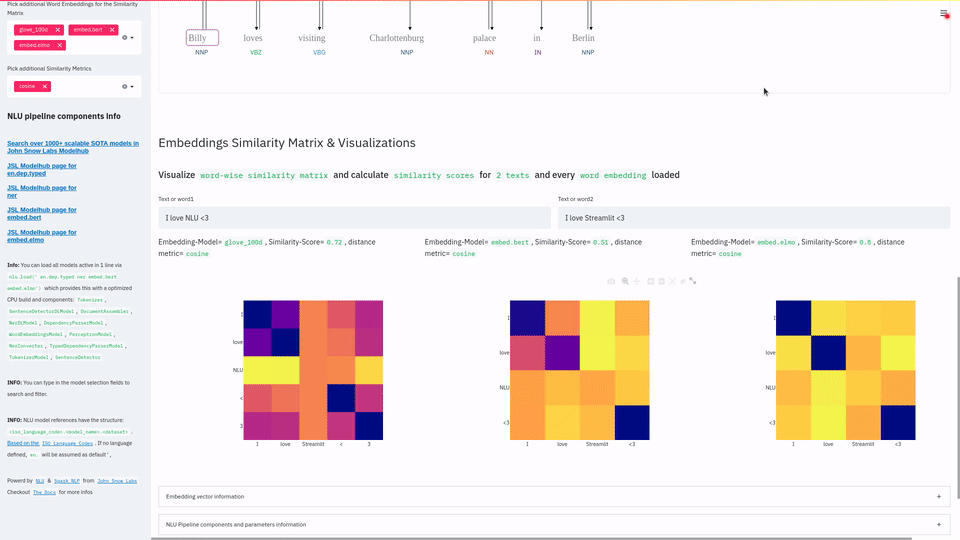
NLU provides tight and simple integration into Streamlit, which enables building powerful webapps in just 1 line of code which showcase the. View the NLU&Streamlit documentation or NLU & Streamlit examples section. The entire GIF demo and
Take a look at our official Spark NLU page: https://nlu.johnsnowlabs.com/ for user documentation and examples
| Ressource | Description |
|---|---|
| Install NLU | Just run pip install nlu pyspark==3.0.2 |
| The NLU Namespace | Find all the names of models you can load with nlu.load() |
The nlu.load(<Model>) function |
Load any of the 1000+ models in 1 line |
The nlu.load(<Model>).predict(data) function |
Predict on Strings, List of Strings, Numpy Arrays, Pandas, Modin and Spark Dataframes |
The nlu.load(<train.Model>).fit(data) function |
Train a text classifier for 2-Class, N-Classes Multi-N-Classes, Named-Entitiy-Recognition or Parts of Speech Tagging |
The nlu.load(<Model>).viz(data) function |
Visualize the results of Word Embedding Similarity Matrix, Named Entity Recognizers, Dependency Trees & Parts of Speech, Entity Resolution,Entity Linking or Entity Status Assertion |
The nlu.load(<Model>).viz_streamlit(data) function |
Display an interactive GUI which lets you explore and test every model and feature in NLU in 1 click. |
| General Concepts | General concepts in NLU |
| The latest release notes | Newest features added to NLU |
| Overview NLU 1-liners examples | Most common used models and their results |
| Overview NLU 1-liners examples for healthcare models | Most common used healthcare models and their results |
| Overview of all NLU tutorials and Examples | 100+ tutorials on how to use NLU on text datasets for various problems and from various sources like Twitter, Chinese News, Crypto News Headlines, Airline Traffic communication, Product review classifier training, |
| Connect with us on Slack | Problems, questions or suggestions? We have a very active and helpful community of over 2000+ AI enthusiasts putting NLU, Spark NLP & Spark OCR to good use |
| Discussion Forum | More indepth discussion with the community? Post a thread in our discussion Forum |
| John Snow Labs Medium | Articles and Tutorials on the NLU, Spark NLP and Spark OCR |
| John Snow Labs Youtube | Videos and Tutorials on the NLU, Spark NLP and Spark OCR |
| NLU Website | The official NLU website |
| Github Issues | Report a bug |
To get your hands on the power of NLU, you just need to install it via pip and ensure Java 8 is installed and properly configured. Checkout Quickstart for more infos
pip install nlu pyspark==3.0.2import nlu
nlu.load('sentiment').predict('I love NLU! <3') Get 6 different embeddings in 1 line and use them for downstream data science tasks!
nlu.load('bert elmo albert xlnet glove use').predict('I love NLU! <3') NLU provides everything a data scientist might want to wish for in one line of code!
- NLU provides everything a data scientist might want to wish for in one line of code!
- 1000 + pre-trained models
- 100+ of the latest NLP word embeddings ( BERT, ELMO, ALBERT, XLNET, GLOVE, BIOBERT, ELECTRA, COVIDBERT) and different variations of them
- 50+ of the latest NLP sentence embeddings ( BERT, ELECTRA, USE) and different variations of them
- 100+ Classifiers (NER, POS, Emotion, Sarcasm, Questions, Spam)
- 300+ Supported Languages
- Summarize Text and Answer Questions with T5
- Labeled and Unlabeled Dependency parsing
- Various Text Cleaning and Pre-Processing methods like Stemming, Lemmatizing, Normalizing, Filtering, Cleaning pipelines and more
Choose the right tool for the right task! Whether you analyze movies or twitter, NLU has the right model for you!
- trec6 classifier
- trec10 classifier
- spam classifier
- fake news classifier
- emotion classifier
- cyberbullying classifier
- sarcasm classifier
- sentiment classifier for movies
- IMDB Movie Sentiment classifier
- Twitter sentiment classifier
- NER pretrained on ONTO notes
- NER trainer on CONLL
- Language classifier for 20 languages on the wiki 20 lang dataset.
Working with text data can sometimes be quite a dirty Job. NLU helps you keep your hands clean by providing lots of components that take away data engineering intensive tasks.
- Datetime Matcher
- Pattern Matcher
- Chunk Matcher
- Phrases Matcher
- Stopword Cleaners
- Pattern Cleaners
- Slang Cleaner
For NLU models to load, see the NLU Namespace or the John Snow Labs Modelshub or go straight to the source.
- Pandas DataFrame and Series
- Spark DataFrames
- Modin with Ray backend
- Modin with Dask backend
- Numpy arrays
- Strings and lists of strings
- Kaggle Twitter Airline Sentiment Analysis NLU demo
- Kaggle Twitter Airline Emotion Analysis NLU demo
- Kaggle Twitter COVID Sentiment Analysis NLU demo
- Kaggle Twitter COVID Emotion Analysis nlu demo
Checkout the following notebooks for examples on how to work with NLU.
- 2 class Finance News sentiment classifier training
- 2 class Reddit comment sentiment classifier training
- 2 class Apple Tweets sentiment classifier training
- 2 class IMDB Movie sentiment classifier training
- 2 class twitter classifier training
- 5 class WineEnthusiast Wine review classifier training
- 3 class Amazon Phone review classifier training
- 5 class Amazon Musical Instruments review classifier training
- 5 class Tripadvisor Hotel review classifier training
- 5 class Phone review classifier training
- Train Multi Label Classifier on E2E dataset Demo
- Train Multi Label Classifier on Stack Overflow Question Tags dataset Demo
- Sentence Similarity with Multiple Sentence Embeddings
- 6 Wordembeddings in 1 line with T-SNE plotting
- Kaggle Twitter Airline Sentiment Analysis NLU demo
- Kaggle Twitter Airline Emotion Analysis NLU demo
- Kaggle Twitter COVID Sentiment Analysis NLU demo
- Kaggle Twitter COVID Emotion Analysis nlu demo
The following are Collab examples which showcase each NLU component and some applications.
- NER pretrained on ONTO Notes
- NER pretrained on CONLL
- Tokenize, extract POS and NER in Chinese
- Tokenize, extract POS and NER in Korean
- Tokenize, extract POS and NER in Japanese
- Aspect based sentiment NER sentiment for restaurants
- POS pretrained on ANC dataset
- Tokenize, extract POS and NER in Chinese
- Tokenize, extract POS and NER in Korean
- Tokenize, extract POS and NER in Japanese
- Translate between 192+ languages with marian
- Try out the 18 Tasks like Summarization Question Answering and more on T5
- T5 Open and Closed Book question answering tutorial
- Unsupervised Keyword Extraction with YAKE
- Toxic Text Classifier
- Twitter Sentiment Classifier
- Movie Review Sentiment Classifier
- Sarcasm Classifier
- 50 Class Questions Classifier
- 300 Class Languages Classifier
- Fake News Classifier
- E2E Classifier
- Cyberbullying Classifier
- Spam Classifier
- Emotion Classifier
- BERT, ALBERT, ELMO, ELECTRA, XLNET, GLOVE at once with t-SNE plotting
- BERT Word Embeddings and t-SNE plotting
- ALBERT Word Embeddings and t-SNE plotting
- ELMO Word Embeddings and t-SNE plotting
- XLNET Word Embeddings and t-SNE plotting
- ELECTRA Word Embeddings and t-SNE plotting
- COVIDBERT Word Embeddings and t-SNE plotting
- BIOBERT Word Embeddings and t-SNE plotting
- GLOVE Word Embeddings and t-SNE plotting
- BERT Sentence Embeddings and t-SNE plotting
- ELECTRA Sentence Embeddings and t-SNE plotting
- USE Sentence Embeddings and t-SNE plotting
- BERT Sentence Embeddings and t-SNE plotting
- ELECTRA Sentence Embeddings and t-SNE plotting
- USE Sentence Embeddings and t-SNE plotting
- Tokenization
- Stopwords removal
- Stemming
- Lemmatization
- Normalizing
- Spell checking
- Sentence Detecting
- Normalize documents
- Tokenization
- Trainable Word Segmentation
- Stop Words Removal
- Token Normalizer
- Document Normalizer
- Stemmer
- Lemmatizer
- NGrams
- Regex Matching
- Text Matching,
- Chunking
- Date Matcher
- Sentence Detector
- Deep Sentence Detector (Deep learning)
- Dependency parsing (Labeled/unlabeled)
- Part-of-speech tagging
- Sentiment Detection (ML models)
- Spell Checker (ML and DL models)
- Word Embeddings (GloVe and Word2Vec)
- BERT Embeddings (TF Hub models)
- ELMO Embeddings (TF Hub models)
- ALBERT Embeddings (TF Hub models)
- XLNet Embeddings
- Universal Sentence Encoder (TF Hub models)
- BERT Sentence Embeddings (42 TF Hub models)
- Sentence Embeddings
- Chunk Embeddings
- Unsupervised keywords extraction
- Language Detection & Identification (up to 375 languages)
- Multi-class Sentiment analysis (Deep learning)
- Multi-label Sentiment analysis (Deep learning)
- Multi-class Text Classification (Deep learning)
- Neural Machine Translation
- Text-To-Text Transfer Transformer (Google T5)
- Named entity recognition (Deep learning)
- Easy TensorFlow integration
- GPU Support
- Full integration with Spark ML functions
- 1000 pre-trained models in +200 languages!
- Multi-lingual NER models: Arabic, Chinese, Danish, Dutch, English, Finnish, French, German, Hewbrew, Italian, Japanese, Korean, Norwegian, Persian, Polish, Portuguese, Russian, Spanish, Swedish, Urdu and more
- Natural Language inference
- Coreference resolution
- Sentence Completion
- Word sense disambiguation
- Clinical entity recognition
- Clinical Entity Linking
- Entity normalization
- Assertion Status Detection
- De-identification
- Relation Extraction
- Clinical Entity Resolution
We have published a paper that you can cite for the NLU library:
@article{KOCAMAN2021100058,
title = {Spark NLP: Natural language understanding at scale},
journal = {Software Impacts},
pages = {100058},
year = {2021},
issn = {2665-9638},
doi = {https://doi.org/10.1016/j.simpa.2021.100058},
url = {https://www.sciencedirect.com/science/article/pii/S2665963821000063},
author = {Veysel Kocaman and David Talby},
keywords = {Spark, Natural language processing, Deep learning, Tensorflow, Cluster},
abstract = {Spark NLP is a Natural Language Processing (NLP) library built on top of Apache Spark ML. It provides simple, performant & accurate NLP annotations for machine learning pipelines that can scale easily in a distributed environment. Spark NLP comes with 1100+ pretrained pipelines and models in more than 192+ languages. It supports nearly all the NLP tasks and modules that can be used seamlessly in a cluster. Downloaded more than 2.7 million times and experiencing 9x growth since January 2020, Spark NLP is used by 54% of healthcare organizations as the world’s most widely used NLP library in the enterprise.}
}
}