
Aim logs your training runs, enables a beautiful UI to compare them and an API to query them programmatically.
Documentation • Aim in 3 steps • Demo • Examples • Roadmap • Alternatives • Slack Community • Twitter










Aim is an open-source, self-hosted ML experiment tracking tool. Aim is good at tracking lots of (1000s) of runs and allowing you to compare them with a performant and beautiful UI.
You can use Aim not only through its UI but also through its SDK to query your runs' metadata programmatically for automations and additional analysis. Aim's mission is to democratize AI dev tools.
Follow the steps below to get started with Aim.
1. Install Aim on your training environment
pip3 install aim2. Integrate Aim with your code
Integrate your Python script
from aim import Run, Image, Distribution
# Initialize a new run
run = Run()
# Log run parameters
run["hparams"] = {
"learning_rate": 0.001,
"batch_size": 32,
}
# Log artefacts
for step in range(1000):
# Log metrics
run.track(loss_val, name='loss', step=step, context={ "subset": "train" })
run.track(accuracy_val, name='acc', step=step, context={ "subset": "train" })
# Log images
run.track(Image(tensor_or_pil, caption), name='gen', step=step, context={ "subset": "train" })
# Log distributions
run.track(Distribution(tensor), name='gradients', step=step, context={ "type": "weights" })See documentation here.
Integrate PyTorch Lightning
from aim.pytorch_lightning import AimLogger
# ...
trainer = pl.Trainer(logger=AimLogger(experiment='experiment_name'))
# ...See documentation here.
Integrate Hugging Face
from aim.hugging_face import AimCallback
# ...
aim_callback = AimCallback(repo='/path/to/logs/dir', experiment='mnli')
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
callbacks=[aim_callback],
# ...
)
# ...See documentation here.
Integrate Keras & tf.keras
import aim
# ...
model.fit(x_train, y_train, epochs=epochs, callbacks=[
aim.keras.AimCallback(repo='/path/to/logs/dir', experiment='experiment_name')
# Use aim.tensorflow.AimCallback in case of tf.keras
aim.tensorflow.AimCallback(repo='/path/to/logs/dir', experiment='experiment_name')
])
# ...See documentation here.
Integrate XGBoost
from aim.xgboost import AimCallback
# ...
aim_callback = AimCallback(repo='/path/to/logs/dir', experiment='experiment_name')
bst = xgb.train(param, xg_train, num_round, watchlist, callbacks=[aim_callback])
# ...See documentation here.
3. Run the training as usual and start Aim UI
aim upAn overview of the major screens/ features of Aim UI
Runs explorer will help you to holistically view all your runs, each metric last tracked values and tracked hyperparameters.
Features:
- Full Research context at hand
- Search runs by date, experiment, hash, tag or parameters
- Search by run/experiment

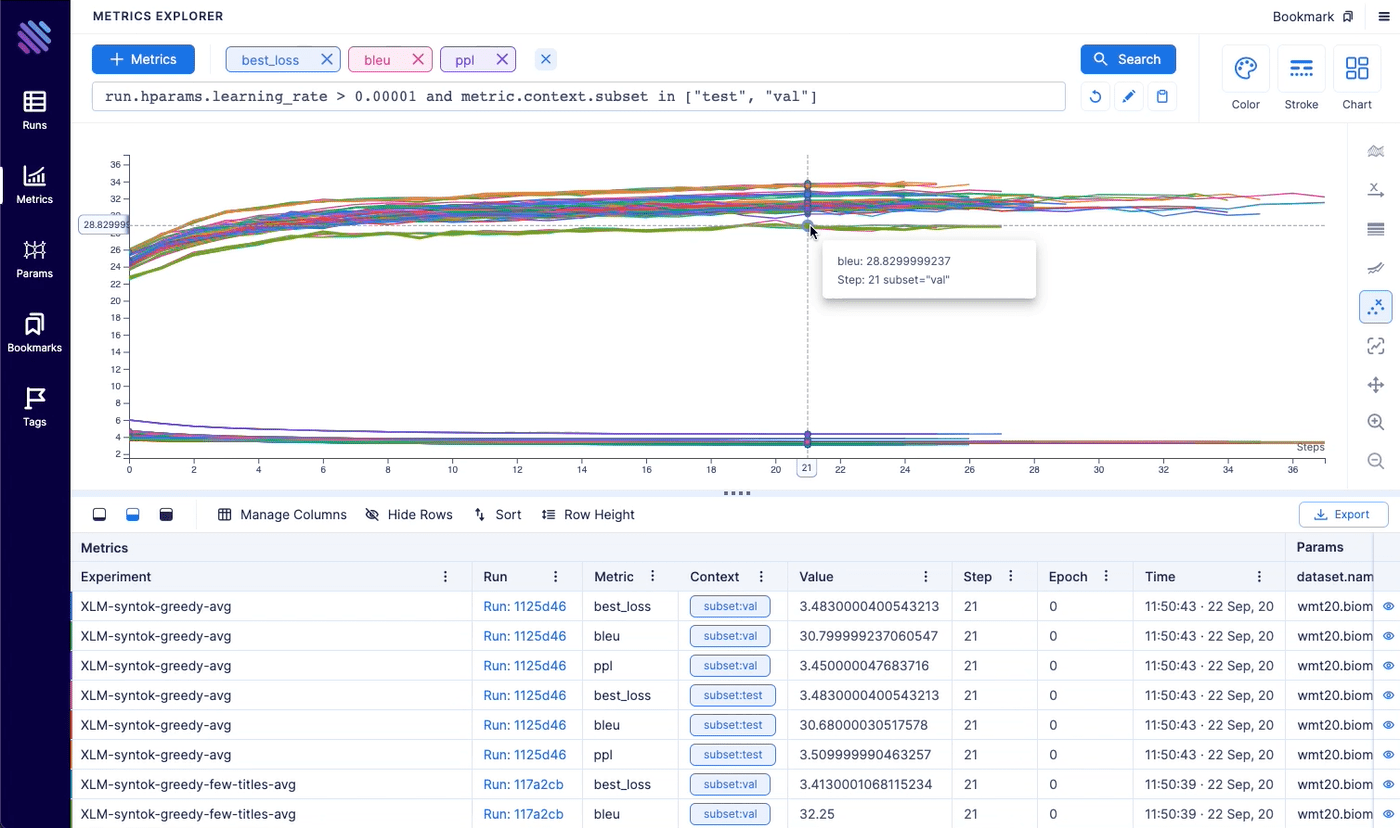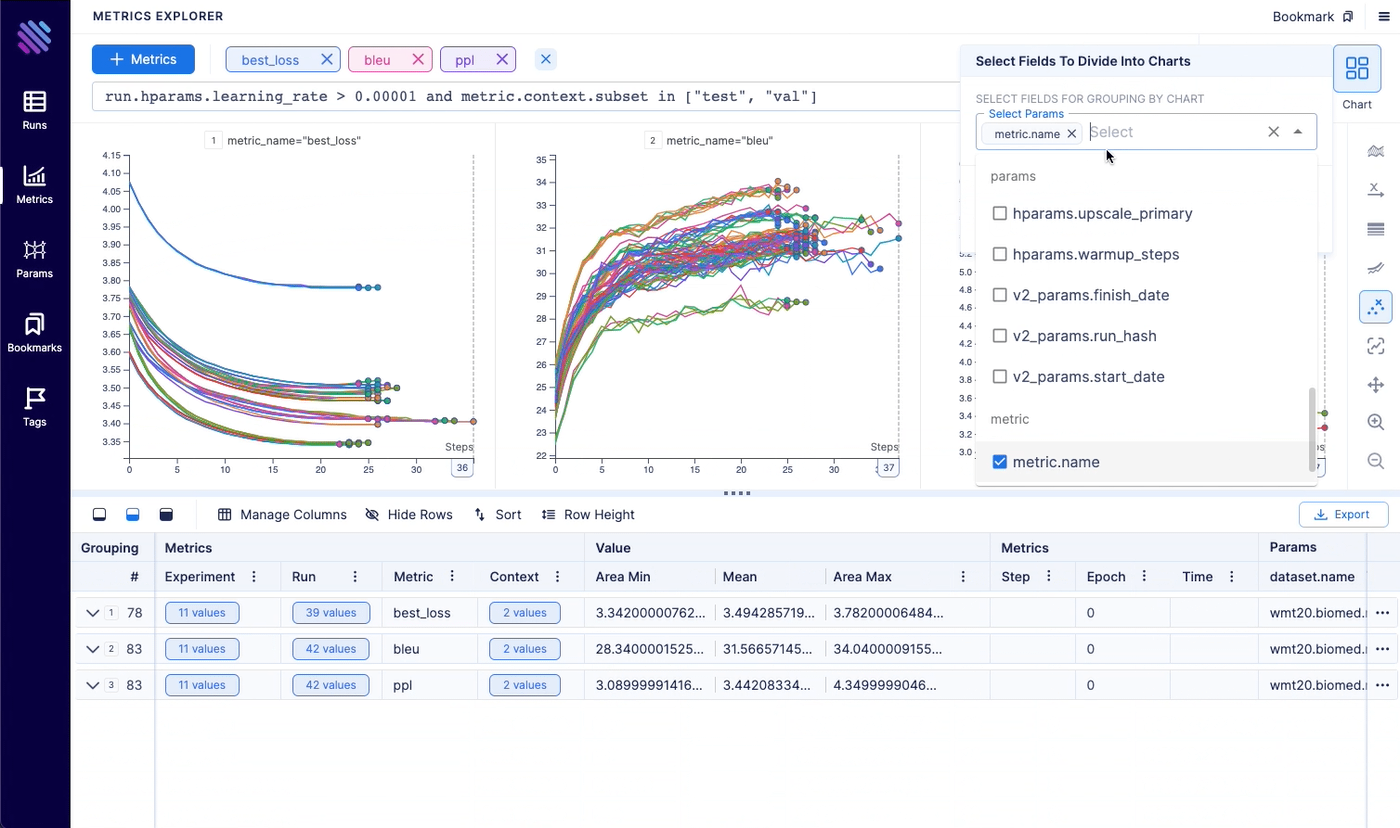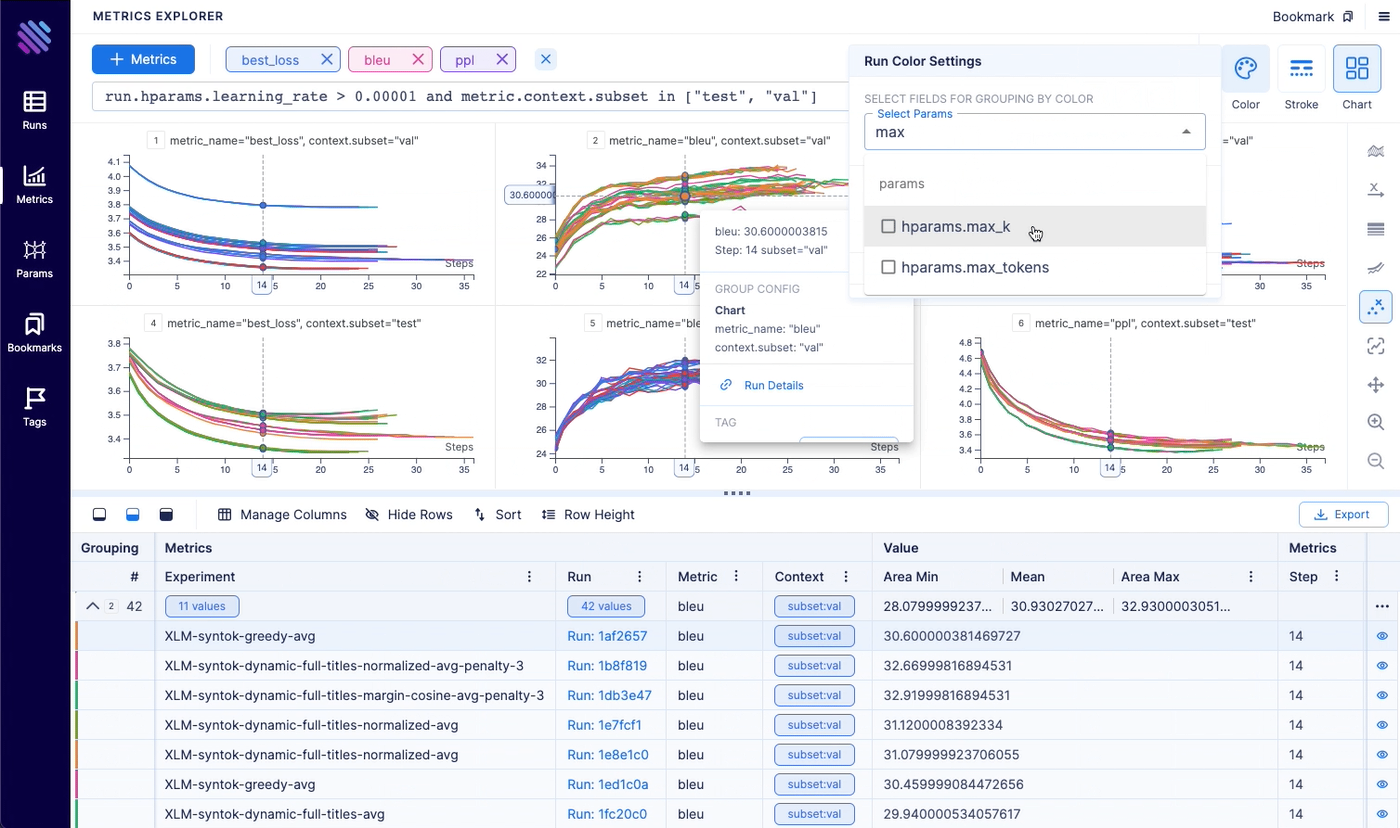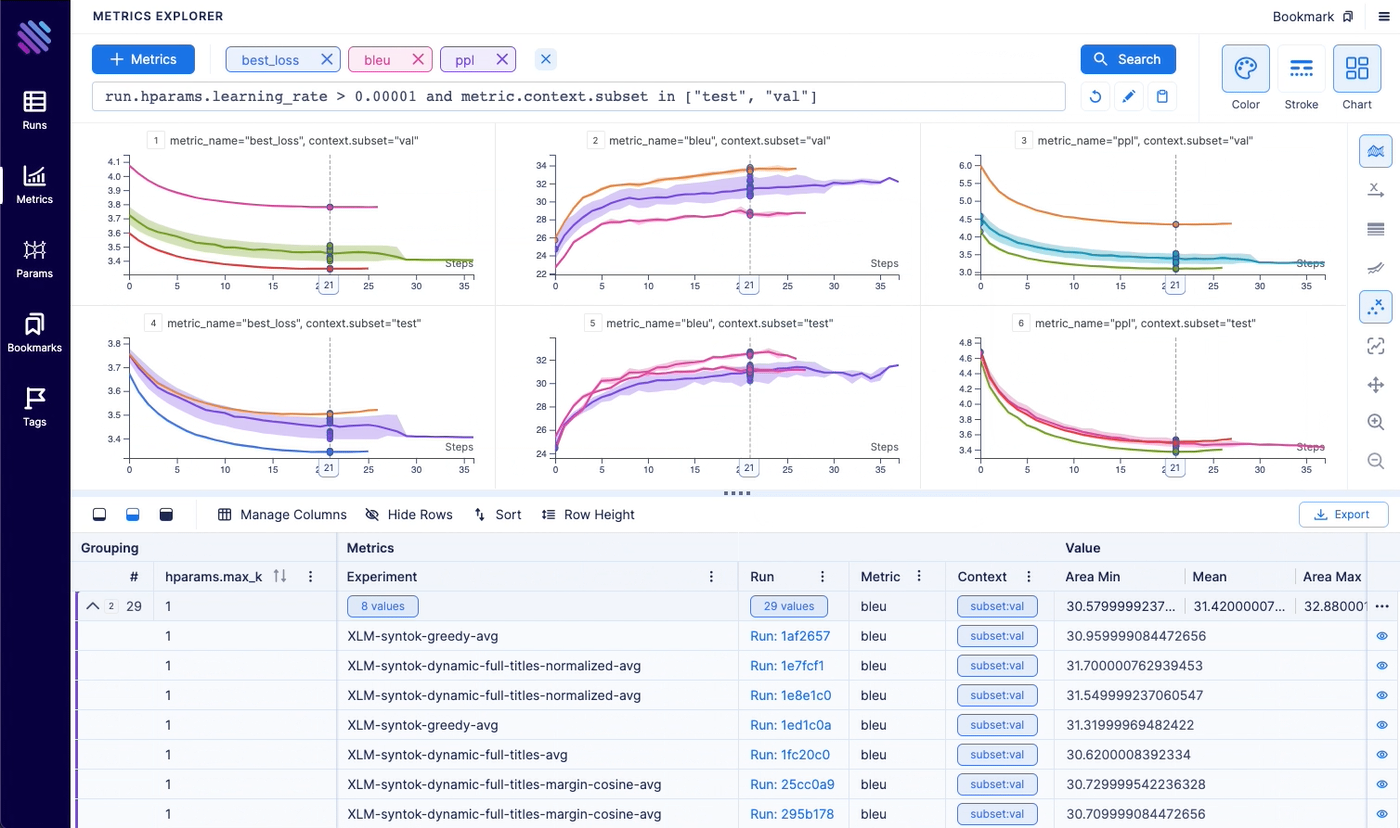
Metrics explorer helps you to compare 100s of metrics within a few clicks. It helps to save lots of time compared to other open-source experiment tracking tools.
Features:
- Easily query any metric
- Group by any parameter
- Divide into subplots
- Aggregate grouped metrics (by conf. interval, std. dev., std. err., min/max)
- Apply smoothing
- Change scale of the axes (linear or log)
- Align metrics by time, epoch or another metric

Track intermediate images and search, compare them on the Images Explorer.
Features:
- Easily query any image
- Group images by run parameters
- Group images by step
Params explorer enables a parallel coordinates view for metrics and params. Very helpful when doing hyperparameter search.
Features:
- Easily query any metrics and params
- Group runs or divide into subplots
- Apply chart indicator to see correlations

Explore all the metadata associated with a run on the single run page. It's accessible from all the tables and tooltips.
Features:
- See all the logged params of a run
- See all the tracked metrics(including system metrics)

Use Repo object to query and access saved Runs.
Initialize a Repo instance:
from aim import Repo
my_repo = Repo('/path/to/aim/repo')Repo class full spec.
Query logged metrics and parameters:
query = "metric.name == 'loss'" # Example query
# Get collection of metrics
for run_metrics_collection in my_repo.query_metrics(query).iter_runs():
for metric in run_metrics_collection:
# Get run params
params = metric.run[...]
# Get metric values
steps, metric_values = metric.values.sparse_numpy()See more advanced usage examples here.
Training run comparison
Order of magnitude faster training run comparison with Aim
- The tracked params are first class citizens at Aim. You can search, group, aggregate via params - deeply explore all the tracked data (metrics, params, images) on the UI.
- With tensorboard the users are forced to record those parameters in the training run name to be able to search and compare. This causes a super-tedius comparison experience and usability issues on the UI when there are many experiments and params. TensorBoard doesn't have features to group, aggregate the metrics.
Scalability
- Aim is built to handle 1000s of training runs with dozens of experiments each - both on the backend and on the UI.
- TensorBoard becomes really slow and hard to use when a few hundred training runs are queried / compared.
Beloved TB visualizations to be added on Aim
- Distributions / gradients visualizations.
- Embedding projector.
- Neural network visualization.
MLFlow is an end-to-end ML Lifecycle tool. Aim is focused on training tracking. The main differences of Aim and MLflow are around the UI scalability and run comparison features.
Run comparison
- Aim treats tracked parameters as first-class citizens. Users can query runs, metrics, images and filter using the params.
- MLFlow does have a search by tracked config, but there are no grouping, aggregation, subplotting by hyparparams and other comparison features available.
UI Scalability
- Aim UI can handle several thousands of metrics at the same time smoothly with 1000s of steps. It may get shaky when you explore 1000s of metrics with 10000s of steps each. But we are constantly optimizing!
- MLflow UI becomes slow to use when there are a few hundreds of runs.
Hosted vs self-hosted
- Weights and Biases is a hosted closed-source experiment tracker.
- Aim is self-hosted free and open-source.
- Remote self-hosted Aim is coming soon...
Aim package is available for Python 3.6+ on the following platforms
| Linux | MacOS | Windows |
|---|---|---|
| ✔️ | ✔️ | ➖ |
❇️ The Aim product roadmap
- The
Backlogcontains the issues we are going to choose from and prioritize weekly - The issues are mainly prioritized by the highly-requested features
The high-level features we are going to work on the next few months
Done
- Live updates (Shipped: Oct 18 2021)
- Images tracking and visualization (Start: Oct 18 2021, Shipped: Nov 19 2021)
- Distributions tracking and visualization (Start: Nov 10 2021, Shipped: Dec 3 2021)
- Jupyter integration (Start: Nov 18 2021, Shipped: Dec 3 2021)
- Audio tracking and visualization (Start: Dec 6 2021, Shipped: Dec 17 2021)
- Transcripts tracking and visualization (Start: Dec 6 2021, Shipped: Dec 17 2021)
- Plotly integration (Start: Dec 1 2021, Shipped: Dec 17 2021)
- Colab integration (Start: Nov 18 2021, Shipped: Dec 17 2021)
In progress:
- Centralized tracking server (Start: Oct 18 2021)
- Scikit-learn integration (Start: Nov 18 2021)
- Tensorboard adaptor - visualize TensorBoard logs with Aim (Start: Dec 17 2021)
Track and Explore:
- Models tracking/versioning, model registry
- Runs side-by-side comparison
Data Backup:
- Cloud storage support: aws s3, gsc, azure storage
Reproducibility:
- Track git info, env vars, CLI arguments, dependencies
- Collect stdout, stderr logs
Integrations:
- Kubeflow integration
- Streamlit integration
- Raytune integration
- Google MLMD
- MLFlow adaptor (visualize MLflow logs with Aim)
If you have questions please: