Implementation of "Pricing the Term Structure with Linear Regressions" from Adrian, Crump and Moench (2013).
The NominalACM class prices the time series and cross-section of the term
structure of interest rates using a three-step linear regression approach.
Computations are fast, even with a large number of pricing factors. The object
carries all the relevant variables as atributes:
- The yield curve itself
- The excess returns from the synthetic zero coupon bonds
- The principal components of the curve used as princing factors
- Risk premium parameter estimates
- Yields fitted by the model
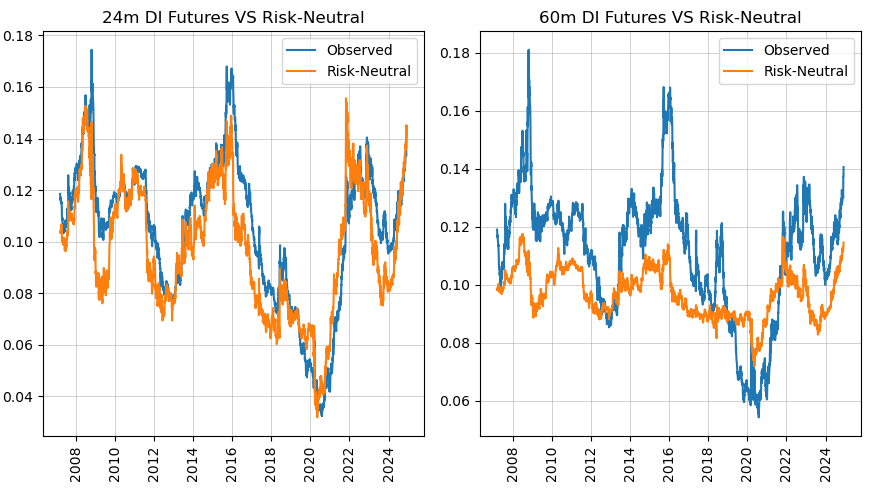
- Risk-neutral yields
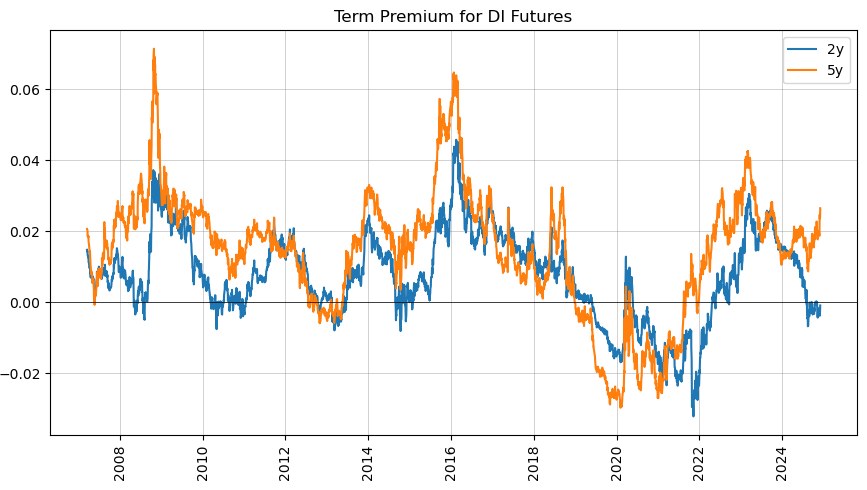
- Term premium
- Historical in-sample expected returns
- Expected return loadings
- Hypothesis testing (Not sure if correct, more info observations below)
pip install pyacmfrom pyacm import NominalACM
acm = NominalACM(
curve=yield_curve,
n_factors=5,
)The tricky part of using this model is getting the correct data format. The
yield_curve dataframe in the expression above requires:
- Annualized log-yields for zero-coupon bonds
- Observations (index) must be in either monthly or daily frequency
- Maturities (columns) must be equally spaced in monthly frequency and start at month 1. This means that you need to construct a bootstraped curve for every date and interpolate it at fixed monthly maturities
- Whichever maturity you want to be the longest, your input data should have one column more. For example, if you want term premium estimate up to the 10-year yield (120 months), your input data should include maturities up to 121 months. This is needed to properly compute the returns.
The estimates for the US are available on the NY FED website.
The jupyter notebook example_br
contains an example application to the Brazilian DI futures curve that showcases all the available methods.
Adrian, Tobias and Crump, Richard K. and Moench, Emanuel, Pricing the Term Structure with Linear Regressions (April 11, 2013). FRB of New York Staff Report No. 340, Available at SSRN: https://ssrn.com/abstract=1362586 or http://dx.doi.org/10.2139/ssrn.1362586
The version of the article that was published by the NY FED is not 100% explicit on how the data is being manipulated, but I found an earlier version of the paper on SSRN where the authors go deeper into the details on how everything is being estimated:
- Data for zero yields uses monthly maturities starting from month 1
- All principal components and model parameters are estiamted with data resampled to a monthly frequency, averaging observations in each month
- To get daily / real-time estimates, the factor loadings estimated from the monthly frquency are used to transform the daily data
I am not completely sure that computations in the inferences attributes are correct. If you find any mistakes, please open a pull request following the contributing guidelines.