这是一个声音克隆工具,可使用任何人类音色,将一段文字合成为使用该音色说话的声音,或者将一个声音使用该音色转换为另一个声音。
使用非常简单,没有N卡GPU也可以使用,下载预编译版本,双击 app.exe 打开一个web界面,鼠标点点就能用。
支持 中文、英文、日语、韩语 4种语言,可在线从麦克风录制声音。
为保证合成效果,建议录制时长5秒到20秒,发音清晰准确,不要存在背景噪声。
英文效果很棒,中文效果还凑合。
1.mp4
-
右侧Releases中下载预编译版,适用于window 10/11(已含文字到语音模型,语音到语音模型需单独下载),Mac下请拉取源码自行编译
-
下载后解压到某处,比如 E:/clone-voice 下
-
双击 start.bat ,等待自动打开web窗口,如下
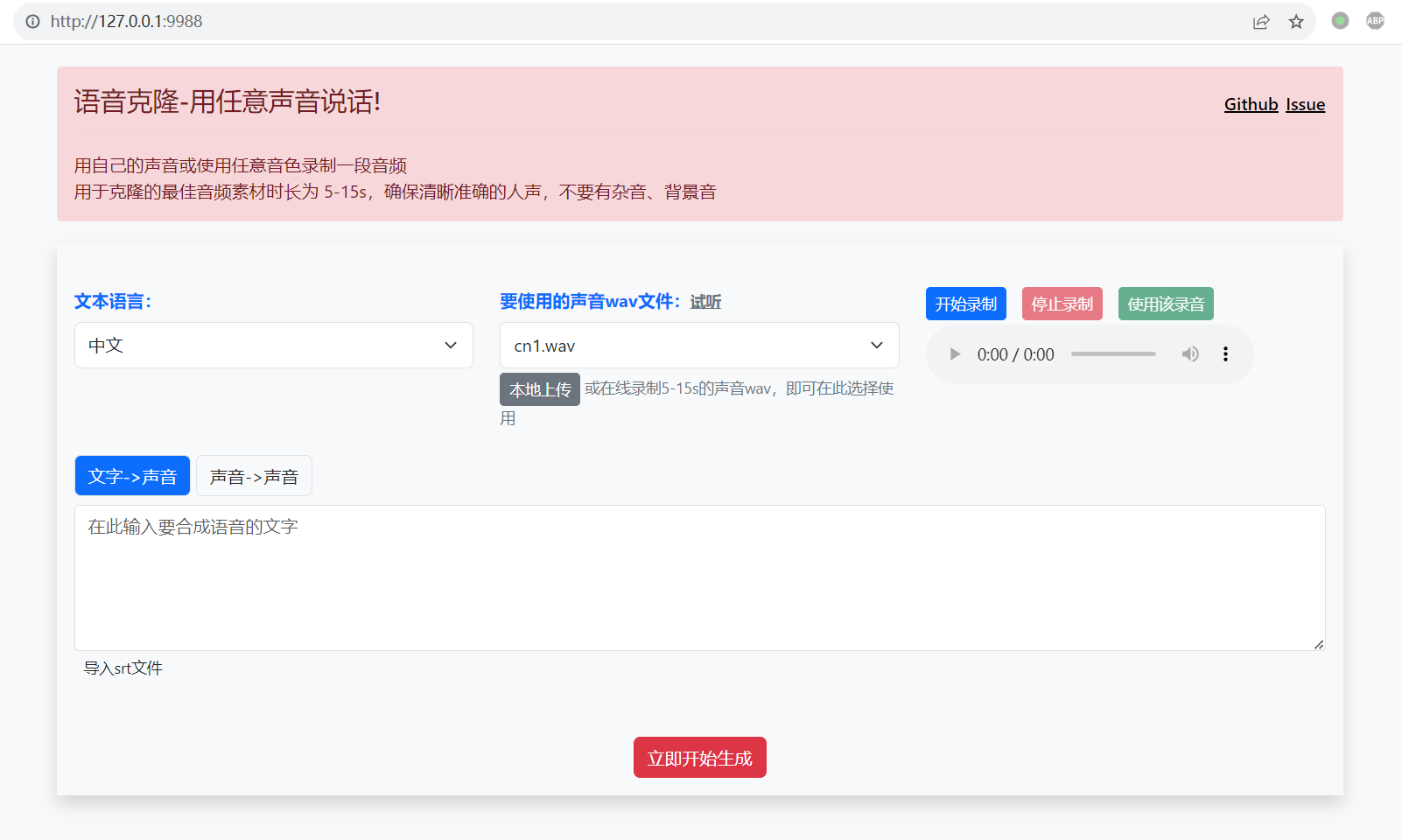
-
输入文字或者上传想转换的音频文件,然后录制或从本地上传一段音色文件,开始转换
-
为减小体积,预编译版仅支持CPU,只包含文字到语音模型
如果需要语音到语音功能,即上传一个音频文件,然后将该音频转换为使用选定音色的另一个音频,需单独下载语音到语音(speech-to-speech)模型,然后放到和app.exe同级的tts文件夹中,右键“解压到当前文件夹下”
-
如需GPU支持,请拉取源码本地编译
- 要求 python 3.9+
- 创建空目录,比如 E:/clone-voice
- 创建虚拟环境
python -m venv venv - 激活环境
cd venv/scripts,activate,cd ../.. - 安装依赖 CPU版:
pip install -r requirements.txt, GPU版:pip install -r requirements-gpu.txt - 解压 ffmpeg.7z 到项目根目录
- 下载模型 文字到语音(text-to-speech)模型 和 语音到语音(speect-to-speech)模型 到项目目录下的tts文件中,然后解压到当前文件夹
- 启动
python app.py
- 语音到语音模型(speech-to-speech)下载
链接:https://pan.baidu.com/s/1vIYzxnlmx2_4prahufoEEw?pwd=hgh2
提取码:hgh2
- 文字到语音模型(text-to-speech)下载(预编译版已包含该模型)
链接:https://pan.baidu.com/s/1LA3JFIb0MnCgoF0Q1sW5dQ?pwd=5k7c
提取码:5k7c
- 预编译版下载(已包含text-t-speech文字到语音模型)
链接 https://pan.baidu.com/s/1lQaosvD1DNLWjA5e3QA27g?pwd=mvgt
提取码:mvgt

