This repository contains the code for EduQG:
EduQG: A Multi-format Multiple Choice Dataset for the Educational Domain
If you use part of the code/dataset please cite:
@misc{2210.06104,
Author = {Amir Hadifar and Semere Kiros Bitew and Johannes Deleu and Chris Develder and Thomas Demeester},
Title = {EduQG: A Multi-format Multiple Choice Dataset for the Educational Domain},
Year = {2022},
Eprint = {arXiv:2210.06104},
}
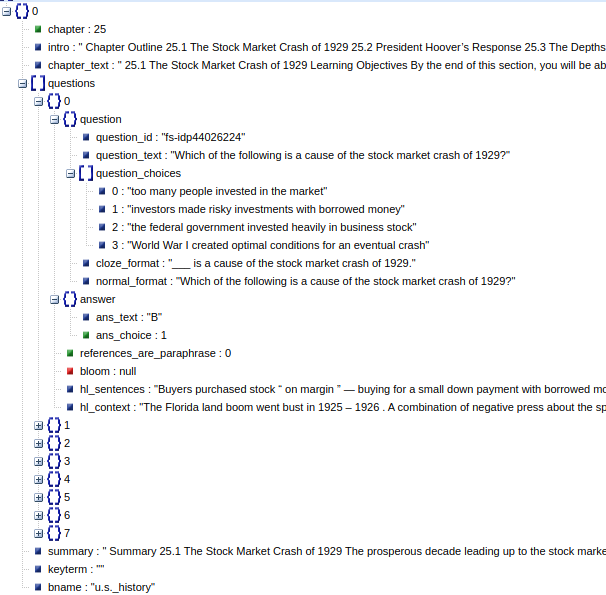
The structure of dataset files (raw_data/qg_train_v0.json and raw_data/qg_valid_v0.json) is shown in the following figure. Each file is a list of chapters with various attributes such as: intro, chapter_text, bname, etc.
pip install -r requirements.txt
sh run_qg_exp.sh
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("hadifar/openstax_qg_agno")
model = AutoModelForSeq2SeqLM.from_pretrained("hadifar/openstax_qg_agno")
This code is based on repo from here.