
66 seasons. 1040 people. 1 package!
survivoR is a collection of data sets detailing events across 66 seasons of Survivor US, Australia, South Africa, New Zealand and UK. It includes castaway information, vote history, immunity and reward challenge winners, jury votes, advantage details and a lot more.
Now on CRAN (v2.1.0) or Git (v2.1.0).
If Git > CRAN I’d suggest install from Git. We are constantly improving the data sets so the github version is likely to be slightly improved.
install.packages("survivoR")devtools::install_github("doehm/survivoR")- Adding data for US44, UK01 and NZ02
- Confessional timing app built with R Shiny (see below)
- Confessional times for US44 and UK01
result_numberon castaways- New features on
castaway_detailslgbt+ flagthree_words– the answer to the question “Three words to describe you”.hobbiespet_peeves
The following link takes you to a repository of complete confessional tables, inlcuding counts and confessional timing for a few seasons.

Confessional counts from myself, Carly Levitz, Sam, Grace.
Included in the package is a confessional timing app to record the length of confessionals while watching the episode.
To launch the app, first install the package and run,
library(survivoR)
launch_confessional_app()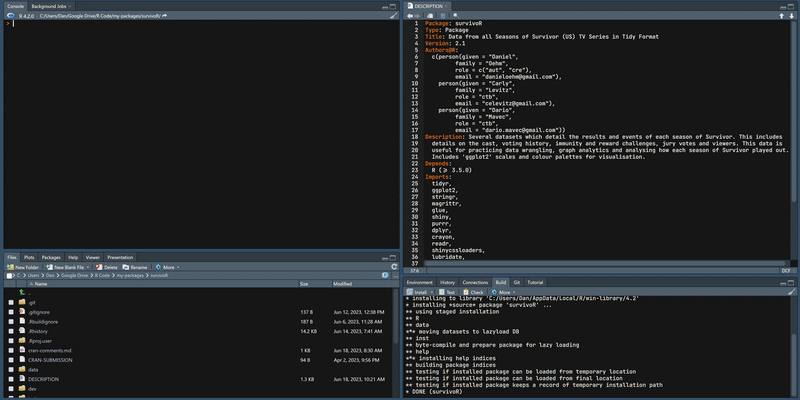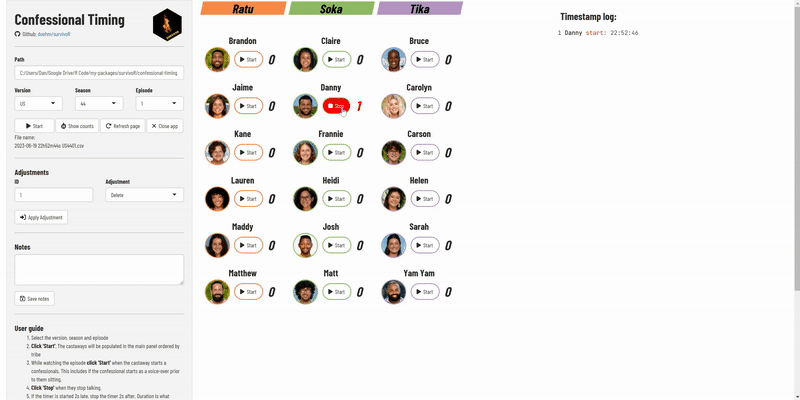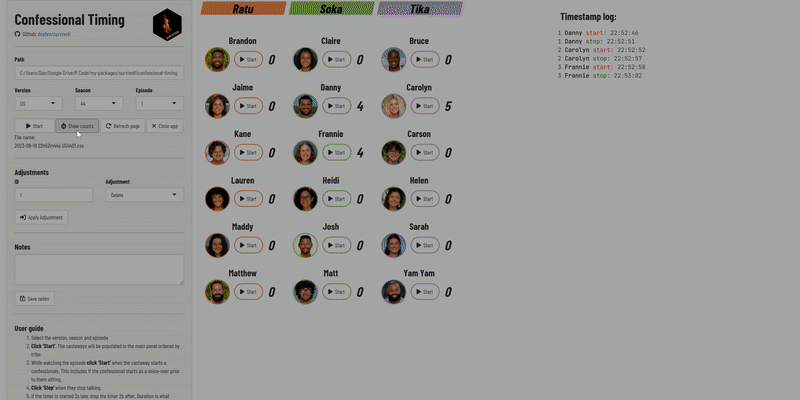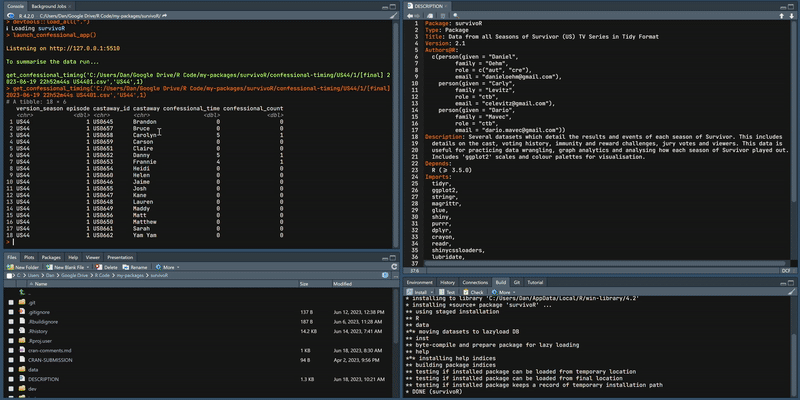
To try it out online 👉 Confessional timing app
More info here.
There are 17 data sets included in the package:
advantage_detailsadvantage_detailsboot_mappingcastaway_detailscastawayschallenge_resultschallenge_descriptionconfessionalsjury_votesscreen_timeseason_palettesseason_summarysurvivor_auctiontribe_colourstribe_mappingviewersvote_history
See the sections below for more details on the key data sets.
Season summary
A table containing summary details of each season of Survivor, including the winner, runner ups and location.
season_summary
#> # A tibble: 66 × 23
#> version version_season season_name season n_cast location country tribe_setup
#> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr>
#> 1 AU AU01 Survivor A… 1 24 Upolu Samoa "The 24 co…
#> 2 AU AU02 Survivor A… 2 24 Upolu Samoa "The 24 co…
#> 3 AU AU03 Survivor A… 3 24 Savusavu Fiji "The 24 co…
#> 4 AU AU04 Survivor A… 4 24 Savusavu Fiji "Two tribe…
#> 5 AU AU05 Survivor A… 5 24 Savusavu Fiji "Two tribe…
#> 6 AU AU06 Survivor A… 6 24 Cloncur… Austra… "The 24 co…
#> 7 AU AU07 Survivor A… 7 24 Charter… Austra… "Blood v W…
#> 8 AU AU08 Survivor A… 8 24 Upolu Samoa "Castaways…
#> 9 NZ NZ01 Survivor N… 1 16 San Jua… Nicara… "Two teams…
#> 10 NZ NZ02 Survivor N… 2 18 Lake Va… Thaila… "Schoolyar…
#> # ℹ 56 more rows
#> # ℹ 15 more variables: full_name <chr>, winner_id <chr>, winner <chr>,
#> # runner_ups <chr>, final_vote <chr>, timeslot <chr>, premiered <date>,
#> # ended <date>, filming_started <date>, filming_ended <date>,
#> # viewers_premiere <dbl>, viewers_finale <dbl>, viewers_reunion <dbl>,
#> # viewers_mean <dbl>, rank <dbl>Castaways
This data set contains season and demographic information about each castaway. It is structured to view their results for each season. Castaways that have played in multiple seasons will feature more than once with the age and location representing that point in time. Castaways that re-entered the game will feature more than once in the same season as they technically have more than one boot order e.g. Natalie Anderson - Winners at War.
Each castaway has a unique castaway_id which links the individual
across all data sets and seasons. It also links to the following ID’s
found on the vote_history, jury_votes and challenges data sets.
vote_idvoted_out_idfinalist_id
castaways |>
filter(season == 42)
#> # A tibble: 18 × 17
#> version version_season season_name season full_name castaway_id castaway
#> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
#> 1 US US42 Survivor: 42 42 Jackson Fox US0613 Jackson
#> 2 US US42 Survivor: 42 42 Zach Wurthen… US0626 Zach
#> 3 US US42 Survivor: 42 42 Marya Sherron US0618 Marya
#> 4 US US42 Survivor: 42 42 Jenny Kim US0614 Jenny
#> 5 US US42 Survivor: 42 42 Swati Goel US0624 Swati
#> 6 US US42 Survivor: 42 42 Daniel Strunk US0610 Daniel
#> 7 US US42 Survivor: 42 42 Lydia Meredi… US0617 Lydia
#> 8 US US42 Survivor: 42 42 Chanelle How… US0609 Chanelle
#> 9 US US42 Survivor: 42 42 Rocksroy Bai… US0622 Rocksroy
#> 10 US US42 Survivor: 42 42 Tori Meehan US0625 Tori
#> 11 US US42 Survivor: 42 42 Hai Giang US0612 Hai
#> 12 US US42 Survivor: 42 42 Drea Wheeler US0611 Drea
#> 13 US US42 Survivor: 42 42 Omar Zaheer US0621 Omar
#> 14 US US42 Survivor: 42 42 Lindsay Dola… US0616 Lindsay
#> 15 US US42 Survivor: 42 42 Jonathan You… US0615 Jonathan
#> 16 US US42 Survivor: 42 42 Romeo Escobar US0623 Romeo
#> 17 US US42 Survivor: 42 42 Mike Turner US0620 Mike
#> 18 US US42 Survivor: 42 42 Maryanne Oke… US0619 Maryanne
#> # ℹ 10 more variables: age <dbl>, city <chr>, state <chr>, episode <dbl>,
#> # day <dbl>, order <dbl>, result <chr>, jury_status <chr>,
#> # original_tribe <chr>, result_number <dbl>A few castaways have changed their name from season to season or have
been referred to by a different name during the season e.g. Amber
Mariano; in season 8 Survivor All-Stars there was Rob C and Rob M. That
information has been retained here in the castaways data set.
castaway_details contains unique information for each castaway. It
takes the full name from their most current season and their most
verbose short name which is handy for labelling.
It also includes gender, date of birth, occupation, race, ethnicity and other data. If no source was found to determine a castaways race and ethnicity, the data is kept as missing rather than making an assumption.
castaway_details
#> # A tibble: 1,040 × 16
#> castaway_id full_name full_name_detailed castaway date_of_birth date_of_death
#> <chr> <chr> <chr> <chr> <date> <date>
#> 1 AU0001 Des Quil… Des Quilty Des NA NA
#> 2 AU0002 Bianca A… Bianca Anderson Bianca NA NA
#> 3 AU0003 Evan Jon… Evan Jones Evan NA NA
#> 4 AU0004 Peter Fi… Peter Fiegehen Peter NA NA
#> 5 AU0005 Barry Lea Barry Lea Barry NA NA
#> 6 AU0006 Tegan Ha… Tegan Haining Tegan NA NA
#> 7 AU0007 Rohan Ma… Rohan MacLauren Rohan NA NA
#> 8 AU0008 Kat Dumo… Kat Dumont Katinka 1989-09-21 NA
#> 9 AU0009 Andrew T… Andrew Torrens Andrew NA NA
#> 10 AU0010 Craig I'… Craig I'Anson Craig NA NA
#> # ℹ 1,030 more rows
#> # ℹ 10 more variables: gender <chr>, race <chr>, ethnicity <chr>, poc <chr>,
#> # personality_type <chr>, lgbt <lgl>, occupation <chr>, three_words <chr>,
#> # hobbies <chr>, pet_peeves <chr>Vote history
This data frame contains a complete history of votes cast across all seasons of Survivor. This allows you to see who who voted for who at which Tribal Council. It also includes details on who had individual immunity as well as who had their votes nullified by a hidden immunity idol. This details the key events for the season.
There is some information on split votes to help calculate if a player engaged in a split vote but ultimately hit their target. There are events which influnce the vote e.g. Extra votes, safety without power, etc. These are recorded here as well.
vh <- vote_history |>
filter(
season == 42,
episode == 9
)
vh
#> # A tibble: 10 × 22
#> version version_season season_name season episode day tribe_status tribe
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 2 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 3 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 4 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 5 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 6 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 7 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 8 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 9 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> 10 US US42 Survivor: 42 42 9 17 Merged Kula K…
#> # ℹ 14 more variables: castaway <chr>, immunity <chr>, vote <chr>,
#> # vote_event <chr>, vote_event_outcome <chr>, split_vote <chr>,
#> # nullified <lgl>, tie <lgl>, voted_out <chr>, order <dbl>, vote_order <dbl>,
#> # castaway_id <chr>, vote_id <chr>, voted_out_id <chr>vh |>
count(vote)
#> # A tibble: 4 × 2
#> vote n
#> <chr> <int>
#> 1 Rocksroy 4
#> 2 Romeo 1
#> 3 Tori 4
#> 4 <NA> 1Challenges
Note: From v1.1 the challenge_results dataset has been improved but
could break existing code. The old table is maintained at
challenge_results_dep
There are two tables challenge_results and challenge_description.
A tidy data frame of immunity and reward challenge results. The winners and losers of the challenges are found recorded here.
challenge_results |>
filter(season == 42) |>
group_by(castaway) |>
summarise(
won = sum(result == "Won"),
lost = sum(result == "Lost"),
total_challenges = n(),
chosen_for_reward = sum(chosen_for_reward)
)
#> # A tibble: 18 × 5
#> castaway won lost total_challenges chosen_for_reward
#> <chr> <int> <int> <int> <int>
#> 1 Chanelle 4 7 11 0
#> 2 Daniel 3 4 7 0
#> 3 Drea 5 11 16 0
#> 4 Hai 5 10 15 0
#> 5 Jackson 0 1 1 0
#> 6 Jenny 2 2 4 0
#> 7 Jonathan 10 10 20 1
#> 8 Lindsay 9 10 19 1
#> 9 Lydia 4 5 9 0
#> 10 Marya 1 2 3 0
#> 11 Maryanne 7 13 20 1
#> 12 Mike 5 15 20 2
#> 13 Omar 6 12 18 1
#> 14 Rocksroy 5 8 13 0
#> 15 Romeo 5 15 20 1
#> 16 Swati 3 3 6 0
#> 17 Tori 9 4 13 0
#> 18 Zach 1 1 2 0The challenge_id is the primary key for the challenge_description
data set. The challange_id will change as the data or descriptions
change.
Note: This data frame is going through a massive revamp. Stay tuned.
This data set contains descriptive binary fields for each challenge. Challenges can go by different names but where possible recurring challenges are kept consistent. While there are tweaks to the challenges, where the main components of the challenge is consistent, they share the same name.
The features of each challenge have been determined largely through string searches of key words that describe the challenge. It may not capture the full essence of the challenge but on the whole will provide a good basis for analysis. Since the description is simply a short paragraph or sentence it may not flag all appropriate features. If any descriptive features need altering please let me know in the issues.
Features:
puzzle: If the challenge contains a puzzle element.race: If the challenge is a race between tribes, teams or individuals.precision: If the challenge contains a precision element e.g. shooting an arrow, hitting a target, etc.endurance: If the challenge is an endurance event e.g. last tribe, team, individual standing.strength: If the challenge is largerly strength based e.g. Shoulder the Load.turn_based: If the challenge is conducted in a series of rounds until a certain amount of points are scored or there is one player remaining.balance: If the challenge contains a balancing element.food: If the challenge contains a food element e.g. the food challenge, biting off chunks of meat.knowledge: If the challenge contains a knowledge component e.g. Q and A about the location.memory: If the challenge contains a memory element e.g. memorising a sequence of items.fire: If the challenge contains an element of fire making / maintaining.water: If the challenge is held, in part, in the water.
challenge_description
#> # A tibble: 1,396 × 14
#> challenge_id challenge_name puzzle race precision endurance strength
#> <chr> <chr> <lgl> <lgl> <lgl> <lgl> <lgl>
#> 1 AU0101IM00 Throw One Over TRUE TRUE FALSE FALSE TRUE
#> 2 AU0102IR01 Sacrificial Lamb FALSE TRUE FALSE FALSE FALSE
#> 3 AU0103IM02 Caught in the Web FALSE TRUE FALSE FALSE FALSE
#> 4 AU0103RD02 Supply Ships TRUE TRUE FALSE FALSE FALSE
#> 5 AU0104IM03 Crab Pots FALSE TRUE FALSE FALSE FALSE
#> 6 AU0105IM04 Nutslinger FALSE TRUE TRUE FALSE FALSE
#> 7 AU0105RD04 Build It Up, Break It… FALSE TRUE FALSE FALSE FALSE
#> 8 AU0106IM04 Breakout FALSE TRUE FALSE FALSE FALSE
#> 9 AU0107IM05 Pull Your Weight FALSE FALSE FALSE TRUE TRUE
#> 10 AU0107RD05 Barrel Bridge FALSE TRUE FALSE FALSE FALSE
#> # ℹ 1,386 more rows
#> # ℹ 7 more variables: turn_based <lgl>, balance <lgl>, food <lgl>,
#> # knowledge <lgl>, memory <lgl>, fire <lgl>, water <lgl>
challenge_description |>
summarise_if(is_logical, sum)
#> # A tibble: 1 × 12
#> puzzle race precision endurance strength turn_based balance food knowledge
#> <int> <int> <int> <int> <int> <int> <int> <int> <int>
#> 1 NA NA NA NA NA NA NA NA NA
#> # ℹ 3 more variables: memory <int>, fire <int>, water <int>Jury votes
History of jury votes. It is more verbose than it needs to be, however having a 0-1 column indicating if a vote was placed or not makes it easier to summarise castaways that received no votes.
jury_votes |>
filter(season == 42)
#> # A tibble: 24 × 9
#> version version_season season_name season castaway finalist vote castaway_id
#> <chr> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
#> 1 US US42 Survivor: … 42 Jonathan Romeo 0 US0615
#> 2 US US42 Survivor: … 42 Lindsay Romeo 0 US0616
#> 3 US US42 Survivor: … 42 Omar Romeo 0 US0621
#> 4 US US42 Survivor: … 42 Drea Romeo 0 US0611
#> 5 US US42 Survivor: … 42 Hai Romeo 0 US0612
#> 6 US US42 Survivor: … 42 Tori Romeo 0 US0625
#> 7 US US42 Survivor: … 42 Rocksroy Romeo 0 US0622
#> 8 US US42 Survivor: … 42 Chanelle Romeo 0 US0609
#> 9 US US42 Survivor: … 42 Jonathan Mike 1 US0615
#> 10 US US42 Survivor: … 42 Lindsay Mike 0 US0616
#> # ℹ 14 more rows
#> # ℹ 1 more variable: finalist_id <chr>jury_votes |>
filter(season == 42) |>
group_by(finalist) |>
summarise(votes = sum(vote))
#> # A tibble: 3 × 2
#> finalist votes
#> <chr> <dbl>
#> 1 Maryanne 7
#> 2 Mike 1
#> 3 Romeo 0Advantages
This dataset lists the hidden idols and advantages in the game for all
seasons. It details where it was found, if there was a clue to the
advantage, location and other advantage conditions. This maps to the
advantage_movement table.
advantage_details |>
filter(season == 42)
#> # A tibble: 11 × 9
#> version version_season season_name season advantage_id advantage_type
#> <chr> <chr> <chr> <dbl> <chr> <chr>
#> 1 US US42 Survivor: 42 42 USAM4201 Amulet
#> 2 US US42 Survivor: 42 42 USAM4202 Amulet
#> 3 US US42 Survivor: 42 42 USAM4203 Amulet
#> 4 US US42 Survivor: 42 42 USEV4201 Extra vote
#> 5 US US42 Survivor: 42 42 USEV4202 Extra vote
#> 6 US US42 Survivor: 42 42 USHI4201 Hidden immunity idol
#> 7 US US42 Survivor: 42 42 USHI4202 Hidden immunity idol
#> 8 US US42 Survivor: 42 42 USHI4203 Hidden immunity idol
#> 9 US US42 Survivor: 42 42 USKP4201 Knowledge is power
#> 10 US US42 Survivor: 42 42 USHI4204 Hidden immunity idol
#> 11 US US42 Survivor: 42 42 USIN4201 Idol nullifier
#> # ℹ 3 more variables: clue_details <chr>, location_found <chr>,
#> # conditions <chr>The advantage_movement table tracks who found the advantage, who they
may have handed it to and who the played it for. Each step is called an
event. The sequence_id tracks the logical step of the advantage. For
example in season 41, JD found an Extra Vote advantage. JD gave it to
Shan in good faith who then voted him out keeping the Extra Vote. Shan
gave it to Ricard in good faith who eventually gave it back before Shan
played it for Naseer. That movement is recorded in this table.
advantage_movement |>
filter(advantage_id == "USEV4102")
#> # A tibble: 5 × 15
#> version version_season season_name season castaway castaway_id advantage_id
#> <chr> <chr> <chr> <dbl> <chr> <chr> <chr>
#> 1 US US41 Survivor: 41 41 JD US0603 USEV4102
#> 2 US US41 Survivor: 41 41 Shan US0606 USEV4102
#> 3 US US41 Survivor: 41 41 Ricard US0596 USEV4102
#> 4 US US41 Survivor: 41 41 Shan US0606 USEV4102
#> 5 US US41 Survivor: 41 41 Shan US0606 USEV4102
#> # ℹ 8 more variables: sequence_id <dbl>, day <dbl>, episode <dbl>, event <chr>,
#> # played_for <chr>, played_for_id <chr>, success <chr>, votes_nullified <dbl>Confessionals
A dataset containing the number of confessionals for each castaway by season and episode. There are multiple contributors to this data. Where there are multiple sets of counts for a season the average is taken and added to the package. The aim is to establish consistency in confessional counts in the absence of official sources. Given the subjective nature of the counts and the potential for clerical error no single source is more valid than another. So it is reasonable to average across all sources.
Confessional time exists for a few seasons. This is the total cumulative time for each castaway in seconds. This is a much more accurate indicator of the ‘edit’.
confessionals |>
filter(season == 44) |>
group_by(castaway) |>
summarise(
count = sum(confessional_count),
time = sum(confessional_time)
)
#> # A tibble: 18 × 3
#> castaway count time
#> <chr> <dbl> <dbl>
#> 1 Brandon 27 325
#> 2 Bruce 2 3
#> 3 Carolyn 68 1331
#> 4 Carson 62 1022
#> 5 Claire 7 64
#> 6 Danny 38 579
#> 7 Frannie 34 466
#> 8 Heidi 33 618
#> 9 Helen 8 76
#> 10 Jaime 35 465
#> 11 Josh 25 386
#> 12 Kane 20 273
#> 13 Lauren 31 493
#> 14 Maddy 6 51
#> 15 Matt 30 525
#> 16 Matthew 21 345
#> 17 Sarah 18 244
#> 18 Yam Yam 83 1189The confessional index is available on this data set. The index is a standardised measure of the number of confessionals the player has recieved compared to the others. It is stratified by tribe so it measures how many confessionals each player gets proportional to even share within tribe e.g. an index of 1.5 means that player as received 50% more than others in their tribe.
The tribe grouping is important since the tribe that attends tribal council typical get more screen time, which is fair enough. I don’t think we should expect even share across everyone in the pre-merge stage of the game.
The index is cumulative with episode, so the players final index is the index in their final episode.
confessionals |>
filter(season == 44) |>
group_by(castaway) |>
slice_max(episode) |>
arrange(desc(index_time)) |>
select(castaway, episode, confessional_count, confessional_time, index_count, index_time)
#> # A tibble: 18 × 6
#> # Groups: castaway [18]
#> castaway episode confessional_count confessional_time index_count index_time
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Matthew 5 4 37 1.49 1.89
#> 2 Matt 7 8 168 1.59 1.87
#> 3 Carolyn 13 9 189 1.04 1.24
#> 4 Carson 13 10 229 1.19 1.20
#> 5 Danny 11 7 90 1.12 1.14
#> 6 Yam Yam 13 13 248 1.30 1.13
#> 7 Frannie 10 8 107 1.12 1.02
#> 8 Brandon 8 4 45 1.16 0.973
#> 9 Josh 6 6 97 0.898 0.942
#> 10 Sarah 4 5 82 1.00 0.923
#> 11 Heidi 13 6 166 0.689 0.781
#> 12 Kane 9 4 77 0.754 0.713
#> 13 Jaime 12 6 65 0.828 0.709
#> 14 Lauren 13 4 113 0.626 0.614
#> 15 Maddy 1 6 51 0.72 0.596
#> 16 Claire 3 3 37 0.75 0.563
#> 17 Helen 2 4 57 0.764 0.497
#> 18 Bruce 1 2 3 0.353 0.0575Screen time
This dataset contains the estimated screen time for each castaway during an episode. Please note that this is still in the early days of development. There is likely to be misclassifcation and other sources of error. The model will be refined over time.
An individuals’ screen time is calculated, at a high-level, via the following process:
-
Frames are sampled from episodes on a 1 second time interval
-
MTCNN detects the human faces within each frame
-
VGGFace2 converts each detected face into a 512d vector space
-
A training set of labelled images (1 for each contestant + 3 for Jeff Probst) is processed in the same way to determine where they sit in the vector space. TODO: This could be made more accurate by increasing the number of training images per contestant.
-
The Euclidean distance is calculated for the faces detected in the frame to each of the contestants in the season (+Jeff). If the minimum distance is greater than 1.2 the face is labelled as “unknown”. TODO: Review how robust this distance cutoff truly is - currently based on manual review of Season 42.
-
A multi-class SVM is trained on the training set to label faces. For any face not identified as “unknown”, the vector embedding is run into this model and a label is generated.
-
All labelled faces are aggregated together, with an assumption of 1-5 full second of screen time each time a face is seen and factoring in time between detection capping at a max of 5 seconds.

screen_time |>
filter(version_season == "US42") |>
group_by(castaway_id) |>
summarise(total_mins = sum(screen_time)/60) |>
left_join(
castaway_details |>
select(castaway_id, castaway = short_name),
by = "castaway_id"
) |>
arrange(desc(total_mins))
#> Error in `select()`:
#> ! Can't subset columns that don't exist.
#> ✖ Column `short_name` doesn't exist.Currently it only includes data for season 42. More seasons will be added as they are completed.
Boot mapping
A mapping table to detail who is still alive at each stage of the game. It is useful for easy filtering to say the final players.
# filter to season 42 and when there are 6 people left
# 18 people in the season, therefore 12 boots
still_alive <- function(.version, .season, .n_boots) {
survivoR::boot_mapping |>
filter(
version == .version,
season == .season,
final_n == 6,
game_status %in% c("In the game", "Returned")
)
}
still_alive("US", 42, 6)
#> # A tibble: 6 × 12
#> version version_season season_name season episode order final_n castaway_id
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 US US42 Survivor: 42 42 12 12 6 US0615
#> 2 US US42 Survivor: 42 42 12 12 6 US0616
#> 3 US US42 Survivor: 42 42 12 12 6 US0619
#> 4 US US42 Survivor: 42 42 12 12 6 US0620
#> 5 US US42 Survivor: 42 42 12 12 6 US0621
#> 6 US US42 Survivor: 42 42 12 12 6 US0623
#> # ℹ 4 more variables: castaway <chr>, tribe <chr>, tribe_status <chr>,
#> # game_status <chr>Viewers
Viewers is an episode level table. It contains the episode information such as episode title, air date, length, IMDb rating and the viewer information for every episode across all seasons.
viewers |>
filter(season == 42)
#> # A tibble: 13 × 13
#> version version_season season_name season episode_number_overall episode
#> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 US US42 Survivor: 42 42 571 1
#> 2 US US42 Survivor: 42 42 572 2
#> 3 US US42 Survivor: 42 42 573 3
#> 4 US US42 Survivor: 42 42 574 4
#> 5 US US42 Survivor: 42 42 575 5
#> 6 US US42 Survivor: 42 42 576 6
#> 7 US US42 Survivor: 42 42 577 7
#> 8 US US42 Survivor: 42 42 578 8
#> 9 US US42 Survivor: 42 42 579 9
#> 10 US US42 Survivor: 42 42 580 10
#> 11 US US42 Survivor: 42 42 581 11
#> 12 US US42 Survivor: 42 42 582 12
#> 13 US US42 Survivor: 42 42 583 13
#> # ℹ 7 more variables: episode_title <chr>, episode_label <chr>,
#> # episode_date <date>, episode_length <dbl>, viewers <dbl>,
#> # imdb_rating <dbl>, n_ratings <dbl>Given the variable nature of the game of Survivor and changing of the rules, there are bound to be edges cases where the data is not quite right. Before logging an issue please install the git version to see if it has already been corrected. If not, please log an issue and I will correct the datasets.
New features will be added, such as details on exiled castaways across the seasons. If you have a request for specific data let me know in the issues and I’ll see what I can do. Also, if you’d like to contribute by adding to existing datasets or contribute a new dataset, please contact me directly.
Carly Levitz has developed a fantastic dashboard showcasing the data and allowing you to drill down into seasons, castaways, voting history and challenges.
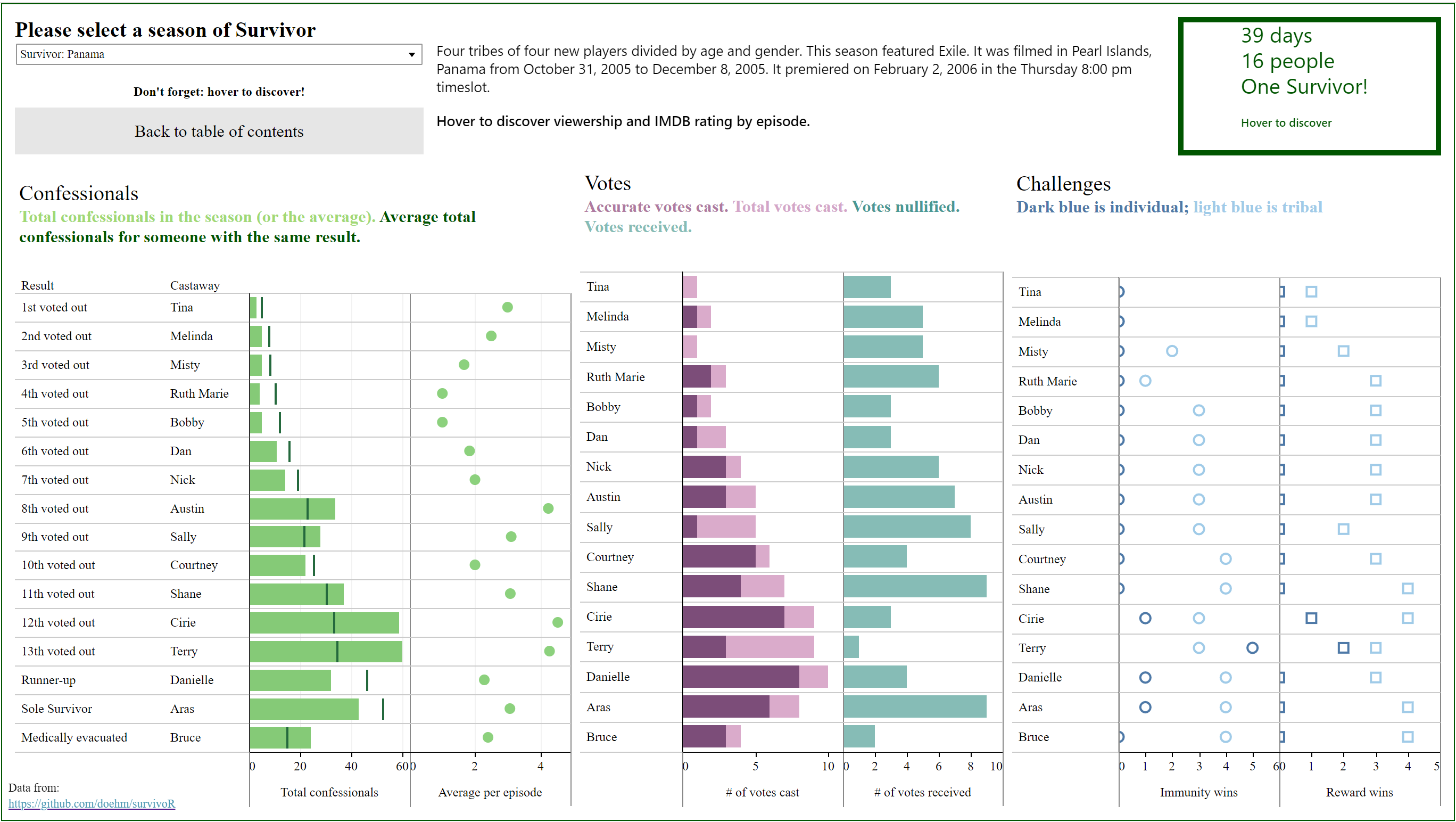
This looks at the number of immunity idols won and votes received for each winner.

A big thank you to:
- Carly Levitz for ongoing data collection and curation
- Dario Mavec for developing the face detection model for estimating total screen time
- Sam for contributing to the confessional counts
- Camilla Bendetti for collating the personality type data for each castaway.
- Uygar Sozer for adding the filming start and end dates for each season.
- Holt Skinner for creating the castaway ID to map people across seasons and manage name changes.
Data was sourced from Wikipedia and the Survivor Wiki. Other data, such as the tribe colours, was manually recorded and entered by myself and contributors.