中文 | English
本仓库为我本科设计全部代码,目标是实现一个仅通过移动设备屏幕获取信息并做出决策的智能体,其设计框架如下

生成式目标识别数据集构建方法

制作的图像数据集:GitHub - Clash-Royale-Detection-Dataset 目标识别、图像分类数据集。
YOLOv8目标检测


决策模型架构设计

离线强化学习策略与8000分AI进行实时对局(12个获胜对局-Bilibili)



我使用的推理环境:手机系统为鸿蒙、电脑系统为 Ubuntu24.04 LTS,CPU: R9 7940H,GPU: RTX GeForce 4060 Laptop,平均决策用时 120ms,特征融合用时 240ms。
电脑至少需要一块Nvidia显卡,又由于手机视频流输入必须依赖Linux内核中的V4L2,且JAX的GPU版本不支持Windows,因此本项目的验证决策部分只能Linux系统下运行。
在requirements.txt中列举了本项目所用到的Python包,但是由于使用了三种不同的神经网络框架,环境安装建议方法如下:
-
安装miniforge,创建环境
conda create -n katacr python==3.11 -
根据你的显卡驱动所支持的最高版本安装CUDA(使用
nvidia-smi查看所支持的最高版本CUDA),建议直接在conda环境中安装cuda:
conda activate katacr
conda install -c conda-forge cudatoolkit=11.8 cudnn=8.9 # or cudatoolkit=12.0 cudnn=8.9- 安装神经网络框架:
-
安装
JAX(注意:CUDA11.8的编译版本请使用pip install "jax[cuda11]==0.4.25 -f https://storage.googleapis.com/jax-releases/jax_cuda_releases.html",最新版已经不再支持CUDA11.8) -
执行
debug/cuda_avail.py查看神经网络框架是否都已支持GPU
- 安装其他依赖包:
pip install -r requirements.txt
Scrcpy的安装方法见scrcpy/doc/linux
注意:由于我使用的手机屏幕分辨率为
1080x2400高比宽为2.22,其他屏幕位置的相对参数均在该分辨率比例下确定,如果需要使用不同的分辨率,请在constant.py中修改split_bbox_params中的part{idx}_{ratio},其中idx=1,2,3分别表示右上角时间图像位置,中间竞技场和下方手牌区域,可以使用split_part.py进行调试,ratio为你的手机屏幕高比宽比例。
这里给出最佳性能双目标组合识别器,将模型权重文件放到 KataCR/runs 下,修改代码 combo_detect.py 中的识别视频文件,即可在 KataCR/logs/detection/{start-time} 下看到目标识别出的结果。
| 模型名称 | 参数下载 | 更新时间 |
|---|---|---|
| YOLOv8 x2 | detector1 v0.7.13, detector2 v0.7.13 | 2024.05.01. |
这是两个用ResNet实现的模型
| 模型名称 | 参数下载 | 备注 |
|---|---|---|
| 卡牌分类器 | CardClassification | 仅对2.6速猪卡牌进行分类 |
| 圣水分类器 | ElixirClassification | 仅对圣水数字-1,-2,-3,-4进行分类 |
三种不同决策模型的验证方法不同
| 连续动作预测模型(有Delay) | 离散动作预测模型(无Delay) | 连续动作预测全卡牌模型 | |
|---|---|---|---|
| 验证代码 | eval.py | eval_no_delay.py | eval_all_unit.py |
| 模型参数下载 | StARformer_3L__step50 DT_4L__step50 |
StARformer_no_delay_2L__step50 | StARformer_3L_pred_cls__step50 |
| 总奖励(测试20回合) | −4.7±3.1 −5.7±2.5 |
−7.5±0.8 | −5.6±2.1 |
将模型权重文件放到KataCR/logs/Policy/{model-name}中,模型验证方法如下:
cd KataCR/katacr/policy/offline
python eval.py --load-epoch 3 --eval-num 20 --model-name "StARformer_3L_v0.8_golem_ai_cnn_blocks__nbc128__ep30__step50__0__20240512_181646"
python eval.py --load-epoch 8 --eval-num 20 --model-name "DT_4L_v0.8_golem_ai_cnn_blocks__nbc128__ep20__step50__0__20240519_224135"
python eval_no_delay.py --load-epoch 1 --eval-num 20 --model-name "StARformer_no_delay_2L_v0.8_golem_ai_cnn_blocks__nbc128__ep20__step50__0__20240520_205252"
python eval_all_unit.py --load-epoch 2 --eval-num 20 --model-name "StARformer_3L_pred_cls_v0.8_golem_ai_cnn_blocks__nbc128__ep20__step50__0__20240516_125201"模型会自动点击屏幕中的几个位置进入训练师对局,当然这几个点位也是相对 2.22 分辨率高宽比设定的,自行对 sar_daemon.py 中的 def _start_new_episode(self) 函数进行修改。
YOLOv8模型的重构内容见yolov8_modify。
- 生成式数据集下载Clash-Royale-Detection-Dataset,修改build_dataset/constant.py中
path_dataset参数为本机的数据集路径。 - 生成式目标识别图像:执行build_dataset/generator.py,即可在
KataCR/logs/generation文件夹下看到生成的原图像与带目标识别的图像。 - YOLOv8训练:由于本任务识别类别数目多达150个,所以我尝试了YOLOv8检测器组合方法,每个识别器分别对不同切片大小的类别进行识别:
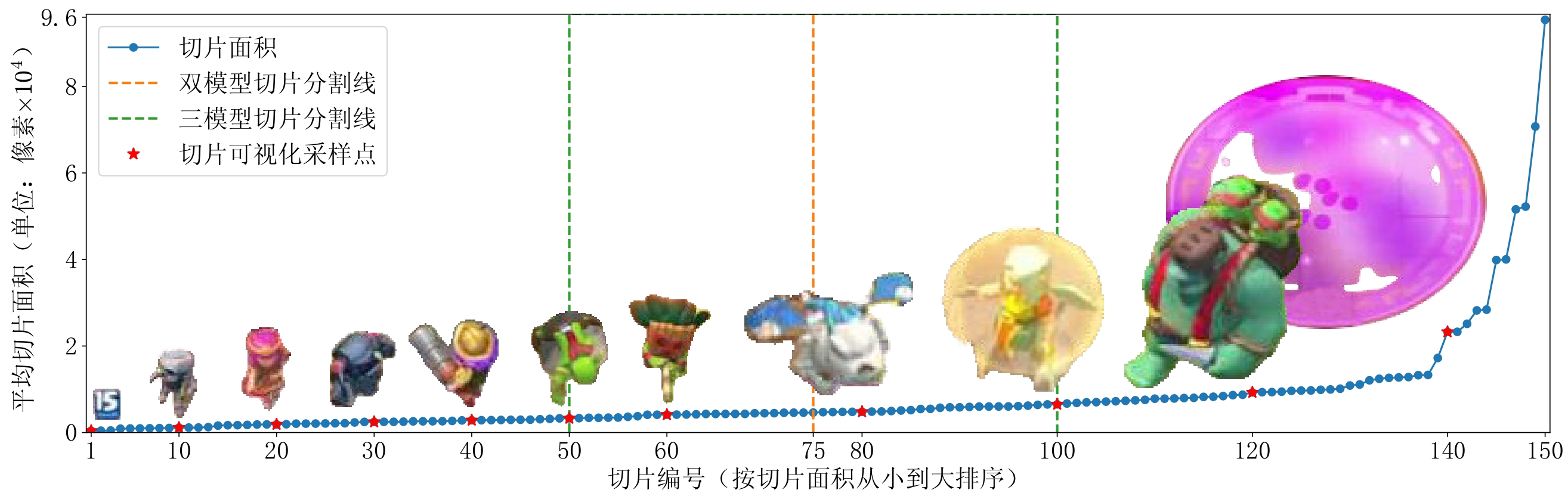 橙色和绿色虚线分别分割了双和三模型组合所需识别的切片类型,训练不同模型组合方法如下:
橙色和绿色虚线分别分割了双和三模型组合所需识别的切片类型,训练不同模型组合方法如下:
- 配置多模型参数配置文件
yolov8/cfg.py - 执行
yolov8/model_setup.py可自动在./katacr/yolov8/detector{i}下生成对应的识别器配置用于模型训练(所需识别的类别,验证集路径) - 配置
yolov8/ClashRoyale.yaml中name模型名称、deviceGPU设别编号和一些数据增强策略 - 训练:执行
yolov8/train.py对模型进行训练(本项目的训练曲线图wandb_YOLOv8) - 验证:执行
yolov8/combo_validator.py对组合模型进行验证 - 推理:执行
yolov8/combo_detect.py对组合模型进行推理(推理中可以制定目标追踪算法)
- 配置多模型参数配置文件
- 决策模型训练:
-
离线数据集制作(也可直接从Clash Royale Replay Dataset下载):
-
将原始对战视频通过
build_dataset/cut_episodes.py通过OCR识别按照回合进行划分 -
使用
build_dataset/extract_part.py将回合中的竞技场部分单独截取出来 -
使用
policy/replay_data/offline_data_builder.py进行特征融合制作出离线数据集,制作结果保存于KataCR/logs/offline/{start-time}/文件夹下 -
参考train_policy.sh中代码
(本项目的训练曲线图wandb_ClashRoyale_Policy)CUDA_VISIBLE_DEVICES=$1 \ # 指定GPU编号(只支持单卡训练) python katacr/policy/offline/train.py --wandb \ # 启用wandb在线记录 --total-epochs 20 --batch-size 32 --nominal-batch-size 128 \ # 训练参数配置 --cnn-mode "cnn_blocks" --name "StARformer_3L_v0.8_golem_ai_interval2" --pred-card-idx --random-interval 2 --n-step 50 \ # 模型参数配置 --replay-dataset "/data/user/zhihengwu/Coding/dataset/Clash-Royale-Replay-Dataset/golem_ai" # 数据集参数配置
-

build_dataset/:- 对视频文件进行预处理(划分episode,逐帧提取,图像不同部分提取)
- 目标识别数据集搭建工具(辅助标记数据集,数据集版本管理,生成式目标识别,标签转化及识别标签生成,图像切片提取)
classification/:用ResNet进行手牌及圣水分类constants:常量存储(卡牌名称及对应圣水花费,目标识别类别名称)detection:自行用JAX复现的YOLOv5模型(后弃用)interact:测试与手机进行实时交互,包括目标识别,文本识别,GUIocr_text:包括用JAX复现的CRNN(后弃用)和PaddleOCR的接口转化policy:env:两种测试环境:VideoEnv:将视频数据集作为输入,仅用于调试模型的输入是否与预测相对应InteractEnv:与手机进行实时交互,使用多进程方式执行感知融合
offline:包含了决策模型StARformer和DT的训练,验证的功能,并包含三种CNN测试结构ResNet,CSPDarkNet, CNNBlocksperceptron:感知融合:包含了state,action,reward三种特征生成器,并整合到SARBuilder中(感知基于YOLOv8,PaddleOCR,ResNet Classifier)replay_data:提取专家视频中的感知特征,制作并测试离线数据集visualization:实时监测手机图像,可视化感知融合特征
utils:用于目标检测相关的工具(绘图、坐标转化、图像数据增强),用于视频处理的ffmpeg相关工具yolov8:重构YOLOv8源码,包括数据读取、模型训练、验证、目标检测、跟踪,模型识别类型设置以及参数配置