- Designed a reinforcement learning algorithm based on AlphaGo Zero for Chinese chess playing
- Optimized the original AlphaGo Zero algorithm by 1) updating the data structure for Chinese chess games, 2) cutting off some branches of the self-play decision tree to reach deeper learning, 3) enriching the reward and punishment standards, and 4) finding a well-performed combination of different value and decision networks
- Enabled the new algorithm to surpass most human chess players
- Demos for the entire SRTP, which included 3 studies, with the chess_simulator, and chess_vision.
- Environment
Python 3.6.13
cuda 11.2
tensorflow-gpu 2.6.2
pillow 8.4.0
scipy
uvloop
- Usage
# Just play
python main.py --mode play --processor gpu --num_gpus 1 --ai_function mcts --ai_count 1
# Multiple processes train
python main.py --mode distributed_train --processor gpu --train_playout 400 --res_block_nums 9 --train_epoch 100 --batch_size 256 --mcts_num 8
# Evaluate (Compute elo)
python main.py --mode eval --processor gpu --play_playout 40 --res_block_nums 9 --eval_num 1 --game_num 10
- Self-Play & Network Training

- Real Play (Net + MCTS)

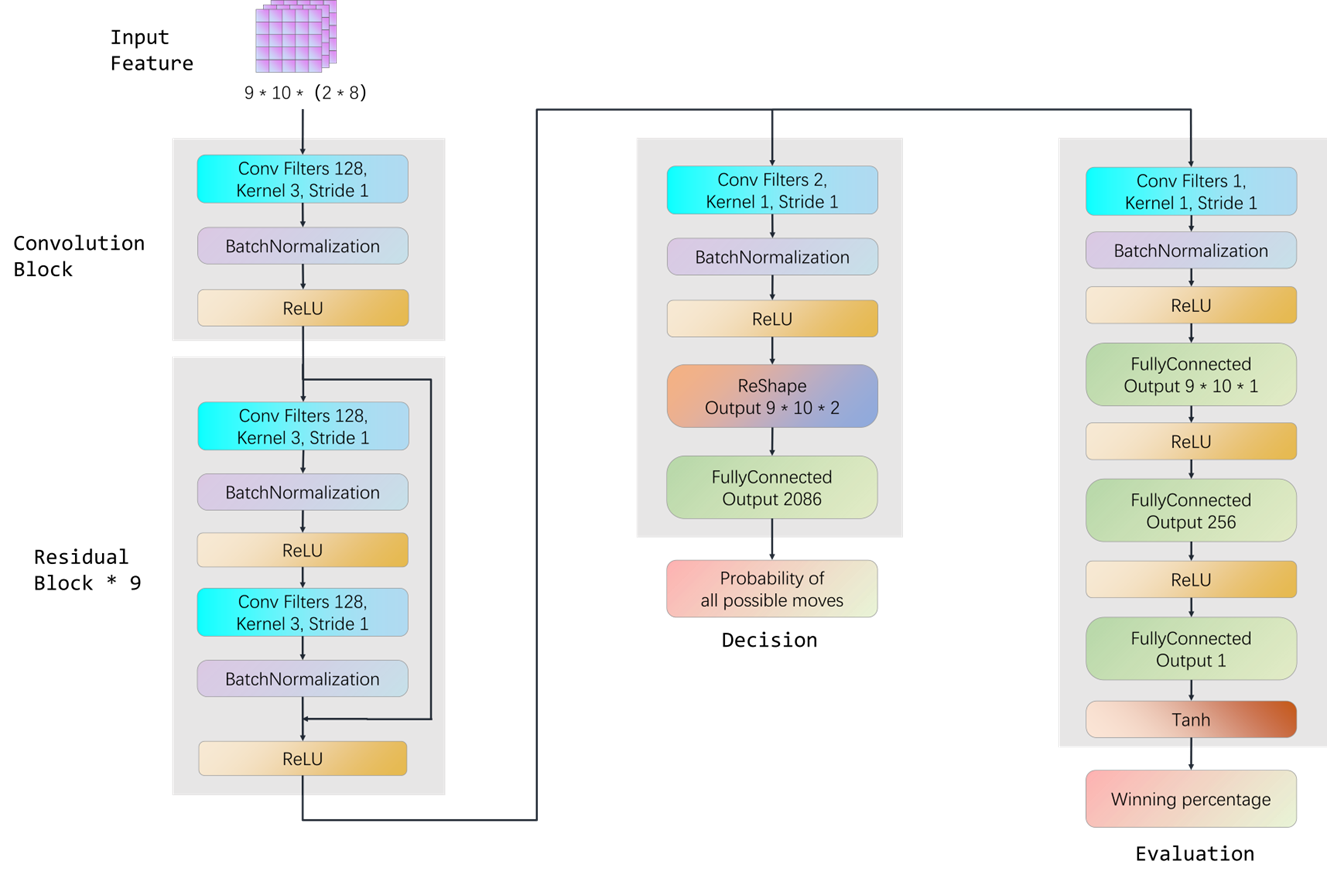
- Network Structure
[1] Silver, David, Schrittwieser, Julian, Simonyan, Karen, Antonoglou, Ioannis, Huang, Aja, Guez, Arthur, Hubert, Thomas, Baker, Lucas, Lai, Matthew, Bolton, Adrian, Chen, Yutian, Lillicrap, Timothy, Hui, Fan, Sifre, Laurent, van den Driessche, George, Graepel, Thore and Hassabis, Demis. "Mastering the game of Go without human knowledge." Nature 550 (2017): 354--.