该Repo内容为知乎专栏《机器不学习》的源代码。
专栏地址:https://zhuanlan.zhihu.com/zhaoyeyu
TensorFlow
基于RNN(LSTM)对《安娜卡列尼娜》英文文本的学习,实现一个字符级别的生成器。
实现skip-gram算法的Word2Vec,基于对英文语料的训练,模型学的各个单词的嵌入向量。
基于RNN实现歌词生成器。
基于RNN Encoder-Decoder结构的Seq2Seq模型,实现对一个单词中字母的排序。
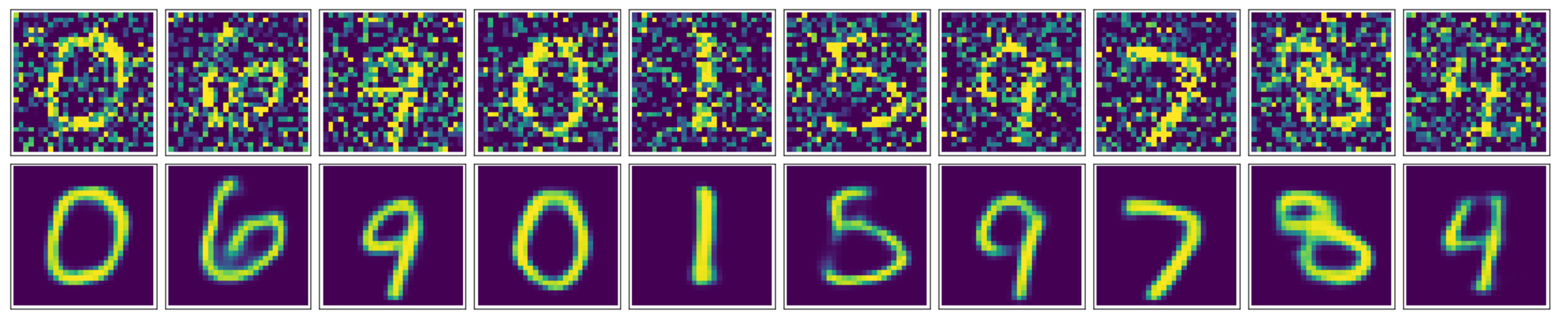
基于MNIST手写数据集训练了一个自编码器,并在此基础上增加卷积层实现一个卷积自编码器,从而实现对图像的降噪。
文章地址:利用卷积自编码器对图片进行降噪
对Kaggle上CIFAR图像分类比赛的一个实现,分别对比了KNN和卷积神经网络在数据上的表现效果。
文章地址:利用卷积神经网络处理CIFAR图像分类

基于MNIST手写数据集,训练了一个隐层为Leaky ReLU的生成对抗网络,让模型学会自己生成手写数字。

基于MNIST数据集训练了一个DCGAN,加入了Batch normalization,加速模型收敛并提升新能。
文章地址:深度卷积GAN之图像生成

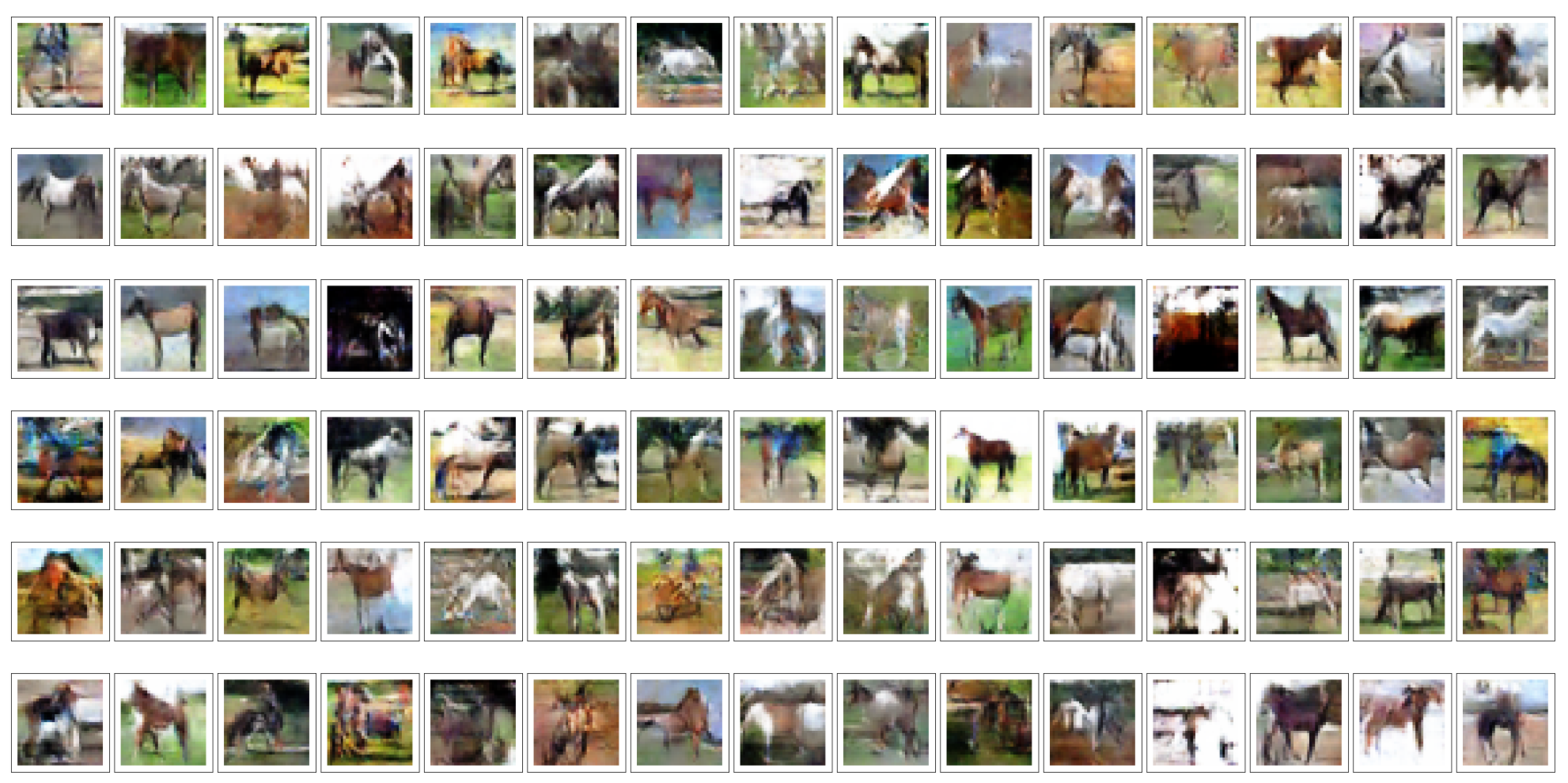
基于CIFAR数据集中的马的图像训练一个DCGAN生成马的图像。
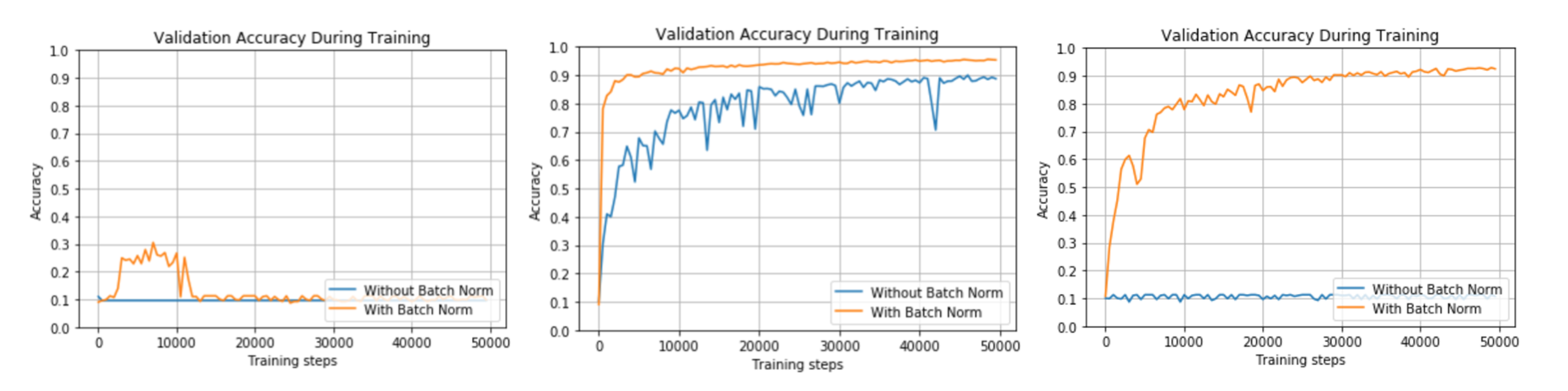
该部分代码基于MNIST手写数据集构造了一个四层的全连接层神经网络。通过改变不同参数来测试BN对于模型性能的影响。同时利用TensorFlow实现底层的batch normalization。
该代码基于TensorFlow 1.6版本的Seq2Seq构建了一个基本的英法翻译模型。
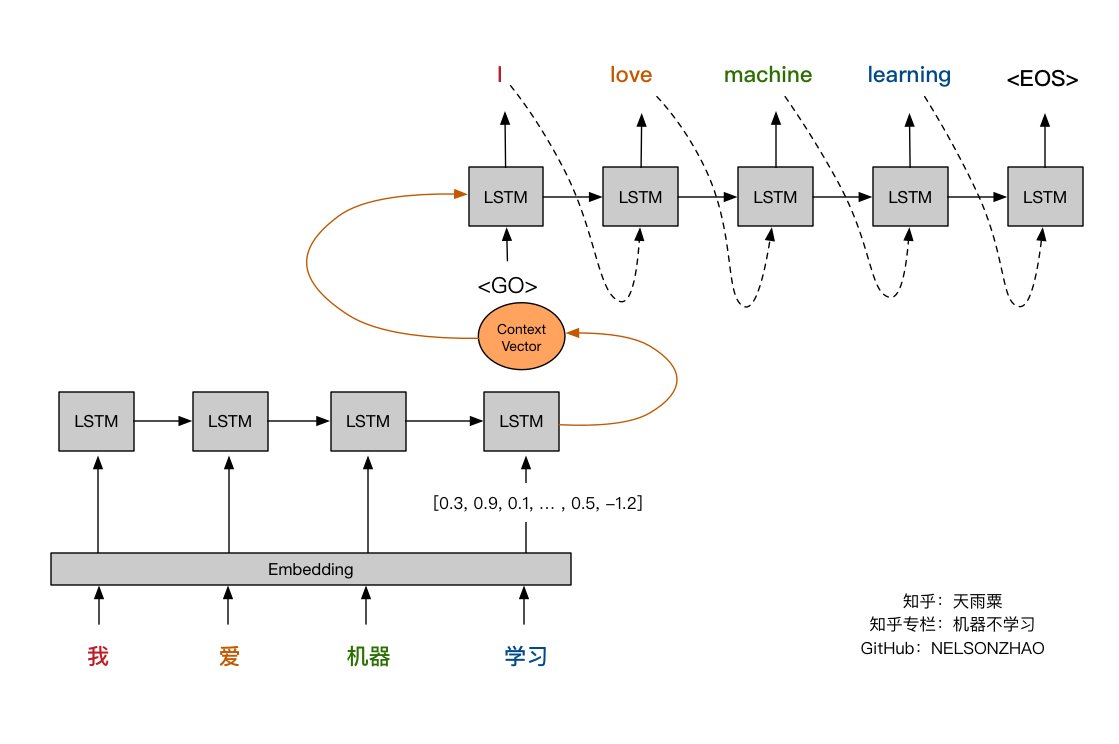
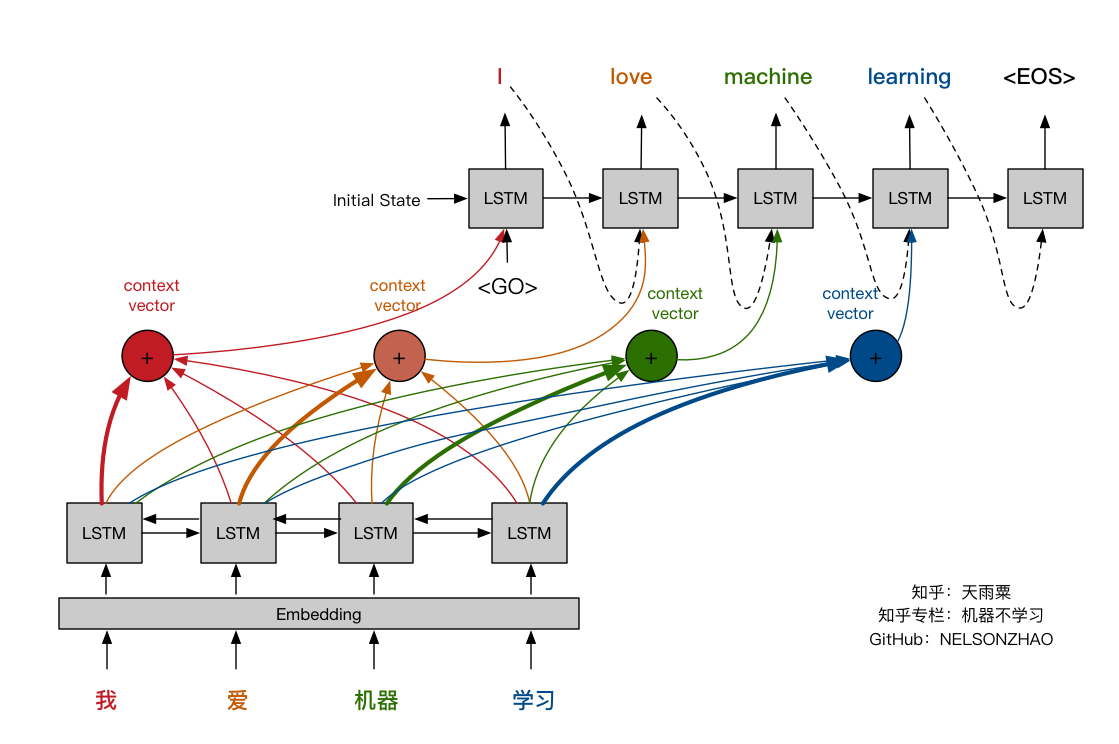
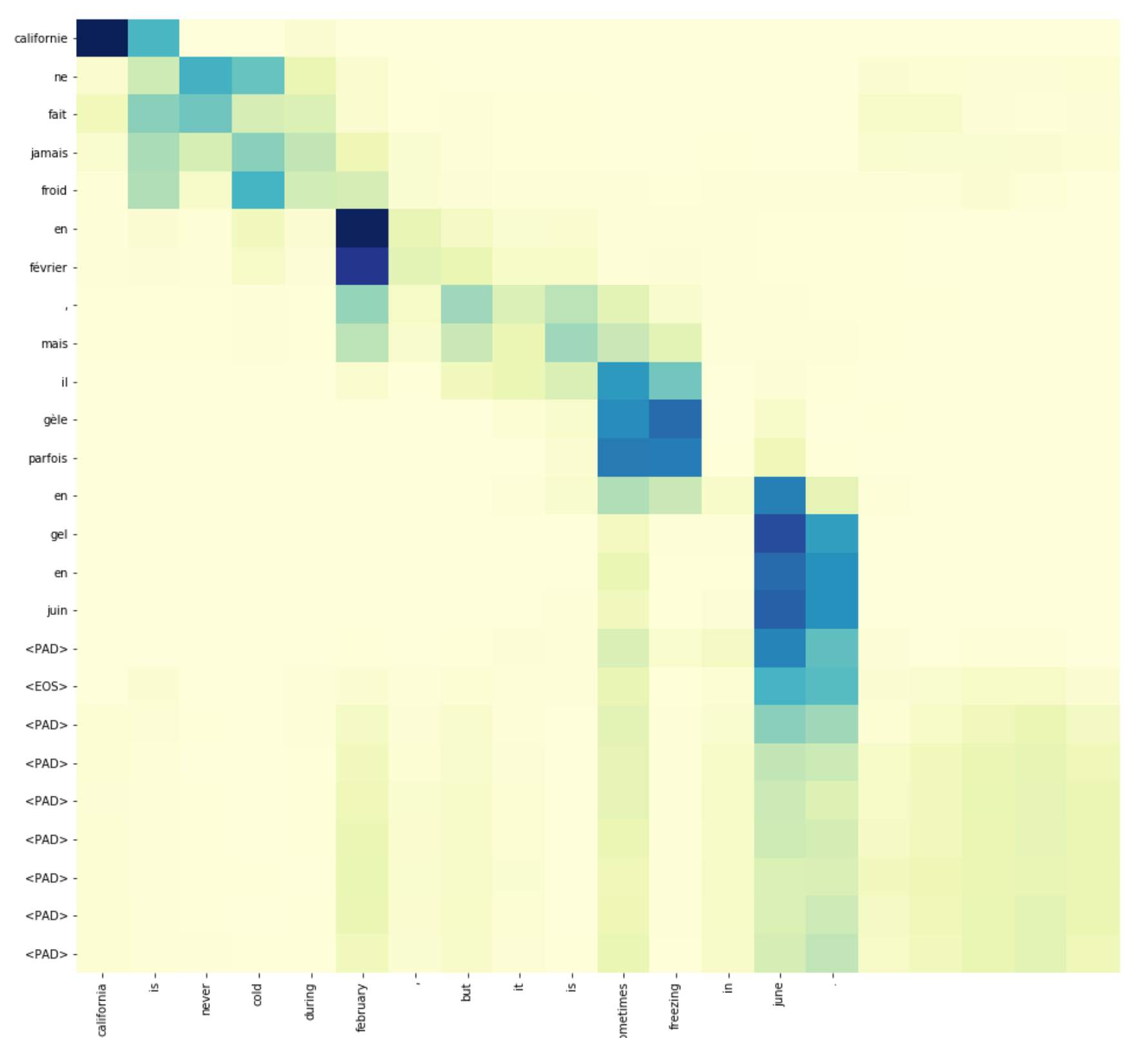
该代码基于Keras框架,在基础Seq2Seq模型基础上增加Attention机制与BiRNN,进一步提升翻译模型的效果;同时可视化Attention层,加深读者对Attention工作机制的理解。模型在在训练样本上的BLEU分数接近0.9。
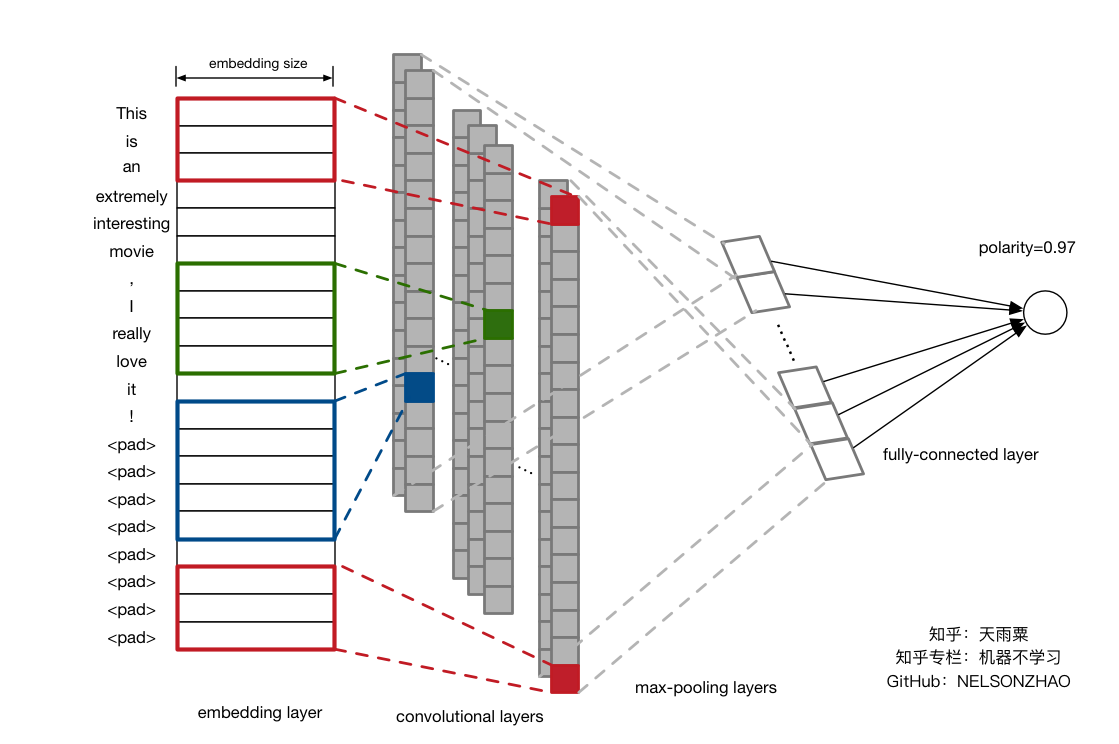
该代码基于TensorFlow 1.6版本,用DNN、LSTM以及CNN分别构建了sentiment analysis模型,并分析与比较了不同模型的性能。