As per the Ditch the Label survey, one of the world’s leading anti-bullying organizations, has provided that 42% of the people bullied on Instagram, 37% on facebook and 9% on twitter. We can use the comments available on these social media for analysing whether a person is bullied or not using sentiment analysis concept, text mining and Navie Bayes- a machine learning algorithm.
Sentiment Analysis is a branch of data science which includes contextual mining of text(also called as text mining) which identifies and extracts subjective information in source material, and thus helps a to understand the social sentiment. Sentiment Analysis or opinion mining is the process of determining whether the language reflects positive, negative or neutral sentiment.
Text analysis, here, is done using Naive Bayes Theorem, which is based on ’Bayesian Model’.It is not a single algorithm but a family of algorithms where all of them share a common principle, i.e. every pair of features being classified is independent of each other. Bayes’ Theorem finds the probability of an event occurring given the probability of another event that has already occurred. Bayes’ theorem is stated mathematically as the following equation:
P(A|B) = P(A)(P(B|A)/P(B))
where A and B are events and P(B) != 0.
- Basically, we are trying to find probability of event A, given the event B is true. Event B is also termed as evidence.
- P(A) is the priori of A. The evidence is an attribute value of an unknown instance. (here, it is event B)
- P(A /B) is a posteriori probability of B, i.e. probability of event after evidence is seen.Now, with regards to our dataset, we can apply Bayes’ theorem in following way:
P(y|X) = P(y)(P(X|y)/P(X))
where, y is class variable and X is a dependent feature vector (of size n) where: X=(x1,x2,x3,.....xn)
Steps for implemation of Naive Bayes algorithm for cyberbullying
-
Import the dataset which is in
.csvformat (named as Dataset-of-comments-of-instagram-facebook-twitter) that contains the twitter,instagram and facebook comments of users and labelled as bully or not bully. -
Data cleaning: Removing unwanted words that contribute nothing to the analysis by building corpus.
-
Tokenization: Creation of DocumentTermMatrix.The process of converting text into tokens before transforming it into vectors. For example, a document into paragraphs or sentences into words. In this case we are tokenising the reviews into words.
-
Data Visualization: Formation of wordcloud.
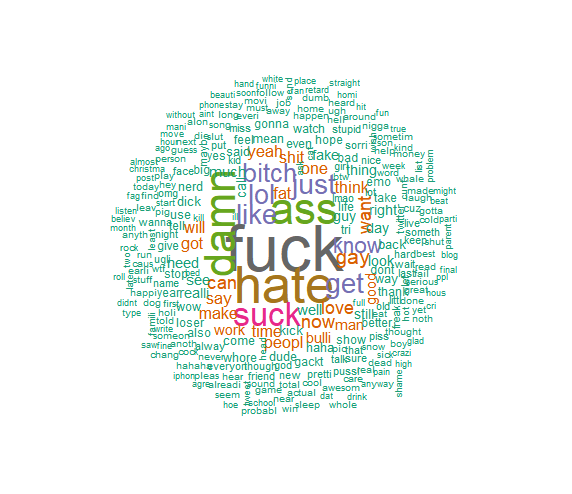
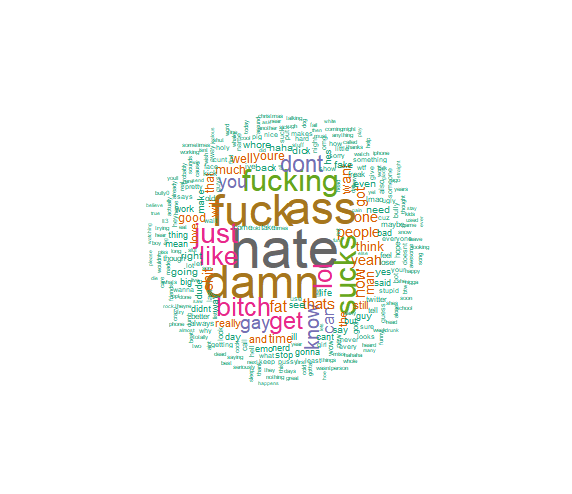
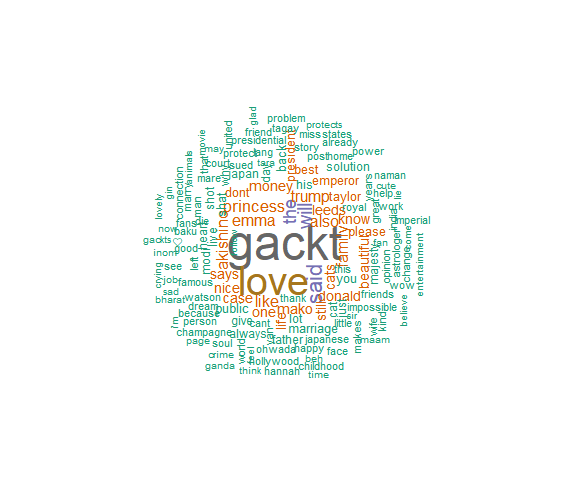
-
Divide dataset into 75% training and 25% testing
-
Apply Naive Bayes algorithm. Calculate confusion matrix.
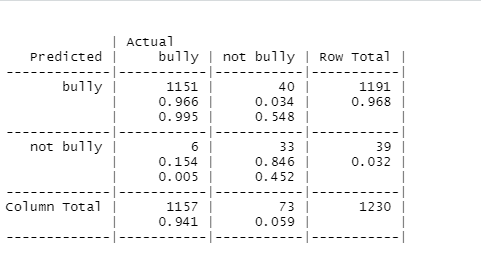
-
Display result i.e. accuracy of the model

-
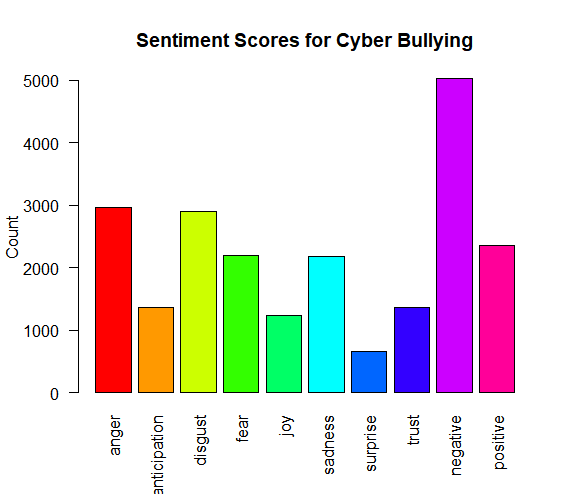
Display Sentiment Scores.






RStudio and CRAN library
- Click here to know how to install RStudio
- Before running libraries mention in the code, you need to type
install.packages()in the console. For e.g.,install.packages("tm")for loadinglibrary(tm)
From the various machine learning approaches for sentiment analysis we chose Naive Bayes algorithm. The advantage of these classifiers is that they require small number of training data for estimating the parameters necessary for classification. This is the algorithm of choice for text categorization. Naive Bayes model trains the model in less time (for small data as in our case there are no hidden layers for the probabilistic model). Naive Bayes models are comparatively better for small data which is represented in our project.
Please find the google drive link below Sentiment Analysis Using Text Mining for Cyber Bullying
Note: Sentiment Analysis.R file has code of Sentiment Scores and Cyber Bullying.R has main Sentiment Analysis using Naive Bayes algorithm.