Optical character recognition for printed text media allows for proper digitalization of print media such as magazine, newspapers, etc which can then be used for further data-processing such as sentiment analysis. Although there are already existing solutions for this problem statement, a new approach is taken in this project to evaluate its performance in a real-time environment. The model developed is also made as simple as possible in terms of memory and processing requirements so that, the model can be easily exported to run on edge devices. The new approach involves creating a new dataset that better represents printed characters as the current models use handwritten characters as their dataset. A convolutional neural network model with three stages of two consecutive convolutional blocks and a max pooling layer which is then followed by a dense layer that terminated with a softmax activation function was developed.
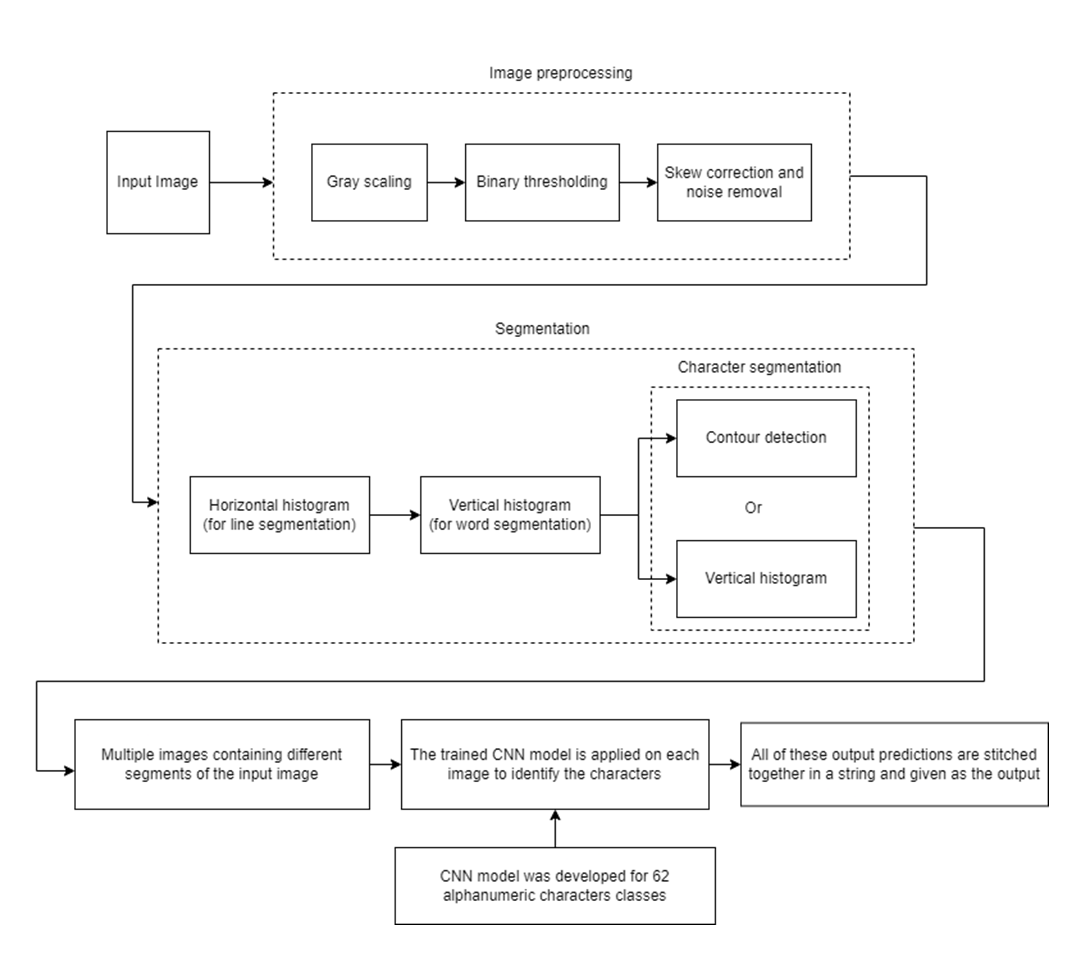
A convolutional neural network with three stages of two consecutive convolutional blocks and a max pooling layer each which is then followed by a dense layer that terminated with a softmax activation function was developed.
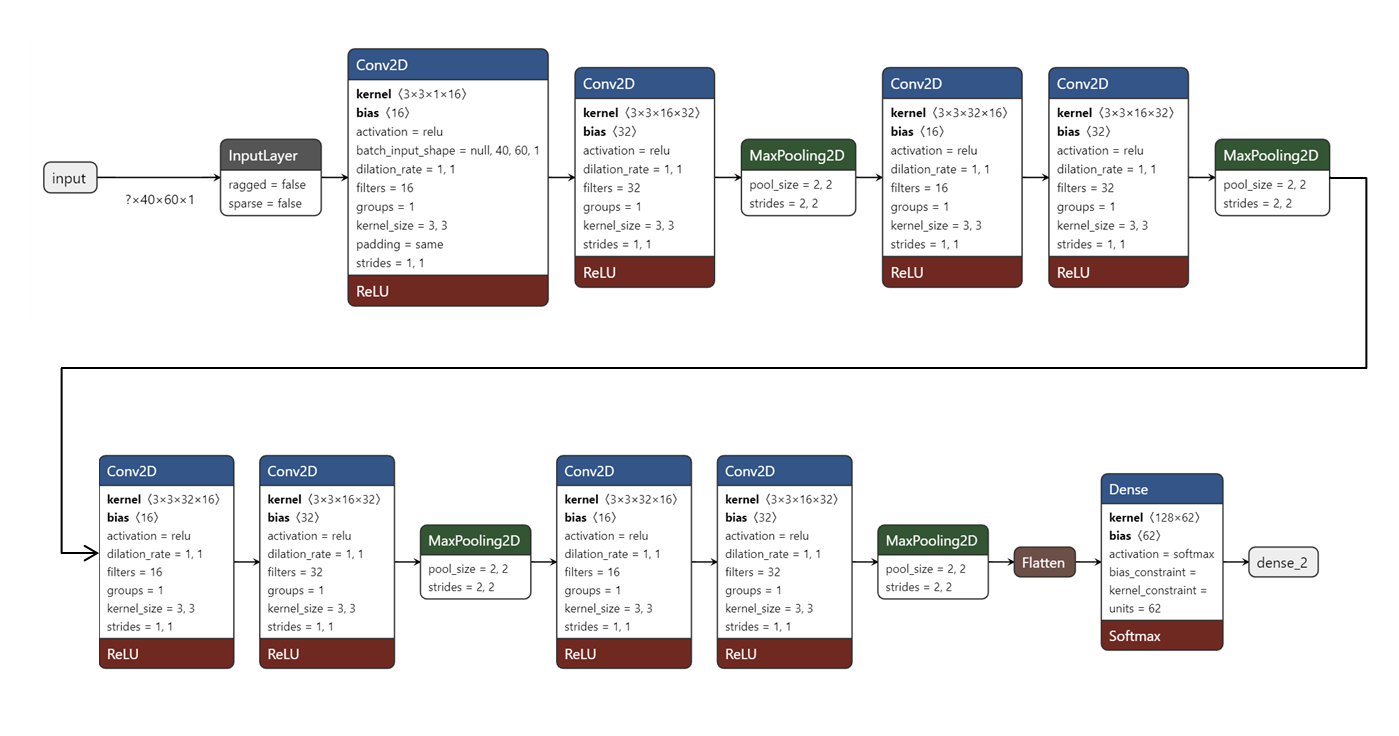
The input image is first converted to gray scale after which the single channel input image is then converted to a binary image using adaptive binary thresholding. This image is then given for skew correction which will help to align the input image horizontally. Now in segmentation, the paragraph type input image is converted to individual lines using horizontal histogram method. Once individual lines are saved as a separate image, each of these images are rotated and the same horizontal histogram is applied to obtain individual characters from the lines. Now the model developed is run on each of these images and the result is printed out as a string in the terminal.
A new dataset for printed characters were generated using all the fonts which are open-sourced at google fonts. A total of three thousand forty-five (3445) fonts were used to generate images for each of the sixty-two classes. The dataset was then analyzed and cleaned to remove unwanted data. In total two lakh and ten thousand images were generated for sixty-two classes.
Dataset can be viewed at: Kaggle - OCR_Dataset

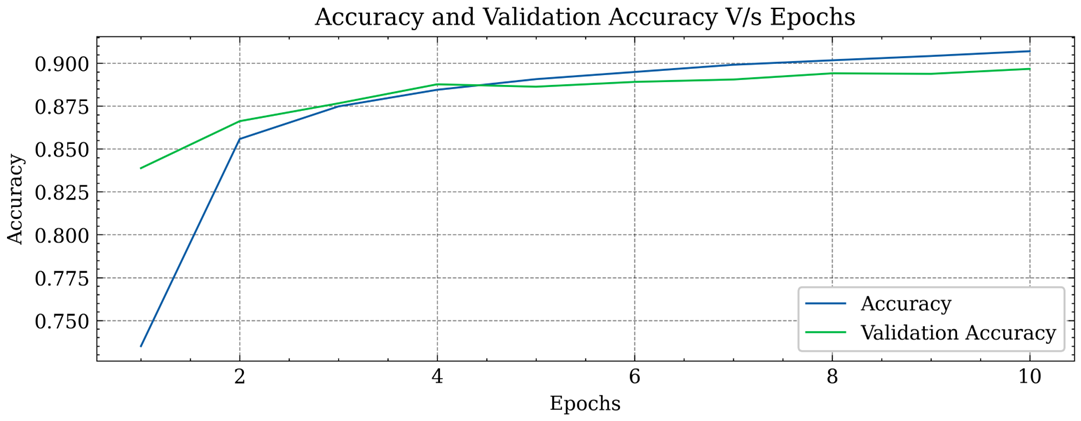
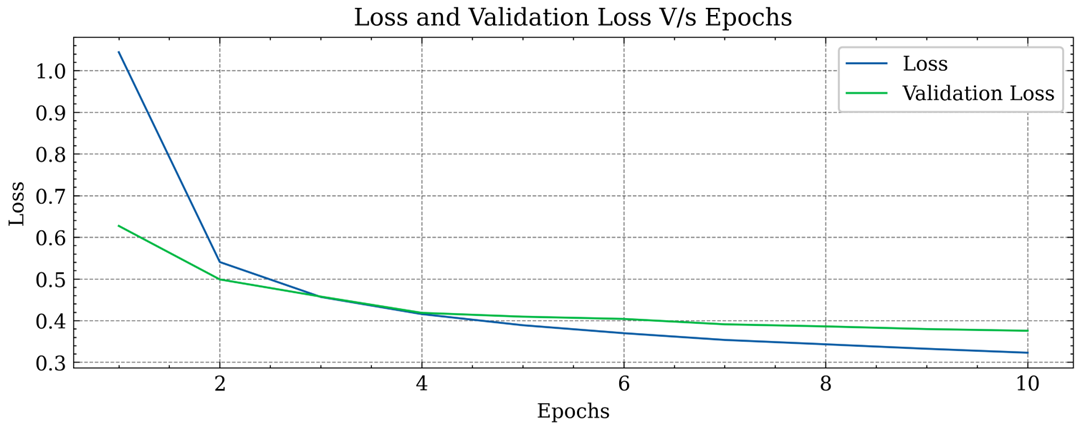
Two different versions of the model were developed, the former implemented a Double stage CNN with Max Pooling and the latter implemented Single stage CNN with Average Pooling.
| Model Architecture | Validation Accuracy (at the end of 10 epochs) |
|---|---|
| Double stage CNN with Max Pooling | 89.67 % |
| Single stage CNN with Average Pooling | 88.14 % |

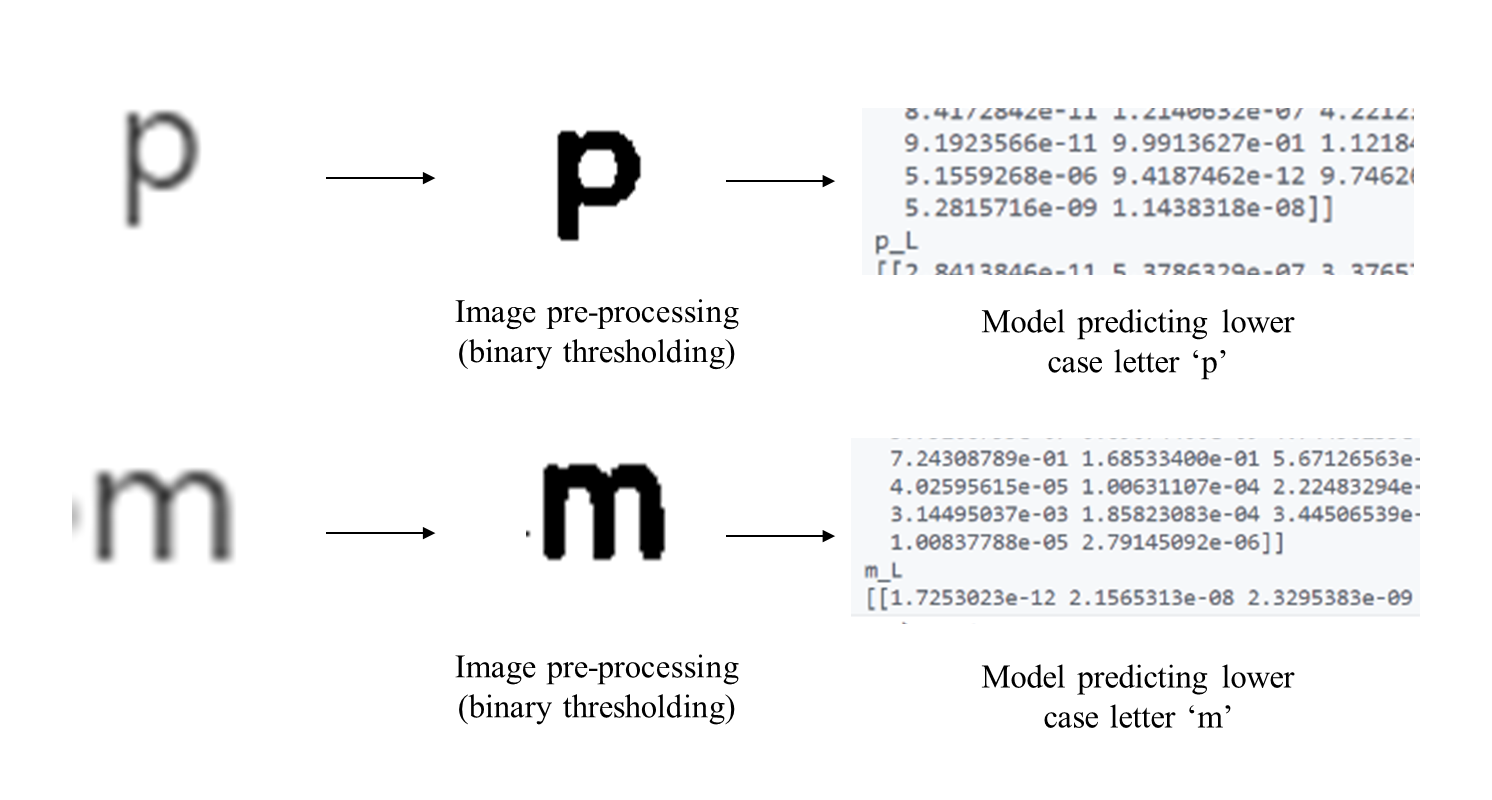
Digitalizing printed media content such as documents, magazines and newspapers using optical character recognition. These digitalized documents can be used in wide applications such as text to speech conversion (TTS), digitalizing data records.