This project aims to create a multimodal data ingestion pipeline using ImageBind to generate multimodal embeddings, and KDBAI Vector Database for storing these embeddings.
Note: We are not using any frameworks like LangChain or LlamaIndex for this project because, as of now, they do not support integration with ImageBind for handling different data types (such as PDFs, CSVs, or emails) directly as input and converting them to text.
[Paper] [Blog] [Demo] [Supplementary Video] [BibTex]
PyTorch implementation and pretrained models for ImageBind. For details, see the paper: ImageBind: One Embedding Space To Bind Them All.
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation.
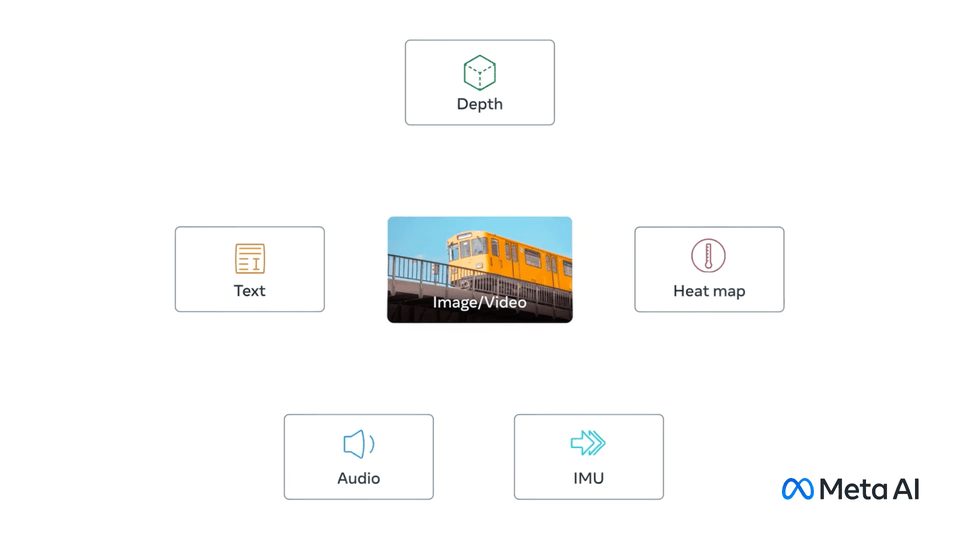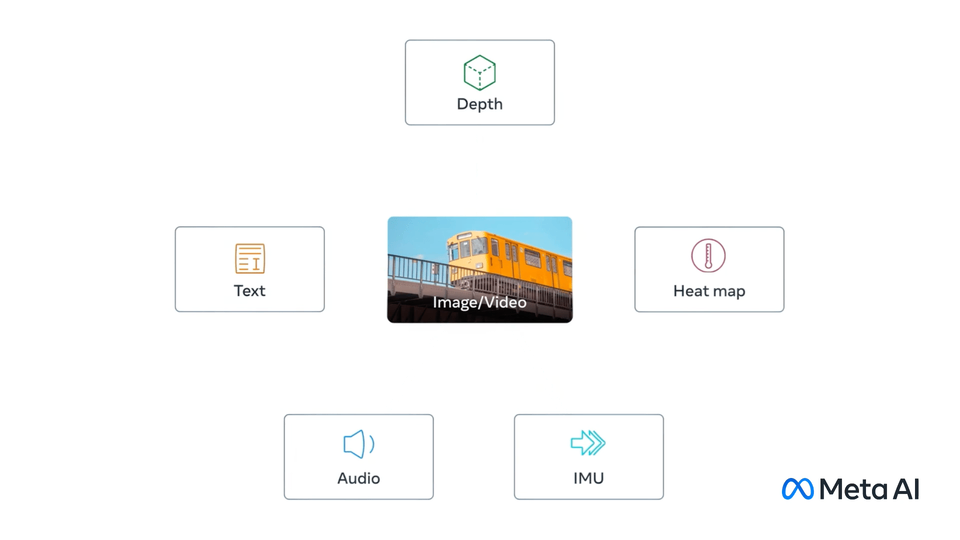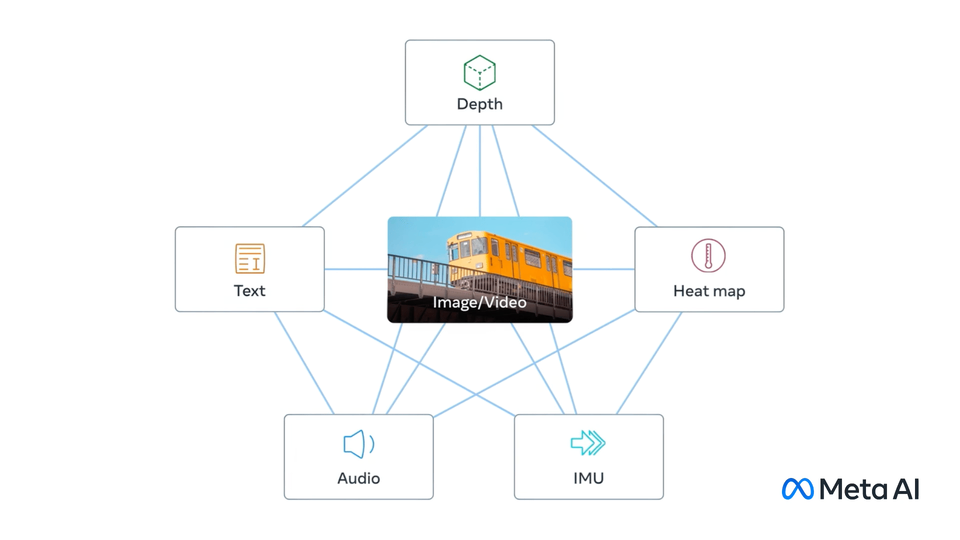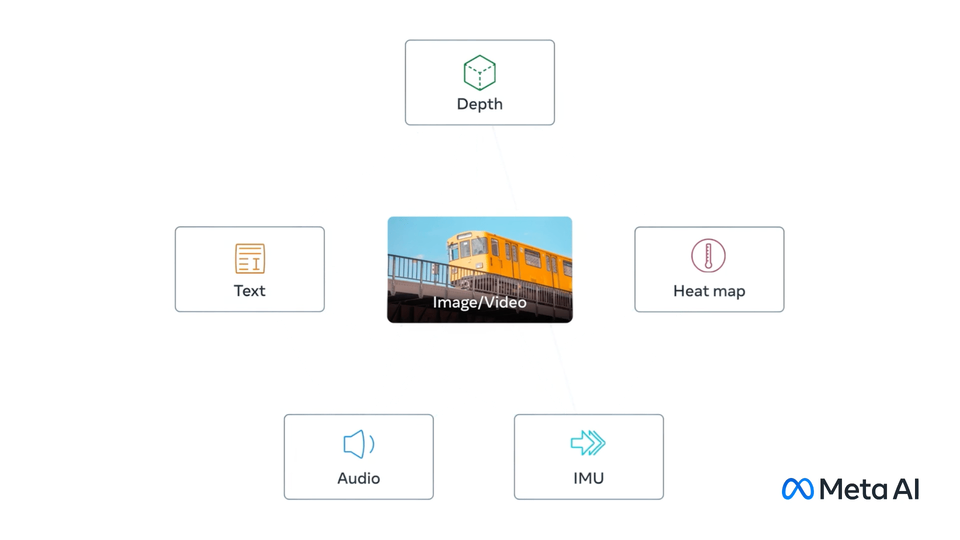
The example KDB.AI samples provided aim to demonstrate examples of the use of the KDB.AI vector database in a number of scenarios ranging from getting started guides to industry specific use-cases.
KDB.AI comes in two offerings:
- KDB.AI Cloud - For experimenting with smaller generative AI projects with a vector database in our cloud.
- KDB.AI Server - For evaluating large scale generative AI applications on-premises or on your own cloud provider.
Depending on which you use, there will be different setup steps and connection details required. You can signup at the links above and see the notebooks for connection inctructions.
KDB.AI is a vector database with time-series capabilities that allows developers to build scalable, reliable, and real-time applications by providing advanced search, recommendation, and personalization for Generative AI applications. KDB.AI is a key component of full-stack Generative AI applications that use Retrieval Augmented Generation (RAG).
Built by KX, the creators of kdb+, KDB.AI provides users with the ability to combine unstructured vector embedding data with structured time-series datasets to allow for hybrid use-cases which benefit from the rigor of conventional time-series data analytics and the usage patterns provided by vector databases within the Generative AI space.
KDB.AI supports the following feature set:
- Multiple index types: Flat, qFlat, IVF, IVFPQ, HNSW and qHnsw.
- Multiple distance metrics: Euclidean, Inner-Product, Cosine.
- Top-N and metadata filtered retrieval
- Python and REST Interfaces
First, clone the ImageBind repository from GitHub:
git clone https://github.com/facebookresearch/ImageBind.gitconda create --name imagebind python=3.10 -y
conda activate imagebindFor Windows users, you might need to install soundfile to handle reading/writing of audio files:
pip install soundfileNote:
- There may be version conflicts with Numpy. To resolve this, install the following version of Numpy:
conda install numpy=1.24- Since we are using pandas to create dataframes, install the following version to ensure compatibility with the Numpy version installed in the previous step:
pip install pandas==1.5.3The setup is done!
Next steps include creating the files myfile.py and insert_data.py.
This guide will help you set up a KDB.AI Vector Database to store and manage vector embeddings. If you do not already have a KDB.AI account, you can sign up for free at KDB.AI.
- A KDB.AI account
- Python environment with
kdbai_clientinstalled
You will need to connect to a KDB.AI session, either through the cloud (recommended) or another instance, using your KDB.AI API key and endpoint.
pip install kdbai_clientTo connect to KDB.AI, you will need your KDB.AI Cloud endpoint URL and API key. These can either be provided manually or through environment variables.
You can set the following environment variables on your system for automatic use in the code:
KDBAI_ENDPOINT: Your KDB.AI endpoint URLKDBAI_API_KEY: Your KDB.AI API key
To set these variables on your system, run the following commands (for Unix-based systems):
export KDBAI_ENDPOINT="your_kdbai_endpoint"
export KDBAI_API_KEY="your_kdbai_api_key"Once the session is created using the endpoint and API key, you can proceed with vector database operations such as creating tables, inserting data, and running queries.
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)This establishes a connection to KDB.AI, allowing you to interact with the vector database!
After successful setup of the connection with KDB.AI vector database(the steps are given below) you can run the file insert_data.py in your terminal:
python insert_data.pyNow lets explore the files 'myfile.py' and 'insert_data.py'
Note: The data files contain all the 10 files of different data types.
This Python script uses the ImageBind model to generate multimodal embeddings for different media types, including images, audio, video, PDFs, CSVs, and emails. The embeddings are stored in a pandas DataFrame, which can be later used for storage in a vector database like KDBAI for further analysis.
-
Imports:
imagebindfor generating embeddings from different modalities (text, images, audio, etc.).PyPDF2for extracting text from PDF files.mailparserfor parsing email files.pandasto store and manage the generated embeddings in a DataFrame.
-
Media Types: The script supports processing the following media types:
- Text
- Images
- Audio
- Video
- CSV
- Emails
-
Model Setup: The
imagebind_hugemodel is instantiated and set to evaluation mode to generate embeddings from input data. The model runs on a GPU (if available) or CPU. -
Embedding Generation: The function
dataToEmbeddinghandles different media types and converts them into embedding vectors using the appropriate loading and transformation functions provided byimagebind. -
Data Processing: For each media type (images, text, audio, etc.), the script:
- Loads the media file.
- Converts it into embeddings using the
dataToEmbeddingfunction. - Appends the file path, media type, and embeddings to a pandas DataFrame.
-
PDF and CSV Handling:
- PDFs are parsed using
PyPDF2to extract text from each page. - CSVs are read and converted to text format by concatenating rows for embedding generation.
- PDFs are parsed using
-
Email Handling: Emails are parsed using
mailparserto extract the email body for embedding. -
Output: The function
newFunction()returns a pandas DataFrame containing the paths, media types, and their corresponding embeddings.
Usage:
The script allows for multimodal data processing and embedding generation. These embeddings can be stored in a vector database for further analysis, making it ideal for applications involving complex multimedia data.
This Python script inserts the multimodal embeddings generated by the ImageBind model (from myfile.py) into a KDB.AI vector database. The embeddings are stored in a structured table, allowing for efficient retrieval and querying of vector data.
-
Imports:
kdbai_clientto interact with the KDB.AI vector database.myfile.pyto use thenewFunction()function that generates embeddings.dotenvto securely load API keys and environment variables.
-
Data Ingestion: The DataFrame
dfcontaining multimodal embeddings is created by callingnewFunction()frommyfile.py. -
KDB.AI Setup: The script loads the KDB.AI endpoint and API key from environment variables (
.envfile) usingload_dotenv(). -
Database Connection: A session is established with the KDB.AI database using the provided endpoint and API key.
-
Table Schema: The table schema is defined with three columns:
path: Stores the file path of the media.media_type: Stores the type of media (image, text, audio, etc.).embeddings: Stores the embedding vectors with 1024 dimensions, indexed using cosine similarity (CS).
-
Table Creation: The script ensures that any pre-existing table named
multi_modal_ImageBindis dropped, then creates a new table using the specified schema. -
Data Insertion: The DataFrame
dfis split into batches of 2000 rows for efficient insertion into the table. Thetqdmlibrary is used to display a progress bar during the insertion process. -
Querying the Database: After inserting the data, the script queries the table to explore its contents.
Usage: This script enables efficient storage and retrieval of multimodal embeddings in the KDB.AI vector database. It defines a custom schema for storing the embeddings, and the data can be queried or explored after insertion.