Project to analyse and visualize sentiment of tweets in real-time on a world map using Apache Spark ecosystem [Spark MLlib + Spark Streaming].
At a very high level, this project encapsulates and covers each of the following broad topics:
- Distributed Stream Processing » Apache Spark
- Machine Learning » Naive Bayes Classifier [Apache Spark MLlib implementation]
- Visualization » Sentiment visualization on a World map using Datamaps
- DevOps » Docker Hub and Docker Image
For more details on this project and the code associated with it, please check this blogpost.
Also, a Docker Image is available on Docker Hub with the complete environment and dependencies installed and preconfigured.
I had actually written a blog post on my personal website with the code walkthru and explaining intricate details; but unfortunately I managed to corrupt my Octopress GitHub repo. 😧 😩 😡 So, till the time I salvage it, I thought of publishing it as GitHub wiki for the time being.





- Apache Spark MLlib's implementation of Naive Bayes classifier is used for classifying the tweets in real-time.
- Training is performed using 1.6 million tweet training data made available by Sentiment140.
- Model created by Naive Bayes is applied in real-time to the tweets retrieved using Twitter Streaming API to determine the sentiment of each of the tweets.
- We also compare this result with Stanford CoreNLP sentiment prediction.
- Tweets are classified by both these approaches as:
- Positive
- Neutral
- Negative
- Please note all non-English tweets are classified as "neutral" as our training data consists of English language only tweets.
- We analyze and process and consider only the tweets which have location and discard tweets without location info.
- This is to facilitate the visualization based on the latitude, longitude info of the tweets.
- Application can also save compressed raw tweets to the disk.
- Please set
SAVE_RAW_TWEETSflag totrueinapplication.confif you want to save / retain the raw tweets we retrieve from Twitter.
- Please set
- The result of the tweet is published to Redis which is subscribed by the front-end webapp for visualization.
- Datamaps -- based on D3.js -- is used for visualization to display the tweet location on the world map with a pop up for more details on hover.
- Hover over the bubbles to see the additional info of the tweets.
- Visualization is fully responsive and scales well for any form factor. Works even on mobile.
- App adjusts if a window is resized without impacting the UX or losing the data already on the screen.
- Changes to the orientation [of a phone / tablet] does not have any impact on the app either.
- This codebase has been updated with comments, where necessary.
- Docker image hosted on Docker Hub is available with the complete environment and dependencies installed.
- Dockerfile and other supporting files are also available on GitHub.
- For detailed info on this project, please check the blogpost.
Following is the complete list of languages and frameworks used and their significance in this project.
- OpenJDK 64-Bit v1.8.0_102 » Java for compiling and execution; the VM to be precise
- Scala v2.10.6 » basic infrastructure and Spark jobs
- SBT v0.13.12 » build script and uber jar creation
- Apache Spark v1.6.2
- Spark Streaming » connecting to Twitter and streaming the tweets
- Spark MLlib » creating a ML model and predicting the sentiment of tweets based on the text
- Spark SQL » saving tweets [both raw and classified]
- Stanford CoreNLP v3.6.0 » alternative approach to find sentiment of tweets based on the text
- Redis » publishing classified tweets; subscribed by the front-end app to render the chart
- Datamaps » chart and visualization
- Python » run the flask app for rendering the front-end
- Flask » render the template for front-end
Also, please check build.sbt for more information on the various other dependencies of the project.
- A machine with Docker installed and in which you can allocate at least the following [actually the more, the merrier] to the Docker-machine instance:
- 2 GB RAM
- 2 CPUs
- 6 GB free disk space
- We will need unfettered internet access for executing this project.
- Twitter App OAuth credentials are mandatory.
- These credentials are for retrieving tweets using Twitter Streaming API.
- We will download ~1.5 GB of data with this image and SBT dependencies, etc and streaming tweets too.
If not already installed, please install Docker on your machine.
We will be using the accompanying Docker image created for this project.
- Stop docker-machine.
docker-machine stop default - Launch VirtualBox and click on settings of
defaultinstance, which should be inPowered Offstate. - Fix the settings as highlighted in the screenshots below.
- Please note this is minimum required config; you might want to allocate more.
- Increase RAM of the VM
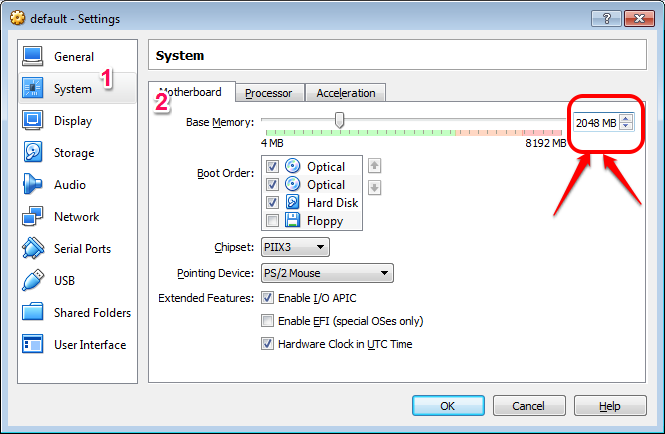
- Increase # of CPUs of the VM
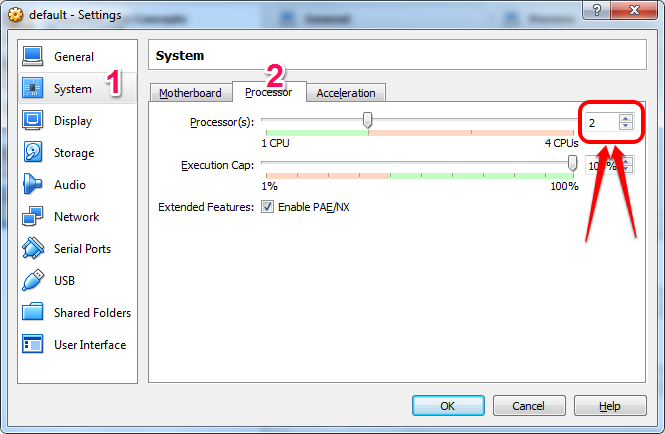
- Relaunch docker after modifying the settings.
docker-machine start default - Any Docker image you create now will have 2 GB RAM and 2 CPUs allocated.
- Or the resources you allocated earlier.


- This step will pull the Docker image from Docker Hub and runs it.
- If the image doesn't exist locally, the Docker Client will first fetch the image from the registry and then run the image.
- After image boots up and completes the setup process, you will land into a bash shell waiting for your input.
docker run -ti -p 4040:4040 -p 8080:8080 -p 8081:8081 -p 9999:9999 -h spark --name=spark p7hb/p7hb-docker-mllib-twitter-sentiment:1.6.2
Please note:
rootis the user we logged into.sparkis the container name.sparkis host name of this container.- This is very important as Spark Slaves are started using this host name as the master.
- The container exposes ports 4040, 8080, 8081 for Spark Web UI console and 9999 for Twitter sentiment Visualization.
- The only manual intervention required in this project is setting up a Twitter App and updating OAuth credentials to connect to Twitter Streaming API. Please note that this is a critical step and without this, Spark will not be able to connect to Twitter or retrieve tweets with Twitter Streaming API and so, the visualization will be empty basically without any data.
- Please check the
application.confand add your own values and complete the integration of Twitter API to your application by looking at your values from Twitter Developer Page.- If you did not create a Twitter App before, then please create a new Twitter App on Twitter Developer Page, where you will get all the required values of
application.conf.
- If you did not create a Twitter App before, then please create a new Twitter App on Twitter Developer Page, where you will get all the required values of
- Please execute
/root/exec_spark_jobs.shin the console after updating the Twitter App OAuth credentials inapplication.conf.- This script first starts Spark services [Spark Master and Spark Slave] and then launches Spark jobs one after the other.
- This might take sometime as SBT will initiate a download and setup of all the required packages from Maven Central Repo and Typesafe repo as required.
- After a few minutes of launching the Spark jobs, point your browser on the host machine to
http://192.168.99.100:9999/to view the Twitter sentiment visualized on a world map. - When a tweet is classified, a small bubble appears on world map exactly showing the location from which that tweet originated from.
- Hovering over a bubble displays the corresponding tweet's additional info:
- tweet handle
- tweet profile pic
- date tweet created
- text of the tweet
- sentiment predicted by MLlib
- sentiment as per Stanford CoreNLP
- Visualization could be completely scrapped for something better and UX needs a lot of uplifting.
- Use Spark package / wrapper for Stanford CoreNLP and reduce the boilerplate code further.
- Current prediction accuracy is ~80%. Prediction accuracy needs to be rethinked about and probably a better dataset should be used for creating the model.
- Update the project to Apache Spark v2.0.
- Push out RDDs; hello DataFrames and Datasets!
- And also use
org.apache.spark.mlpackage. - Speed gains too!
- Also processing and predicting non-English tweets too could be taken up in future.
- Add or update comments in the code where necessary.
This is a very quick recap / summary of the steps required for execution of this code.
Please consider these steps only if you are an expert on Docker, Spark and ecosystem of this project and understand clearly what is being done here.
- Install and launch Docker.
- Stop Docker and in the VirtualBox GUI, increase RAM of Docker machine [instance named
defaultand should be inPowered Offstate] to at least 2 GB [or more] and # of CPUs to 2 [or more]. - Start Docker again.
- Pull the project Docker image and launch it.
- Might have to wait for ~10 minutes or so [depending on your internet speed].
docker run -ti -p 4040:4040 -p 8080:8080 -p 8081:8081 -p 9999:9999 -h spark --name=spark p7hb/p7hb-docker-mllib-twitter-sentiment:1.6.2
- Might have to wait for ~10 minutes or so [depending on your internet speed].
- Update
application.confto include your Twitter App OAuth credentials. - Execute:
/root/exec_spark_jobs.sh- Might have to wait for ~10 minutes or so [depending on your internet speed].
- Point your browser on the host machine to
http://192.168.99.100:9999for visualization.
Please do not forget to modify the Twitter App OAuth credentials in the file application.conf.
Please check Twitter Developer page for more info.
I am currently hosting this web app on Amazon EC2: http://54.84.252.184:9999/. I will bring it down sometime next week.Update on 19th September, 2016: After running the live app on EC2 for almost a month, I have shutdown this instance today.- Docker Image on Docker Hub Registry: https://hub.docker.com/r/p7hb/p7hb-docker-mllib-twitter-sentiment/.
- GitHub URL for source code of the project: https://github.com/P7h/Spark-MLlib-Twitter-Sentiment-Analysis.
- GitHub URL for blog post on code walkthru: https://github.com/P7h/Spark-MLlib-Twitter-Sentiment-Analysis/wiki/.
- Dockerfile GitHub repo: https://github.com/P7h/p7hb-docker-mllib-twitter-sentiment.
If you find any issues or would like to discuss further, please ping me on my Twitter handle @P7h or drop me an email. Appreciate your help. Thanks!

Copyright © 2016 Prashanth Babu.
Licensed under the Apache License, Version 2.0.