An implementation of the YOLO and SSD Computer Vision Algorithms for the Classification of Images and Videos
Theoretical Topics: Computer Vision, You Only Look Once Algorithm, Single-Shot MultiBox Detector
Tools / Technologies: Python, OpenCV, NumPy, PyCharm
-
YOLO Image Classification Implementation -- YOLOImage.py
What are You Only Look Once (YOLO)?
The "You Only Look Once" (YOLO) is a family of models are a series of end-to-end deep learning models designed for fast object detection
The primary advantage of the YOLO set of models is its speed as compared to previously existing models such as CNN, Fast R-CNN, or Histogram of Oriented Gradients (HOG) approaches
In this example, we are exploring YOLO, how it works, and how to use it for image classification
Explanation
With YOLO we can combine object detection, classification/probabilities, and bounding box localization all into a singular regression problem. This is a primary advantage when compared to CNN approaches we can combine the entire model into a singular neural network as opposed to multiple smaller networks.

There are multiple components to consider when it comes to YOLO, I will go through each of them below...
-
Input and Processing
- The YOLO algorithm divides the input images into an
SxSgrid of cells - Each cell can detect up to
B=5boxes or parts of bounding boxes - Every bounding box has a center
(x,y)
The cell will predict the object where the
(x,y)center is located alongside theCprobability class (labels)
- The YOLO algorithm divides the input images into an
-
Prediction and Bounding Box
The algorithm will predict the bounding box and class and returns in the following format...
Prediction -> {x, y, w, h, confidence, class}x = horizontal value of the center of the bounding box relative to the grid celly = vertical value of the center of the bounding box relative to the grid cellw = width of the bounding box relative to the image sizeh = height of the bounding box relative to the image sizeconfidence = p(object) [probability of the given object] x IoU(prediction, ground truth)class = the highest probability predicted class for the given object, this is one-hot encoded so the return is an array in the format [0 1 0] where the second class has the highest probability
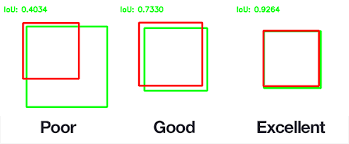
What is IoU?
Intersection over Union is a metric used to evaluate Deep Learning algorithms by estimating how well a predicted mask or bounding box matches the ground truth data
IoU = (area of intersection) / (total area of the boxes)IoU is often used as a measure of how accurate the predicted bounding box is to the ground truth bounding box label
- IoU ~ 0 -> mean error rate is large and the network makes bad predictions
- IoU ~ 1 -> mean error rate is small and the network makes good predictions
-
Non-Max Suppression
What is Non-Max Suppression?
Non-Maximum Suppression is a computer vision method that selects a single entity out of many overlapping entities (for example bounding boxes in object detection)
One of the most common problems in object detection is one object is detected multiple times. With Non-Max Suppression we can get rid of unnecessary bounding boxes.
- The algorithm first considers the bounding box with the highest probability value
- The algorithm considers all other bounding boxes and suppresses the ones that have a high IoU with the selected bounding box

-
Anchor Boxes
How do we deal with multiple objects within the same grid? Anchor Boxes!
Anchor boxes are a set of predefined bounding boxes of a certain height and width. These boxes are defined to capture the scale and aspect ratio of specific object classes you want to detect and are typically chosen based on object sizes in your training datasets.
- The center
(x,y)points of both objects lie on the same grid cell - We use anchor boxes to be able to predict and output both objects
We assign multiple anchor boxes to the same grid cell which manipulates the prediction output
This is the prediction output when dealing with a single anchor box:
Prediction -> {x, y, w, h, confidence, class}This is the prediction output when dealing with 2 anchor boxes, each set is allocated for each of the 2 objects:
Prediction -> {x, y, w, h, confidence, class, x, y, w, h, confidence, class}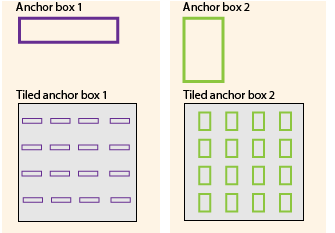
- The center
Snapshot
Below is a snapshot demonstration of the YOLO Image Classifier, in this case, a photo of cars:
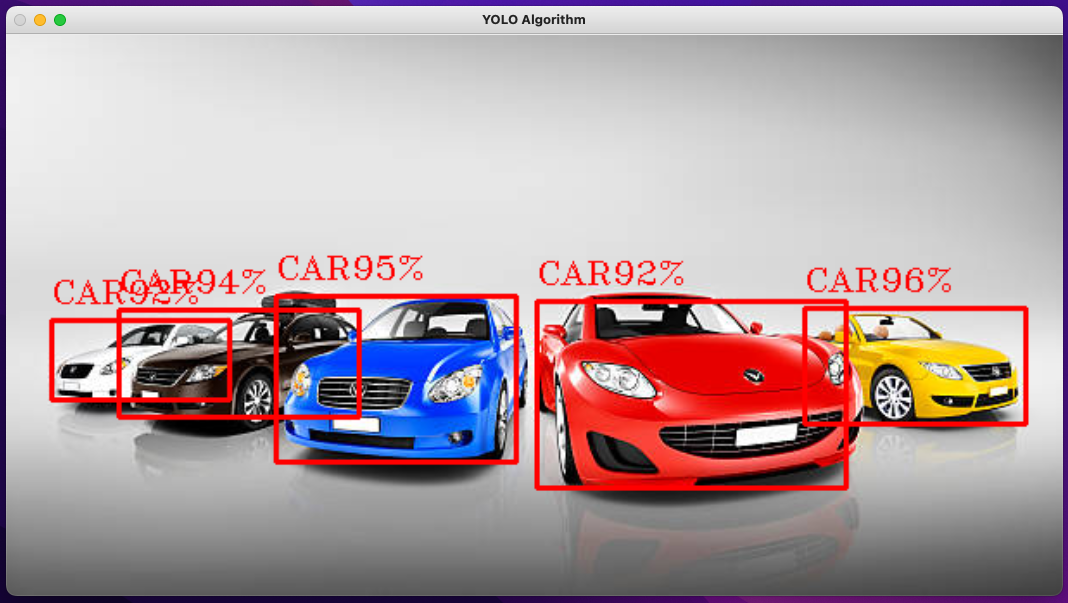
-
-
YOLO Video Classification Implementation -- YOLOVideo.py
Very similar to the YOLO Image implementation. There are just some syntax changes to help incorporate video .mp4 files rather than .jpg image files
The model itself works the same and each frame of the video is treated like an individual images
Demo
Below is a video demonstration of the YOLO Video Classifier:
-
SSD Image Classification Implementation -- SSDImage.py
What is Single-Shot MultiBox Detector (SSD)?
The Single Shot detector (SSD), similar to YOLO, takes only one shot to detect multiple objects present in an image using multi-box
The primary advantage of the SSD is that it is significantly faster in speed and high-accuracy object detection algorithm
In this example we are exploring SSD, how it works, and how to use it for image classification
Explanation
This approach is the state-of-the-art approach for object detection.
Similar to YOLO we can compress many of the steps a CNN would take into a single network
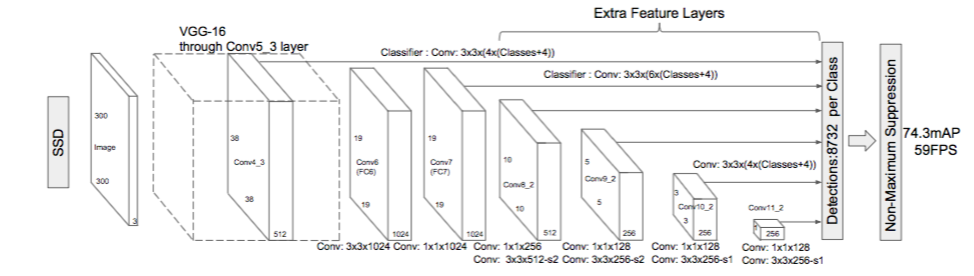
The main idea behind SSD is that several convolutional layers make predictions. Many CNN architectures can be used. In some cases VGG16 is used, however, for our code, we will use mobileNet since it is a lot more lightweight.
There are multiple components to consider when it comes to SSD, I will go through each of them below...
-
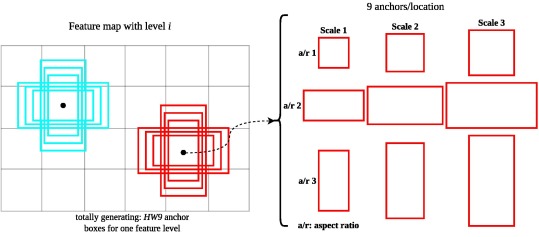
Bounding Boxes and Anchor Boxes
The bounding boxes work very similarly to YOLO, we divide the image into
SxSgrids and each grid cell is responsible for detecting objects in that regionWe still run into the problem of multiple objects in the same region and once again we will use anchor boxes, however, it is slightly different.
- We assign 6 different types of bounding boxes to every single grid cell
- During the training procedure the algorithm will choose the best one
- Vertical bounding boxes would be best for pedestrians, cups, etc.
- Horizontal bounding boxes would be best for airplanes, cars, etc.
There are several proposed bounding boxes in this approach but most don't contain an object to detect, we get rid of these bounding boxes with an IoU < 0.5. Also known as the Jakkard Index, the IoU is a common metric used in computer vision (explained above).
The anchor box with the highest degree of overlap with an object is responsible for that given objects prediction class and location
-
Feature Maps
What is a feature map?
The feature map is the output of one filter applied to the previous layer in the network
The convolutional layers decrease in size progressively and allow predictions of detections at multiple scales. Features at different layers represent different sizes of the region in the input image.
Predictions from previous layers help to deal with smaller objects.

-
Hard Negative Mining
As mentioned above a lot of the anchor boxes will not contain any actual objects. However, we don't want to get rid of all of those useless anchor boxes. Instead of using a ratio of
3:1negative:positive ratio, we keep some of the negative (useless) anchor boxes so the algorithm can learn about incorrect detections. -
Data Augmentation
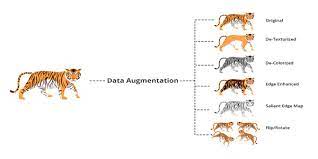
What is Data Augmentation?
Data augmentation is a technique in machine learning used to reduce overfitting when training a machine learning model, by training models on several slightly-modified copies of existing data.
- It is a good approach with the training dataset is too small
- We can generate additional training samples using data augmentation techniques (for example: flipping an image horizontally)
We also apply Non-Max Suppression here to get rid of useless bounding boxes (explained above)
Snapshot
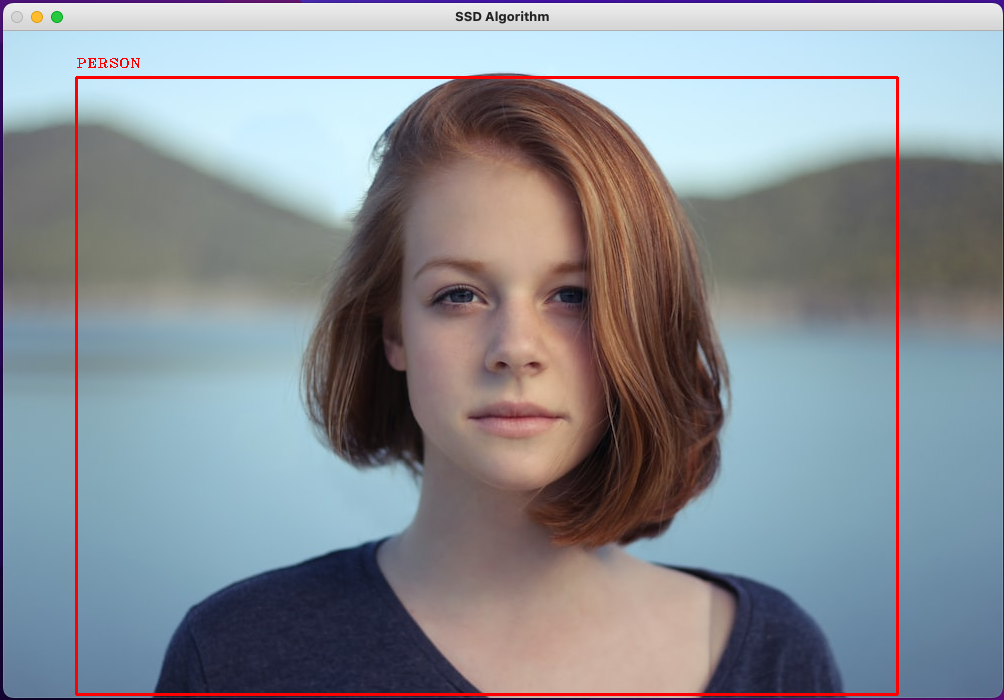
Below is a snapshot demonstration of the SSD Image Classifier, in this case, a photo of a person:
-
-
SSD Video Classification Implementation -- SSDVideo.py
Very similar to the SSD Image implementation. There are just some syntax changes to help incorporate video .mp4 files rather than .jpg image files
The model itself works the same and each frame of the video is treated like an individual images
Demo
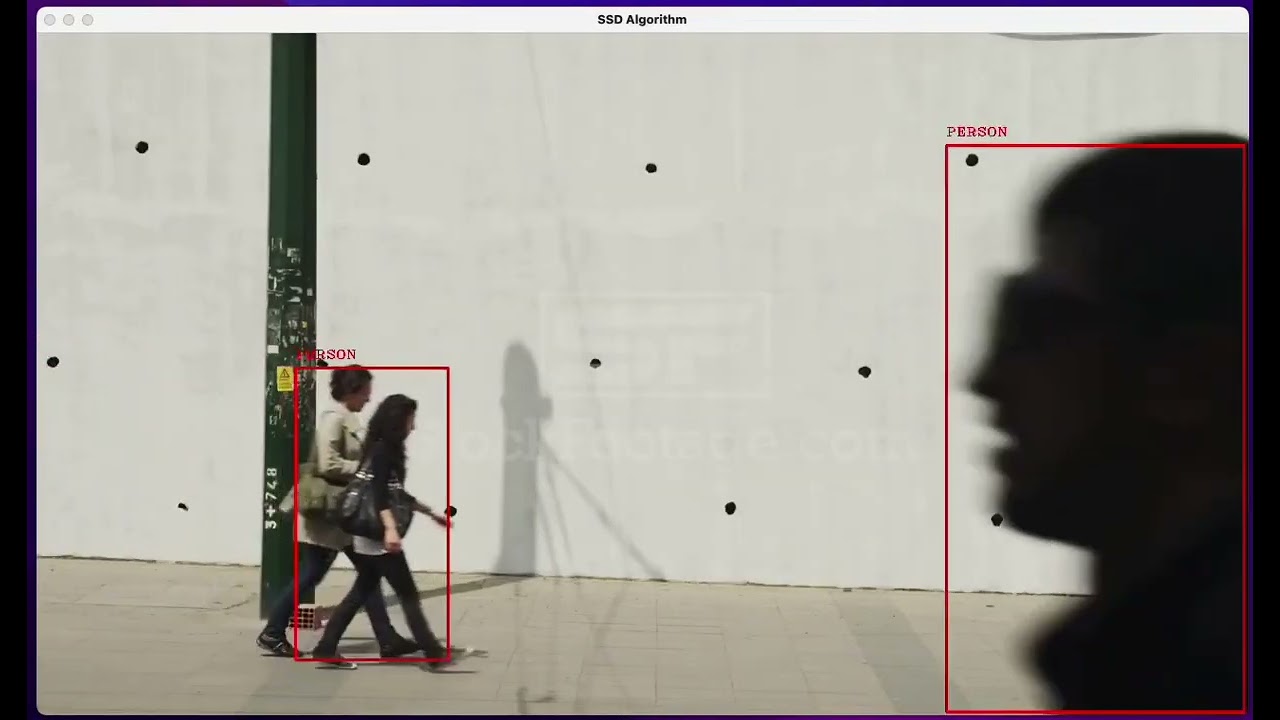
Below is a video demonstration of the SSD Video Classifier:
Note: It is much faster and smoother than YOLO, almost real-time processing.












- Expand classification classes for image implementation
- Integrate CUDA to train on GPU as opposed to CPU
- The YOLO and SSD Model requires model config files which I have not included in the repo however these can be found online
- Person Image Credit used in Demo: Person Photo
- Car Image Credit used in Demo:: Cars Photo
- Pedestrian Video Credit used in Demo:: Pedestrian Video