![]()
Programming environment for JavaScript applications, batteries included
Huncwot /huːn’tswɒt/ is a macro framework for monolithic web applications built for modern JavaScript with « batteries included » approach. It is an integrated solution that optimizes for programmers productivity by reducing choices and incorporating community conventions.
Huncwot is being built with battery included approach in mind, i.e. it comes with a (eventually large) library of useful modules which are developed in a coherent way. This stands in direct opposition to Koa approach. Huncwot tries to formalize conventions and eliminate valueless choices by providing solid defaults for building web applications that increase the programmers productivity.
The framework fights against the accidental complexity. Let's focus on business needs of our applications instead of constantly configuring, patching and putting together various software elements.
Huncwot bridges client-side (frontend) and server-side (backend) development by using a single programming language - JavaScript - across the board.
The framework draws inspiration from Rails while trying to be less magical, if
any at all. In Huncwot, you write your applications using
TypeScript. It also comes with a convenient
command toolkit (CLI) which wraps over npm scripts
As a secondary goal, Huncwot tries to minimize the dependencies. It uses external packages only if absolutely necessary (e.g. security, OS abstractions etc).
- A replacement for Express & Koa to build server-side applications
- Data-driven HTTP handler abstractions
- Use wrappers for common HTTP responses
- Conveniently set the preferred response format
- Create reusable workflows through the function composition
- Huncwot comes with a built-in REST endpoint
- Huncwot comes with a built-in GraphQL endpoint
- Huncwot can collocate GraphQL queries with Vue.js components
- Huncwot provides a data-driven router
- Application structure integrated with popular UI libraries & frameworks such as Vue.js, React, Preact or Svelte
- Argon2 as a hash function for storing passwords (instead of bcrypt or scrypt)
- A simple and efficient background processing for Node.js out of the box
- The task/job queues are handled by PostgreSQL and stored in the same database as the application itself
- CLI tools for starting the background process and scheduling tasks
- Use A SQL Query Builder instead of an ORM as SQL is one of the most valuable skills
- A SQL-like, data-driven abstractions for the database integration
- ... uses Sqorn for the database integration which provides a SQL-like abstractions right inside JavaScript
- ... supports only PostgreSQL
- ... is unwilling to support NoSQL (Thank you for your help NoSQL, but we got it from here)
Install huncwot globally to use its CLI commands which simplify frequent operations. You also need to install yarn.
npm install -g huncwot
Generate new application
huncwot new my-project
cd my-project
Start the application using the start command:
huncwot start
or with the hc alias:
hc start
Visit https://localhost:8080
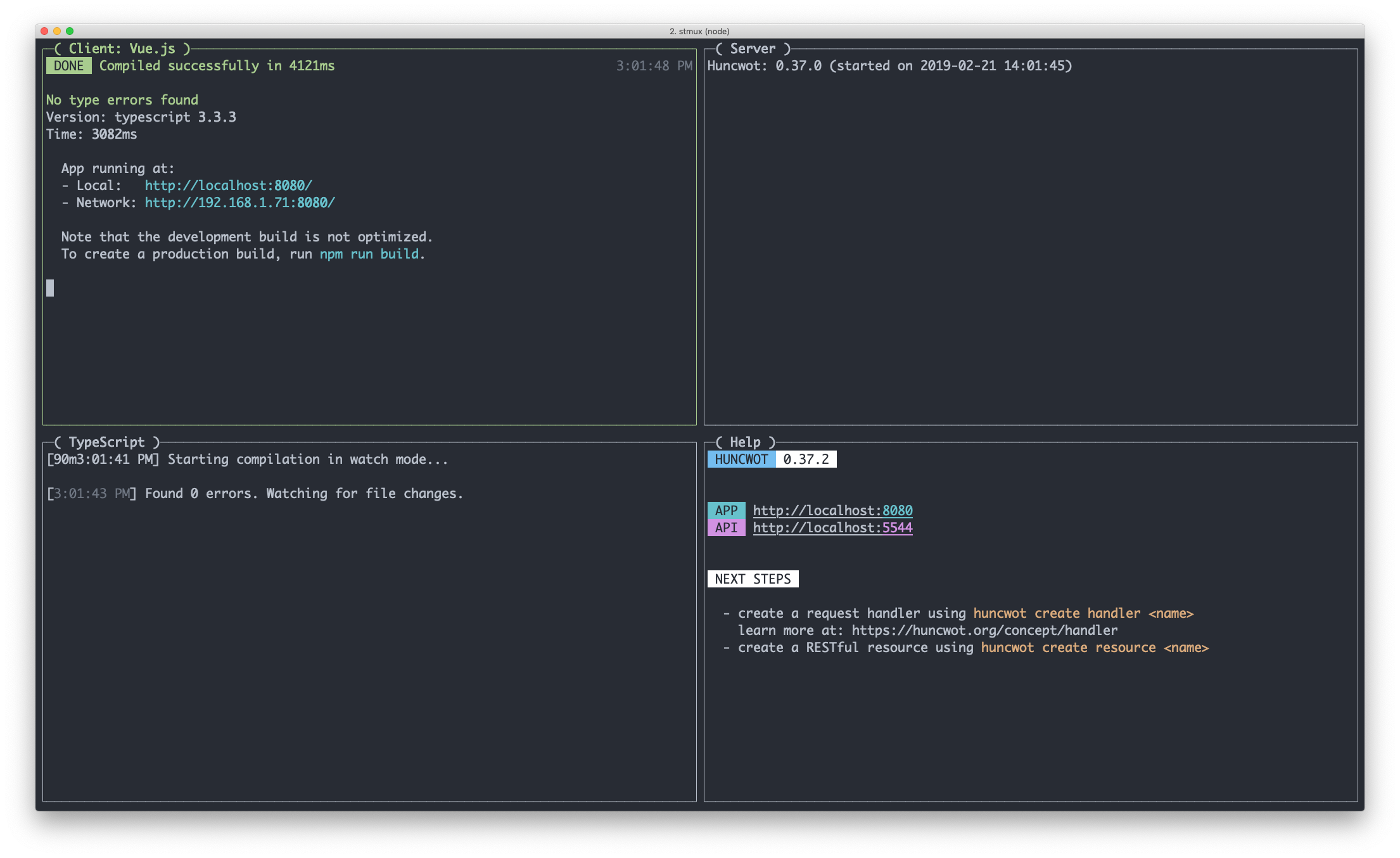
The directory structure in Huncwot is organized around your application features, and not by type. This means that artifacts, either client-side or server-side are kept together. In other words, this approach groups together entities (classes, functions) that actually work together. This leads to high modularity of your application and better cohesion.
The Folder-By-Feature approach makes it easier to find files in your application directory. It is especially visible once your project grows - folder-by-feature is a better long-term approach due its scalability.
To some extend, the Folder-By-Feature approach is similar to how recent frontend libraries and frameworks (React, Vue, etc) group together HTML, JavaScript and Stylesheets. In Huncwot, this simply goes one step further by applying a similar technique to the entire application so that it covers both frontend and backend.
bcrypt lacks memory hardness while in scrypt both, memory hardness and iteration count are tied to a single cost factor. On top of that, Argon2 won the Password Hashing Competition in 2015. It is build around AES ciphers, is resistant to ranking tradeoff attacks and more...
Contrary to Express.js (and similar frameworks), a handler in Huncwot is a one argument function. This argument is the incoming request.
// An example of a handler
const browse = request => {
return { ... } // <- the return value is used by Huncwot to create an HTTP response
}In Express, and the majority of other Node.js frameworks, handlers take two arguments. The first one is the request and the second one is the response.
In Huncwot, the response is simply everything that is being returned by the handler. This way, it may be slightly more natural to think about the process of handling requests and generating responses: handlers are functions, which take requests as their input and produce responses as their output. The response is represented as a JavaScript object which must have at least the body key.
const fetch = request => {
return { body: 'Hello, Huncwot!' }
}The return value can be a string. In that case the response is 200 OK with the Content-Type header set to text/plain, e.g.
const say = request => {
return 'This is nice'
}Usually the value returned by a handler is an object with (at least) the body property. Optionally, you can also specify the headers, statusCode or type properties. This constitutes the Handler type.
import { Handler } from 'huncwot';
const fetch: Handler = request => {
return {
body: '<h1>Hello World</h1>',
type: 'text/html',
statusCode: 200,
headers: {}
}
}Huncwot uses plain objects (a regular data structure in JavaScript) to represent HTTP responses. That's why we say it's a data-driven (and declarative) approach. This is inspired by the ring library from the Clojure community.
In some relatively rare cases, the response can be also a stream. Huncwot sets the type automatically to application/octet-stream in that event.
It would be arduous to create an object with the specific fields each time an HTTP response is needed. Huncwot provides convenient wrappers in that situation.
Instead of writing:
import { Handler } from 'huncwot';
const fetch: Handler = request => {
return {
body: '<h1>Hello World</h1>',
type: 'text/html',
statusCode: 200,
headers: {}
}
}you can use the HTMLPage wrapper and write this:
import { Handler } from 'huncwot';
import { HTMLPage } from 'huncwot/response';
const fetch: Handler = request => {
return HTMLPage('<h1>Hello World</h1>')
}Huncwot determines the preferred response format from either the HTTP Accept
header or format query string parameter, submitted by the client. The format
query parameter takes precedence over the HTTP Accept header.
Based on the preferred format, you can construct actions that handle several
possibilities at once using just the JavaScript's switch statement - no
special syntax needed.
const browse = ({ format }) => {
// ... the action body
switch (format) {
case 'html':
// provide a response as a HTML Page
return HTMLPage(...)
case 'csv':
// provide a response as in CSV format
return CSVPayload(...)
default:
// format not specified
return JSONPayload(...)
}
}Handlers can be composed from simple functions so that the shared bevahior can be extracted into reusable chunks of code. Such composition creates workflows that can contain validation, logging, profiling, permission checking or throttling.
import { validate } from 'huncwot/request';
GET: {
'/request-validation': [
validate({ name: { type: String, required: true } }),
({ params: { admin } }) =>
`Admin param (${admin}) should be absent from this request payload`
]
}In Huncwot, you can define implicit routes that are derived from the application features. These are called Resource routes and they can be configured in config/server/routes.ts under the Resources key.
Each resource expects a controller in the features/<feature name>/Controller directory. This controller consists of 1 to 5 actions that may be defined in separate files.
Let's say we have a Game feature. If we define a Game resource as described above, this configuration will implicitly generate the five following routes:
| Name | File in features/ |
HTTP Method | Default Path |
|---|---|---|---|
| Create | Game/Controller/create.ts |
POST |
/game |
| Browse | Game/Controller/browse.ts |
GET |
/game |
| Fetch | Game/Controller/fetch.ts |
GET |
/game/:id |
| Update | Game/Controller/update.ts |
PUT |
/game/:id |
| Destroy | Game/Controller/destroy.ts |
DELETE |
/game/:id |
The action names create a CBFUD acronym, an extension of CRUD approach, where we explicitly differentiate between reading a single element and reading a potentially filtered collection of elements.
Actions are responsible to connect the information received from the incoming request to underlaying data in your application (i.e. fetching/saving/updating) in order to produce a corresponding view e.g. a HTML page or a JSON payload.
There are two kinds of parameters possible in a web application: the ones that are sent as part of the URL after ?, called query string parameters; and the ones that are sent as part of the request body, referred to as POST data (usually comes from an HTML form or as JSON). Huncwot does not make any distinction between query string parameters and POST parameters, both are available in the request params object.
Huncwot provides a simple and efficient background processing in Node.js using the graphile-worker package.
The task are written in TypeScript and put by name on the task queues along with the necessary payload.
const SendEmail: Task = async input => {
const { name } = input;
console.log(`Hello, ${name}`);
}By convention, the task names in Huncwot are written in Camel Case with the first letter uppercase: think, this is a SendEmail task.
Each task must be placed in a separate file within the tasks/ directory at the root of your Huncwot project, e.g. tasks/SendEmail.ts for the task above.
This background processing mechanism is integrated directly into PostgreSQL (it requires PostgreSQL 10 or higher). You may wonder why not use Redis or something similar. The answer is simplicity. Putting the job/task queues in a relational database is minimally less performant than Redis while providing a significant convenience for the application maintenance: there is less elements to install, manage and configure when running your application.
Also, you can use SQL, a familiar interface to query about tasks & queues statuses instead of learning yet another domain specific language as, for example, in the case of Redis. Simplicity for the win.
You can run the background processing mechanism using the background command:
huncwot backgroundThere is also a convenient bg alias for that:
hc bg
From now on you can schedule tasks. The process of scheduling consists of putting the task name along with its input payload on a task queue. This is usually done from within your application in response to some activity, e.g. you send a welcome email once a user registers, etc.
Background.schedule({ task: SendEmail });For some tasks you may need to provide some input data (the payload) so that they execute properly:
Background.schedule({
task: SendEmail
payload: { to: 'admin@example.com' }
});By default the task is scheduled on a new queue, i.e. the queue name is randomly generated. This means that the worker executes tasks in parallel if there is enough throughput (CPUs).
You may need to force an execution order for certain tasks. In this case you need to schedule those tasks on the same queue so that they run serially:
Background.schedule({
task: SendEmail,
queue: Queue.for('email')
});Lastly, you can schedule tasks via the CLI. This is useful while in development to quickly test if tasks execute as planned:
huncwot background schedule <name> [payload]The name parameter is a mandatory task name, e.g. SendEmail while the payload parameter is an optional JSON payload as string.
hc bg schedule SendEmail '{ "to": "admin@example.com" }'Huncwot can be used as a replacement for Express or Koa, but it also goes beyond that by providing opinionated choices to other layers in the stack (view, ORM, etc) required to build a fully functional web application.
There are two essential ways in Huncwot to construct a web application: traditional server-side or modern component-based. Nonetheless, those two approaches can be combined in any proportion.
This is an example of a basic server-side application in Huncwot. Save it to a file e.g. server.js, run it with node server.js and visit the application https://localhost:5544.
Note Don't forget to install
huncwotby adding it topackage.jsonin your project directory followed bynpm install. If you're starting from scratch, usenpm initor (better)huncwot newdescribed below.
const Huncwot = require('huncwot');
const { OK } = require('huncwot/response');
const app = new Huncwot();
// implicit `return` with a `text/plain` response
app.get('/', _ => 'Hello Huncwot')
// explicit `return` with a 200 response of `application/json` type
app.get('/json', _ => {
return OK({ a: 1, b: 2 });
})
// set your own headers
app.get('/headers', _ => {
return { body: 'Hello B', statusCode: 201, headers: { 'Authorization': 'PASS' } }
})
// request body is parsed in `params` by default
app.post('/bim', request => {
return `Hello POST! ${request.params.name}`;
})
app.listen(5544);This example shows a regular, server-side application in the style of Express or Koa, e.g. you define various routes as a combination of paths and functions attached to it i.e. route handlers. In contrast to Express, Huncwot handlers only take HTTP request as input and always return an HTTP response: either defined explicitly as an object with body, status, etc keys, or implicitly with an inferred type e.g. text/plain or as a wrapping function e.g. OK() for 200, or created() for 201.
An ORM is at times too much to get data out of the database. Huncwot provides an thin layer of integration with various RDMBS systems using Sqorn. Thanks to this library you can write usual SQL queries, yet fully integrated with the regular JavaScript data structures.
The database configuration is stored config/database.json as a JSON document.
In order to start using the database integration you only need to require huncwot/db:
const db = require('huncwot/db');
Let's see how we can perform some basic and frequent SQL queries in Huncwot
Get all elements with all columns from widgets table; equivalent to select * from widgets:
const results = await db`widgets`;
Get all elements with all some columns from widgets table; equivalent to select id, name from widgets:
const results = await db`widgets`.return('id', 'name');
Get a single element from widgets table by id:
const result = await db`widgets`.where({ id })
Insert a single element into widgets table:
await db`widgets`.insert({ name: 'Widget 1', amount: 2 })
Insert few elements at once into widgets table:
await db`widgets`.insert([
{ name: 'Widget 1', amount: 2 },
{ name: 'Widget 2', amount: 7 },
{ name: 'Widget 3', amount: 4 }
])
Update an existing element (identified by id) in widgets table:
await db`widgets`.where({ id: 2 }).set({ name: 'Widget 22' })
If you're getting an error similar to the following one:
TypeError: '>=' not supported between instances of 'tuple' and 'str'
it means that the node-gyp is outdated. Run the following commands to solve it:
npm explore npm -g -- npm install node-gyp@latest
npm explore npm -g -- npm explore npm-lifecycle -- npm install node-gyp@latest
Huncwot keeps track of the upcoming fixes and features on GitHub Projects: Huncwot Roadmap
We use Github Issues for managing bug reports and feature requests. If you run into problems, please search the issues or submit a new one here: https://github.com/zaiste/huncwot/issues
Detailed bug reports are always great; it's event better if you are able to include test cases.