- Only perform a layer in SGX, instead of the whole network
- Larger networks
- Install opencv2 with the given script
- gcc-7 (as the sgx/Enclave/msse4) is from gcc-7; May opt to gcc-5.
Install gcc-7/g++-7
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt update
sudo apt install g++-7 -y
- Classification
- Training
- Multi-threading
| MSVC Win64 | GCC Linux64 |
|---|---|
 |
mojo is an efficient C++ CNN / DNN implementation that was built with the goal to balance usability, functionality, and speed. It is ideal for use in real-world applications.
See the mojo cnn wiki for updates on what's new.
Consisting of only a handful of header files, mojo is in portable C++ with old fashioned C tricks for optimization. If built with OpenMP and SSE3, it's speed is competitive with other CPU based CNN frameworks. Being a minimal CPU solution, it is not designed to scale over a cluster to train very deep models (for that, go with GPUs and Caffe, TensorFlow, CNTK, Torch, etc…)
The mojo cnn API provides a 'smart training' option which abstracts the management of the training process but still provides the flexibility to handle the threading and input data as you'd like (enabling real-time data augmentation). Just make a loop and pass in training samples until mojo cnn says stop. You are therefore not limited by the RAM required to hold your data. On the standard MNIST handwritten digit database, mojo's 'smart training' gives 99% accuracy in less than a minute and using only random shifts data augmentation, an accuracy of 99.71% (0.29% error) in about an hour. After a couple of hours 99.75% (0.25%) accuracy is achieved with DeepCNet type of network.
| mojo specs | |
|---|---|
| Layers | Input, Fully Connected, Convolution, Grouped Convolution, Depth Wise Convolution, Max Pool, Semi-Stochastic Pool, Dropout, Max Feature Map, Resize, Shuffle, DeepCNet, Concatenation. Read more on the wiki |
| Activations | Identity, Hyperbolic Tangent (tanh), Exponential Linear Unit (ELU), Rectified Linear Unit (ReLU), Leaky Rectified Linear Unit (LReLU), Very Leaky Rectified Linear Unitv (VLReLU), Sigmoid, Softmax |
| Solvers | Stochastic Gradient Descent, RMSProp, AdaGrad, Adam |
| Loss Functions | Mean Squared Error, Cross Entropy |
| Padding | Zero, Edge, Median Border Value |
| Training speed (1st epoch time, MINST 2 layer) | about 10 sec with smart training on CPU |
| Required external dependencies | none |
| Native Windows Support | yes |
| Mutli-core support | yes (OpenMP) |
| g++ 5.3.0/MSVC 2010/2013/2015 | yes/yes/yes/yes |
| Branching | yes |
| Multiple Inputes | yes |
| Real-time Data Augmentation | yes, random shift, rotate/scale available if linking OpenCV |
| Automatic training | yes |
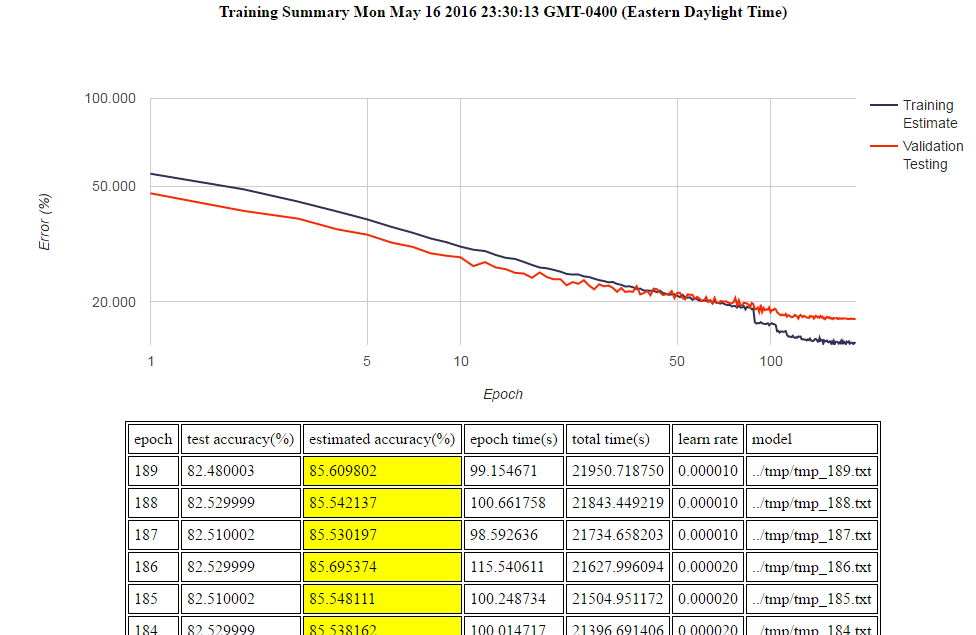
| HTML Training Log and Graphing | yes |
| GPU Support | no |
| Model Zoo | DeepCNet MNIST, DeepCNet CIFAR-10, VGG |
API Example: Load model and perform prediction:
#include <mojo.h>
mojo::network cnn;
cnn.read("../models/mojo_mnist.model");
const int predicted_class=cnn.predict_class(float_image.data());
API Example: Construction of a new CNN for MNIST, and train records with OpenMP threading:
#define MOJO_OMP
#include <mojo.h>
ucnn::network cnn("adam");
cnn.set_smart_train(true);
cnn.enable_omp();
cnn.set_mini_batch_size(24);
// add layer definitions. format : "layer_name", "layer_type params"
cnn.push_back("I1","input 28 28 1"); // MNIST is 28x28x1
cnn.push_back("C1","convolution 5 20 1 elu"); // 5x5 kernel, 20 maps, stride 1. out size is 28-5+1=24
cnn.push_back("P1","semi_stochastic_pool 4 4"); // pool 4x4 blocks, stride 4. out size is 6
cnn.push_back("C2","convolution 5 200 1 elu"); // 5x5 kernel, 200 maps. out size is 6-5+1=2
cnn.push_back("P2","semi_stochastic_pool 2 2"); // pool 2x2 blocks. out size is 2/2=1
cnn.push_back("FC1","fully_connected 100 identity");// fully connected 100 nodes
cnn.push_back("FC2","softmax 10");
cnn.connect_all(); // connect layers automatically (no branches)
while(1)
{
// train with OpenMP threading
cnn.start_epoch("cross_entropy");
#pragma omp parallel
#pragma omp for schedule(dynamic)
for(int k=0; k<train_samples; k++) cnn.train_class(train_images[k].data(), train_labels[k]);
cnn.end_epoch();
std::cout << "estimated accuracy:" << cnn.estimated_accuracy << "%" << std::endl;
cnn.write("mojo_tmp.model");
if (cnn.elvis_left_the_building()) break;
};
Here are the weights for the first convolution layer in the MNIST sample model, viewable by linking with opencv, and shown in the color maps gray, hot, tensorglow, and voodoo:




This is a training log from the sample application: