Report issue . Submit a feature
Table of Contents
TL;DR: This framework allows you to get started with an ML landing zone on AWS using native services and SageMaker models. The example in this framework uses SageMaker's prebuilt models (Scikit Learn and TensorFlow) with example data from AWS.
MLOps Toolkit is part of Firemind's Modern Data Strategy tools
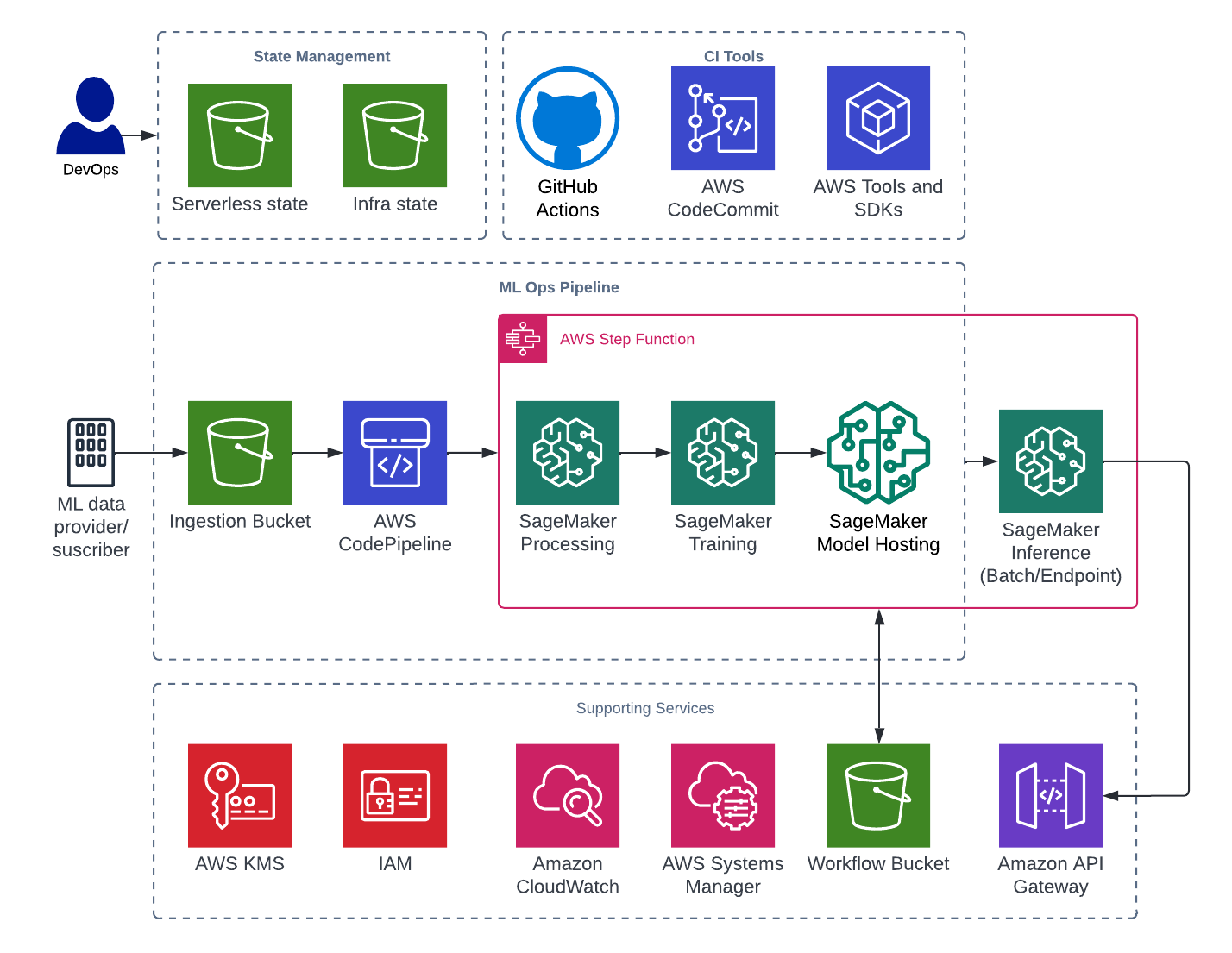
- AWS CodePipeline
- AWS Step Functions
- AWS Identity and Access Management (IAM) Roles
- AWS Key Management Service (AWS KMS)
- Amazon Simple Storage Service (Amazon S3) Buckets
- AWS Systems Manager Parameter Store (SSM) Parameters
- AWS Lambda
- Amazon SageMaker
Please complete these steps before continuing.
- Install Python 3.9 (This can be done through the installer here (where you should select a stable release for Python 3.9).
- Install NodeJs with npm (Install instructions in the official repo here.
- Install Poetry here.
Ensure your CLI has correct credentials to access the AWS account you want this framework deployed to.
To use this framework, create an empty remote repo in your organisation in GitHub, clone a copy of this repo and push to your remote.
Navigate to github-oidc-federation-template-infra.yml file and add a default value for:
GitHubOrg: This should be the name of the organisation where your repo exists.FullRepoName: The name of the repo which has a copy of this infrastructure.
Add the following to your remote repository secrets:
AWS_REGION: <e.g. eu-west-1>.S3_TERRAFORM_STATE_REGION: <e.g. eu-west-1>.S3_TERRAFORM_STATE_BUCKET: ml-core-<account_id>-state-bucket.ACTION_IAM_ROLE: arn:aws:iam::<account_id>:role/GithubActionsDeployInfra.
The first step is to deploy a GitHub Actions Role and GitHub OIDC identity provider in the account that allows you to run GitHub actions for the infrastructure.
Note: This only needs to be run once per AWS account. Details on this can be found here: https://github.com/marketplace/actions/configure-aws-credentials-action-for-github-actions
- Important Note: If an identity provider already exists for your project. Always check that the identity provider exists for your project, which can be found within the AWS IAM console.
Run the following command in the terminal. Can change the stack name and region:
aws cloudformation deploy --template-file github-oidc-federation-template-infra.yml --stack-name app-authorisation-infra-github-authentication --region {{ eu-west-1 }} --capabilities CAPABILITY_IAM --capabilities CAPABILITY_NAMED_IAM
GitHub actions is used to deploy the infrastructure.
The config for this can be found in the .gitHub/workflows
We send through a variety of different environment variables
BUILD_STAGE- We get this from the branch names.S3_TERRAFORM_STATE_BUCKET- Get this from GitHub secrets.S3_TERRAFORM_STATE_REGION- Get this from GitHub secrets.AWS_REGION- Get this from GitHub secrets.SERVICE- Has default but can be set by user in the.github/workflowsfiles.
For quick setup follow these instructions:
- Create an empty repo within your GitHub account.
- Checkout this repository on development branch to you local drive and push to your remote repo.
- Assuming the GitHub actions have been set up correctly, the deployment will begin.
If you are having any issues please report a bug via the repo.
If GitHub actions is not the preferred CI/CD of choice then you can deploy using CodePipeline. Note: After deployment of the framework you should have two pipelines: The first is the CI/CD pipeline and the second being the framework pipeline.
The Terraform resources for this CI/CD can be found in the cicd folder. The following resources are deployed:
- AWS CodePipline
- AWS CodeBuild
- AWS Identity Access Management (IAM)
- AWS Key Management Service (KMS)
- Amazon Simple Storage Service (S3)
Before deployment you must configure some values to ensure the pipeline is connected correctly to your repository.
- Firstly in
deployment-scripts/cicd-env.shyou must change these values to match your desired Repo and Branch for CI/CD : - E.g.
TF_VAR_FULL_REPOSITORY_ID="ORG_NAME/REPO_NAME" - E.g.
TF_VAR_BRANCH="development" - Optionally you can also modify TF_VAR_CICD_SERVICE
- The following variables can be optionally modified but will work if unchanged. In
deployment-scripts/quick-deploy.sh: - S3_TERRAFORM_STATE_REGION
- TF_VAR_SERVICE
- TF_VAR_BUILD_STAGE
- Finally, ensure you have the correct credentials configured in your terminal for deploying into your AWS account.
To deploy CI/CD Codepipeline, run the following command:
bash deployment-scripts/deploy-codepipeline.sh
After deployment, navigate to CodePipeline in your AWS Account and select the 'Settings' > 'Connections' section in the left navigation bar.
'github-connection' which you must update and connect to your GitHub Repo.
Note: Your GitHub User must have permissions to connect the repo to AWS through CodeStar.
Once complete, the framework pipeline is ready to use and any changes you make to this repo will be deployed though CI/CD.
To destroy the framework, run the following commands in order:
bash deployment-scripts/quick-destroy.sh
bash deployment-scripts/destroy-codepipeline.sh
The framework is currently setup to work with the following example runbook provided by AWS. More details can be found here.
- Once the infrastructure has been deployed, navigate to CodePipeline and
Release Changeon the pipeline. - The first stage will read the
manifest.jsonfile with all the configurations needs for the pipeline to run end to end.- The contents of this file is populated during the next stage but a reference to all the keys can be found in
config/manifest.json.
- The contents of this file is populated during the next stage but a reference to all the keys can be found in
- The
CreateSchemaLambda Function updates the manifest file with resolved values.- Details of these values can be found in code/lambda/create_schema under
update_payload()function.
- Details of these values can be found in code/lambda/create_schema under
- A
Manual approvalstage will prompt the user to upload the source files to the relevant location in S3.- The location in S3 will be
{workflow_bucket}{timestamp_of_execution}/source. - A sample file has been added in
sample-files/cal_housing.csvwhich can be uploaded to the above location.
- The location in S3 will be
- After approval, the
Machine Learning Step Functionis invoked with the contents of the manifest file. During this phase the following occurs:- Preprocessing of the data (
workflow/preprocess.py). - Training of data (
workflow/train.py). - Model Evaluation (
workflow/evaluation.py). - Model Hosting.
- Preprocessing of the data (
- The output for all the steps in the step function can be found in the workflow bucket
- CodePipelines next stage will prompt the user to verify the model. This can be done using the output provided by the evaluation step.
- After verification, the inference stage begins. The
UpdateSchemalambda function is invoked and modifies the manifest payload.- Modifications can be found in
code/lambda/update_schemaunderupdate_payload()function.
- Modifications can be found in
- Another prompt in CodePipeline will ask the user to verify that the inference data has been uploaded.
- The location in S3 will be
{workflow_bucket}{timestamp_of_execution}/inference - Sample file for inference can be found at
sample-files/cal_pred.csvwhich can be uploaded to the above location. - Note: This only needs to be uploaded if the EndpointType is configured to
Batchinstead ofSageMaker Endpoint. This can be configured in theupdate_schema -> update_payloadlambda function code.
- The location in S3 will be
- Finally, the Machine Learning Step Function is invoked with the new payload.
- Batch Transform Job is invoked.
- Real Time Endpoint.
- The output of inference can be found:
{workflow_bucket}{timestamp_of_execution}/inference/out.
Configure your AWS credentials in the CLI with permissions to deploy to your account.
Deploy
bash deployment-scripts/quick-deploy.sh
Destroy
bash deployment-scripts/quick-destroy.sh