This project is a basic real-time german traffic sign recognition application with deep learning techniques. It uses one camera inside the car to localize and classify the traffic sign in real time.
There are not many open training data for German traffic signs. Datasets used here are: GTSDB and GTSRB.
- Besides the accuracy, as a real-time system the speed of inference is also important. The final goal of this project is to install it on a Raspberry Pi. So the big network architecture like Inception-ResNet and the complex algorithm like Mask R-CNN may not applicable here.
- The datasets are quite small for deeplearning. GTSDB only contains 900 images (600 training images and 300 evaluation images), it is quite hard to train an end-to-end object detection system like SSD or YOLO. Although GTSRB has more images (50,000 images in total), it is only for classification, traffic signs are cropped from background images. It also only contains 43 different traffic signs, common signs like "Haltverbot", "Fußgängerüberweg" and some speed limit signs are missing.
Different than standard end-to-end object detection algorithms, in this project a pipeline is built, localization and classification tasks are handled separately.
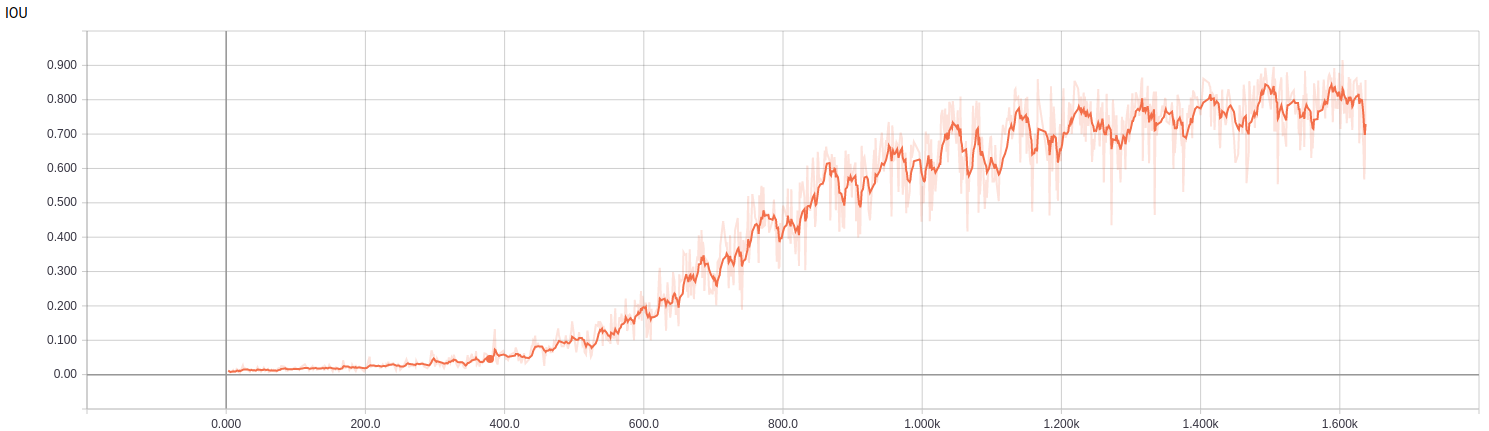
For localization U-Net, a convolutional neural network with an encoder-decoder architecture, is used. It is popular for biomedical image segmentation. Because biomedical training data are expensive and hard to get, this network works pretty well with little data. Compare with other semantic segmentation networks with dilated/atrous convolutions, it requires less resource.
This is my training result:
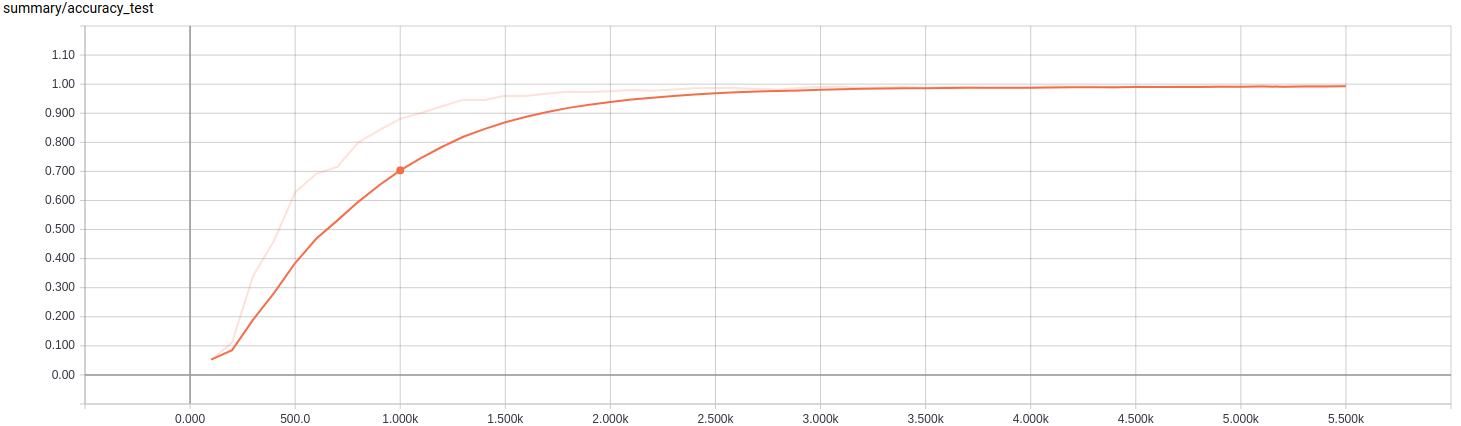
For classification a convolutional neural network calls SqueezeNet is chosen. It is famous for its small size and still good enough accuracy.
This is my training result:
- Video frames are retrieved in a worker thread (25fps), they are then sent to the U-Net, traffic sign segmentation is found and bounding boxes are calculated.
- Crops the image areas inside bounding boxes and resize it to 90x90 (keep width-height ratio and pad borders if need)
- Cropped images are sent to the classifier network, it outputs classes and confidence scores (softmax value), ignore the one with a score lower than a threshold.
- Draw bounding boxes, classes and scores on frames.
After the first implementation some issues are found:
- Some bounding boxes are marked incorrectly. It also decreases the classification accuracy.
- Bounding boxes blinks a lot.
To solve these issues, a 10x10 grid is created, the frame is then divided into 100 equal areas.
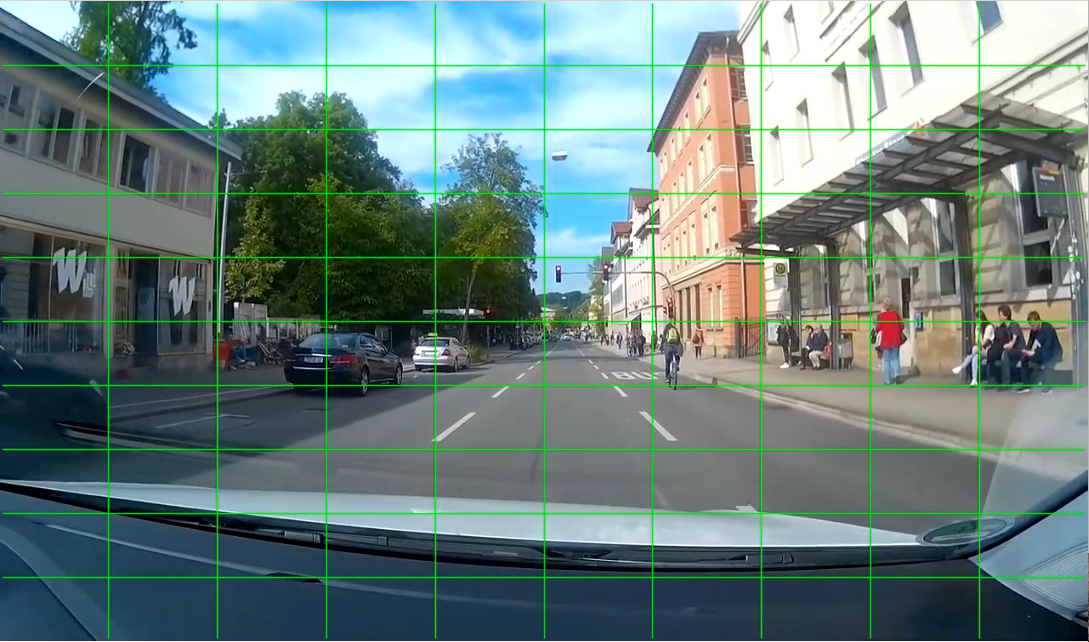
With the help of this grid, some parts of the frame are ignored, for example last two rows at the bottom because of the camera position. These areas should not contain traffic signs, it reduces some incorrect bounding boxes.
To reduce the blink effect, for each grid cell, instead of only considering the current frame, 5 recent frames are used to calculate the mode of classes and the average of confidence scores. The grid helps to identify the traffic sign instance in successive frames (with the assumption that each traffic sign belongs to the same cell in recent 5 frames and there is only one traffic sign in each cell)
The number of frames is important, if it's too large, some important frames might be lost. Actually, it should be set dynamically based on the car speed, fewer frames should be used when it is fast. Also, the grid is divided equally, a perspective grid system might be better.
At the last, too small boxes are ignored. The classifier won't work well in this case.
The video is cut from a driving lesson video Gerd Moll Onlinefahrlehrer, please ignore the white texts in the video.
Some classification error is caused by the dataset, for example there is no 40-speed limit sign in training data, they are all marked as 60 in this video.

- /src/localization/ is the training code for U-Net, it is inspirited by U-Net Implementation in TensorFlow. For training you need to download the GTSDB dataset seprately.
- /src/classification/ is the training code for SqueezeNet. For training you need to download the GTSRB dataset seprately.
- /src/object_detection_test2.py is the code for inference, its input could be an image or a video (under /src/testimg/ and /src/testvideo/). It needs the models which are trained with the scripts mentioned above. Two already trained models are included: /src/models/models_27_8/ for localization and /src/outs/my_train_classifier/ for classification.
- /src/object_detection_api/ are the utility codes I copied from the Tensorflow Object Detection API, to make them work correctly you may need to install some additional packages like protobuf: Tensorflow Object Detection API Installation
- GTSDB_label_map.pbtxt is the mapping file of label and class text
- ThreadVideoCapture.py is an utility code for video/camera multi-thread capturing.
- There are many different speed limit signs, besides including all of them into training data, a number recognizer could also be added in the pipeline. A small convolutional neural network works already pretty good for MNIST handwriting number recognition, the numbers on traffic signs are more formal, it should be easy to build such recognizer without introducing much time during inference.
- The accuracy of localization network could be improved. There is an alteration of the original U-Net design, which adds dropout layers and batch normalization. Also can try to train with other traffic sign datasets, although they are not for German traffic signs, for localization task it could be helpful.
- With additional information like the distance of the object we may distinguish them better.
- As mentioned before, the grid could be perspective and the number of frame could be dynamic.
- In general the camera does not work well in bad wetter condition and light condition.