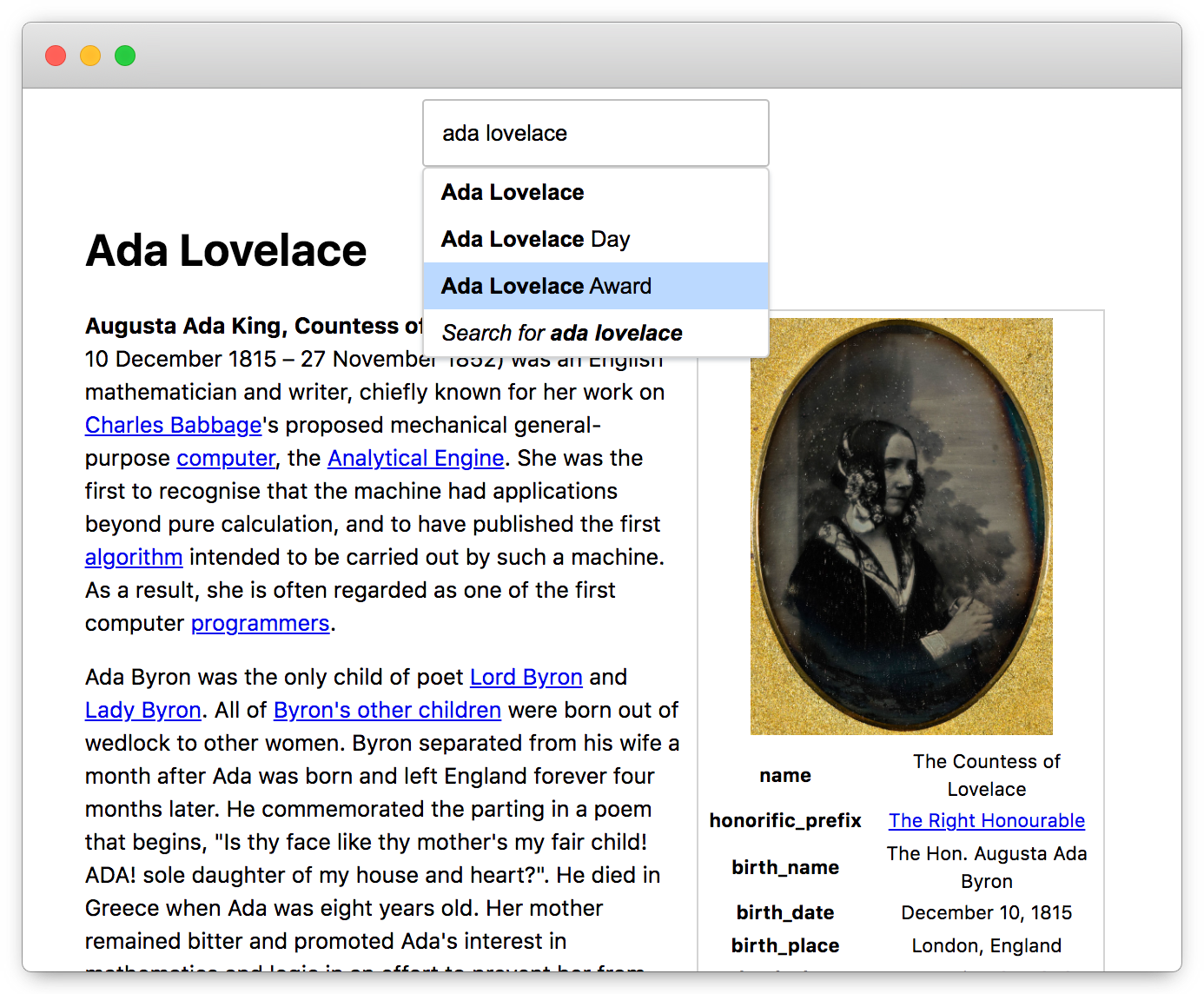
A proof-of-concept inspired and enabled by Hosting SQLite Databases on Github Pages and the ensuing Hacker News post. The compiled single-page app supports autocomplete for titles, automatic redirecting & other MediaWiki datasets like WikiQuote or Chinese Wikipedia. It makes no external API calls except to get Wikipedia's images.

Known Limitations
The compiled app is not production ready and is bandwidth intensive. It will eat your phone's data plan. Here are some other shortcomings:
Autocomplete is slow
500ms after your last keypress, the app checks if an article matches your input exactly. Then, it searches through an index of 7.3 million article titles for 3 similar matches. Improving the performance of the search requires modifying SQLite or switching to a different WASM/index altogether. See this thread for details
Autocomplete is stuck / the page won't load any more content
If your page is stuck, please try refreshing it. I could not find a way to terminate an ongoing request in the SQLite HttpVFS library.
The /search/ page always shows "no results"
This feature is currently disabled for en.db and a few others.
Article search is even slower than the autocomplete and will lead to the page crashing.
Some wikipages look funny or are incomplete
Any mediawiki syntax/wikitext that can't be easily converted to markdown is stripped out and ignored. Check out wtf_wikipedia for details around the difficulties of parsing wikitext.
Building the app
Just want the db files? Download them from Kaggle
Watch out
1. Get a wikipedia dump
Go to the wikipedia dump website and choose your desired language and the latest date.
On the index page, select the file that resembles <languageofchoice>wiki-<dateofbackup>-pages-articles-multistream.xml.bz2 and save the largest archive.
Once it's downloaded, extract the xml file from the archive. If you chose the English dump, you'll have a ~90GB uncompressed xml to play with.
2. Process the xml into a SQLite db
Run npm install in the repo.
Then, stream the xml file into the converter.
cat "/path/to/enwiki.xml" | node ./scripts/xml_to_sqlite.js /path/to/output/folder/en.db
A new SQLite file will be created at the directory and path you specified. For comparison, conversion for English wikipedia produces a 43 GB db file. It takes ~10 hours on 15" 2014 Macbook Pro and will require 100GB+ of space (excluding the xml dump file)
You can run ./scripts/sqlite3 /path/to/output/folder/en.db to see app-ready data.
3. Build the frontend assets
Run npm run build and it will compile "src/" into "dist/". See the Vite docs for more info on how SPA builds.
If you want to test the SQLite db with your local assets, you can
run npm run build and npm run serve in conjunction with a local nginx service to serve the SQLite db separately.
Check out the sample nginx.conf which, if you're on Mac, you can use to replace /usr/local/etc/nginx/nginx.conf.
Be sure to adjust the dev urls in db.js to point to your localhost-served "en.db".
But what about hot-reloading? Why can't I just drop the db file in the dist folder and execute npm run dev?
The Vite dev-server does not seem to emit the "Accept-Range" header which is required by the SQLite HttpVFS library.
npm run dev also crashes after reloading the SQLite library a few times, for some reason.
4. Deploy "dist/" and "db/" to static file hosts
Upload the dist files to your S3 bucket, github pages, surge, vercel, or any static file host. The "db/" directory must be uploaded to a CORS friendly host that supports/emits an "Accept-Range" Header. Setting up cross-domain CORS on a static host is a real pain so I've included sample CORS config for S3 as a point-of-reference.
Finally, adjust the production urls in db.js. With that, your app should be ready to be deployed.
5. Repeat for other wikimedia dumps
If you want to try other dbs, just follow steps 1-4 and add them to db.js.
Questions around the code
Why did you build this?
I wanted to play around with the SQLite HttpVFS library. I got carried away with the wikipedia part.
Why not just build 6 million html files without SQlite?
Static files work well for rendering content. Discoverability demands a separate lookup index and search index. You might be able to build those indexes with JSON / your own code; I found SQLite-HttpVFS to be pretty easy to reason about.
Are the articles converted to real markdown?
Nope. I extended markdown to support thumbnails and other presentational content that most Markdown formats do not support natively.
Why is converting from xml to SQLite so slow?
The conversion code is inefficient. For one, it needs to be cleaned up. For two, it could be parallelized.
Why aren't the SQLite dbs in this repo?
They're too big. As a workaround, you either generate the databases yourself or get a copy from Kaggle.
Credits
- Phiresky for his sqlite-httpvfs library and tutorial.
- The good christians and folks behind SQLite.
- spencermountain for his wtf_wikipedia library.
- Wikipedia for their daily dataset dumps.
- Everyone in package.json for their libraries.