数据集:MovieLens的ml-latest-small数据集,大概600多个用户,大概9700多部电影,10万条评分记录
电影详细信息:ml-latest-small提供了一个CSV文件,里面有电影在IMDB上面的ID编号,用爬虫爬下来的,https://blog.csdn.net/hhmy77/article/details/106389370 这篇博客里面有爬虫的代码
技术栈:web框架用的是Django,数据库MySQL,使用Navicat操作数据库,前端用的bootstrap做渲染
算法:使用的是UserCF做推荐,600多个用户用UserCF比较快。ItemCF只计算了相似度,在展示相似电影栏里面用到。 https://github.com/hhmy27/ReSysCode/tree/master/CF 上面有CF算法的代码
详细版本:
- Django 2.0
- Python 3.6
运行方法:
本项目运行需要数据库,database文件夹里面提供了我的数据库备份文件。
如果你想直接导入我的数据库
- 导入数据库,数据库命名必须是movie_recommend_db
- 配置好Django里面的数据库链接选项
- 开始运行
如果你想自己导入数据,从头开始做的话,在views.py开始的地方注释了一大块导入数据库的代码
- 配置好Django连接数据库的属性
- 迁移model到数据库上
- 按顺序运行注释掉的导入数据库代码
- 开始运行
确保你之前已经配置好Django环境
缺点:
- 数据库密码用明文存储,当时存储的时候没有想到用加密存储
- 注释了csrf中间件,没有继续研究这个部分
- 只在本地运行测试,没有部署到服务器上
- 推荐大概需要3~4秒的时间,并且推荐的结果中热门电影出现的概率很高(当年的星战,黑客帝国,阿甘正传,肖申克的救赎几乎每次都会推荐。。)
- 界面有些简陋
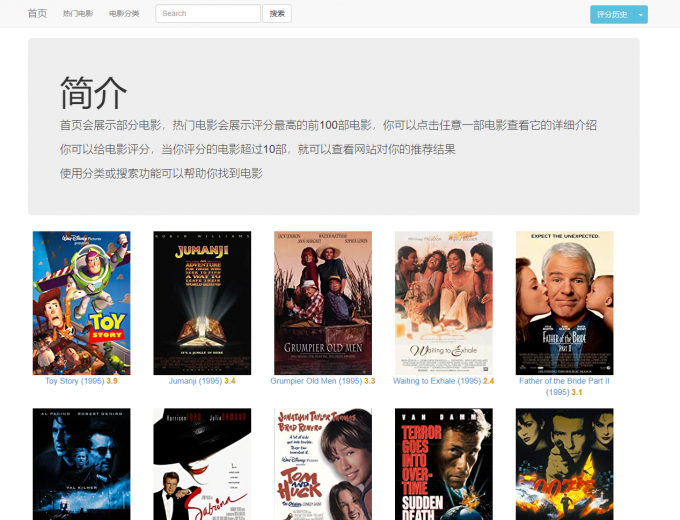
页面展示:
首页:
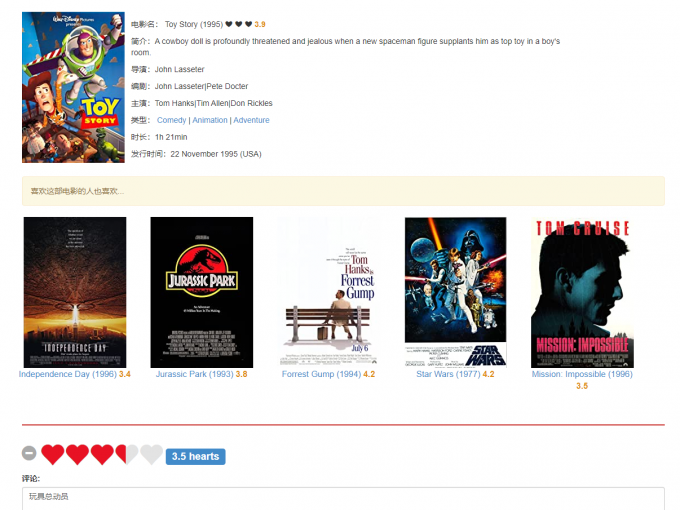
电影详情页:Toy Story为例。黄色提示条下面是相似电影(使用ItemCF计算相似度的方法得出)
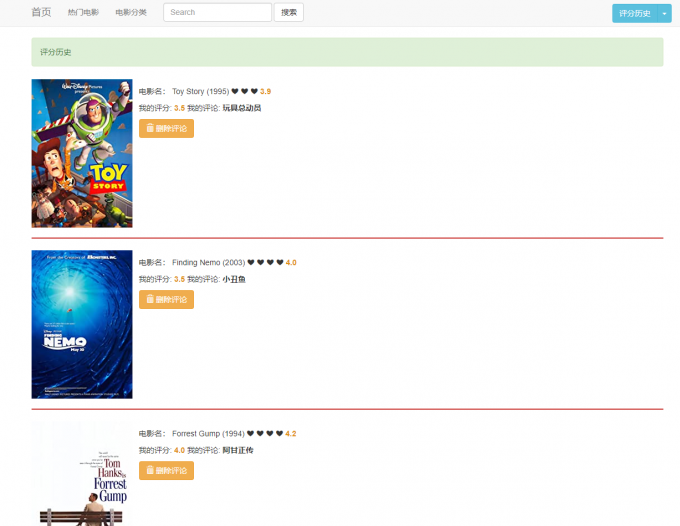
用户的评分记录:
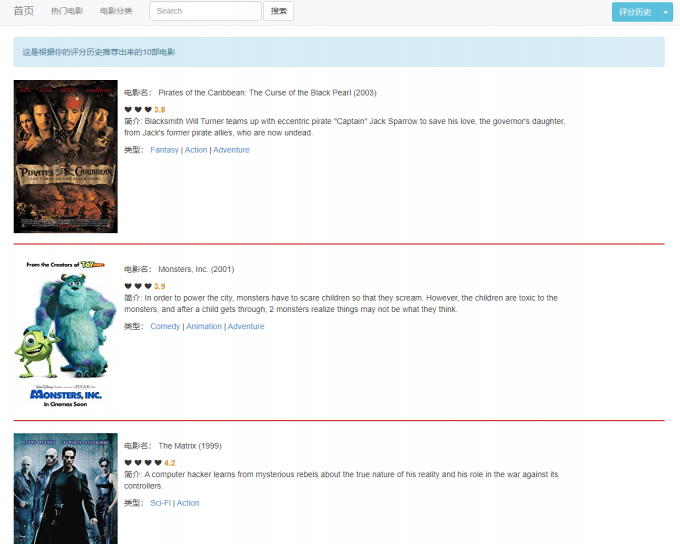
推荐效果:使用UserCF