CAVEVOC is a means to
get speech recognition into the CAVE. CAVEVOC has two
components, the CAVEVOC client and the CAVEVOC Python Module.
The CAVEVOC client runs on a PC, records audio samples and sends
them to Google for translation. The translated text and its
corresponding confidence level is then transmitted to the CAVE
for application use. On the CAVE, the CAVEVOC Python module will
read this data and apply it to a user-defined callback function
within your program.
Trivia: CAVEVOC was the
name given to the first speech recognition system I developed
for the old CAVE in the mid-90s for CALVIN [Video]. At the time
IBM's speech engine was used. Arguably this new CAVEVOC is much
more accurate using Google's crowd-sourced recognition engine.
You will need to
download the following to use CAVEVOC:
- Processing
-
CAVEVOC-Processing.zip - The client already bundles together the STT (Speech To Text)
translation library and the UDP (networking)
library in the zip file. But you can download them separately
from their original source by clicking the respective links.
These library folders need to be installed in your Processing
user library folder.
- CAVEVOC Python
Module - cavevoc.py - This is the python module you will use
to incorporate speech recognition into your CAVE application.
- CAVEVOC CAVE Demo
Application - demo.py - This is a simple CAVE application to
show you how to use the CAVEVOC
Python API.
This demo simply takes
any recognized speech from CAVEVOC and print on the screen in
the CAVE including the confidence level reported by Google.
- You should install Items 1-3 on the PC that will access the microphone.
- Install Items 4 and 5 in the location where you normally install your CAVE applications.
- First launch the
CAVE Demo application: e.g.
orun -s demo.py
The environment should just be gray and blank until recognized text is received. The picture below is taken from a desktop simulation.
In the demo, whenever recognized text is received, it will display its confidence level (reported by Google) and the text, in a random position on the screen in front of you, hence the picture below.
- Launch Processing and open CAVEVOC-PTT.pde.
- You will first need to edit the ip address in the code to reflect the ip address of the CAVE (e.g. lyra.evl.uic.edu).
- Now RUN the
CAVEVOC-PTT.pde application.
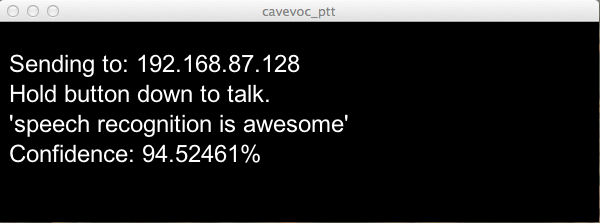
- Hold down any key on your keyboard (like the SPACEBAR) and start talking.
- Release the key when you are done talking.
- The audio will begin recording when you hold the key down. When released the audio sample will be transmitted to Google for translation.
- Once the translation is received you should see feedback on the CAVEVOC-PTT window.
- Furthermore that text should also be sent to the CAVE application and it should show up in the CAVE.

Note: There is also a
CAVEVOC-Auto.pde file that contains a version of the CAVEVOC
client that will continually listen for audio without requiring
you to hold a key down. Also both the CAVEVOC-PTT and
CAVEVOC-Auto code are kept to a minimum so you can further
customize them for your needs.
The second demo (called Ideation) lets you
create boxes and spheres, color them and move them, all via
voice command. To select an object simply turn your head
towards it.
Launch the program using: orun -s ideation.py

Ideation is an example that shows how you could use Pyparsing to parse the incoming voice commands. With Pyparsing you can very quickly develop a parser for very complex grammars. In the demo I have included the module: pyparsing.py so you don't need to bother to download and install Pyparsing.
The following are
example voice commands:
- MAKE | BUILD | CREATE A BOX | CUBE - creates a 1-foot cube
- MAKE | BUILD | CREATE A SPHERE | BALL - creates a 1-foot diameter sphere
- PAINT | COLOR | MAKE IT RED | GREEN | BLUE | .... - color the object that your head is pointing at Red. Other colors are green, blue, magenta, orange, yellow, black.... you get the idea.
- NAME IT | THIS JASON - give a name to the object
- PLACE JASON HERE - if you navigate the space and say this it will take the object named JASON and bring it to you and place it in front of you.
- AGAIN - if you say either AGAIN or REPEAT, it will perform the last command again. E.g. if you said MAKE A BOX last, it will make a second box if you say AGAIN or REPEAT.
- MAKE A BOX AND PAINT IT RED AND PLACE JASON HERE - You can chain commands together with the AND operator.
To see the full extent
of the grammar and how it is used to activate parts of your code
you will need to read the ideation.py code.
- Get a wireless microphone that has a push-to-talk button if possible- it will help cut out any unnecessary attempts at translation- even better if you can find a wireless bluetooth microphone. But for testing purposes you could just start with your laptop's built-in microphone.
- Use speech
recognition for interactions that take more time or dexterity
to perform the physical manipulation than to say the phrase.
For example, it may be challenging to accurately position a
CAVE object in space using physical interactions but it is
easy to say: Move object to 2.5 3 5.5 or Rotate 23.5 degrees
along X axis or Make a box 1 by 2.5 by 3 meters and put it at
3 4 5.
- After text is recognized or not recognized, try to give the user feedback- for example with an audible cue. You've seen sci-fi movies like Iron Man, use your imagination!
- It is sometimes
helpful to prefix every command with a name, e.g. "Jarvis,
move the object". You can use this prefix to know when you are
talking to the CAVE rather than talking to someone else in the
audience. Another approach is to create a virtual
character/avatar and have it so that it will only interpret
your commands if you are facing it.
- Consider creating a
grammar to describe your commands and then use something like
Pyparsing to
implement the grammar parser.
- If you want to be
more advanced you can also use the Natural Language Toolkit.
The main advantage of using natural language processing techniques is that
you can minimize the need for the user to remember a specific grammar.
- But if you don't
have much experience in NLP, try to keep the number of speech
utterances low to minimize the need to remember them. In any
case it may be helpful to provide a "dropdown" cheat sheet in
the CAVE to help the user remember the commands. Better still
is to create a cheat sheet that unfolds to show the next word
in a phrase that can be spoken. A good example of this is used
in the video game End War.
- Lastly you may consider implementing a state-machine-based conversation engine so that followup commands are possible:
- User: Computer, make me a cube
- Computer: Where would you like me to put it?
- User: Put it at 5 5 5
- Computer: How big would you like it?
- User: How about 3 by 5 by 2 meters
- Computer: Coming right up. Cube at 5 5 5 of size 3 by 5 by 2 meters.
- User: Take me to the other side of the cube.
- etc....
- 7/26/2013 - Revised to include example using Pyparsing as the command parser.
- 7/20/13 - First version released.