
The Universe of Evaluation.
All about the evaluation for LLMs.
Upstage Solar is powered by Evalverse! Try at Upstage Console!
🤗HugginFace Space • 📚Docs • 📄Paper
Examples • FAQ • Contribution Guide • Contact • Discord
- [2024.05.10] LLM-Evaluation Report of Evalverse is now available on HuggingFace Space.

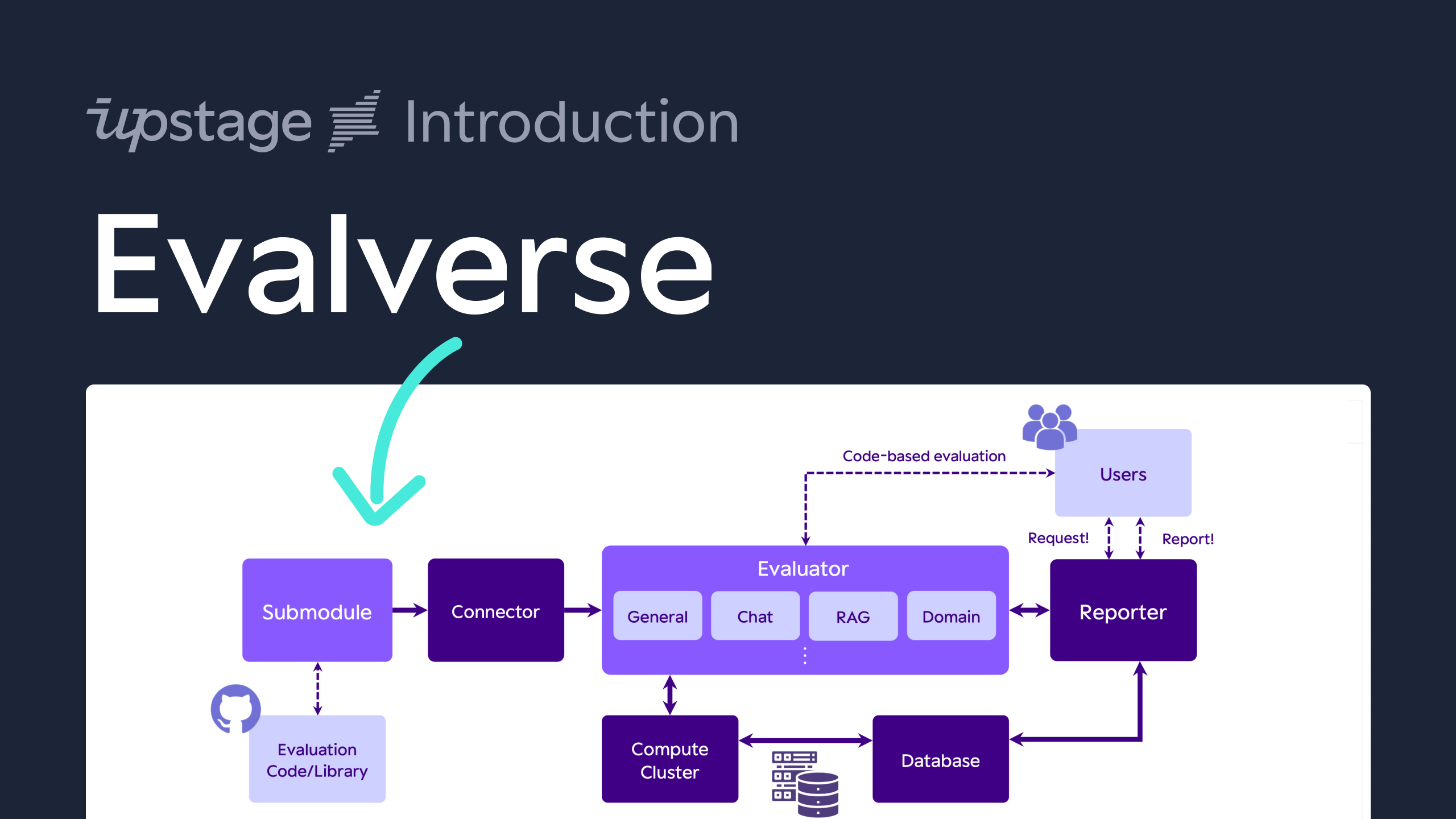
Evalverse is a freely accessible, open-source project designed to support your LLM (Large Language Model) evaluation needs. We provide a simple, standardized, and user-friendly solution for the processing and management of LLM evaluations, catering to the needs of AI research engineers and scientists. We also support no-code evaluation processes for people who may have less experience working with LLMs. Moreover, you will receive a well-organized report with figures summarizing the evaluation results.
- access various evaluation methods without juggling multiple libraries.
- receive insightful report about the evaluation results that helps you to compare the varied scores across different models.
- initiate evaluation and generate reports without any code via Slack bot.

- Unified evaluation with Submodules: Evalverse extends its evaluation capabilities through Git submodules, effortlessly incorporating frameworks like lm-evaluation-harness and FastChat. Swiftly add new tools and keep pace with the latest in LLM evaluation.
- No-code evaluation request: With Evalverse, request LLM evaluations without any code, simply by sending
Request!in a direct message or Slack channel with an activate Evalverse Slack bot. Enter the model name in the Huggingface hub or local model directory path in Slack, and let the bot handle the rest. - LLM evaluation report: Obtain comprehensive, no-code reports from Evalverse. Request with a simple command -
Report!-, select the model and evaluation criteria, and receive detailed reports with scores, rankings, and visuals, all generated from the stored score database.
If you want to know more about Evalverse, please checkout our docs.
By clicking below image, it'll take you to a short intro video!
Before cloning, please make sure you've registered proper SSH keys linked to your GitHub account.
- Notes: add
--recursiveoption to also clone submodules
git clone --recursive https://github.com/UpstageAI/evalverse.git
cd evalverse
pip install -e .
Currently, installation via Pypi is not supported. Please install Evalverse with option 1.
You have to set an API key and/or Token in the .env file (rename .env_sample to .env) to use all features of Evalverse.
- OpenAI API Key (required for
mt_bench) - Slack BOT/APP Token (required for slack reporter)
OPENAI_API_KEY=sk-...
SLACK_BOT_TOKEN=xoxb-...
SLACK_APP_TOKEN=xapp-...
More detailed tutorials are here.
- basic_usage.ipynb: Very basic usage, like how to use
Evaluatorfor evaluation andReporterfor generating report. - advanced_usage.ipynb: Introduces methods for evaluating each benchmark and all benchmarks collectively.
The following code is a simple example to evaluate the SOLAR-10.7B-Instruct-v1.0 model on the h6_en (Open LLM Leaderboard) benchmark.
import evalverse as ev
evaluator = ev.Evaluator()
model = "upstage/SOLAR-10.7B-Instruct-v1.0"
benchmark = "h6_en"
evaluator.run(model=model, benchmark=benchmark)Here is a CLI script that produces the same result as the above code:
cd evalverse
python3 evaluator.py \
--h6_en \
--ckpt_path upstage/SOLAR-10.7B-Instruct-v1.0Currently, generating a report is only available through the library. We will work on a Command Line Interface (CLI) version as soon as possible.
import evalverse as ev
db_path = "./db"
output_path = "./results"
reporter = ev.Reporter(db_path=db_path, output_path=output_path)
reporter.update_db(save=True)
model_list = ["SOLAR-10.7B-Instruct-v1.0", "Llama-2-7b-chat-hf"]
benchmark_list = ["h6_en"]
reporter.run(model_list=model_list, benchmark_list=benchmark_list)
| Model | Ranking | total_avg | H6-ARC | H6-Hellaswag | H6-MMLU | H6-TruthfulQA | H6-Winogrande | H6-GSM8k |
|---|---|---|---|---|---|---|---|---|
| SOLAR-10.7B-Instruct-v1.0 | 1 | 74.62 | 71.33 | 88.19 | 65.52 | 71.72 | 83.19 | 67.78 |
| Llama-2-7b-chat-hf | 2 | 53.51 | 53.16 | 78.59 | 47.38 | 45.31 | 72.69 | 23.96 |
We currently support four evaluation methods. If you have suggestions for new methods, we welcome your input!
| Evaluation | Original Repository |
|---|---|
| H6 (Open LLM Leaderboard) | EleutherAI/lm-evaluation-harness |
| MT-bench | lm-sys/FastChat |
| IFEval | google-research/instruction_following_eval |
| EQ-Bench | EQ-bench/EQ-Bench |
If you have any use-cases of your own, please feel free to let us know.
We would love to hear about them and possibly feature your case.
✨ Upstage is using Evalverse for evaluating Solar.
✨ Upstage is using Evalverse for evaluating models at Open Ko-LLM Leaderboard.
Evalverse is an open-source project orchestrated by the Data-Centric LLM Team at Upstage, designed as an ecosystem for LLM evaluation. Launched in April 2024, this initiative stands at the forefront of advancing evaluation handling in the realm of large language models (LLMs).
Evalverse is completely freely-accessible open-source and licensed under the Apache License 2.0.
If you want to cite our 🌌 Evalverse project, feel free to use the following bibtex. You can check our paper via link.
@misc{kim2024evalverse,
title={Evalverse: Unified and Accessible Library for Large Language Model Evaluation},
author={Jihoo Kim and Wonho Song and Dahyun Kim and Yunsu Kim and Yungi Kim and Chanjun Park},
year={2024},
eprint={2404.00943},
archivePrefix={arXiv},
primaryClass={cs.CL}
}