By using the Reinforcement Learning method (sub-branch of machine learning) the aim is to ensure that the agent in a maze reaches its target with the Q Learning Algorithm.
Python, Numpy, Jupyter, PySimpleGUI, PyGame, Matplotlib, Maze, Agent, Situation, Action, Shortest Path, Grid, Q Learning, Reinforcement Learning, Rewarding, Episode, Training, Auxiliary Functions, Machine Learning, Bellman, Q Table, R Table.
Our robot (agent) must use the Q learning algorithm to escape from the obstacles and travel through the white areas. If our robot starts from the blue square and reaches the end in the shortest (cost efficient) way without hitting the red boxes, it will be considered successful. The robot can move right, left, up and down starting from any white square. The steps taken must be decisive and will succeed unless the agent hits an obstacle. As a result, the robot receives the reward from the starting point to the desired target.

Jupyter Notebook was used as the development environment.
PyGame was used for visualization.
Numpy library was used for Q Learning.
PySimpleGUI library was used for interface design.
Matplotlib library was used to draw plots.
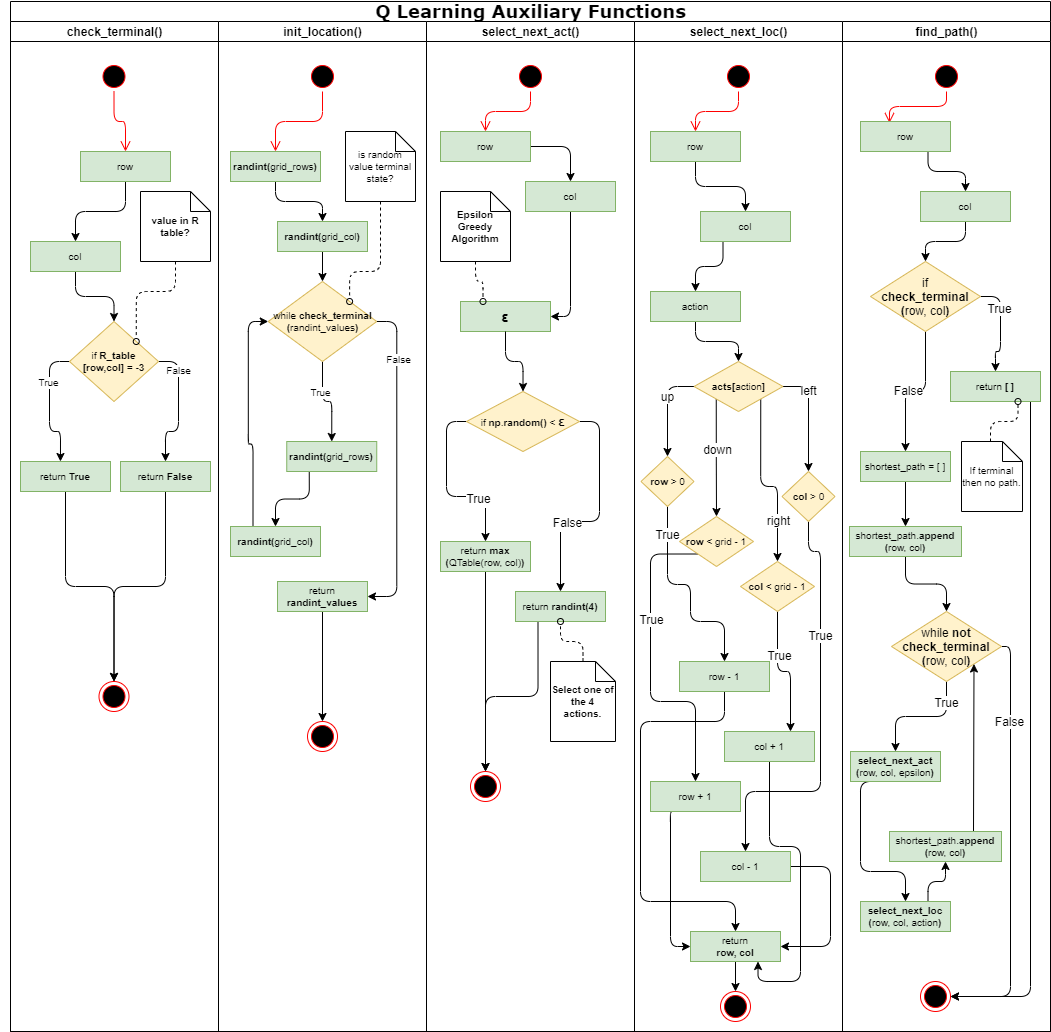
The Q-Learning algorithm is one of the most well-known algorithms of reinforcement learning. The main purpose of the algorithm is to examine the next moves and calcuate the reward that will be earned according to the examination.
The reward values are kept in the reward table (which is randomly generated). The robot's experience will be shaped according to this reward table. On the way to the goal, the robot uses the experience gained in each iteration to maximize the places he can go. The robot keeps these experiences in a table called the Q-Table.
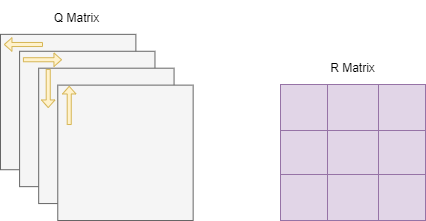
In this project, the aim is to find the shortest path in the grid for a start and exit point selected by the user. To achieve this, Q Learning Algorithm will be applied.
In order to apply the Q Learning Algorithm, the environment must first be defined. The environment consists of three components:
- States
- Actions
- Rewards
The agent is expected to take states and rewards as input and produce actions according to them.
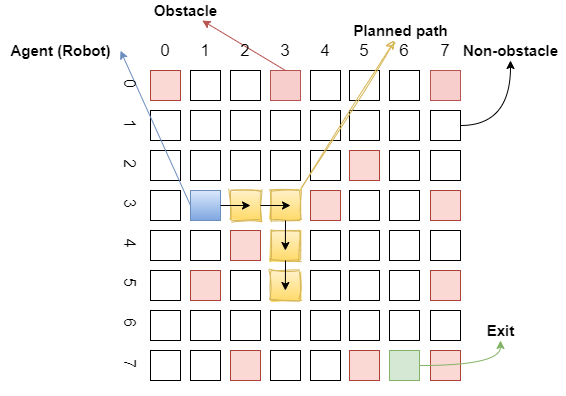
Red squares in the grid represent obstacles, blue squares agent, green squares exit (target), white squares represent paths through which the agent can pass. Each position (square) in the grid is a state. Each situation has a row and column number. Red and green squares are called terminal states. A training episode will end when the agent gets to the red or green square. If it reaches the green square, the agent has arrived at its target, but if it reaches a red square, it will fail due to the wrong move. When it comes to a white square, it will move to another square.
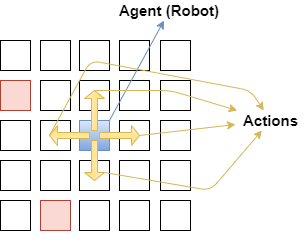
There are 4 actions in this scenario. The agent can go up, down, right or left. Naturally, the agent is expected to learn not to hit the red squares.
In order for the agent to learn, each state must have a rewarding coefficient. The agent can start on any white square, but his goal is always the same - to maximize reward. In this case, the concept of negative rewarding is encountered. Negative reward is punishment and is used for every state except the exit (target) state. This helps the agent find the shortcut because the agent always tries to minimize the punishment.
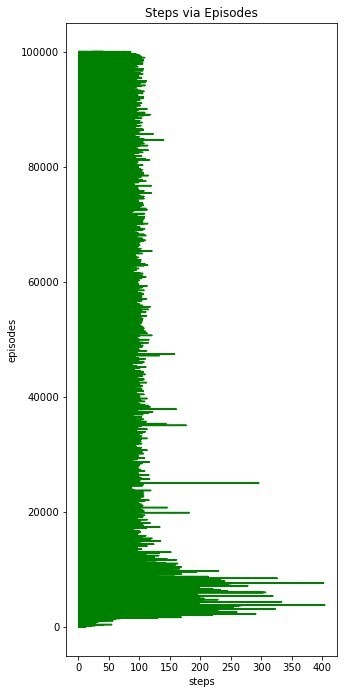
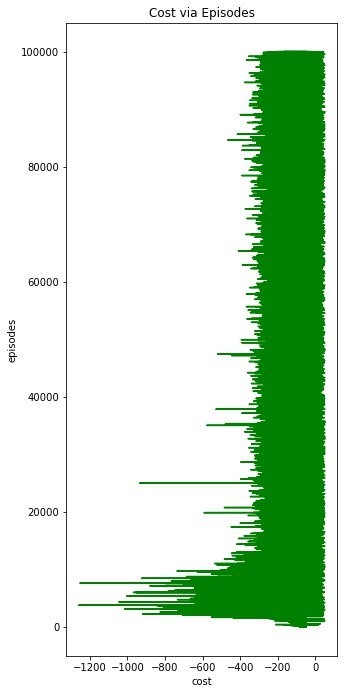
The number of steps and rewards are calculated for each episode. After the starting position of the agent is taken, the Q table is updated by using Bellman equation in each episode for the actions that the agent randomly chooses until the agent reaches a red square. Temporary difference is calculated with Bellman equation.
Once this has been done for 100,000 episodes, the agent may have been adequately trained. If it is not sufficiently trained, this code snippet must be rerun.
Start = (0,0)
End = (49,49)