Presented by Kevin Markham at PyCon on May 28, 2016. Watch the complete tutorial video on YouTube.
Although numeric data is easy to work with in Python, most knowledge created by humans is actually raw, unstructured text. By learning how to transform text into data that is usable by machine learning models, you drastically increase the amount of data that your models can learn from. In this tutorial, we'll build and evaluate predictive models from real-world text using scikit-learn.
By the end of this tutorial, attendees will be able to confidently build a predictive model from their own text-based data, including feature extraction, model building and model evaluation.
Attendees will need to bring a laptop with scikit-learn and pandas (and their dependencies) already installed. Installing the Anaconda distribution of Python is an easy way to accomplish this. Both Python 2 and 3 are welcome.
I will be leading the tutorial using the IPython/Jupyter notebook, and have added a pre-written notebook to this repository. I have also created a Python script that is identical to the notebook, which you can use in the Python environment of your choice.
- IPython/Jupyter notebooks: tutorial.ipynb, tutorial_with_output.ipynb, exercise.ipynb, exercise_solution.ipynb
- Python scripts: tutorial.py, exercise.py, exercise_solution.py
- Datasets: data/sms.tsv, data/yelp.csv
Attendees to this tutorial should be comfortable working in Python, should understand the basic principles of machine learning, and should have at least basic experience with both pandas and scikit-learn. However, no knowledge of advanced mathematics is required.
- If you need a refresher on scikit-learn or machine learning, I recommend reviewing the notebooks and/or videos from my scikit-learn video series, focusing on videos 1-5 as well as video 9. Alternatively, you may prefer reading the tutorials from the scikit-learn documentation.
- If you need a refresher on pandas, I recommend reviewing the notebook and/or videos from my pandas video series. Alternatively, you may prefer reading this 3-part tutorial.
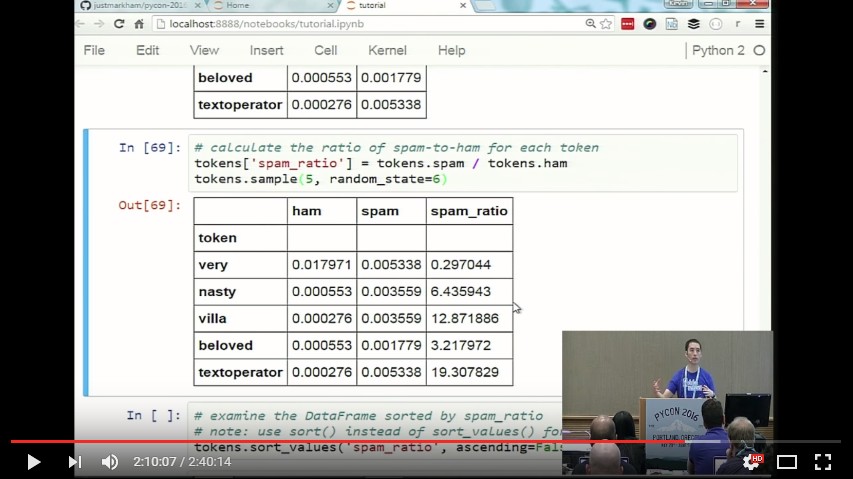
It can be difficult to figure out how to work with text in scikit-learn, even if you're already comfortable with the scikit-learn API. Many questions immediately come up: Which vectorizer should I use, and why? What's the difference between a "fit" and a "transform"? What's a document-term matrix, and why is it so sparse? Is it okay for my training data to have more features than observations? What's the appropriate machine learning model to use? And so on...
In this tutorial, we'll answer all of those questions, and more! We'll start by walking through the vectorization process in order to understand the input and output formats. Then we'll read a simple dataset into pandas, and immediately apply what we've learned about vectorization. We'll move on to the model building process, including a discussion of which model is most appropriate for the task. We'll evaluate our model a few different ways, and then examine the model for greater insight into how the text is influencing its predictions. Finally, we'll practice this entire workflow on a new dataset, and end with a discussion of which parts of the process are worth tuning for improved performance.
- Model building in scikit-learn (refresher)
- Representing text as numerical data
- Reading a text-based dataset into pandas
- Vectorizing our dataset
- Building and evaluating a model
- Comparing models
- Examining a model for further insight
- Practicing this workflow on another dataset
- Tuning the vectorizer (discussion)
Kevin Markham is the founder of Data School and the former lead instructor for General Assembly's Data Science course in Washington, DC. He is passionate about teaching data science to people who are new to the field, regardless of their educational and professional backgrounds, and he enjoys teaching both online and in the classroom. Kevin's professional focus is supervised machine learning, which led him to create the popular scikit-learn video series for Kaggle. He has a degree in Computer Engineering from Vanderbilt University.
- Email: kevin@dataschool.io
- Twitter: @justmarkham
Text classification:
- Read Paul Graham's classic post, A Plan for Spam, for an overview of a basic text classification system using a Bayesian approach. (He also wrote a follow-up post about how he improved his spam filter.)
- Coursera's Natural Language Processing (NLP) course has video lectures on text classification, tokenization, Naive Bayes, and many other fundamental NLP topics. (Here are the slides used in all of the videos.)
- Automatically Categorizing Yelp Businesses discusses how Yelp uses NLP and scikit-learn to solve the problem of uncategorized businesses.
- How to Read the Mind of a Supreme Court Justice discusses CourtCast, a machine learning model that predicts the outcome of Supreme Court cases using text-based features only. (The CourtCast creator wrote a post explaining how it works, and the Python code is available on GitHub.)
- Identifying Humorous Cartoon Captions is a readable paper about identifying funny captions submitted to the New Yorker Caption Contest.
- In this PyData video (50 minutes), Facebook explains how they use scikit-learn for sentiment classification by training a Naive Bayes model on emoji-labeled data.
Naive Bayes and logistic regression:
- Read this brief Quora post on airport security for an intuitive explanation of how Naive Bayes classification works.
- For a longer introduction to Naive Bayes, read Sebastian Raschka's article on Naive Bayes and Text Classification. As well, Wikipedia has two excellent articles (Naive Bayes classifier and Naive Bayes spam filtering), and Cross Validated has a good Q&A.
- My guide to an in-depth understanding of logistic regression includes a lesson notebook and a curated list of resources for going deeper into this topic.
- Comparison of Machine Learning Models lists the advantages and disadvantages of Naive Bayes, logistic regression, and other classification and regression models.
scikit-learn:
- The scikit-learn user guide includes an excellent section on text feature extraction that includes many details not covered in today's tutorial.
- The user guide also describes the performance trade-offs involved when choosing between sparse and dense input data representations.
- To learn more about evaluating classification models, watch video #9 from my scikit-learn video series (or just read the associated notebook).
pandas:
- Here are my top 8 resources for learning data analysis with pandas.
- As well, I have a new pandas Q&A video series targeted at beginners that includes two new videos every week.