NAVER CAMPUS HACKDAY 2017 Winter - comment
- 댓글 증감수 기반 콘텐츠 랭킹 시스템 개발
주제 선정 배경
- 수많은 컨텐츠가 이미 생성 되어있고 새로 생성이 되는데, 컨텐츠에 작성된 댓글 최신 목록을 조회하고 특정 기간 동안 댓글의 증감을 표시하고 랭킹순으로 조회할 수 있는 페이지를 개발해 보자!
목표
- 특정 기간 동안(최소 1분 간격)의 모든 컨텐츠들 간 댓글 증감수에 따른 랭킹 및 최신 댓글 N개 조회 가능한 API 개발
개발환경
-
Ubuntu 16.04 LTS
-
MySQL 5.7.17
-
Spring Framework
-
JDK 1.8
* DB Server : 멘토님이 제공해 주심.
DataBase Table Structure
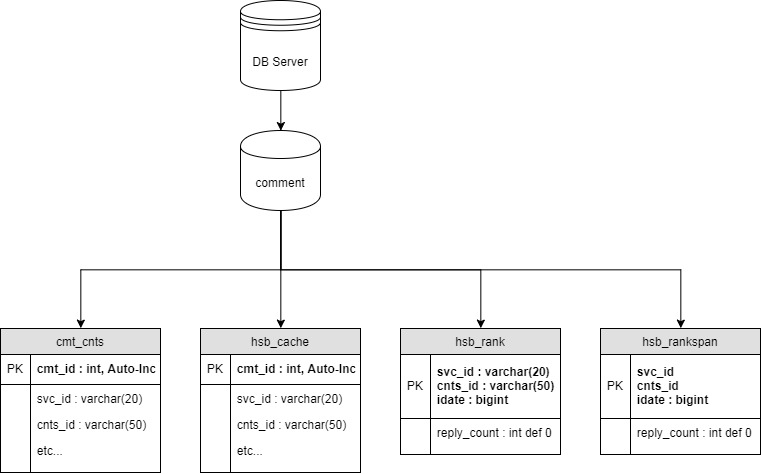
Database : comment
Tables : cmt_cnts, hsb_cache, hsb_rank, hsb_rankspan
cmt_cnts
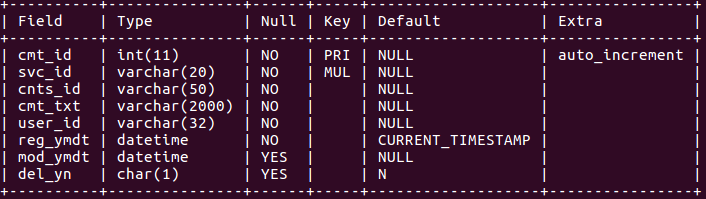
- 실시간으로 초당 500개의 댓글이 무작위 컨텐츠에 무작위로 INSERT된다.
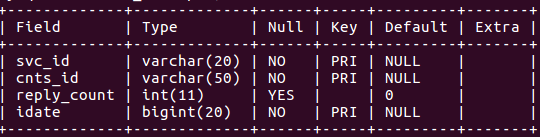
hsb_rank
![]()
- 특정 날짜의 Service의 Content에 대한 댓글 증감수를 분 단위로 모두 기록해 Rank를 매기는 곳이다.
- hsb_cache에 데이터가 추가/수정될 때마다, 적용된 Trigger가 실행되어 이곳에 해당 댓글의 Service ID와 Contents ID, 그리고 분 단위의 날짜 값이 모두 일치하는 Row를 찾아 댓글 증감을 표시하게 된다.
- PK로 인해 Indexing이 되어 있는 Column들이 있기 때문에, 그에 해당하는 Column에 대한 ORDER BY문을 통한 READ에도 성능이 좋다.
- WRITE에 대해 수행함에 있어 신경 쓸 만 한 부하가 없었다.
hsb_rankspan
- hsb_rank로부터 분 단위로 저장된 랭킹들로부터 Top 100을 선정하여 저장하는 테이블이다. 최종적으로 이 테이블을 통해 API 기능을 제공하게 되며, 유저는 날짜, Service ID, Contents ID를 통해 데이터를 제공받을 수 있다.
hsb_cache
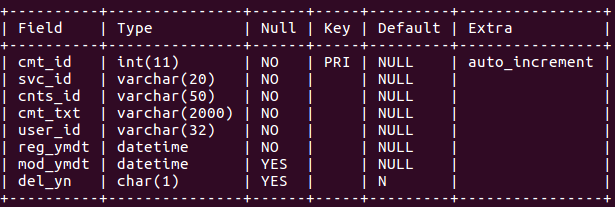
- 서버가 실행된 후로부터는 cmt_cnts에 추가되는 댓글들이 이 테이블에도 추가된다.
- Delete요청마다 삭제하면 느리고, 복구를 해야 할 수 있으므로 del_yn column을 만들어 UPDATE 요청으로 mark만 해 놓는 방식을 이용한다.
- MySQL Procedure 코드를 작성해 INSERT / UPDATE에 Trigger를 적용해 놓았다.
- INSERT 시 : hsb_rank에 작성된 날짜(reg_ymdt에 저장됨)를 1711240312와 같이 분 단위의 Integer로 변환하여 저장해 주는데, hsb_rank에 이미 존재한다면 댓글 증감 수치만 1 증가시킨다.
- UPDATE 시 : INSERT와 같은 처리를 하지만, 수정된 날짜에 대해 처리해야 하므로 mod_ymdt(수정된 날짜) 데이터를 이용하여 저장한다.
- UPSERT 를 이용하여 효율적으로 처리했다.
Implementation
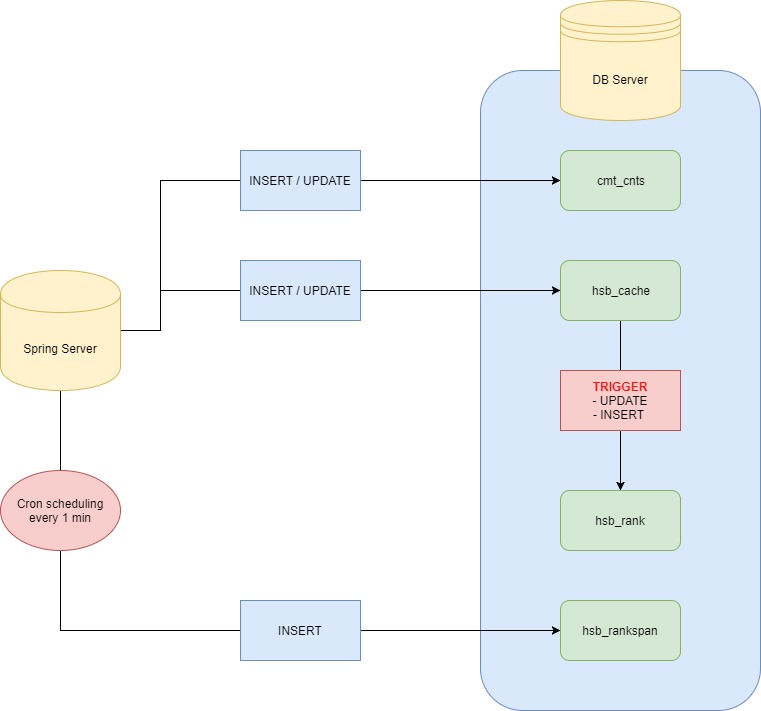
*실제로 서비스를 하게 된다면 같은 데이터를 다른 테이블에 2번 씩이나 Insert하는 것은 비효율적이다. 원래 댓글에 대한 처리 후 처리한 데이터를 cmt_cnts 테이블로 옮기는 방식을 사용하는 것이 효율적이지만, 멘토님께서 cmt_cnts 테이블에 댓글을 무작위로 등록할 것이라 하셨으니 cmt_cnts 테이블에 우선적으로 댓글이 저장되는 방식을 변경할 수는 없었다.
1) 댓글?
- 1분에 3만 건의 댓글이 무작위로 INSERT / UPDATE 된다.
- 새로운 컨텐츠는 계속 새로 추가된다.
2) Cache를 만들어, 서버 실행 이후의 데이터를 저장.
- 형식은 cmt_cnts 테이블에 저장되는 데이터와 동일하다.
- 현재 시간을 기준으로 랭킹을 계산할 것이고, 모든 댓글 수가 아닌 댓글 '증감'수 이므로 서버 실행 이후의 모든 데이터를 이곳에 저장한다.
- cmt_cnts 테이블은 모든 댓글에 대한 데이터가 저장되는 곳. hsb_cache 테이블은 분석이 끝나면 삭제해도 상관 없는 테이블이다.
3) MySQL Trigger on Cache
- hsb_cache 테이블에 MySQL Procedure 코드를 작성해 hsb_rank 테이블에 대한 INSERT와 UPDATE(삭제도 UPDATE다) Trigger를 등록시켜 놓는다. 이로 인해 따로 Spring Server에서 Query 요청을 관리할 필요가 없어지고, 일련의 과정은 하나의 Transaction처럼 이루어진다.
- 이 과정을 통해 hsb_cache에 INSERT / UPDATE 쿼리 요청 시 Trigger가 실행되어 자동으로 hsb_rank에 랭킹이 갱신되며 저장된다.
- 즉 이 단계까지는 Database에 프로그래밍하는 것만으로 해결되었으므로, 실제로는 어느 서버를 거쳐 댓글이 달리든지 상관이 없다. 즉, 여기까지는 따로 나만의 Spring Server 구현이 필요하지는 않았다.
4) Daemon by Cron
- Spring Server에서 1분 단위로 hsb_rank 테이블로부터 Top 100을 선정하여 hsb_rankspan 테이블에 저장해 준다.
- 이 작업은 Cron scheduling을 통해 Background에서 이루어진다.
이렇게 API 개발이 완료되었다!
결과
이렇게 구현하여 성능을 테스트 해 본 결과, 실제로 분당 3만 개의 데이터에 대한 처리 시간은 10~15초 로 안정적이었고, 이 API에 대한 성능으로는 이미 hsb_rankspan에 top100으로 정렬되어 저장되어 있는 곳에서 검색하는 것이므로 문제가 없었다. 이 구조의 장점은 대부분의 처리를 DB Server에 트랜잭션 형태로 맡기고, Spring Server에서는 Cron Scheduling을 통해 다른 하나의 스레드에서 랭킹 갱신작업이 수행되는 것만으로도 충분한 성능을 보였으므로 아직 Server에서 사용할 Thread에 대한 자원이 많이 남아돌아 추후 어떤 식으로든 다른 처리를 더 여유롭게 할 수 있는 상태라는 것이다.
추가 고려사항
- 만약 이전의 댓글들에 대한 데이터를 분석할 필요가 있다면, 현재는 [현재시간 - 1분] 간격으로 현재 시간을 기준으로 랭킹을 갱신하는데, 이 알고리즘을 그대로 활용하여 Cron을 이용해 Background에서 또 하나의 Daemon을 돌리는 것으로 해결된다. 단지 Input으로 원하는 댓글 증감 분석 기간을 준다면 [(10 ~ 15) * 원하는 분석 기간]초 의 시간이 걸리며 해결될 것이다.
- 이렇게 되면 최종적으로는 현재의 랭킹을 갱신하는 스레드와 과거의 랭킹을(얼마나 오랜 기간인지는 모르겠으나) 갱신하고 있는 스레드로 총 2개의 스레드에서 수행된다.
해커톤 소감
이렇게 방대한 양의 데이터에 대한 처리를 실제로 해 본 적이 없어서 걱정을 많이 했었다. 특히 Indexing에 대해 정확한 성능 파악을 해 본 적이 없어 극도로 고민하고 있었는데, 멘토님의 가르침을 통해 실제로 이런 데이터들을 어떻게 처리하고 있는지에 대해 파악할 수 있었고, 결과적으로 랭킹 시스템 API를 개발해 보고 잘 작동하는 모습을 보니 정말 행복했다..,. 같은 팀 분들도 너무 착하고 좋았다.. 최고.