- 从零开始复刻ruoyi-vue-pro
- 复刻的难题是如何将庞大体量的代码拆分成一个个小功能
- 提交大纲即是拆分成一个个小功能的过程
- 也是代码的提交过程,git切到对应提交节点就是查看该功能的完整代码.
-
[yudao-server]
- 空壳项目,作为启动使用。其他业务模块会作为依赖引入,进行整合。
- 调通接口
-
[yudao-dependencies]
- 基础 bom 文件,管理整个项目的依赖版本
- 管理springboot版本为2.7.13
-
[最外层pom.xml]
- 作为其他所有模块的父pom,管理项目的版本号和依赖
- 版本仲裁(
<dependencyManagement>)中import[yudao-dependencies],将[yudao-dependencies]的依赖管理传递给所有的子模块,进而统一管理所有模块的依赖版本
<scope>import</scope>只能在<dependencyManagement>中使用,只会将被引用依赖中<dependencyManagement>中的依赖关系导入下来
- [yudao-framework]
-
创建一个[yudao-framework]作为所有组件的父项目,管理子项目的依赖关系和构建配置。
- pom表示该模块仅作为依赖项,不作为jar包。一般作为父项目,管理子项目的依赖关系和构建配置。
-
该包是技术组件,每个子包,代表一个组件。
-
- [yudao-spring-boot-starter-web]
- 创建一个web组件空架子。用于未来实现或封装Web 框架,全局异常、API 日志等
- 引入spring-boot-starter-web依赖,web相关依赖会全放在这。
- org.springframework.boot.autoconfigure.AutoConfiguration.imports 用于导入其他自动配置类(不写则不导入)。
- YudaoWebAutoConfiguration 针对 SpringMVC 的基础封的配置类,用于自动配置针对 SpringMVC 的基础封装的各种组件和功能的类。
- [yudao-dependencies]
- 对yudao-spring-boot-starter-web进行版本管理
- [yudao-server]
- 移除spring-boot-starter-web依赖,使用组件[yudao-spring-boot-starter-web]提供的web功能
- [yudao-common]
- jar包模块,定义基础的通用类,和框架无关,所有的组件都会引用它
- 引入lombok和hutool
- [yudao-spring-boot-starter-banner]
- 简单的用于打banner的组件
- banner.txt,自定义的banner
- BannerApplicationRunner,在项目启动后执行日志打印,补充banner信息
- ApplicationRunner,Spring Boot提供的接口,在项目启动后执行run方法
- lombok.config
- lombok.config是lombok的配置文件,用于配置此文件所在目录以及子目录的lombok特性,子目录中配置文件可以覆盖父目录配置
- [yudao-module-system]
- 存放管理后台系统管理相关业务,用户、部门、权限、数据字典等等
- 作为system模块的父pom
- [yudao-module-system-api]
- system 模块 API,暴露给其它模块调用,暴露的接口由[yudao-module-system-biz]实现
- [yudao-module-system-biz]
- system 模块的具体实现
-
[yudao-spring-boot-starter-web]
- 给接口路径增加访问前缀,避免接口路径暴露(不理解)
- 给
**.controller.admin.**下的接口路径增加访问前缀/admin-api - 给
**.controller.app.**下的接口路径增加访问前缀/app-api
- 给
- WebMvcConfigurer
- WebMvcConfigurer是一个接口,里面提供了很多web应用常用的拦截方法。通过实现该接口,可以实现web应用 跨域设置、类型转化器、自定义拦截器、页面跳转等功能。
- configurePathMatch:路径匹配规则
- 设置前端请求url与后端接口url的匹配规则。
- 给接口路径增加访问前缀,避免接口路径暴露(不理解)
-
[yudao-spring-boot-starter-web]
- 生成接口文档,支持接口调试。地址:http://localhost:48080/doc.html#/home
- 编写swagger包,集成 Swagger + Knife4j 实现 API 接口文档
- 配置OpenAPI页面的接口信息
- @ConditionalOnProperty:用于根据配置文件中的属性值来决定是否加载某个Bean或配置类。
- @ConditionalOnProperty注解有以下几个常用的属性:
- name:指定配置文件中的属性名。
- havingValue:指定配置文件中的属性值,与name属性一起使用。
- matchIfMissing:当配置文件中没有指定属性时,是否加载被注解的Bean或配置类。
- prefix:指定配置文件中的属性名的前缀。
- value:name属性的别名。
- @ConditionalOnProperty注解有以下几个常用的属性:
- spring-boot-configuration-processor:用于生成配置元数据的注解处理器,使用后在配置文件(yml等)中写配置会有提示(不知道为什么没生效)
- maven中
<optional>true</optional>:true是用来标记一个依赖项为可选的。当一个依赖项被标记为可选时,它不会被自动包含在项目的依赖树中,也不会传递给其他依赖项。 - Springdoc:Springdoc是一个用于生成OpenAPI(前身为swagger)文档的Spring Boot库。它通过解析应用程序中的注解和配置,自动生成API文档,并提供了一些自定义选项和扩展功能。与Swagger UI集成,可以方便地查看和测试API文档。
- Knife4j:基于Springdoc的一个增强工具
- knife4j-openapi3-spring-boot-starter:集成和使用Knife4j,一个用于生成和展示OpenAPI文档的工具。集成了springdoc-openapi-ui、
- springdoc-openapi-ui:用于生成和展示OpenAPI文档的开源库,自动将你的API端点映射为OpenAPI规范([yudao-server]中的TestController)
-
[yudao-server]
- 对接口入参进行数据校验
- [spring-boot-starter-validation]:提供了对数据校验的支持。它基于Java Bean Validation规范(JSR 380)实现,可以用于对请求参数、方法参数、实体对象等进行校验。
- [yudao-common]
- 设置通用结果类CommonResult
- 设置异常体系
- ErrorCode:异常码
- ServiceException:业务异常
- ServerException:服务异常
- GlobalErrorCodeConstants:全局错误码枚举
- ServiceErrorCodeRange:业务异常的错误码区间规定
- ServiceExceptionUtil:业务异常工具类,便于手动抛业务异常和格式化异常信息
- [yudao-spring-boot-starter-web]
- GlobalExceptionHandler:全局异常处理
- [yudao-module-system-biz]
- TestController测试上述功能
-
[yudao-spring-boot-starter-redis]
- 创建RedisTemplate<String, Object> Bean,使用 JSON 序列化方式,支持任何对象类型的序列化/反序列化
- JavaTimeModule:支持Java 8中的日期和时间类型的序列化和反序列化。
- redisson:Java的分布式对象存储和缓存框架,目前仅使用到它创建RedisConnectionFactory bean,连接redis的功能
-
[yudao-spring-boot-starter-captcha]
- 基于 aj-captcha 实现滑块验证码
- RedisCaptchaServiceImpl:基于SPI实现验证码缓存的set和get(redis实现)
-
[yudao-module-system-biz]
- 实现业务接口,验证码的获取和校验
- @CrossOrigin:解决跨域
-
[yudao-spring-boot-starter-banner]
- 自定义banner文件:MyBanner.txt
-
[yudao-spring-boot-starter-captcha]
- 开启一分钟内接口请求次数限制配置:req-frequency-limit-enable=true
- CaptchaVO#browserInfo:客户端ip+userAgent,用于生成clientUid(限流开启时使用)
- FrequencyLimitHandler:频率限制处理程序,按clientUid进行限流。(实现时使用clientUid作为缓存key,进行加锁和计数)
-
[yudao-spring-boot-starter-web]
- 创建CorsFilter Bean,解决跨域
- FilterRegistrationBean:用于注册和管理过滤器(Filter)的Bean。管理生命周期或者设置过滤器的名称、URL模式、调用顺序等
- CorsFilter:跨域filter
- UrlBasedCorsConfigurationSource:为不同的URL路径配置不同的CORS策略(CorsConfiguration)。
- CorsConfiguration:CORS配置
-
[yudao-spring-boot-starter-mybatis]
- 整合mybatisplus
- 依赖mybatis-plus-boot-starter
- 开启下划线(数据库字段)转驼峰(DO字段)映射:map-underscore-to-camel-case: true
- 配置全局主键生成策略:id-type: AUTO(自增)
- 配置逻辑删除/未删除的值:logic-delete-value/logic-not-delete-value
- 数据库敏感数据加密密码配置:mybatis-plus.encryptor.password(应该没用到)
- MybatisPlus的注解
- @TableName:DO对应的表名,不写则取DO类名
- 属性autoResultMap:autoResultMap配置为true时,MyBatis会自动根据查询结果的列名和Java对象的属性名进行映射,创建结果映射。无需手动编写结果映射。
- @TableLogic:标注为逻辑删除字段.
- @TableName:DO对应的表名,不写则取DO类名
- MybatisPlus的API
- BaseMapper类:Mapper 继承该接口后,无需编写 mapper.xml 文件,即可获得CRUD功能
- LambdaQueryWrapper:Lambda 语法使用 Wrapper(Wrapper为查询条件封装,eq、like等等)
- 开启多数据源支持
- 依赖dynamic-datasource-spring-boot-starter
- 配置druid数据源
- 依赖druid-spring-boot-starter
- 开启事务支持
- @EnableTransactionManagement
- 扫描mapper接口,注册映射器
- 配置mybatisPlus拦截器,开启分页
-
扫描cn.iocoder.yudao包下的并且由@Mapper注解标记的接口,注册为MyBatis的映射器。lazyInitialization=true则开启延迟加载Mapper接口的实现类
@MapperScan(value = "cn.iocoder.yudao", annotationClass = Mapper.class, lazyInitialization = "${mybatis.lazy-initialization:false}")
- 整合mybatisplus
-
[yudao-module-system-biz]
- 编写业务接口:/system/tenant/get-id-by-name(使用租户名,获得租户编号)
- 创建TenantController、TenantService、TenantMapper
-
[yudao-module-system-biz]
- 实现/login接口
- 校验验证码
- 服务端验证码二次校验:(猜测)验证码check接口和login接口非同一接口。为防止用户直接跳过验证码的check接口,因此会在login接口进行二次验证码校验,校验check接口下发的验证成功的票据
- 认证账号密码
- 密码校验未做
- 下发token
- 校验验证码
- 实现/login接口
-
[yudao-common]
- 创建ValidationUtils,提供方法内的参数校验
- Validator:基于JSR-303标准的参数校验类
- validate方法:执行校验操作,返回验证失败的约束
- ConstraintViolation:验证失败的约束
-
[yudao-common]
- 集成mapstruct的依赖,便于所有模块使用
- mapstruct
- Java注解处理器
- 基于JSR 269实现,在编译期处理注解,并且读取、修改和添加抽象语法树中的内容(https://blog.csdn.net/Mango_Bin/article/details/125168370)
- 在编译期自动生成映射转换代码,因此安全性高,速度快。
- mapstruct
- 集成mapstruct的依赖,便于所有模块使用
-
[yudao-module-system-biz]
- 创建/list-all-simple,获得全部字典数据列表接口
- cn.iocoder.yudao.module.system.convert:存放mapstruct的对象转换类
- [yudao-module-system-biz]
- 创建接口/get-permission-info:获取登录用户的权限信息
- RBAC模式,通过登录用户获取用户角色信息,通过角色获取角色菜单信息
- 获取权限信息后,可以进入到后台页面了
- 创建接口/get-permission-info:获取登录用户的权限信息
-
[yudao-spring-boot-starter-security]
-
自定义Filter(
TokenAuthenticationFilter)完成token解析和用户认证- 解析自定义header(头Authorization)获取token
- 解析token,构建用户信息
- 构建认证信息,完成认证(
cn.iocoder.yudao.framework.security.core.util.SecurityFrameworkUtils#buildAuthentication)
-
配置
SecurityFilterChain- CSRF禁用
- 开放无需认证即可访问的接口,其他接口配置为认证才可访问
- 配置
TokenAuthenticationFilter在UsernamePasswordAuthenticationFilter之前
- @EnableWebSecurity:启用spring security,加载一堆相关的bean
- SecurityFilterChain:过滤器链,spring security是基于各种过滤器实现的权限控制,
filterChain方法就是构建各种过滤器 - csrf:跨站请求伪造,spring security默认开启了csrf,启用后需要前端配合编码,因此关闭
- authorizeRequests:允许根据使用RequestMatcher实现(即通过 URL 模式)限制HttpServletRequest访问。
- antMatchers:ant模式的接口路径匹配。
- .permitAll():允许任何人访问(无论是否为登录用户)
- httpSecurity.addFilterBefore:在某过滤器之前添加一个过滤器
- UsernamePasswordAuthenticationFilter:基于用户名和密码的身份验证过滤器,是spring security默认的认证过滤器
-
-
[yudao-spring-boot-starter-redis]
- 创建RedisUtil,提供redis读写服务
-
[yudao-module-system-biz]
- /login接口中,在登录成功后将用户的token存入缓存中,用于
TokenAuthenticationFilter中进行token的认证和解析,完善登录认证流程
- /login接口中,在登录成功后将用户的token存入缓存中,用于
-
[yudao-spring-boot-starter-security]
-
自定义免登录免鉴权注解
- @LoginFree:免登录
- @Authenticated:免鉴权
-
解析注解配置相应的权限规则(
YudaoWebSecurityConfigurerAdapter方法filterChain中)-
@PostConstruct:标记一个方法,在对象创建之后,依赖注入完成之后,自动执行该方法。
-
Multimap:多映射Map,相同的key可以有多个值。guava包提供,形如:
A → 1 A → 2 b → 3
-
.permitAll():允许任何人访问(无论是否为登录用户) -
.authenticated():指定任何经过身份验证的用户都允许使用 URL
-
-
-
[yudao-module-system-biz]
- 登录之前的接口方法上使用@LoginFree进行标注,实现免登录
- [yudao-spring-boot-starter-mybatis]
- 抽取数据库公共字段封装成对象
BaseDO
- 抽取数据库公共字段封装成对象
-
[yudao-spring-boot-starter-mybatis]
BaseDO字段上面添加字段自动填充策略- fill:自动填充策略
- DEFAULT:默认不处理
- INSERT:插入时填充字段
- UPDATE:更新时填充字段
- INSERT_UPDATE:插入和更新时填充字段
- jdbcType:字段对应的数据库类型
- fill:自动填充策略
- 创建数据库通用字段自动填充控制器(见
DefaultDBFieldHandler) - 配置
MetaObjectHandlerbean
-
MetaObjectHandler:元对象字段填充控制器抽象类,实现公共字段自动写入
-
insertFill:插入时对字段的填充
-
updateFill:更新时对字段的填充
-
MetaObject:操作Java对象的工具类。它提供了一系列方法,可以方便地对Java对象进行属性的读取、写入和判断等操作。(Mybatis提供)
-
[yudao-module-system-biz]
-
/get-unread-count接口暂时写一个空实现,不让页面报错 -
用户模块提供
/system/user/list-all-simple接口,获取用户精简信息列表。供部门管理使用 -
部门管理
-
数据库模型
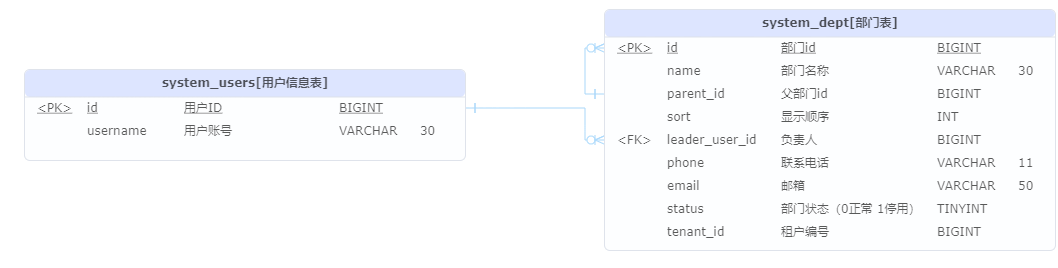
-
CRUD
validateForCreateOrUpdate()方法:- 校验自己是否存在
- 校验父部门的有效性
- 不能设置自己为父部门
- 父岗位是否存在校验
- 父部门不能是原来的子部门(需要递归校验所有子部门)
-
-

-
[yudao-spring-boot-starter-mybatis]
BaseMapperX:在 MyBatis Plus 的BaseMapper的基础上拓展,提供更多的能力,简化dal层代码书写-
增强
selectOne() -
增强
selectList() -
提供
insertBatch() -
提供
updateBatch() -
提供
saveOrUpdateBatch()
-
LambdaQueryWrapperX:拓展 MyBatis PlusQueryWrapper类- 拼接条件的方法,增加 xxxIfPresent 方法,用于判断值不存在的时候,不要拼接到条件中。
- 重写父类方法,方便链式调用
-
[yudao-common]
-
分页查询支持
-
[yudao-spring-boot-starter-mybatis]
- 分页查询支持
-
[yudao-module-system-biz]
-
岗位管理数据库模型
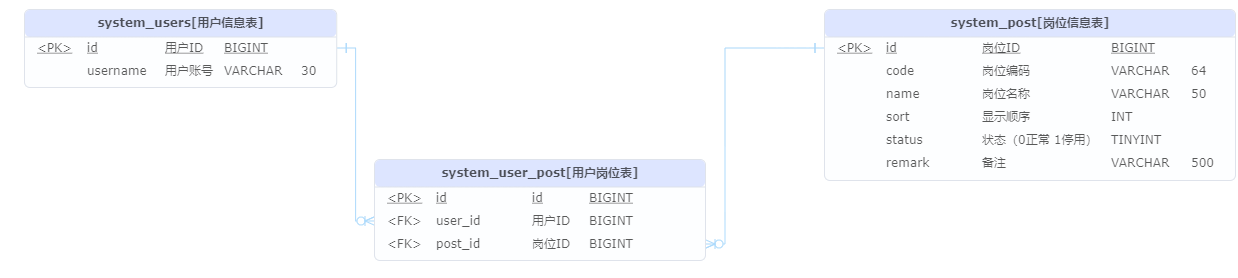
-
CRUD
-

- [yudao-spring-boot-starter-security]
- 配置密码编码器
PasswordEncoder
- 配置密码编码器
- [yudao-module-system-biz]
- 登录接口使用密码编码器验证密码
-
[yudao-module-system-biz]
-
用户管理数据库模型
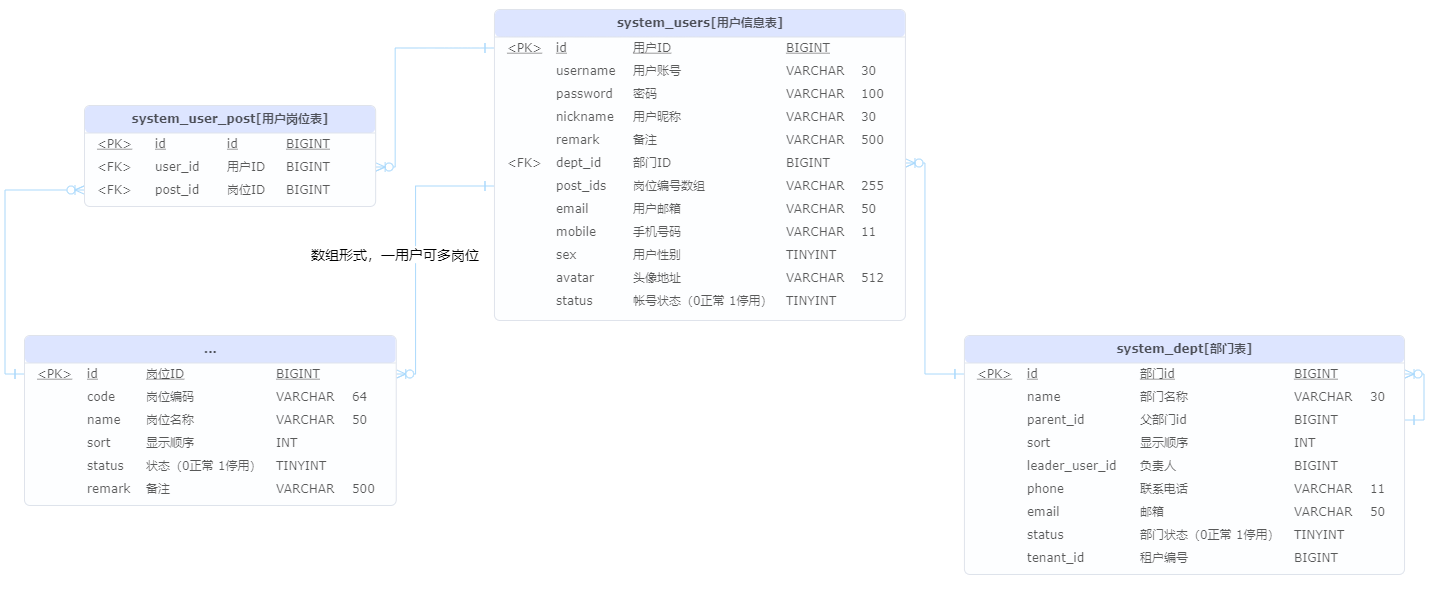
-
CRUD
-
检验用户正确性
- 校验用户存在
- 校验用户名唯一
- 校验手机号唯一
- 校验邮箱唯一
- 校验部门处于开启状态
- 校验岗位处于开启状态(所选的多个岗位)
-
更新用户岗位
- 计算应新增岗位:计算集合的单差集,即只返回【前端页面传递的岗位编号集合】中有,但是【该用户数据库记录中所拥有岗位编号集合】中没有的元素
- 计算应删除岗位:计算集合的单差集,即只返回【该用户数据库记录中所拥有岗位编号集合】中有,但是【前端页面传递的岗位编号集合】中没有的元素
- 执行新增和删除
CollUtil.subtract():求单差集CollectionUtils.singleton(T o):返回仅包含指定对象的不可变集。- o不可变
- 同时不可移除该元素。
removeIf方法会报错。 - 这样设计应该是为了防止用户误操作
-
用户分页查询-按部门查询时
- 递归查询获取到当前部门的所有子部门(子子孙孙部门)
- 按当前部门+所有子部门作为部门条件查询用户列表
-
创建用户是密码加密后落库
- 使用spring security的
PasswordEncoder对密码加密后落库
- 使用spring security的
-
- @DateTimeFormat:用于请求参数(例如控制器方法的参数)上,以指定日期时间格式化规则,以便在请求处理期间将日期时间字符串转换为 Java 对象()。
-

-
[yudao-common]
-
自定义Bean Validation(
@Mobile同理)-
自定义验证注解
@InEnum:用于校验参数是否在枚举值范围内@Constraint:@Constraint是 Bean Validation 中的注解,用于创建自定义验证注解。validatedBy属性:validatedBy属性是@Constraint注解的一部分,它接受一个验证器类或验证器类的数组。- Bean Validation 会根据参数字段的类型选择合适的验证器进行验证。
-
自定义验证器
InEnumValidator和InEnumCollectionValidatorInEnumValidator:验证参数类型为Integer的字段的值InEnumCollectionValidator:验证参数类型为Collection<Integer>>的字段的值
ConstraintValidator:- 这是 Bean Validation 框架提供的一个接口,用于创建自定义验证器。
initialize: 在验证器初始化时调用,你可以在这里执行一些初始化操作。isValid: 用于实际验证逻辑的方法,它接收被注解的字段或参数的值,并返回一个布尔值,表示验证是否通过。
-
辅助验证的接口
IntArrayValuable- 辅助@InEnum的验证器获取用于校验的枚举的值
@Target注解:@Target是一个元注解,用于指定注解的使用范围。ElementType.METHOD:可以用于方法。ElementType.FIELD:可以用于字段。ElementType.ANNOTATION_TYPE:可以用于其他注解。ElementType.CONSTRUCTOR:可以用于构造函数。ElementType.PARAMETER:可以用于方法参数。ElementType.TYPE_USE:可以用于类型使用处,例如在泛型中。
@Retention注解:@Retention是另一个元注解,用于指定注解的保留策略。在这里,@InEnum注解的保留策略是RetentionPolicy.RUNTIME,表示这个注解将在运行时保留,以便在运行时可以通过反射获取注解信息。
-
-
-
[yudao-spring-boot-starter-mybatis]
-
自定义
TypeHandler- 自定义Mybatis Plus类型处理器
JsonLongSetTypeHandler:实现数据库字符串字段和 Set 并且泛型为 Long的java对象的自动转换
AbstractJsonTypeHandler:是 MyBatis Plus 框架中的一个抽象类,用于处理数据库字段与 Java 中的 JSON 类型之间的转换。parse():json字符串转jaa对象toJson:java对象转json字符串
- 自定义Mybatis Plus类型处理器
-
使用
TypeHandler/** * 岗位编号数组 */ @TableField(typeHandler = JsonLongSetTypeHandler.class) private Set<Long> postIds;
-
-
自定义
AuthenticationEntryPoint类AuthenticationEntryPointImpl.java- 用户登录过期后返回错误码401,前端接收响应后自动跳转到登录页
AuthenticationEntryPoint:即使用户已经登录,但由于某些原因(例如会话过期或凭证失效),仍然无法访问受保护的资源。在这种情况下,AuthenticationEntryPoint也会被触发。
- [yudao-module-system-biz]
- 角色管理数据库模型

- CRUD
- 超级管理员(用code区分),不允许创建
- 内置角色不允许操作
- 角色管理数据库模型

- [yudao-module-system-biz]
-
菜单数据库模型
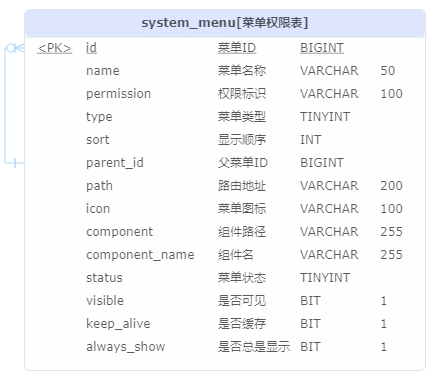
- 菜单id自关联
permission:- 权限标识:一般格式为:${系统}:${模块}:${操作} 例如说:system:admin:add,即 system 服务的添加管理员。
- 仅按钮和菜单上需填写。目录不用
- 用法:
- 对后端接口的访问权限控制:
- 用户的角色拥有该菜单或按钮就拥有此
permission对应的@PreAuthorize("@ss.hasPermission('permission')")接口访问权限
- 用户的角色拥有该菜单或按钮就拥有此
- 对页面按钮的展示控制:
- 前端按钮上会标记对应
permission的值,与用户的权限进行匹配,匹配不上就不展示按钮- 原因:用户的角色未分配该按钮,权限信息中就不会有该
permission值,按钮就不会展示
- 原因:用户的角色未分配该按钮,权限信息中就不会有该
- 前端按钮上会标记对应
- 对后端接口的访问权限控制:
- type:目录、菜单、按钮(目录应该是任何人都能有权限访问,不控制权限)
- path:路由地址。如果 path 为 http(s) 时,则它是外链
- 组件地址:用途不明,可能是前端的vue文件,缓存时使用
- visible:是否可见。只有菜单、目录使用 当设置为 true 时,该菜单不会展示在侧边栏,但是路由还是存在。例如说,一些独立的编辑页面 /edit/1024 等等
- keepAlive:是否缓存 。只有菜单、目录使用,否使用 Vue 路由的 keep-alive 特性 注意:如果开启缓存,则必须填写 componentName 属性,否则无法缓存
- alwaysShow:是否总是显示。如果为 false 时,当该菜单只有一个子菜单时,不展示自己,直接展示子菜单
-
CRUD
- 校验父菜单存在
- 校验菜单(自己)
- 父菜单必须是目录或者菜单类型
- 存在子菜单,无法删除
- 存在bug:可设置自己的子菜单为父菜单
-

-
[yudao-module-system-biz]
- RBAC数据库模型
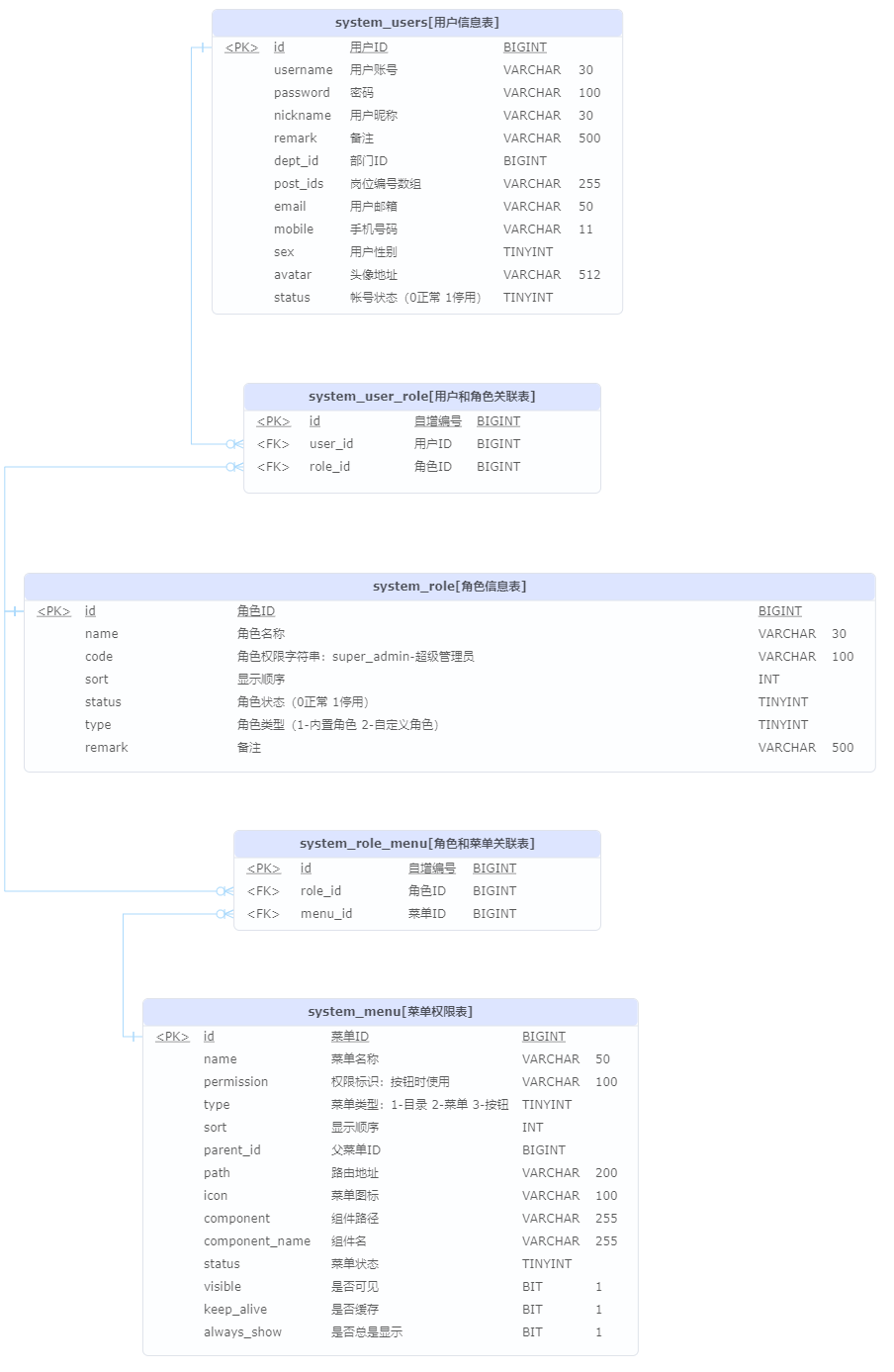
- 基于角色的权限控制。给用户分配角色即分配权限(菜单、按钮、接口等)
- 特殊角色:角色
code值为super_admin的为超级管理员,拥有所有权限。
- 编写登出接口
- 登出时删除token的redis缓存
- RBAC数据库模型

- [yudao-spring-boot-starter-web]
- jackson序列化:Java对象和JSON互相转换的过程
- LocalDateTimeDeserializer.java:LocalDateTime反序列化规则,会将毫秒级时间戳反序列化为LocalDateTime
JsonDeserializer<LocalDateTime>:表示它是一个用于反序列化LocalDateTime对象的自定义反序列化器。public static final LocalDateTimeDeserializer INSTANCE = new LocalDateTimeDeserializer();:这是一个静态的常量,表示一个单例的LocalDateTimeDeserializer实例。通常,为了节省资源,自定义反序列化器会以单例模式创建,因此通常会有一个常量来表示该实例。deserialize():覆盖了JsonDeserializer类中的deserialize方法,以提供自定义的反序列化逻辑。return LocalDateTime.ofInstant(Instant.ofEpochMilli(p.getValueAsLong()), ZoneId.systemDefault());:这是实际的反序列化逻辑。它执行以下操作:p.getValueAsLong():从JsonParser对象中获取时间戳的值,这个时间戳通常表示为毫秒数。Instant.ofEpochMilli(...):将毫秒时间戳转换为Instant对象,Instant是Java 8中表示时间戳的类。ZoneId.systemDefault():获取系统默认的时区。LocalDateTime.ofInstant(...):将Instant对象转换为LocalDateTime对象,考虑了时区信息,从而将时间戳转换为本地日期和时间。
- LocalDateTimeSerializer.java:LocalDateTime序列化规则,会将LocalDateTime序列化为毫秒级时间戳
JsonSerializer<LocalDateTime>:表示它是一个用于序列化LocalDateTime对象的自定义序列化器。serialize():覆盖了JsonSerializer类中的serialize方法,以提供自定义的序列化逻辑。public void serialize(LocalDateTime value, JsonGenerator gen, SerializerProvider serializers) throws IOException:这是serialize方法的定义,用于实际执行序列化操作。它接受三个参数:value:要序列化的LocalDateTime对象。gen:一个JsonGenerator对象,用于生成JSON数据。serializers:一个SerializerProvider对象,提供了序列化过程中的上下文信息。
gen.writeNumber(value.atZone(ZoneId.systemDefault()).toInstant().toEpochMilli());:这是实际的序列化逻辑。它执行以下操作:value.atZone(ZoneId.systemDefault()):将LocalDateTime对象与系统默认的时区(ZoneId.systemDefault())关联,以便将日期时间信息转换为特定时区下的ZonedDateTime对象。toInstant():将ZonedDateTime对象转换为Instant对象,以便获取时间戳信息。toEpochMilli():将Instant对象的时间戳转换为毫秒数。gen.writeNumber(...):使用JsonGenerator对象将毫秒时间戳写入JSON中作为数字。
- NumberSerializer.java:Long 序列化规则 会将超长 long 值转换为 string,解决前端 JavaScript 最大安全整数是 2^53-1 的问题
@JacksonStdImpl:这是一个Jackson的注解,用于指示该类是Jackson标准实现之一。它可以提高Jackson序列化框架的性能,因为Jackson会根据这个注解的存在来优化一些操作。- NumberSerializer 类继承了com.fasterxml.jackson.databind.ser.std.NumberSerializer类,这是Jackson提供的默认数字序列化器的基类。它提供了一些默认的数字序列化行为。
- MAX_SAFE_INTEGER 和 MIN_SAFE_INTEGER 常量:这些常量定义了安全整数的范围。安全整数是在JavaScript中可以精确表示的整数范围,通常是从 -9007199254740991 到 9007199254740991。这些常量将用于检查数字是否在安全整数范围内。
NumberSerializer 构造函数:这个构造函数接受一个Class参数,该参数表示要序列化的数字的具体类型,例如Integer.class、Long.class等。在构造函数中,它调用了父类的构造函数,将这个具体的类型传递给父类。serialize 方法:这是一个覆盖了父类方法的自定义序列化逻辑。在序列化数字之前,它首先检查数字是否在安全整数范围内(即在MIN_SAFE_INTEGER和MAX_SAFE_INTEGER之间)。如果在范围内,则使用父类的默认数字序列化方式进行序列化。如果超出了安全整数范围,则将数字值转换为字符串,并使用gen.writeString(value.toString())将其序列化为字符串形式。
- 配置objectMappers:
ObjectMapper:ObjectMapper是Jackson库中的一个类,用于序列化和反序列化Java对象和JSON。SimpleModule:SimpleModule它是Jackson库中用于定制序列化和反序列化规则的容器。.addSerializer()和.addDeserializer():添加序列化和反序列化规则注册SimpleModule到objectMapper:使用objectMappers参数中的每个ObjectMapper对象,通过循环调用objectMapper.registerModule(simpleModule)方法,将上述定义的SimpleModule注册到每个ObjectMapper中。这样,所有的ObjectMapper都将具有相同的自定义序列化和反序列化规则。
- LocalDateTimeDeserializer.java:LocalDateTime反序列化规则,会将毫秒级时间戳反序列化为LocalDateTime
- 自定义jackson序列化(反序列化)的思路:
- 创建自定义序列化器(
JsonSerializer和JsonDeserializer):在序列化(反序列化)器中,你可以定义如何将特定类型的Java对象转换为JSON或(JSON转Java对象)。 - 注册自定义序列化器:需要将(自定义序列化器)注册到Jackson的ObjectMapper中。这可以通过调用objectMapper.registerModule或objectMapper.setSerializerFactory等方法来完成。
- 标注Java对象(应该是和上一个步骤二选一):如果你希望自定义序列化应用于特定类型的Java对象,你可以使用Jackson的注解,如@JsonSerialize(using = YourCustomSerializer.class),将自定义序列化器与对象类关联起来。
- 创建自定义序列化器(
- jackson序列化:Java对象和JSON互相转换的过程
- [yudao-module-system-biz]
- 租户管理数据库模型
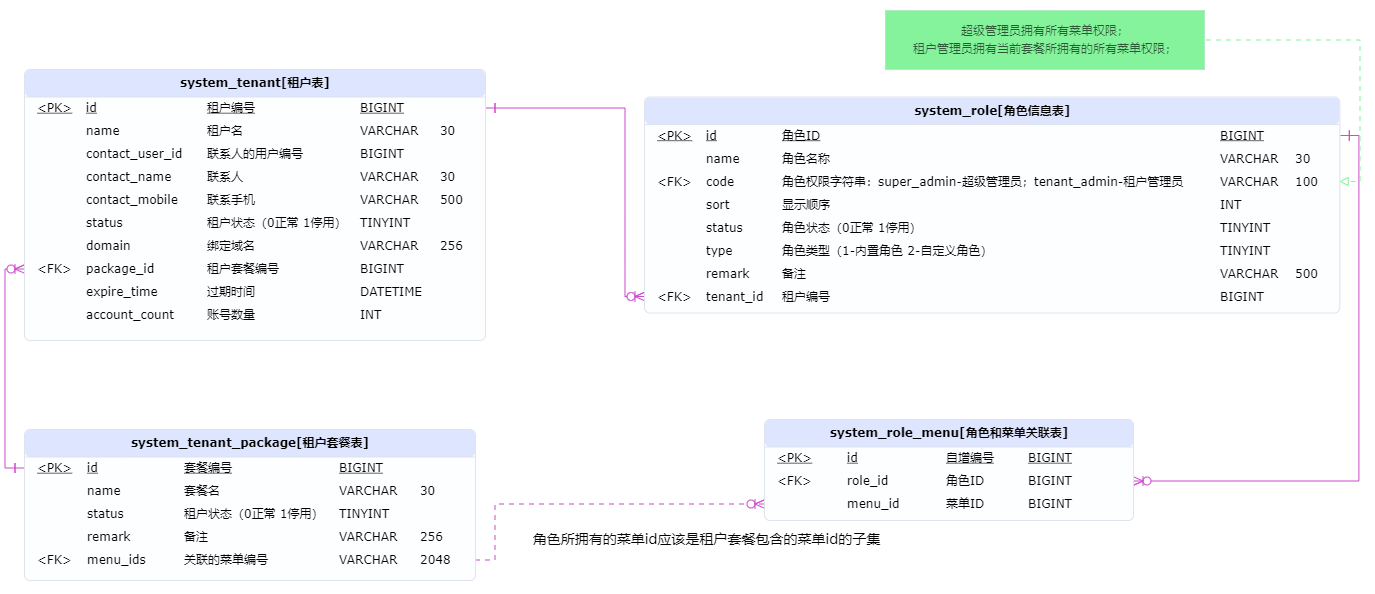
- 租户套餐表:主要用于控制租户可使用的菜单权限
- 租户表:
- 用于划分不同租户出来,隔离数据
- 控制租户的过期时间
- 控制租户下最大账号数量等
- crud
- 租户创建:
- 创建租户,配置租户套餐等
- 创建默认租户管理员角色
- 给默认租户管理员配置选中的租户套餐所拥有的所有菜单权限
- 创建默认租户管用户,并赋予租户管理员角色
- 配置该默认用户为当前租户联系人
- 租户更新:
- 若租户套餐发生变化时,需要修改该租户下所有角色的菜单权限
- 租户套餐创建:
- 配置租户可拥有的菜单权限
- 租户套餐修改:
- 若租户套餐菜单权限发生变化,需要同步更新使用了该租户套餐的所有租户的旗下所有角色的菜单权限
- 租户套餐删除:
- 校验是否还有使用该租户套餐的租户,无租户使用后方能删除
- 内置租户:
- 本项目默认配置了租户套餐id为0的内置租户套餐。
- 租户套餐id为0的内置租户不可删除
- 租户创建:
- 租户管理数据库模型

-
yudao-spring-boot-starter-biz-tenant
-
多租户Web的封装
- TenantContextWebFilter.java:多租户 Context Web 过滤器
- 将请求 Header 中的 tenant-id 解析出来,添加到
TenantContextHolder中,这样后续的 DB 等操作,可以获得到租户编号。 TenantContextHolder:多租户上下文 HolderOncePerRequestFilter:一次请求过滤器,保证只执行一次
- 将请求 Header 中的 tenant-id 解析出来,添加到
- TenantContextHolder.java:多租户上下文 Holder
- 存取租户id
- 全局忽略租户开关
TransmittableThreadLocal:能够在多线程环境中传递变量的值
- 配置多租户 Context Web 过滤器
@Bean public FilterRegistrationBean<TenantContextWebFilter> tenantContextWebFilter() { FilterRegistrationBean<TenantContextWebFilter> registrationBean = new FilterRegistrationBean<>(); registrationBean.setFilter(new TenantContextWebFilter()); registrationBean.setOrder(WebFilterOrderEnum.TENANT_CONTEXT_FILTER); return registrationBean; }
registrationBean.setOrder(WebFilterOrderEnum.TENANT_CONTEXT_FILTER):保证过滤器在Spring Security Filter的过滤器之前。便于在Spring Security中使用到TenantContextHolder中存放的租户的值
- TenantContextWebFilter.java:多租户 Context Web 过滤器
-
多租户DB的封装
- TenantDatabaseInterceptor.java:MP的租户处理器
TenantLineHandler:租户处理器,主要用于在 SQL 查询中动态注入租户标识条件,以确保不同租户之间的数据隔离。getTenantId():获取租户 ID 值表达式,SQL中动态注入租户标识条件时使用ignoreTable(String tableName):根据表名判断是否忽略拼接多租户条件getTenantIdColumn:获取租户字段名
- 配置租户拦截器:
@Bean public TenantLineInnerInterceptor tenantLineInnerInterceptor(TenantProperties properties, MybatisPlusInterceptor interceptor) { TenantLineInnerInterceptor inner = new TenantLineInnerInterceptor(new TenantDatabaseInterceptor(properties)); // 添加到 interceptor 中 // 需要加在首个,主要是为了在分页插件前面。这个是 MyBatis Plus 的规定 MyBatisUtils.addInterceptor(interceptor, inner, 0); return inner; }
TenantLineInnerInterceptor:MP的租户拦截器,它在 MyBatis 执行 SQL 语句之前拦截并修改 SQL 查询,以注入租户标识条件。- 将租户拦截器置于拦截器首位
TenantLineInnerInterceptor和TenantLineHandler:TenantLineInnerInterceptor 依赖于 TenantLineHandler 的实现。当你使用 TenantLineInnerInterceptor 时,你需要为其配置一个具体的 TenantLineHandler 的实现,这个实现会处理租户标识的获取和注入逻辑。
- TenantBaseDO.java:拓展多租户的 BaseDO 基类
tenantId:定义租户字段名("tenant_id")
- TenantProperties.java:多租户配置
enable:租户开关(默认开启,其实没多大用处)ignoreUrls:需要忽略多租户的请求。默认情况下,每个请求需要带上 tenant-id 的请求头。但是,部分请求是无需带上的,例如说获取验证码接口ignoreTables:需要忽略多租户的表。即默认所有表都开启多租户的功能,需忽略的在此配置
- TenantDatabaseInterceptor.java:MP的租户处理器
-
多租户Security的封装
- TenantSecurityWebFilter.java:多租户 Security Web 过滤器
- 如果是登陆的用户,校验是否有权限访问该租户,避免越权问题。
- 如果请求未带租户的编号,检查是否是忽略的 URL,否则也不允许访问。
- 校验租户是否合法,例如说被禁用、到期
ApiRequestFilter:在shouldNotFilter()方法中设置只过滤 API 请求的地址
- 配置多租户 Security Web 过滤器
@Bean public FilterRegistrationBean<TenantSecurityWebFilter> tenantSecurityWebFilter(TenantProperties tenantProperties, WebProperties webProperties, GlobalExceptionHandler globalExceptionHandler, TenantFrameworkService tenantFrameworkService) { FilterRegistrationBean<TenantSecurityWebFilter> registrationBean = new FilterRegistrationBean<>(); registrationBean.setFilter(new TenantSecurityWebFilter(tenantProperties, webProperties, globalExceptionHandler, tenantFrameworkService)); registrationBean.setOrder(WebFilterOrderEnum.TENANT_SECURITY_FILTER); return registrationBean; }
registrationBean.setOrder(WebFilterOrderEnum.TENANT_SECURITY_FILTER);:保证在 Spring Security 过滤器后面
- TenantSecurityWebFilter.java:多租户 Security Web 过滤器
-
TenantUtils.java :多租户 Util
execute(Long tenantId, Runnable runnable):使用指定租户,执行对应的逻辑。让业务代码和租户获取、切换的逻辑解耦
-
-
[yudao-common]
-
Cache 工具类
public static <K, V> LoadingCache<K, V> buildAsyncReloadingCache(Duration duration, CacheLoader<K, V> loader) { return CacheBuilder.newBuilder() // 只阻塞当前数据加载线程,其他线程返回旧值 .refreshAfterWrite(duration) // 通过 asyncReloading 实现全异步加载,包括 refreshAfterWrite 被阻塞的加载线程 .build(CacheLoader.asyncReloading(loader, Executors.newCachedThreadPool())); }
这代码片段是一个Java类
CacheUtils,其中定义了一个名为buildAsyncReloadingCache的静态方法,用于构建异步刷新(Asynchronous Reloading)的缓存。它使用了Google Guava缓存库(CacheBuilder)和Guava CacheLoader来实现缓存的创建。让我解释这段代码的关键部分:
-
LoadingCache<K, V>:LoadingCache是Google Guava库中的接口,用于表示具有加载功能的缓存。它支持自动加载缓存项,如果缓存中没有请求的数据,它将使用CacheLoader接口的实现来加载数据。 -
buildAsyncReloadingCache方法:这是一个公共静态方法,接受两个参数,一个是Duration类型的时间段(表示缓存项的刷新时间间隔),另一个是CacheLoader<K, V>类型的加载器。 -
CacheBuilder.newBuilder():这是Google Guava库中的CacheBuilder类的静态方法,用于创建缓存构建器。它允许你配置和定制缓存的行为。 -
.refreshAfterWrite(duration):这行代码配置了缓存的刷新策略。它告诉缓存,如果某个缓存项在指定的duration时间内没有被访问,那么缓存将异步刷新这个缓存项,以确保数据的新鲜性。duration是buildAsyncReloadingCache方法的第一个参数。 -
.build(CacheLoader.asyncReloading(loader, Executors.newCachedThreadPool())):这行代码创建并返回LoadingCache实例。它使用了CacheLoader.asyncReloading方法,该方法接受一个loader和一个Executor。loader是CacheLoader的实现,它定义了如何加载缓存项的逻辑。Executors.newCachedThreadPool()创建了一个可缓存线程池,用于执行异步刷新任务。
所以,
buildAsyncReloadingCache方法的目的是创建一个支持异步刷新的缓存。当某个缓存项过期后,它不会阻塞请求线程来刷新数据,而是使用线程池中的线程异步地执行刷新操作,以提高性能和响应性。这个方法可以在需要使用缓存的地方调用,以创建一个具有异步刷新功能的缓存对象,这在某些情况下可以提高应用程序的性能和数据的新鲜度。
-
-
-
[yudao-module-system-biz]
- 登录时用户信息存放租户id
- 编写校验租户是否合法的逻辑
- 字典管理数据库模型


- yudao-spring-boot-starter-biz-dict:数据字典组件。主要作用为通过将字典缓存在内存中,保证性能
- DictFrameworkUtils.java :数据字典工具类
- 缓存数据。K:字典类型-字典值,V:字典标签
- 缓存数据K。:字典类型-字典标签,V:字典值
String getDictDataLabel(String dictType, String value):通过字典类型-字典值获取字典标签String parseDictDataValue(String dictType, String label):解析字典类型-字典标签获取到字典值DictDataApi:yudao-module-system-biz模块提供的从数据中通过字典类型-字典值获取字典标签和解析字典类型-字典标签获取到字典值的Api@SneakyThrows:在方法上使用@SneakyThrows,以指示方法可能会抛出受检异常,而无需显式地捕获或声明这些异常。Lombok 在编译时会生成必要的异常处理代码,从而减少了代码的复杂性。
- DictFrameworkUtils.java :数据字典工具类
- yudao-spring-boot-starter-excel:excel组件。基于 EasyExcel 实现 Excel 相关的操作
- ExcelUtils.java :Excel 工具类,提供excel的读写功能
- 提供excel文件读写功能
autoCloseStream(false):禁用EasyExcel默认的自动流关闭功能,交给 Servlet 自己处理,Servlet容器通常会在一个请求结束后自动关闭响应流。Class<T> head:会配合head类字段上的@ExcelProperty,自动生成excel的列头
- DictConvert.java :Excel 数据字典转换器。用于java和excel之间字典数据的互相转换
Converter: EasyExcel中用于执行Excel数据和Java对象之间的相互转换的接口Converter<Object>:作用于Object类型的字段的转换convertToJavaData(...):将 Excel 对象转换为 Java 对象convertToExcelData(...):将 Java 对象转换为 Excel 对象- 使用
DictFrameworkUtils类完成,字典值与字典标签的转换 - DictFormat.java :用于标注字段的字典类型,辅助
DictConvert完成字典值与字典标签的转换
- JsonConvert.java 与 MoneyConvert.java :同
DictConvert
- ExcelUtils.java :Excel 工具类,提供excel的读写功能
- [yudao-module-system-biz]中的excel导入导出
- 【租户管理】excel导出
- 【用户管理】导出用户、导入用户模板下载、导入用户
- 导入用户时没有校验最大租户配额
- 【角色管理】excel导出
- 【岗位管理】excel导出
- 【字典管理】字典类型导出、字典数据导出
-
[yudao-spring-boot-starter-security]:启用
@PreAuthorize接口权限控制的支持-
@EnableGlobalMethodSecurity(prePostEnabled = true):开启Spring Security的@PreAuthorize支持@EnableGlobalMethodSecurity:启用方法级别的安全性控制prePostEnabled = true:用于启用方法级别的安全控制中的@PreAuthorize和@PostAuthorize注解@PreAuthorize:用于在方法执行前进行权限验证。它允许你定义方法级别的安全控制规则,只有当规则中指定的条件满足时(EL表达式结果为true时),方法才能被执行。
-
SecurityFrameworkService.java:定义权限相关的校验操作。用于
@PreAuthorize的EL表达式中使用 -
配置
SecurityFrameworkService的bean,取别名ss简化引用@Bean("ss") // 使用 Spring Security 的缩写,方便使用 public SecurityFrameworkService securityFrameworkService(PermissionApi permissionApi) { return new SecurityFrameworkServiceImpl(permissionApi); }
-
-
[yudao-module-system-biz]:应用
@PreAuthorize完成接口权限控制-
@PreAuthorize("@ss.hasPermission('system:dept:query')")
-
- 通知公告数据库模型


-
AdminAuthServiceImpl.java:登录登出时记录日志
-
LoginLogController.java:登录日志查询
-
登录日志数据库模型

- 用户类型
- 登录日志类型
- 登录结果

-
yudao-spring-boot-starter-biz-operatelog:操作日志组件。基于AOP实现
-
OperateLogAspect.java :日志切面
-
日志记录条件(满足如下任一条件,则会进行记录)
-
使用 @Operation + 非 @GetMapping的接口
-
使用 @OperateLog 注解
但是,如果声明 @OperateLog 注解时,将 enable 属性设置为 false 时,强制不记录。
-
-
异步记入日志
-
拓展:拓展明细和拓展字段
- OperateLogUtils.java:记录操作明细和拓展字段的工具类
-
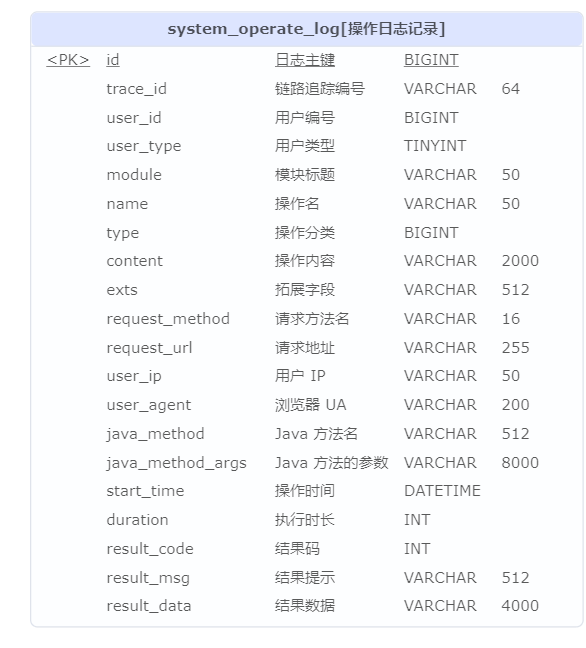
-
module属性:操作模块,例如说:用户、岗位、部门等等。为空时,默认会读取类上的 Swagger@Tag注解的name属性。name属性:操作名,例如说:新增用户、修改用户等等。为空时,默认会读取方法的 Swagger@Operation注解的summary属性。type属性:操作类型,在 OperateTypeEnum.java 枚举。目前有GET查询、CREATE新增、UPDATE修改、DELETE删除、EXPORT导出、IMPORT导入、OTHER其它,可进行自定义
-
操作日志记录内容
-

-
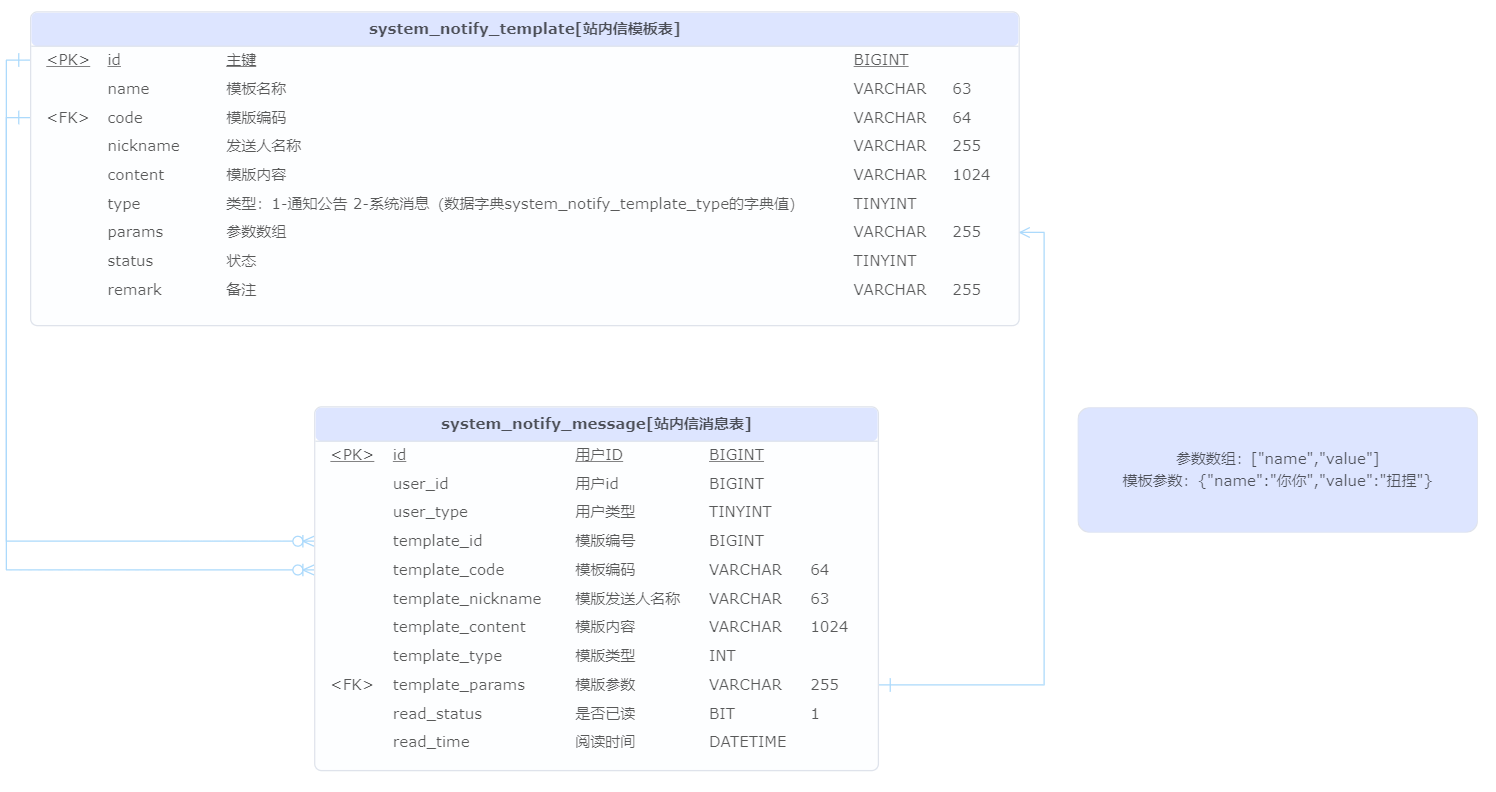
站内信模板
- 模板内容:使用 {var} 作为占位符,例如说 {name}、{code} 等
- 解析模板内容占位符名称
ReUtil.findAllGroup1(Pattern pattern, CharSequence content):返回与正则表达式模式匹配的文本内容,只返回正则表达式中的第一个分组且只包含占位符部分。(hutool提供)ReUtil.findAllGroup0(Pattern pattern, CharSequence content):返回所有与正则表达式模式匹配的文本内容。(hutool提供)
String content = "Date: 2023-10-14, Time: 12:30 PM"; Pattern pattern = Pattern.compile("Date: (\\d{4}-\\d{2}-\\d{2}), Time: (\\d{2}:\\d{2} [APM]{2})"); List<String> allMatches0 = ReUtil.findAllGroup0(pattern, content); List<String> allMatches1 = ReUtil.findAllGroup1(pattern, content); // allMatches0 包含完整的匹配项,包括所有分组内容 // ["Date: 2023-10-14, Time: 12:30 PM", "2023-10-14", "12:30 PM"] // allMatches1 只包含第一个分组的匹配内容 // ["2023-10-14"]
- 填充模板内容
String StrUtil.format(CharSequence template, Map<?, ?> map):(hutool提供,使用这个)- 将
这是模板内容{name}、{code}转换为这是模板内容张三、编码。其中map的key为name和code,对应值会填充在模板内容当中
- 将
-
站内信
- 是否已读
-
站内信管理数据库模型

-
错误码管理数据库模型

-
错误码管理CRUD(数据库操作):ErrorCodeController.java
- 此处的C和U操作后,错误码类型会转为2-手动编辑
- 错误码类型:1-自动生成(从本地错误码常量接口中解析生成) 2-手动编辑
-
错误码自动更新和本地错误码自动写入: yudao-spring-boot-starter-biz-error-code
- 自动更新:ErrorCodeLoaderImpl.java
- 将数据库中的错误码(主要针对
本地错误码自动写入和错误码管理CU操作),更新到应用服务器缓存中(ServiceExceptionUtil#MESSAGES),实现异常提示信息自动更新 - 初始全量更新,后续增量更新
maxUpdateTime:缓存错误码的最大更新时间,用于后续的增量轮询,判断是否有更新@EventListener(ApplicationReadyEvent.class):应用程序启动完成后执行自动更新@Scheduled(fixedDelay = REFRESH_ERROR_CODE_PERIOD, initialDelay = REFRESH_ERROR_CODE_PERIOD)initialDelay:首次执行任务的延迟时间,单位毫秒fixedDelay:任务执行的固定延迟时间,单位毫秒
- 将数据库中的错误码(主要针对
- 本地错误码自动写入:ErrorCodeAutoGeneratorImpl.java
- 解析
yudao.error-code.constants-class-list指定的本地错误码常量接口ClassUtil.loadClass(String className):加载类并初始化(hutool提供)
- insertOrUpdate进数据库
更新有三个前置条件
- 只更新自动生成的错误码,即 Type 为 ErrorCodeTypeEnum.AUTO_GENERATION
- 分组 applicationName 必须匹配,避免存在错误码冲突的情况
- 错误提示语存在差异
- 解析
- 自动更新:ErrorCodeLoaderImpl.java

业务异常为什么不直接return CommonResult 因为 Spring @Transactional 声明式事务,是基于异常进行回滚的,如果使用 CommonResult 返回,则事务回滚会非常麻烦
-
敏感词数据库模型
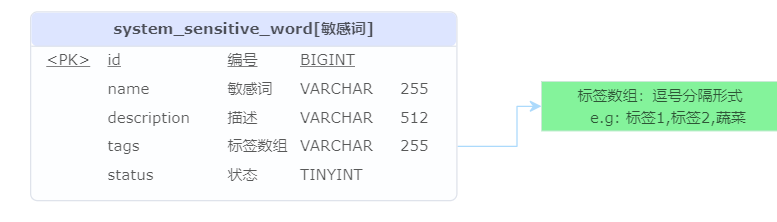
- tags:标签数组。标签即场景,可按不同场景校验敏感词
-
敏感词实现原理-前缀树算法:SimpleTrie.java
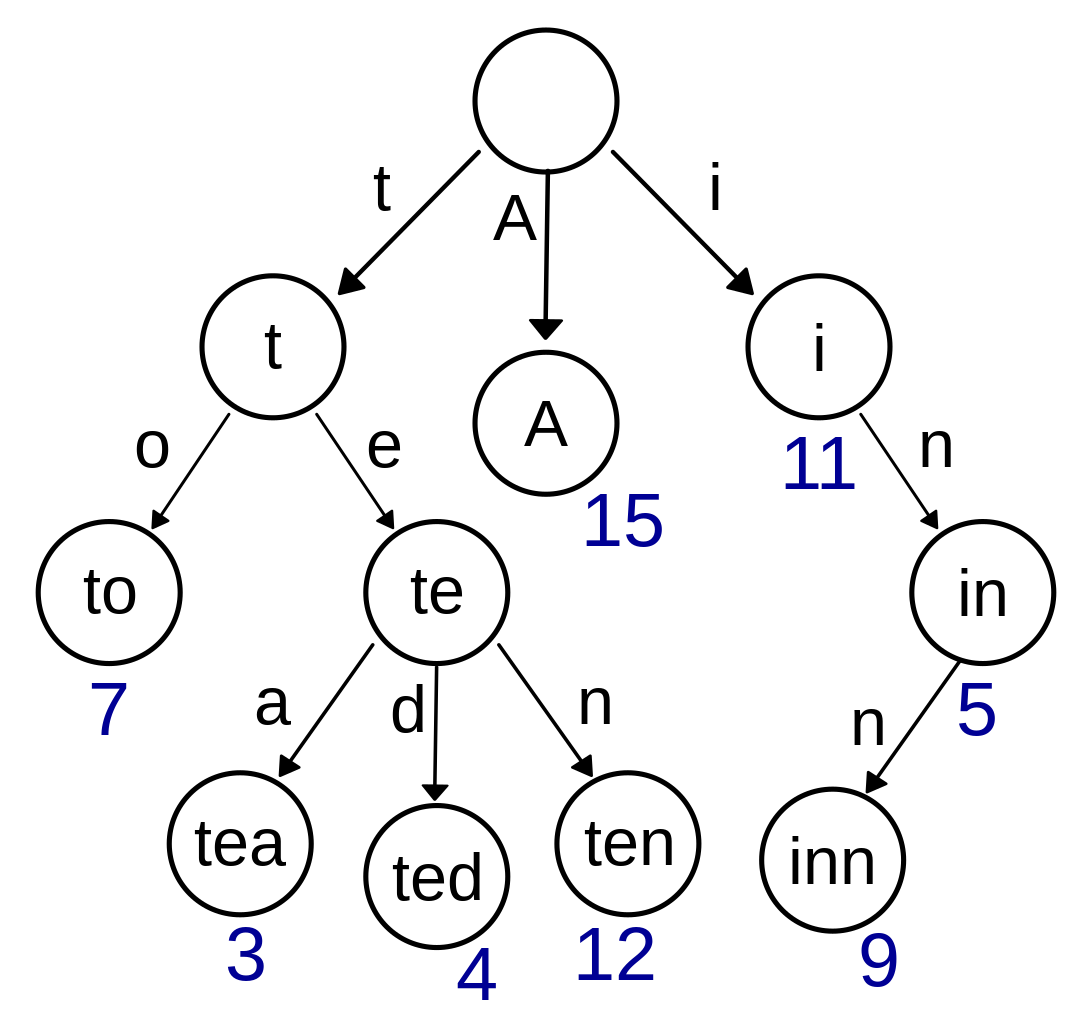
敏感词的前缀树:节点只存单个字符(即前缀),从根节点—>子子孙孙节点组成完整字符串根节点:为空字符串(可无)children:整棵前缀树。本例为HashMap<String,V>结构。V为子节点,无根节点。V的类型仍然为HashMap<String,V>。无限累加下去构成敏感词树.- 成员变量
Character CHARACTER_END = '\0';:标记敏感词的终止(放在一个子节点链路的末尾)。用成员变量
CHARACTER_END来标记敏感词的终止的目的: 从HashMap中get key结果为null,不能判断该key不存在,还是该key存在但值为null。因此使用CHARACTER_END来代替敏感词的终止 即从children中get字符的结果为null,代表该字符非敏感词,为CHARACTER_END,则代表该字符为敏感词,且是敏感词的终止标记。 public SimpleTrie(Collection<String> strs):构建敏感词树短敏感词在前:构建敏感词树时,将原敏感词列表按字符串长度升序排,使短字符串敏感词在前,后再构建树。这样包含相同前缀敏感词的较长敏感词无需存入树种。
boolean isValid(String text):验证文本是否合法,即不包含敏感词。true-合法 false-不合法recursion(...):验证文本从指定位置开始,是否不包含某个敏感词
-
敏感词CRUD和校验、缓存:SensitiveWordServiceImpl.java
volatile SimpleTrie defaultSensitiveWordTrie:默认的敏感词的字典树缓存,包含所有敏感词。校验敏感词忽略标签时使用。volatile保证多线程可见(没有体现出价值)。Map<String, SimpleTrie> tagSensitiveWordTries:按标签分组的敏感词树。用于按标签校验敏感词的场景initLocalCache():敏感词缓存初始化。cud时需调用refreshLocalCache():敏感词缓存定时更新。增量更新。


- IP 功能:查询 IP 对应的城市信息。
- IPUtils.java
- 基于
ip2region。离线IP地址定位库。 - 使用饿汉静态单例,构造函数中加载IP库。实现了类初始加载时加载IP库
- 基于
- IPUtils.java
- 城市功能:查询城市编码对应的城市信息。
- AreaUtils.java
- 使用饿汉静态单例,构造函数中加载地址库。实现了类初始加载时加载地址库
- 构建区域父子关系对象时使用两遍for循环实现
- AreaUtils.java
- 结合1和2,实现通过ip查地址
- 解决mapstruct项目编译时报错
[yudao-module-system-biz]中引入[yudao-spring-boot-starter-biz-ip],项目编译时所有mapstruct会报错
No target bean properties found: can't map Collection element "TenantPackageDO tenantPackageDO" to "TenantPackageSimpleRespVO tenantPackageSimpleRespVO". Consider to declare/implement a mapping method: "TenantPackageSimpleRespVO map(TenantPackageDO value)".通过在最外层pom中增加插件解决
<build> <pluginManagement> <plugins> <!-- maven-compiler-plugin 插件,解决 spring-boot-configuration-processor + Lombok + MapStruct 组合 --> <!-- https://stackoverflow.com/questions/33483697/re-run-spring-boot-configuration-annotation-processor-to-update-generated-metada --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>${maven-compiler-plugin.version}</version> <configuration> <annotationProcessorPaths> <path> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-configuration-processor</artifactId> <version>${spring.boot.version}</version> </path> <path> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>${lombok.version}</version> </path> <path> <groupId>org.mapstruct</groupId> <artifactId>mapstruct-processor</artifactId> <version>${mapstruct.version}</version> </path> </annotationProcessorPaths> </configuration> </plugin> </plugins> </pluginManagement> </build>
-
-
Spring Cache配置:YudaoCacheAutoConfiguration.java
- 启用缓存:
@EnableCaching RedisCacheConfigurationbean配置:redisCacheConfiguration(...)RedisCacheConfiguration:主要作用是为 Redis 缓存提供具体的配置,包括缓存的过期策略、序列化方式、键前缀、是否允许空值等等。@Primary: 若存在多个相同bean,以该bean为主- key分隔符设置使用 : 单冒号,而不是双 :: 冒号,避免 Redis Desktop Manager 多余空格
- 使用 JSON 序列化方式
- 设置
spring.cache.redis的属性- 统一设置过期时间等
RedisCacheManagerbean配置:redisCacheManager(...)RedisCacheManager:使用redis作为Spring Cache的缓存实现- 使用redisTemplate的连接工厂
- 创建一个非阻塞的
RedisCacheWriter - 创建一个支持自定义过期时间的
RedisCacheManager - 自定义过期时间的
RedisCacheManager:TimeoutRedisCacheManager.javaRedisCache createRedisCache(String name, RedisCacheConfiguration cacheConfig):为每个@Cacheable标注的方法,创建 Redis 缓存实例的方法。- 规则:在
Cacheable.cacheNames()格式为 "key#ttl" 时,# 后面的 ttl 为过期时间。单位为最后一个字母(支持的单位有:d 天,h 小时,m 分钟,s 秒),默认单位为 s 秒- 使用示例:@Cacheable(cacheNames = RedisKeyConstants.PERMISSION_MENU_ID_LIST+"#333s", key = "#permission")
- 解析
Cacheable.cacheNames()上配置的的过期时间 - 为该名为
Cacheable.cacheNames()的缓存,设置单独的过期时间
- 启用缓存:
-
@Cacheable:标注在方法上。无缓存时,执行完方法后添加缓存。命中缓存时直接返回缓存数据,无需执行方法。一般用于查询方法上@Cacheable(value = RedisKeyConstants.MENU_ROLE_ID_LIST, key = "#menuId"):缓存key为menu_role_ids:1139
@CachePut:标注在方法上。直接执行方法,执行完后,将结果缓存。一般用于更新方法上进行缓存更新。注意方法的返回结果类型应该同@Cacheable标注的方法结果类型@CacheEvict:标注在方法上。删除缓存。@CacheEvict(value = RedisKeyConstants.USER_ROLE_ID_LIST, key = "#userId"):删除单个缓存@CacheEvict(cacheNames = RedisKeyConstants.DEPT_CHILDREN_ID_LIST, allEntries = true):批量删除前缀为RedisKeyConstants.DEPT_CHILDREN_ID_LIST的缓存@CacheEvict(value = RedisKeyConstants.PERMISSION_MENU_ID_LIST, key = "#reqVO.permission",condition = "#reqVO.permission != null"):有条件的删除缓存
-
-
MenuServiceImpl#deleteMenu:删除菜单时删除该菜单授予给角色的菜单权限(删除role-menu)。MenuServiceImpl.java、PermissionServiceImpl.javaRoleServiceImpl#deleteRole:删除角色时删除该角色关联的用户(user-role)和菜单(role-menu)。RoleServiceImpl.javaAdminUserServiceImpl#createUser:创建用户时校验租户用户配额是否超限。AdminUserServiceImpl.javaAdminUserServiceImpl#deleteUser:删除用户时删除该用户关联的角色(user-role)。AdminUserServiceImpl.java
-
Redis 流数据模型
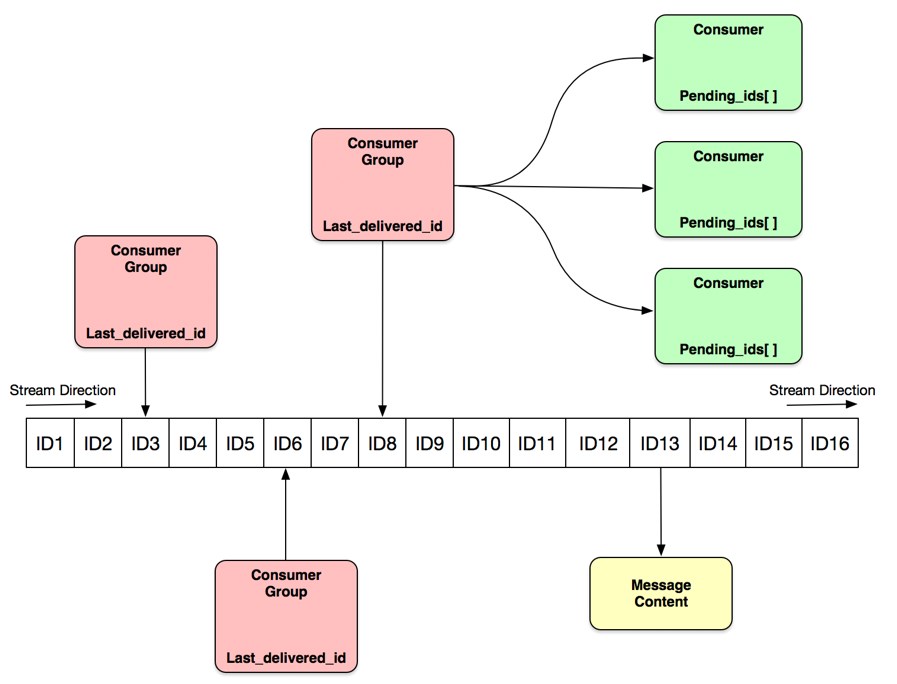
Redis Stream:Redis 流- Redis Stream的结构如上图,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。消息是持久化的,Redis 重启后,内容还在。
- 每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
Consumer Group:消费组- 每个 Stream 都可以挂多个消费组(Consumer Group),每个消费组会有个游标 last_delivered_id 在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。
- 每个消费组都有一个 Stream 内唯一的名称,消费组不会自动创建,它需要单独的指令 xgroup create 进行创建,需要指定从 Stream 的某个消息 ID 开始消费,这个 ID 用来初始化 last_delivered_id 变量。
- 每个消费组的状态都是独立的,相互不受影响。也就是说同一份 Stream 内部的消息会被每个消费组都消费到。
- 每个 Stream 都可以挂多个消费组(Consumer Group),每个消费组会有个游标 last_delivered_id 在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。
Consumer:消费者- 同一个消费组可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标 last_delivered_id 往前移动。
- 每个消费者有一个组内唯一名称。
-
redis mq点对点模式的使用(基于Redis Stream)
-
绑定消息队列:YudaoMQAutoConfiguration.java#redisStreamMessageListenerContainer(...)方法
-
绑定消费者、消费组、Redis Stream、消息监听
-
@Bean(initMethod = "start", destroyMethod = "stop"):initMethod:容器实例化bean后,执行该bean的start方法。destroyMethod:在 bean 销毁之前,执行该bean的stop方法
-
DefaultStreamMessageListenerContainer:默认消息监听容器- 创建一个
SimpleAsyncTaskExecutor,用于执行每个消费者任务对该redis stream消息链表消息的监听SimpleAsyncTaskExecutor:为每个任务启动一个新线程的实现,异步执行它。未重用线程。
- 创建一个
-
DefaultStreamMessageListenerContainerX:解决 Spring Data Redis + Redisson 结合使用时,Redisson 在 Stream 获得不到数据时,返回 null 而不是空 List,导致 NPE 异常。(经测试为偶发,很难复现)-
只能在相同包下继承
DefaultStreamMessageListenerContainer类(访问权限为default修饰:类仅可以被同一包中的类访问。) -
利用hutool的
ReflectUtil.invoke(...)执行父类的私有方法 -
修改父类
readFunction属性的值,解决NPE。该值为Function,调用原值执行apply方法,处理下结果则可解决NPE(Function<ReadOffset, List<ByteRecord>>) readOffset -> { List<ByteRecord> records = readFunction.apply(readOffset); //【重点】保证 records 不是空,避免 NPE 的问题!!! return records != null ? records : Collections.emptyList(); }
-
-
-
消息类:AbstractStreamMessage.java、AbstractStreamMessage.java
AbstractStreamMessage#getStreamKey():用于指定消息的stream key
-
发送消息:RedisMQTemplate.java#send(T message)
-
监听(消费)消息:AbstractStreamMessageListener.java、TestSendConsumer.java
-
-
点对点消息监听类执行流程
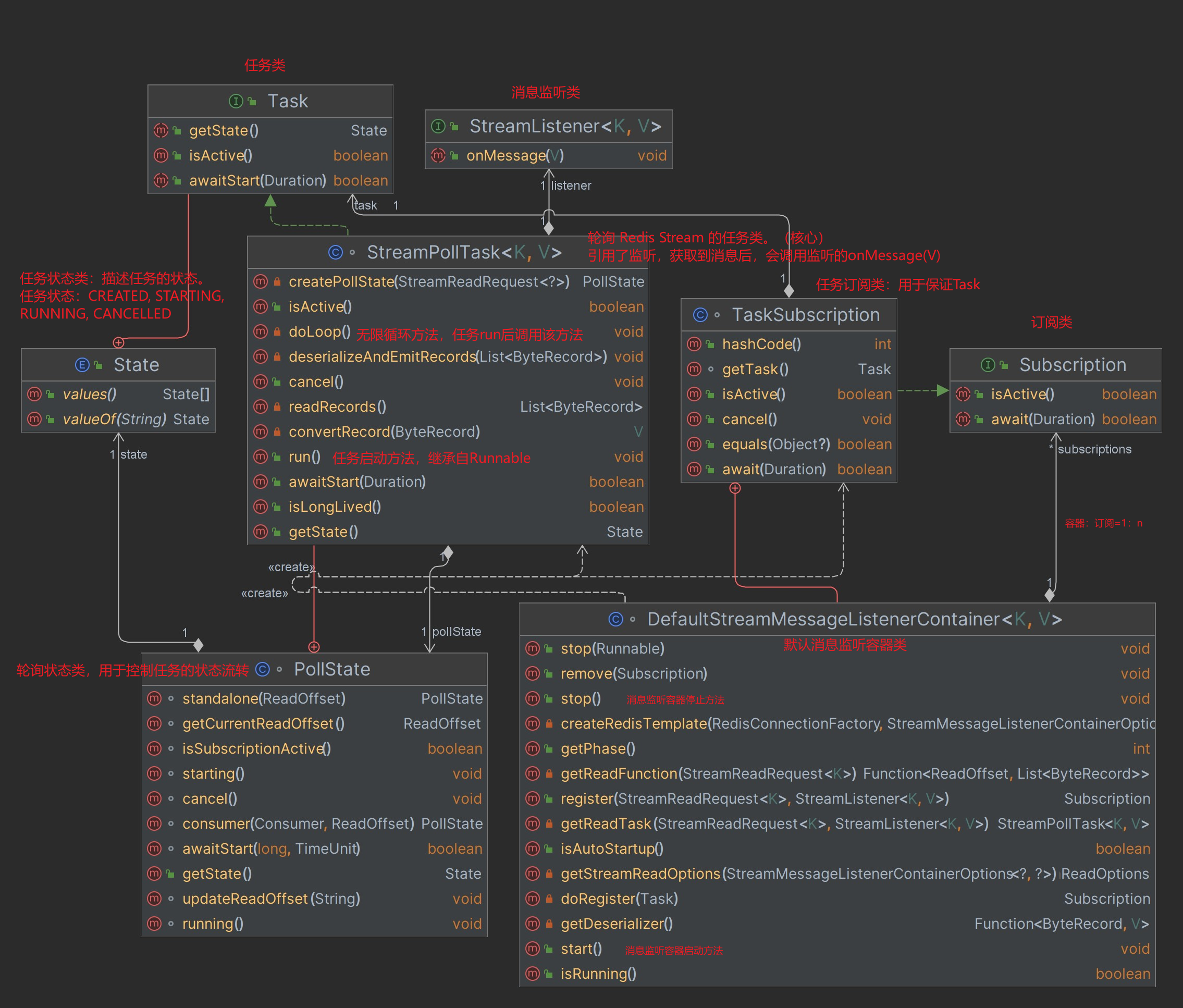
(各类的说明见上图)
- 执行流程:
DefaultStreamMessageListenerContainer#start-> 遍历ist<Subscription>-> 取出StreamPollTask-> 使用SimpleAsyncTaskExecutor为每个任务启动一个新线程的实现,异步执行
- 执行流程:


Redis Stream 消息消费超时后重新消费(定时任务) RedisPendingMessageResendJob.java
消费者内部会有一个状态变量 pending_ids,它记录了当前已经被客户端读取,但是还没有 ack 的消息。 如果客户端没有 ack,这个变量里面的消息 ID 就会越来越多,一旦某个消息被 ack,它就开始减少。 这个 pending_ids 变量在 Redis 官方被称为 PEL,也就是 Pending Entries List,这是一个核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了而没被处理。
-
redis的发布订阅模型
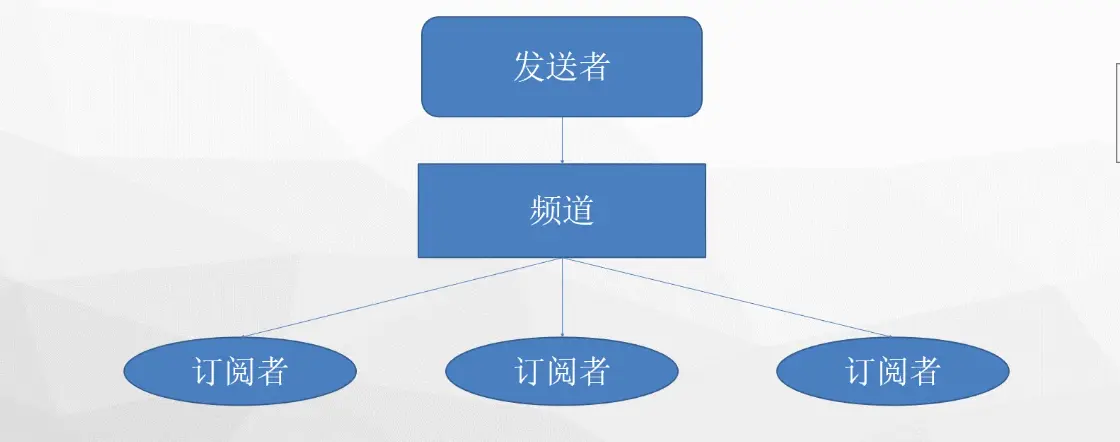
-
redis发布订阅模式的缺陷
- 无消费者时消息丢失
- 消息不能持久化,所以基本弃用。
- 应该可以结合redis stream实现可靠的redistribution stream。但也有可能redis stream建立多个消费组就实现了发布订阅的需求。

-
拦截器规范:RedisMessageInterceptor.java
public interface RedisMessageInterceptor { default void sendMessageBefore(AbstractRedisMessage message) { } default void sendMessageAfter(AbstractRedisMessage message) { } default void consumeMessageBefore(AbstractRedisMessage message) { } default void consumeMessageAfter(AbstractRedisMessage message) { } }
- 可插拔
- 拦截器先进后出
-
拦截器装配:
@Bean public RedisMQTemplate redisMQTemplate(StringRedisTemplate redisTemplate, List<RedisMessageInterceptor> interceptors) { RedisMQTemplate redisMQTemplate = new RedisMQTemplate(redisTemplate); // 添加拦截器 interceptors.forEach(redisMQTemplate::addInterceptor); return redisMQTemplate; }
-
拦截器应用原理:
-
/** * 发送 Redis 消息,基于 Redis pub/sub 实现 * * @param message 消息 */ public <T extends AbstractChannelMessage> void send(T message) { try { sendMessageBefore(message); // 发送消息 redisTemplate.convertAndSend(message.getChannel(), JsonUtils.toJsonString(message)); } finally { sendMessageAfter(message); } } /** * 发送 Redis 消息,基于 Redis Stream 实现 * * @param message 消息 * @return 消息记录的编号对象 */ public <T extends AbstractStreamMessage> RecordId send(T message) { try { sendMessageBefore(message); // 发送消息 return redisTemplate.opsForStream().add(StreamRecords.newRecord() .ofObject(JsonUtils.toJsonString(message)) // 设置内容 .withStreamKey(message.getStreamKey())); // 设置 stream key } finally { sendMessageAfter(message); } } private void sendMessageBefore(AbstractRedisMessage message) { // 正序 interceptors.forEach(interceptor -> interceptor.sendMessageBefore(message)); } private void sendMessageAfter(AbstractRedisMessage message) { // 倒序 for (int i = interceptors.size() - 1; i >= 0; i--) { interceptors.get(i).sendMessageAfter(message); } }
-
消费方:
-
redis stream:AbstractStreamMessageListener.java
@Override public void onMessage(ObjectRecord<String, String> message) { // 消费消息 T messageObj = JsonUtils.parseObject(message.getValue(), messageType); try { consumeMessageBefore(messageObj); // 消费消息 this.onMessage(messageObj); // ack 消息消费完成 redisMQTemplate.getRedisTemplate().opsForStream().acknowledge(group, message); // TODO 芋艿:需要额外考虑以下几个点: // 1. 处理异常的情况 // 2. 发送日志;以及事务的结合 // 3. 消费日志;以及通用的幂等性 // 4. 消费失败的重试,https://zhuanlan.zhihu.com/p/60501638 } finally { consumeMessageAfter(messageObj); } } private void consumeMessageBefore(AbstractRedisMessage message) { assert redisMQTemplate != null; List<RedisMessageInterceptor> interceptors = redisMQTemplate.getInterceptors(); // 正序 interceptors.forEach(interceptor -> interceptor.consumeMessageBefore(message)); } private void consumeMessageAfter(AbstractRedisMessage message) { assert redisMQTemplate != null; List<RedisMessageInterceptor> interceptors = redisMQTemplate.getInterceptors(); // 倒序 for (int i = interceptors.size() - 1; i >= 0; i--) { interceptors.get(i).consumeMessageAfter(message); } }
-
pub/sub:AbstractChannelMessageListener.java
@Override public final void onMessage(Message message, byte[] bytes) { T messageObj = JsonUtils.parseObject(message.getBody(), messageType); try { consumeMessageBefore(messageObj); // 消费消息 this.onMessage(messageObj); } finally { consumeMessageAfter(messageObj); } } private void consumeMessageBefore(AbstractRedisMessage message) { assert redisMQTemplate != null; List<RedisMessageInterceptor> interceptors = redisMQTemplate.getInterceptors(); // 正序 interceptors.forEach(interceptor -> interceptor.consumeMessageBefore(message)); } private void consumeMessageAfter(AbstractRedisMessage message) { assert redisMQTemplate != null; List<RedisMessageInterceptor> interceptors = redisMQTemplate.getInterceptors(); // 倒序 for (int i = interceptors.size() - 1; i >= 0; i--) { interceptors.get(i).consumeMessageAfter(message); } }
-
-
-
电子邮件的工作原理
邮件发送:电子邮件客户端(连接SMTP服务器发送邮件) ->SMTP服务器(解析收件人地址,提取@符后域名,解析DNS,连接POP3服务器或IMAP服务器,发送邮件)->POP3服务器或IMAP服务器(存放邮件)
邮件接收:电子邮件客户端(连接POP3服务器或IMAP服务器接收邮件)
-
电子邮件客户端: 发送和接收电子邮件的过程始于电子邮件客户端,这是您用来编写、发送和接收电子邮件的应用程序或工具,如Outlook、Gmail、Thunderbird等。
-
电子邮件服务器: 电子邮件服务器是用来存储和管理电子邮件的计算机或服务器。通常,有两种主要类型的服务器:
- SMTP服务器(Simple Mail Transfer Protocol):SMTP服务器用于发送电子邮件。当您编写一封电子邮件并点击“发送”时,您的电子邮件客户端将连接到SMTP服务器,将电子邮件发送给服务器。
- POP3服务器或IMAP服务器:POP3(Post Office Protocol 3)和IMAP(Internet Message Access Protocol)服务器用于接收电子邮件。这些服务器存储已发送的邮件,并允许电子邮件客户端从中检索邮件。
-
发送电子邮件: 当您编写一封电子邮件并点击“发送”时,您的电子邮件客户端将连接到SMTP服务器,并将电子邮件传输给SMTP服务器。SMTP服务器将电子邮件路由到目标接收者的电子邮件服务器。
-
接收电子邮件: 接收电子邮件的过程涉及到POP3或IMAP服务器。当您的电子邮件客户端检查新邮件时,它将连接到POP3或IMAP服务器,将新邮件下载到您的电子邮件客户端。
-
邮件传递: 一旦电子邮件到达接收者的电子邮件服务器,接收者可以使用电子邮件客户端或Web邮箱来查看和管理电子邮件。
-
邮件协议: 电子邮件通信遵循特定的邮件协议,如SMTP、POP3、IMAP等,以确保电子邮件的可靠传递和接收。这些协议规定了消息格式、传输规则和服务器之间的通信方式。 POP3 (Post Office Protocol - Version 3)协议用于支持使用电子邮件客户端获取并删除在服务器上的电子邮件。 IMAP (Internet Message Access Protocol)协议用于支持使用电子邮件客户端交互式存取服务器上的邮件。 SMTP (Simple Mail Transfer Protocol)协议用于支持使用电子邮件客户端发送电子邮件。
IMAP 和 POP 有什么区别
POP允许电子邮件客户端下载服务器上的邮件,但是你在电子邮件客户端上的操作(如:移动邮件、标记已读等)不会反馈到服务器上的,比如:你通过电子邮件客户端收取了QQ邮箱中的3封邮件并移动到了其他文件夹,这些移动动作是不会反馈到服务器上的,也就是说,QQ邮箱服务器上的这些邮件是没有同时被移动的。需要特别注意的是,第三方客户端通过POP收取邮件时,也是有可能同步删除服务端邮件。在第三方客户端设置 POP 时,请留意是否有 保留邮件副本/备份 相关选项。如有该选项,且要保留服务器上的邮件,请勾选该选项。
在IMAP协议上,电子邮件客户端的操作都会反馈到服务器上,你对邮件进行的操作(如:移动邮件、标记已读、删除邮件等)服务器上的邮件也会做相应的动作。也就是说,IMAP 是“双向”的。同时,IMAP 可以只下载邮件的主题,只有当你真正需要的时候,才会下载邮件的所有内容。在 POP3 和 IMAP 协议上,QQ邮箱推荐你使用IMAP协议来存取服务器上的邮件。
-
电子邮件地址: 每个电子邮件地址都是唯一的,通常由一个用户名(如user@example.com)和一个域名组成。电子邮件地址用于标识和路由电子邮件。
-
-
qq邮箱配置
- 在qq邮箱中开启POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务
- 配置授权码
- 代码中配置:
-
IMAP/SMTP 设置方法:
用户名/帐户: 你的QQ邮箱完整的地址
密码: 生成的授权码
电子邮件地址: 你的QQ邮箱的完整邮件地址
接收邮件服务器: imap.qq.com,使用SSL,端口号993
发送邮件服务器: smtp.qq.com,使用SSL,端口号465或587
-
邮件发送:
MailUtil.send(...): 邮件发送的方法.hutool提供 -
邮箱管理数据库模型
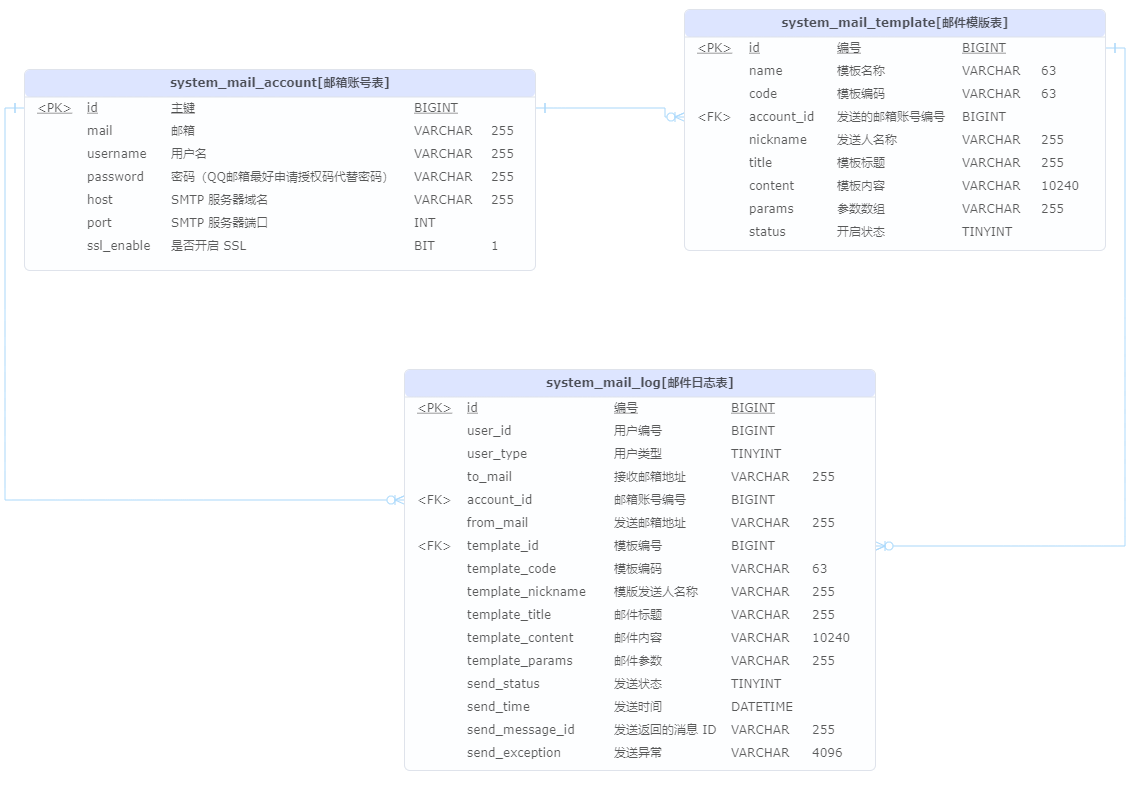

邮箱账号里面,用户名必须填写邮箱地址.
-
sms组件代码结构图
-
简单工厂模式创建短信客户端
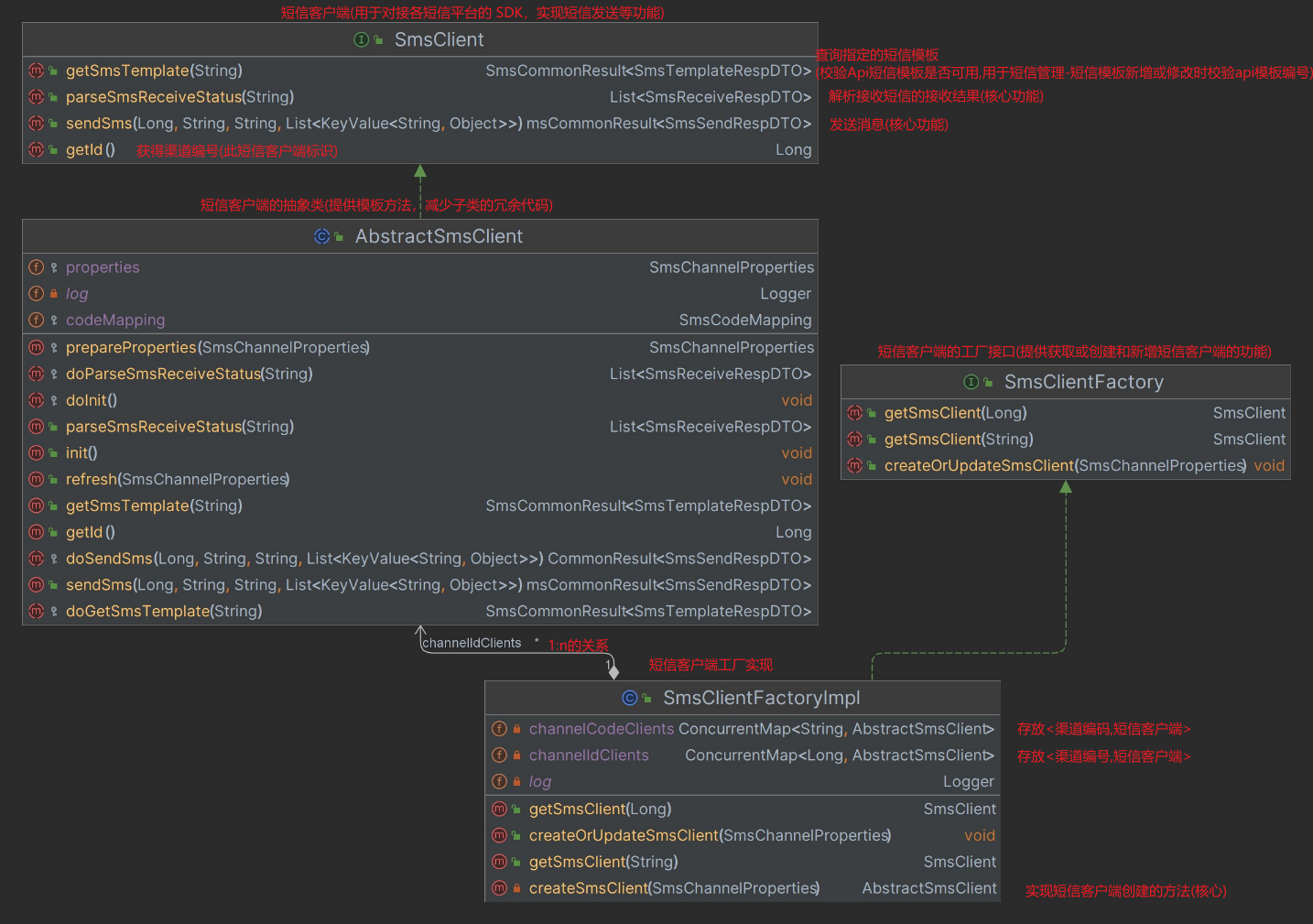
-
模板方法模式执行短信发送等功能
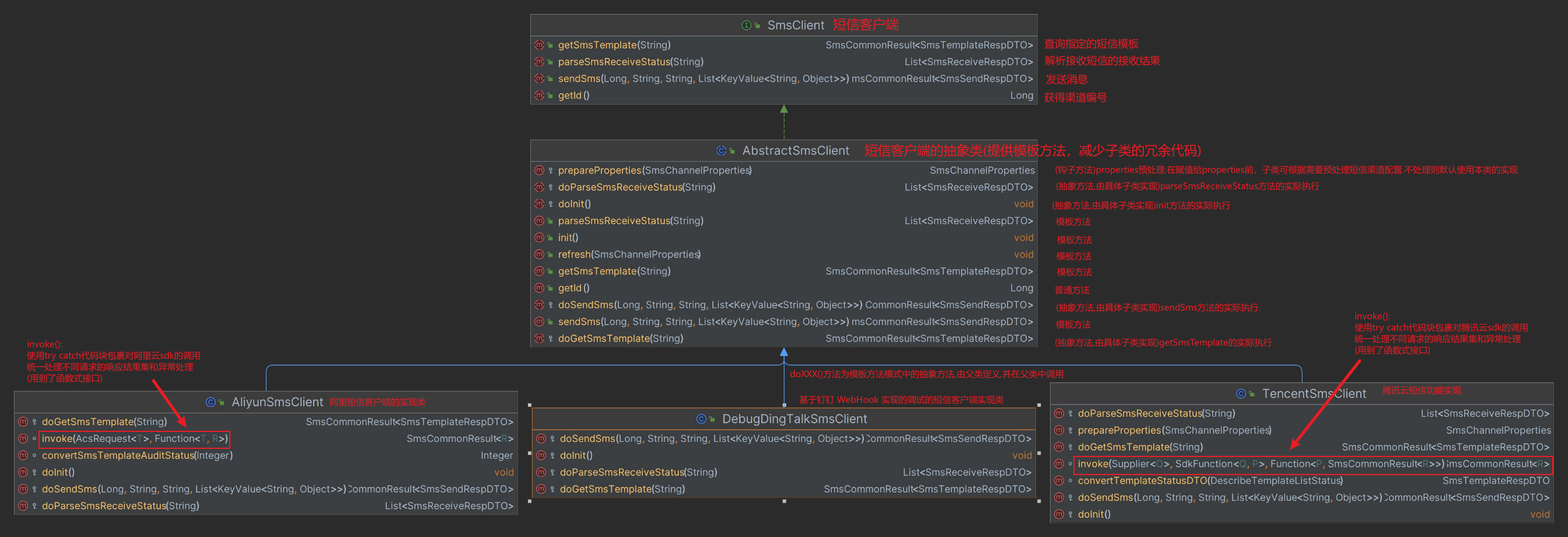
-
使用函数式接口实现短信平台api错误码和全局错误码类(ErrorCode)的转换(不知道是不是一种设计模式):SmsCodeMapping.java
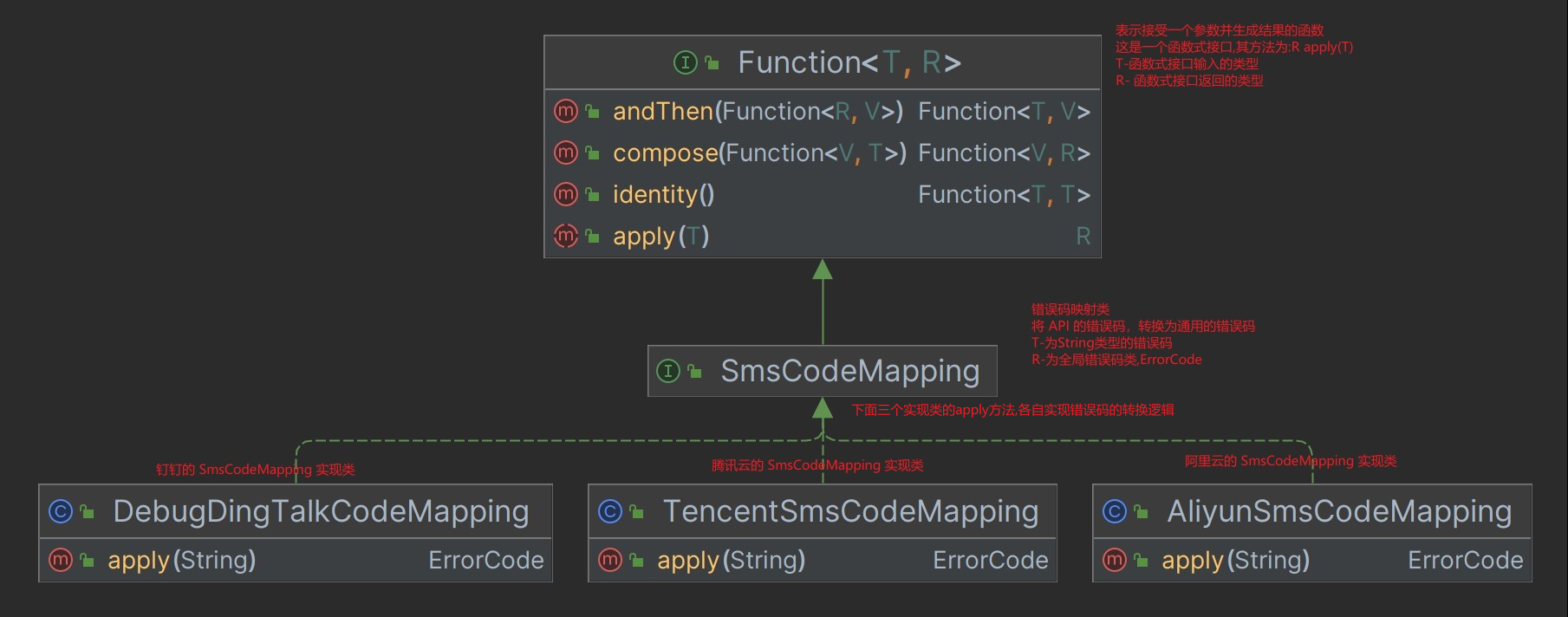
-
SmsCodeMapping的使用
SmsCommonResult.java:短信的 CommonResult 拓展类,SmsCodeMapping在其build方法(核心方法,构建返回结果)中使用,翻译错误码
public static <T> SmsCommonResult<T> build(String apiCode, String apiMsg, String apiRequestId, T data, SmsCodeMapping codeMapping) { Assert.notNull(codeMapping, "参数 codeMapping 不能为空"); SmsCommonResult<T> result = new SmsCommonResult<T>().setApiCode(apiCode).setApiMsg(apiMsg).setApiRequestId(apiRequestId); result.setData(data); // 翻译错误码 if (codeMapping != null) { ErrorCode errorCode = codeMapping.apply(apiCode); if (errorCode == null) { errorCode = SmsFrameworkErrorCodeConstants.SMS_UNKNOWN; } result.setCode(errorCode.getCode()).setMsg(errorCode.getMsg()); } return result; }
-
SmsCommonResult#build的使用
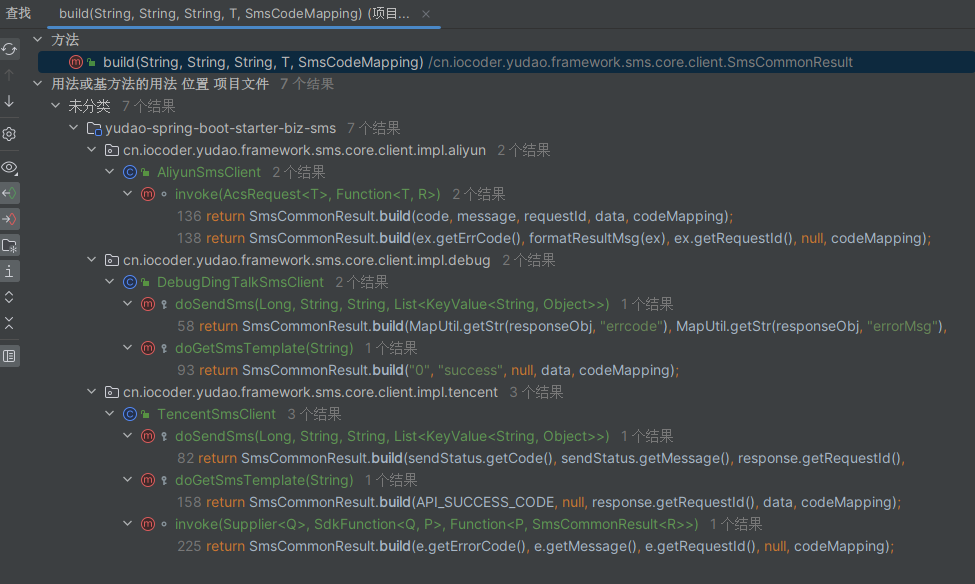
- 全是在向短信平台api发送请求时使用,用于封装请求结果
-
-
短信管理数据库模型

- system_sms_code:用于验证码的生成和校验
-
增加短信登录的功能





- 用户个人信息crud(todo :头像修改)
-
数据库模型

- system_oauth2_client:OAuth2 客户端表,控制令牌的有效期和权限范围等
- system_oauth2_access_token:OAuth2 访问令牌,用于访问系统的令牌
- system_oauth2_refresh_token:OAuth2 刷新令牌,用于刷新访问令牌.正常情况,刷新令牌有效期大于访问令牌
-
AUTH模块使用AccessToken与RefreshToken
-
登录接口登录成功放回AccessToken与RefreshToken
-
提供刷新令牌接口,用于生成新的访问令牌
使用AccessToken与RefreshToken的优缺点
AccessToken(访问令牌)和RefreshToken(刷新令牌)是OAuth 2.0授权框架中的两个重要概念,用于安全地授权第三方应用程序访问用户的资源。它们各自有一些优点和缺点,具体取决于应用程序的需求和安全要求。以下是它们的主要优缺点:
AccessToken的优点:
- 临时性:AccessToken是一种短期令牌,通常在较短的时间内失效,这有助于降低潜在风险,因为即使AccessToken被泄露,攻击者也只能在有限的时间内滥用它。
- 更轻量级:AccessToken通常比RefreshToken更轻量级,因为它只包含有限的信息,例如授权范围和持有者的信息。
- 增加性能:由于AccessToken的寿命较短,它们通常更容易生成和验证,这可以提高性能,尤其是在高负载情况下。
AccessToken的缺点:
- 用户体验:因为AccessToken是有限期的,用户可能需要频繁重新授权,这可能对用户体验产生负面影响。
- 安全性:AccessToken可能容易被截获或泄露,因此需要额外的安全措施来保护它们,例如HTTPS通信。
RefreshToken的优点:
- 持久性:RefreshToken具有较长的有效期,通常可以用于更长时间,以保持用户的持续授权状态,而无需频繁登录或重新授权。
- 安全性:因为RefreshToken的有效期较长,它们通常存储在更安全的环境中,例如服务器端,减少了泄露的风险。
- 减少用户干预:RefreshToken可以减少用户干预的需求,因为用户不必频繁登录或重新授权。
RefreshToken的缺点:
- 长期风险:由于RefreshToken的有效期较长,如果它们被盗或泄露,攻击者有更多时间滥用授权,因此需要更强的安全措施来保护它们。
- 复杂性:使用RefreshToken需要更复杂的流程,包括定期刷新AccessToken,这可能需要额外的开发工作和维护。
最佳实践通常是在应用程序中同时使用AccessToken和RefreshToken,以平衡用户体验和安全性。AccessToken用于实际的资源访问,而RefreshToken用于在AccessToken到期时获取新的AccessToken。同时,应该采取适当的安全措施,以防止令牌泄露和滥用。
-
-
starter-security功能完善
-
自定义AccessDeniedHandler处理spring security拦截到权限不足的情况.返回自定义权限不足错误码.AccessDeniedHandlerImpl.java
-
TokenAuthenticationFilter中增加校验访问令牌的逻辑
-
TransmittableThreadLocalSecurityContextHolderStrategy.java
- 基于 TransmittableThreadLocal 实现的 Security Context 持有者策略 目的是,避免 @Async 等异步执行时,原生 ThreadLocal 的丢失问题
SecurityContextHolderStrategy:用于管理和维护关于安全性的上下文信息,例如当前认证的用户和用户的权限。TransmittableThreadLocal:允许在不同线程之间传递这些上下文信息,同时保持线程隔离。SecurityContextImpl:Spring Security 上下文对象.- 存储认证信息
- 存储权限信息
- 提供方法来获取和设置安全上下文
-
设置使用
TransmittableThreadLocalSecurityContextHolderStrategy作为 Security 的上下文策略/** * 声明调用 {@link SecurityContextHolder#setStrategyName(String)} 方法, * 设置使用 {@link TransmittableThreadLocalSecurityContextHolderStrategy} 作为 Security 的上下文策略 */ @Bean public MethodInvokingFactoryBean securityContextHolderMethodInvokingFactoryBean() { MethodInvokingFactoryBean methodInvokingFactoryBean = new MethodInvokingFactoryBean(); methodInvokingFactoryBean.setTargetClass(SecurityContextHolder.class); methodInvokingFactoryBean.setTargetMethod("setStrategyName"); methodInvokingFactoryBean.setArguments(TransmittableThreadLocalSecurityContextHolderStrategy.class.getName()); return methodInvokingFactoryBean; }
-
MethodInvokingFactoryBean:MethodInvokingFactoryBean是 Spring Framework 中的一个工厂 bean,用于执行一个特定的静态方法或非静态方法,并将其结果暴露为一个 bean。它的作用是将方法的执行结果装配成一个 Spring bean,使方法的结果可以在应用程序中像其他 bean 一样进行管理和注入。主要用途和功能包括:
-
调用静态方法:
MethodInvokingFactoryBean可以用于调用静态方法,这些方法通常不需要特定的实例,而是通过类名调用。 -
调用实例方法:除了静态方法,它还可以调用实例方法,但在这种情况下,需要提供目标对象(通常是某个已存在的 bean)以及方法名。
-
调用工厂方法:它还可以用于调用工厂方法,以便将方法的结果作为 bean 创建并管理。
-
通过 Spring 配置装配结果:
MethodInvokingFactoryBean允许你将方法调用的结果装配为一个 Spring bean,并将其配置到 Spring 容器中,以便其他 bean 可以引用它。
示例使用方法:
<bean id="myService" class="com.example.MyService" /> <bean class="org.springframework.beans.factory.config.MethodInvokingFactoryBean"> <property name="targetObject" ref="myService" /> <property name="targetMethod" value="doSomething" /> </bean>
上面的示例中,
MethodInvokingFactoryBean调用了myService对象的doSomething方法,然后将方法的结果装配为一个 bean,并可以像其他 bean 一样在应用程序中使用。需要注意的是,
MethodInvokingFactoryBean通常用于配置阶段,而不是在运行时执行方法调用。它适用于需要在 Spring 配置文件中执行某些操作,如初始化配置或调用工厂方法的情况。如果需要在运行时动态调用方法,通常会使用 AOP 或编程方式实现。总之,
MethodInvokingFactoryBean是 Spring Framework 中的一个用于执行方法调用并将结果装配为 Spring bean 的工厂 bean,通常用于配置阶段,以执行各种初始化、配置和工厂方法的调用。(方法结果为void怎么封装成bean,还是本例中
setStrategyName为静态方法,不需要封装成bean,setStrategyName方法被调用了即可达成目标)本例中
setStrategyName方法被调用了即可达成目标原因如下:
setStrategyName方法最终会通过反射创建出自定义的策略对象,并赋值给SecurityContextHolder的静态成员变量strategypublic static void setStrategyName(String strategyName) { SecurityContextHolder.strategyName = strategyName; initialize(); }
private static void initialize() { initializeStrategy(); initializeCount++; }
private static void initializeStrategy() { //此处省略一些默认策略处理的代码 // Try to load a custom strategy try { Class<?> clazz = Class.forName(strategyName); Constructor<?> customStrategy = clazz.getConstructor(); strategy = (SecurityContextHolderStrategy) customStrategy.newInstance(); } catch (Exception ex) { ReflectionUtils.handleReflectionException(ex); } }
-
-
SecurityContextHolder#setStrategyName:SecurityContextHolder类的setStrategyName方法是 Spring Security 中的一个重要方法,用于设置安全上下文(SecurityContext)的策略名称(strategyName)。该方法的作用是告诉 Spring Security 如何管理和维护安全上下文,以适应不同的环境和需求。安全上下文策略名称是一个标识,它表示了 Spring Security 在多线程环境中如何处理安全上下文的传递。不同的策略名称可以对应不同的策略实现,以满足特定的需求。在 Spring Security 中,有几种不同的策略可供选择,例如:
-
MODE_THREADLOCAL:这是默认策略,安全上下文信息存储在线程本地变量中,每个线程拥有自己的安全上下文。这意味着安全上下文在不同线程之间不共享,适用于多线程环境。 -
MODE_GLOBAL:这种策略允许安全上下文在全局范围内共享,通常用于单线程应用程序或者不需要多线程安全的应用程序。 -
自定义策略:除了上述两种标准策略,Spring Security还允许开发人员定义自己的安全上下文策略,以满足特定需求。
setStrategyName方法的调用将影响整个应用程序中的安全上下文管理。在多线程应用程序中,通常会选择MODE_THREADLOCAL策略,以确保安全上下文的线程隔离。当你在 Spring Security 配置中调用setStrategyName方法时,Spring Security将根据提供的策略名称使用相应的策略实现来管理安全上下文。示例使用方法:
SecurityContextHolder.setStrategyName(SecurityContextHolder.MODE_THREADLOCAL);
上面的示例将安全上下文策略设置为
MODE_THREADLOCAL,这是在多线程环境中通常使用的默认策略。总之,
SecurityContextHolder的setStrategyName方法用于设置 Spring Security 的安全上下文策略,以控制如何管理和维护安全上下文。选择适当的策略取决于你的应用程序需求,特别是在多线程环境中确保安全上下文的正确传递和隔离。 -
-
-

-
OAuth 2.0 授权模式
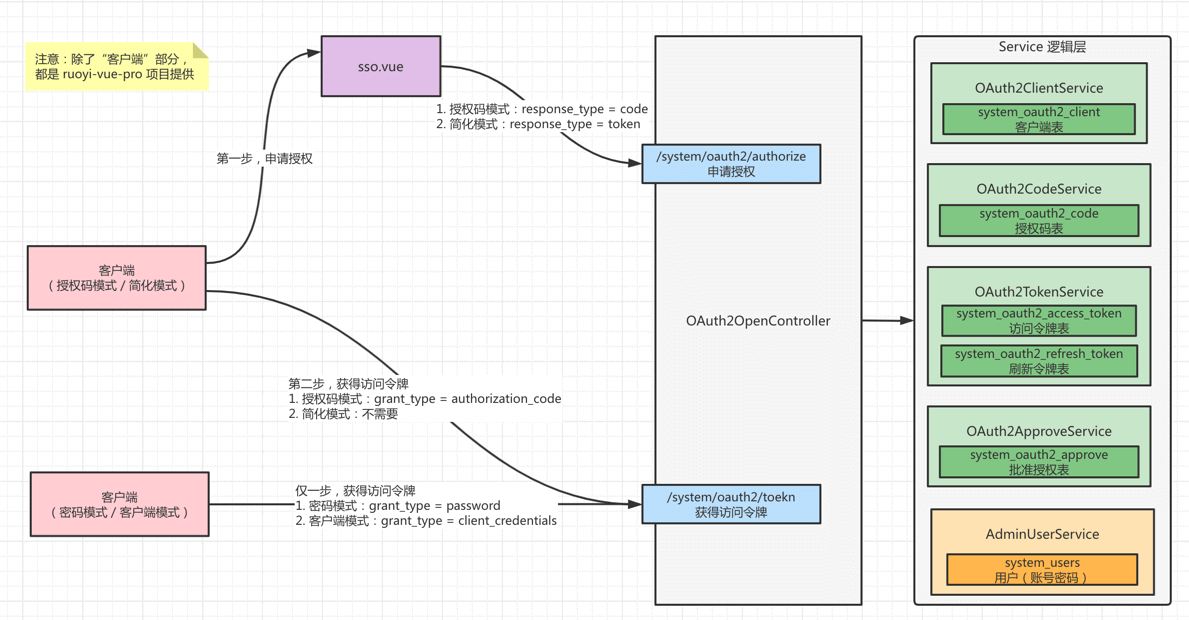
- 授权码模式
- 简化模式
- 密码模式
- 客户端模式
-
基于授权码模式,实现 SSO 单点登录yudao-sso-demo-by-code
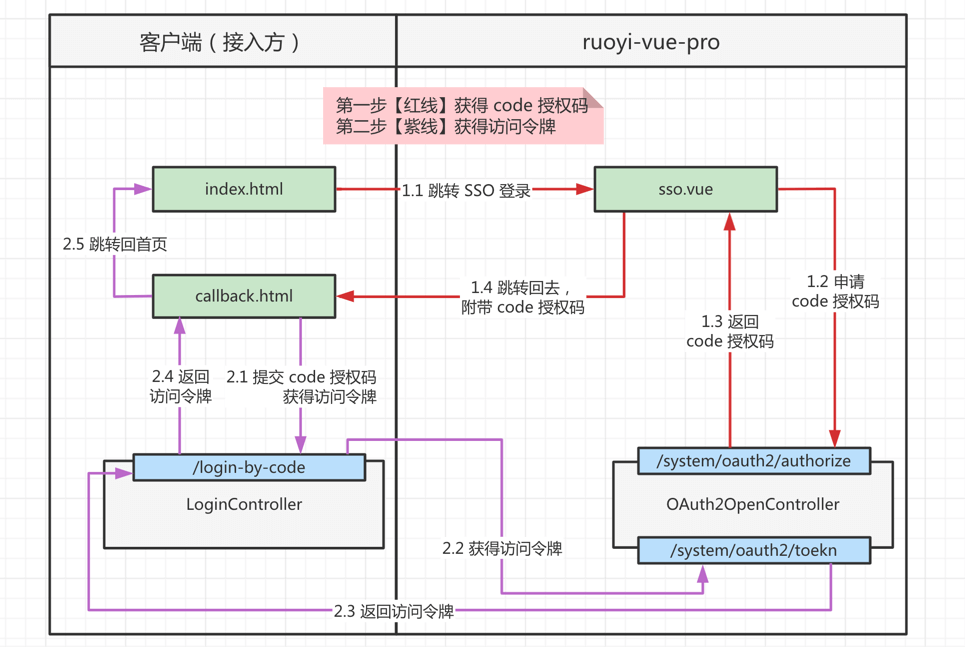
- 重定向通过前端
location.href实现.(授权完成后,服务端返回重定向地址)
- 重定向通过前端
-
基于密码模式,实现 SSO 登录yudao-sso-demo-by-password
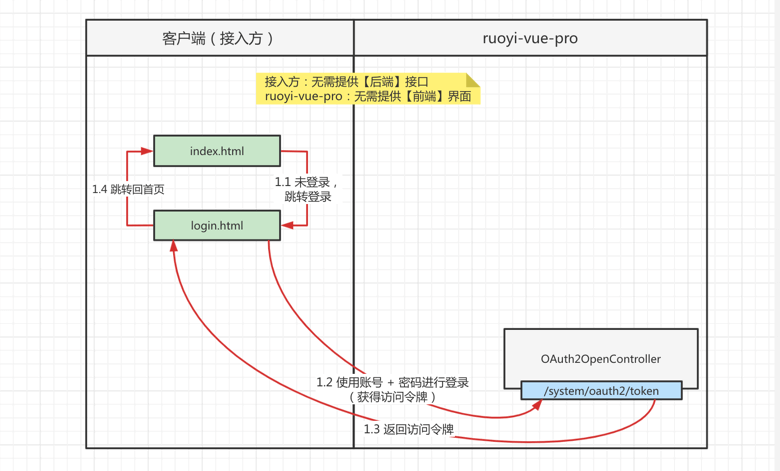
-
OAuth 2.0数据库模型

scopes:授权范围.由system_oauth2_client开始往后传递system_oauth2_approve:OAuth2 批准表,用于授权码模式,记录用户的授权范围system_oauth2_code:OAuth2 授权码表,由yudao服务生成,code使用一次后就销毁
-
SecurityFrameworkService类增加hasScope方法,用于OAuth 2.0中授权范围权限的判断 -
接口设计
/** * OAuth2 批准 Service 接口 * * 从功能上,和 Spring Security OAuth 的 ApprovalStoreUserApprovalHandler 的功能,记录用户针对指定客户端的授权,减少手动确定。 * * @author 芋道源码 */ public interface OAuth2ApproveService { /** * (不知道干嘛的) * 获得指定用户,针对指定客户端的指定授权,是否通过 * * 参考 ApprovalStoreUserApprovalHandler 的 checkForPreApproval 方法 * * @param userId 用户编号 * @param userType 用户类型 * @param clientId 客户端编号 * @param requestedScopes 授权范围 * @return 是否授权通过 */ boolean checkForPreApproval(Long userId, Integer userType, String clientId, Collection<String> requestedScopes); /** * (授权码模式中,用户批准授权使用) * 在用户发起批准时,基于 scopes 的选项,计算最终是否通过 * * @param userId 用户编号 * @param userType 用户类型 * @param clientId 客户端编号 * @param requestedScopes 授权范围 * @return 是否授权通过 */ boolean updateAfterApproval(Long userId, Integer userType, String clientId, Map<String, Boolean> requestedScopes); /** * (授权码模式中,查询用户已批准的授权) * 获得用户的批准列表,排除已过期的 * * @param userId 用户编号 * @param userType 用户类型 * @param clientId 客户端编号 * @return 是否授权通过 */ List<OAuth2ApproveDO> getApproveList(Long userId, Integer userType, String clientId); }
/** * OAuth2.0 授权码 Service 接口 * * 从功能上,和 Spring Security OAuth 的 JdbcAuthorizationCodeServices 的功能,提供授权码的操作 * * @author 芋道源码 */ public interface OAuth2CodeService { /** * (用户授权完成后使用,yudao服务端下发code) * 创建授权码 * * 参考 JdbcAuthorizationCodeServices 的 createAuthorizationCode 方法 * * @param userId 用户编号 * @param userType 用户类型 * @param clientId 客户端编号 * @param scopes 授权范围 * @param redirectUri 重定向 URI * @param state 状态 * @return 授权码的信息 */ OAuth2CodeDO createAuthorizationCode(Long userId, Integer userType, String clientId, List<String> scopes, String redirectUri, String state); /** * (获取token时使用,服务端A用code换yudao服务端的token,code用完即销毁) * 使用授权码 * * @param code 授权码 */ OAuth2CodeDO consumeAuthorizationCode(String code); }
/** * OAuth2 授予 Service 接口 * * 从功能上,和 Spring Security OAuth 的 TokenGranter 的功能,提供访问令牌、刷新令牌的操作 * * 将自身的 AdminUser 用户,授权给第三方应用,采用 OAuth2.0 的协议。 * * 问题:为什么自身也作为一个第三方应用,也走这套流程呢? * 回复:当然可以这么做,采用 password 模式。考虑到大多数开发者使用不到这个特性,OAuth2.0 毕竟有一定学习成本,所以暂时没有采取这种方式。 * * @author 芋道源码 */ public interface OAuth2GrantService { /** * 简化模式 * * 对应 Spring Security OAuth2 的 ImplicitTokenGranter 功能 * * @param userId 用户编号 * @param userType 用户类型 * @param clientId 客户端编号 * @param scopes 授权范围 * @return 访问令牌 */ OAuth2AccessTokenDO grantImplicit(Long userId, Integer userType, String clientId, List<String> scopes); /** * 授权码模式,第一阶段,获得 code 授权码 * * 对应 Spring Security OAuth2 的 AuthorizationEndpoint 的 generateCode 方法 * * @param userId 用户编号 * @param userType 用户类型 * @param clientId 客户端编号 * @param scopes 授权范围 * @param redirectUri 重定向 URI * @param state 状态 * @return 授权码 */ String grantAuthorizationCodeForCode(Long userId, Integer userType, String clientId, List<String> scopes, String redirectUri, String state); /** * 授权码模式,第二阶段,获得 accessToken 访问令牌 * * 对应 Spring Security OAuth2 的 AuthorizationCodeTokenGranter 功能 * * @param clientId 客户端编号 * @param code 授权码 * @param redirectUri 重定向 URI * @param state 状态 * @return 访问令牌 */ OAuth2AccessTokenDO grantAuthorizationCodeForAccessToken(String clientId, String code, String redirectUri, String state); /** * 密码模式 * * 对应 Spring Security OAuth2 的 ResourceOwnerPasswordTokenGranter 功能 * * @param username 账号 * @param password 密码 * @param clientId 客户端编号 * @param scopes 授权范围 * @return 访问令牌 */ OAuth2AccessTokenDO grantPassword(String username, String password, String clientId, List<String> scopes); /** * 刷新模式 * * 对应 Spring Security OAuth2 的 ResourceOwnerPasswordTokenGranter 功能 * * @param refreshToken 刷新令牌 * @param clientId 客户端编号 * @return 访问令牌 */ OAuth2AccessTokenDO grantRefreshToken(String refreshToken, String clientId); /** * 客户端模式 * * 对应 Spring Security OAuth2 的 ClientCredentialsTokenGranter 功能 * * @param clientId 客户端编号 * @param scopes 授权范围 * @return 访问令牌 */ OAuth2AccessTokenDO grantClientCredentials(String clientId, List<String> scopes); /** * 移除访问令牌 * * 对应 Spring Security OAuth2 的 ConsumerTokenServices 的 revokeToken 方法 * * @param accessToken 访问令牌 * @param clientId 客户端编号 * @return 是否移除到 */ boolean revokeToken(String clientId, String accessToken); }
OAuth2GrantService:授权服务,各种授权模式的实际调用方.提供不同模式下访问令牌、刷新令牌和移除访问令牌的操作




-
实现流程
- 在AOP中使用环绕通知,方法执行前获取到所有被
@DataPermission标注的方法(包括类被标注的方法) - 将
@DataPermission的值存入TransmittableThreadLocal中.(会在DataPermissionRuleFactoryImpl中取出) - 切入点方法执行
DataPermissionDatabaseInterceptor执行,拦截sql- 调用
DataPermissionRuleFactoryImpl类,取出数据权限的规则DataPermissionRuleFactoryImpl类中会取出存入TransmittableThreadLocal中的@DataPermission,过滤出需要的数据权限的规则
- 处理 SQL.根据权限规则配置条件
- 在AOP中使用环绕通知,方法执行前获取到所有被
-
自定义该权限规则,构建
DeptDataPermissionRule.@Bean public DeptDataPermissionRule deptDataPermissionRule(PermissionApi permissionApi, List<DeptDataPermissionRuleCustomizer> customizers) { // 创建 DeptDataPermissionRule 对象 DeptDataPermissionRule rule = new DeptDataPermissionRule(permissionApi); // 补全表配置 customizers.forEach(customizer -> customizer.customize(rule)); return rule; }
- 使用@Bean获取到
List<DeptDataPermissionRuleCustomizer> customizers,DeptDataPermissionRuleCustomizer由用户自定义 customizers.forEach(customizer -> customizer.customize(rule));:调用customize()方法,使用户自定义的自定义该权限规则应用上
- 使用@Bean获取到
-
AOP相关
AbstractPointcutAdvisor、Advice、Pointcut和MethodInterceptor都是Spring框架中用于实现面向切面编程(AOP)的重要概念,它们之间有以下关系:
-
AbstractPointcutAdvisor:
AbstractPointcutAdvisor是Spring AOP中的一个抽象类,用于创建通知(Advice)和切入点(Pointcut)的组合。它是PointcutAdvisor接口的一个常见实现。一个AbstractPointcutAdvisor通常包括一个Pointcut和一个Advice。它是AOP代理的关键组件,用于定义切面。 -
Advice:
Advice代表在方法执行的不同切点(例如方法调用前、方法调用后、方法抛出异常等)执行的逻辑。Spring提供了几种类型的Advice,如BeforeAdvice、AfterAdvice、AroundAdvice等。Advice定义了在何时何地执行额外的逻辑,通常与切点结合使用以实现切面功能。Advice可以是普通的Java对象,实现Advice接口或者使用Spring提供的注解。 -
Pointcut:
Pointcut定义了在哪里(即切点)应该应用Advice。Pointcut用于匹配一组方法,允许你指定哪些方法应该受到AOP增强的影响。Spring提供了不同的Pointcut表达式语言,如AspectJ表达式和Spring的自定义表达式语言,用于定义切点。Pointcut可以与Advice关联,以确定何时以及在哪些方法上应用Advice。 -
MethodInterceptor:
MethodInterceptor是Spring AOP中的一种拦截器,通常与AroundAdvice一起使用。它允许你在方法执行前和方法执行后插入自定义逻辑,以完全控制方法的执行。MethodInterceptor通常被用来包装Advice,从而提供更灵活的控制和定制化的AOP行为。
综合起来,一个
AbstractPointcutAdvisor包含了Advice和Pointcut的组合,其中Advice定义了增强逻辑,Pointcut定义了在哪些方法上应用这些增强逻辑。MethodInterceptor通常与AroundAdvice一起使用,以提供在方法执行前和方法执行后插入自定义逻辑的能力。这些组件协同工作,使Spring的AOP能够实现横切关注点的分离和重用。 -
-
protected Pointcut buildPointcut() { Pointcut classPointcut = new AnnotationMatchingPointcut(DataPermission.class, true); Pointcut methodPointcut = new AnnotationMatchingPointcut(null, DataPermission.class, true); return new ComposablePointcut(classPointcut).union(methodPointcut); }
-
这代码段是一个Java方法,用于构建一个Spring AOP的切点(Pointcut)。让我来逐步解释这段代码:
-
AnnotationMatchingPointcut是Spring AOP提供的一个类,它用于匹配具有特定注解的类或方法。在这里,你正在创建两个AnnotationMatchingPointcut实例。-
classPointcut:这是第一个切点,它用于匹配带有DataPermission注解的类。参数DataPermission.class表示要匹配的注解类,而true表示也要匹配子类。这意味着它将匹配包括继承DataPermission注解的类。 -
methodPointcut:这是第二个切点,它用于匹配带有DataPermission注解的方法。参数null表示不限制匹配的类,而DataPermission.class表示要匹配的注解类。同样,true表示也要匹配子类的方法。
-
-
接下来,你使用
ComposablePointcut创建一个可组合的切点,即classPointcut和methodPointcut的组合。ComposablePointcut允许你将多个切点组合在一起,以创建一个更复杂的切点。在这里,使用union方法将这两个切点组合在一起,表示匹配既有DataPermission注解的类又有DataPermission注解的方法。 -
最后,
buildPointcut()方法返回这个组合后的切点,可以在Spring AOP中用于定义切面,以便在匹配的类和方法上应用相应的增强(Advice)。
总之,这段代码创建了一个复合切点,用于匹配既带有
DataPermission注解的类又带有DataPermission注解的方法。这种切点可以用于定义一个切面,以便在相关的类和方法上应用数据权限控制的逻辑。 -
-
-
Guava的Suppliers.memoize方法
Suppliers.memoize方法是 Google Guava 库中的一个方法,用于包装一个Supplier实例,以便对其进行记忆或缓存,以提高性能。记忆是指当首次调用Supplier的get()方法后,Suppliers.memoize会缓存计算结果,并在后续的调用中直接返回缓存的结果,而不会再次计算。这个方法通常用于延迟计算,特别是当计算结果是不变的或者很昂贵的时候。通过使用
Suppliers.memoize,可以确保一个Supplier只会计算一次,而后续调用将直接返回缓存的结果。这可以提高性能并减少重复计算的开销。下面是
Suppliers.memoize方法的一个简单示例:Supplier<String> supplier = Suppliers.memoize(() -> { System.out.println("Calculating..."); return "Result"; }); System.out.println(supplier.get()); // 第一次调用,进行计算 System.out.println(supplier.get()); // 后续调用,直接返回缓存的结果
在这个例子中,第一次调用
supplier.get()会进行计算并打印 "Calculating...",而后续调用会直接返回缓存的结果而不会再次计算。这在某些场景下可以提高程序的性能和效率。
供代码生成功能选择数据库时使用
-
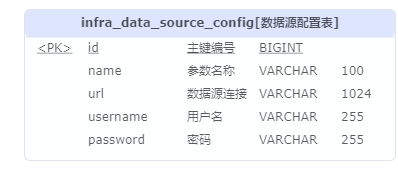
数据源配置数据库模型
-
代码摘要
判断数据库连接是否正确
/** * 判断连接是否正确 * * @param url 数据源连接 * @param username 账号 * @param password 密码 * @return 是否正确 */ public static boolean isConnectionOK(String url, String username, String password) { try (Connection ignored = DriverManager.getConnection(url, username, password)) { return true; } catch (Exception ex) { return false; } }
- 自动资源管理:使用了
try-with-resources结构来获取数据库连接,这确保了无论是否成功连接,连接都会被自动关闭。这有助于避免资源泄漏。 - 使用是否报错来判断链接是否正常
获取配置文件中的主数据源配置
@Resource private DynamicDataSourceProperties dynamicDataSourceProperties; private DataSourceConfigDO buildMasterDataSourceConfig() { String primary = dynamicDataSourceProperties.getPrimary(); DataSourceProperty dataSourceProperty = dynamicDataSourceProperties.getDatasource().get(primary); return new DataSourceConfigDO().setId(DataSourceConfigDO.ID_MASTER).setName(primary) .setUrl(dataSourceProperty.getUrl()) .setUsername(dataSourceProperty.getUsername()) .setPassword(dataSourceProperty.getPassword()); }
- 使用自动注入获取数据源配置类
DynamicDataSourceProperties(由DynamicDataSourceAutoConfiguration注册成为bean)
DynamicDataSourceProperties/** * DynamicDataSourceProperties * * @author TaoYu Kanyuxia * @see DataSourceProperties * @since 1.0.0 */ @Slf4j @Getter @Setter @ConfigurationProperties(prefix = DynamicDataSourceProperties.PREFIX) public class DynamicDataSourceProperties { public static final String PREFIX = "spring.datasource.dynamic"; //省略 }
/** * 动态数据源核心自动配置类 * * @author TaoYu Kanyuxia * @see DynamicDataSourceProvider * @see DynamicDataSourceStrategy * @see DynamicRoutingDataSource * @since 1.0.0 */ @Slf4j @Configuration @EnableConfigurationProperties(DynamicDataSourceProperties.class) @AutoConfigureBefore(value = DataSourceAutoConfiguration.class, name = "com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure") @Import(value = {DruidDynamicDataSourceConfiguration.class, DynamicDataSourceCreatorAutoConfiguration.class}) @ConditionalOnProperty(prefix = DynamicDataSourceProperties.PREFIX, name = "enabled", havingValue = "true", matchIfMissing = true) public class DynamicDataSourceAutoConfiguration implements InitializingBean { }
- 由
DynamicDataSourceAutoConfiguration动态数据源核心自动配置类,中启用DynamicDataSourceProperties,并使其注册成为bean
- 自动资源管理:使用了

-
代码生成流程
- 配置数据源,在该数据源数据库下建表
- 基于数据库的表结构,创建代码生成器的表和字段定义
- 通过数据源id+表名,解析出表结构DatabaseTableService.java#getTable(...)
- 使用 MyBatis Plus Generator 解析表结构和字段定义
- MyBatis Plus Generator 使用原生
java.sql下的DatabaseMetaData#getTables(...)获取表结构 - MyBatis Plus Generator 使用原生
java.sql下的DatabaseMetaDataWrapper#getColumnsInfo(...)获取字段定义
- MyBatis Plus Generator 使用原生
- 使用 MyBatis Plus Generator 解析表结构和字段定义
- 创建代码生成器的表和字段定义
- 将解析出的表结构和字段定义润色后存入
infra_codegen_table和infra_codegen_column,见CodegenBuilder.java
- 将解析出的表结构和字段定义润色后存入
- 通过数据源id+表名,解析出表结构DatabaseTableService.java#getTable(...)
- 生成代码CodegenEngine.java
- 通过代码生成器的表和字段定义等生成待填充的参数
- 获取resources/codegen目录下的模板
- 将参数填充至模板
-
数据库模型


-
系统接口
-
spring Security中配置静态资源可匿名访问
- 系统接口文档访问地址:http://localhost:48080/doc.html
-
禁用 X-Frame-Options 标头,允许页面在框架中嵌入。
- 系统接口菜单中会内嵌接口文档doc.html页面
httpSecurity.headers().frameOptions().disable()
httpSecurity.headers().frameOptions().disable()是 Spring Security 中的一项配置,用于禁用 HTTP 响应头中的 X-Frame-Options 标头。这个标头通常用于防止跨站点请求伪造(Cross-Site Request Forgery, CSRF)攻击,以及点击劫持攻击。在某些情况下,您可能需要禁用它,以便在您的应用程序中使用内嵌的框架或嵌入其他网站的内容。解释一下:
-
X-Frame-Options 标头:X-Frame-Options 是一个 HTTP 标头,用于告知浏览器如何处理嵌入的框架。它可以有以下几个值:
DENY:浏览器不允许嵌入此页面中的任何框架。SAMEORIGIN:浏览器只允许在与页面相同域的框架中加载此页面。ALLOW-FROM uri:浏览器只允许指定 URI 的框架加载此页面。
-
httpSecurity.headers().frameOptions().disable():这是 Spring Security 的配置方法,通过它您可以禁用 X-Frame-Options 标头,允许页面在框架中嵌入。这对于需要在应用程序中嵌入其他网站的内容或使用内嵌的框架(例如,内嵌的视频播放器)的情况非常有用。
请注意,禁用 X-Frame-Options 标头可能会使您的应用程序更容易受到一些安全威胁,因此只有在明确了解潜在风险并采取其他安全措施的情况下才应该禁用它。如果您不确定是否需要禁用 X-Frame-Options,最好仔细考虑您的应用程序的需求和安全性。
-
自定义spring security规则路径权限规则
- doc.html中需要调用Swagger 接口文档中一些接口和页面,在此处进行放行
-
基于实现
Customizer<T>自定义URL 的安全配置/** *接受单个输入参数且不返回任何结果的回调接口。 * * @param <T> the type of the input to the operation * @author Eleftheria Stein * @since 5.2 */ @FunctionalInterface public interface Customizer<T> { /** * 对输入参数执行自定义。 * 形参: t – 输入参数 */ void customize(T t); /** * Returns a {@link Customizer} that does not alter the input argument. * @return a {@link Customizer} that does not alter the input argument. */ static <T> Customizer<T> withDefaults() { return (t) -> { }; } }
-
实现自定义的 URL 的安全配置
/** * 自定义的 URL 的安全配置 * 目的:每个 Maven Module 可以自定义规则! * * @author 芋道源码 */ public abstract class AuthorizeRequestsCustomizer implements Customizer<ExpressionUrlAuthorizationConfigurer<HttpSecurity>.ExpressionInterceptUrlRegistry>, Ordered { @Resource private WebProperties webProperties; protected String buildAdminApi(String url) { return webProperties.getAdminApi().getPrefix() + url; } protected String buildAppApi(String url) { return webProperties.getAppApi().getPrefix() + url; } @Override public int getOrder() { return 0; } }
/** * Infra 模块的 Security 配置 */ @Configuration(proxyBeanMethods = false, value = "infraSecurityConfiguration") public class SecurityConfiguration { @Bean("infraAuthorizeRequestsCustomizer") public AuthorizeRequestsCustomizer authorizeRequestsCustomizer() { return new AuthorizeRequestsCustomizer() { @Override public void customize(ExpressionUrlAuthorizationConfigurer<HttpSecurity>.ExpressionInterceptUrlRegistry registry) { // Swagger 接口文档 registry.antMatchers("/v3/api-docs/**").permitAll() .antMatchers("/swagger-ui.html").permitAll() .antMatchers("/swagger-ui/**").permitAll() .antMatchers("/swagger-resources/**").anonymous() .antMatchers("/webjars/**").anonymous() .antMatchers("/*/api-docs").anonymous(); } }; } }
@Resource private List<AuthorizeRequestsCustomizer> authorizeRequestsCustomizers; // 省略 // ②:每个项目的自定义规则 httpSecurity.and().authorizeRequests(registry -> // 下面,循环设置自定义规则 authorizeRequestsCustomizers.forEach(customizer -> customizer.customize(registry)))
-
-
配置管理
-
目前只给前端使用.(服务端也可以使用)
-

-
集成Screw 数据库文档生成框架
<dependency> <groupId>cn.smallbun.screw</groupId> <artifactId>screw-core</artifactId> <!-- 实现数据库文档 --> </dependency>
-
创建 screw 的引擎配置
-
使用
velocity模板Velocity 是一个用于生成文本输出的模板引擎
-
-
代码摘要
-
返回附件后删除本地文件,finally中执行文件删除操作
private void doExportFile(EngineFileType fileOutputType, Boolean deleteFile, HttpServletResponse response) throws IOException { String docFileName = DOC_FILE_NAME + "_" + IdUtil.fastSimpleUUID(); String filePath = doExportFile(fileOutputType, docFileName); String downloadFileName = DOC_FILE_NAME + fileOutputType.getFileSuffix(); //下载后的文件名 try { // 读取,返回 ServletUtils.writeAttachment(response, downloadFileName, FileUtil.readBytes(filePath)); } finally { //finally中执行文件删除操作 handleDeleteFile(deleteFile, filePath); } }
-
-
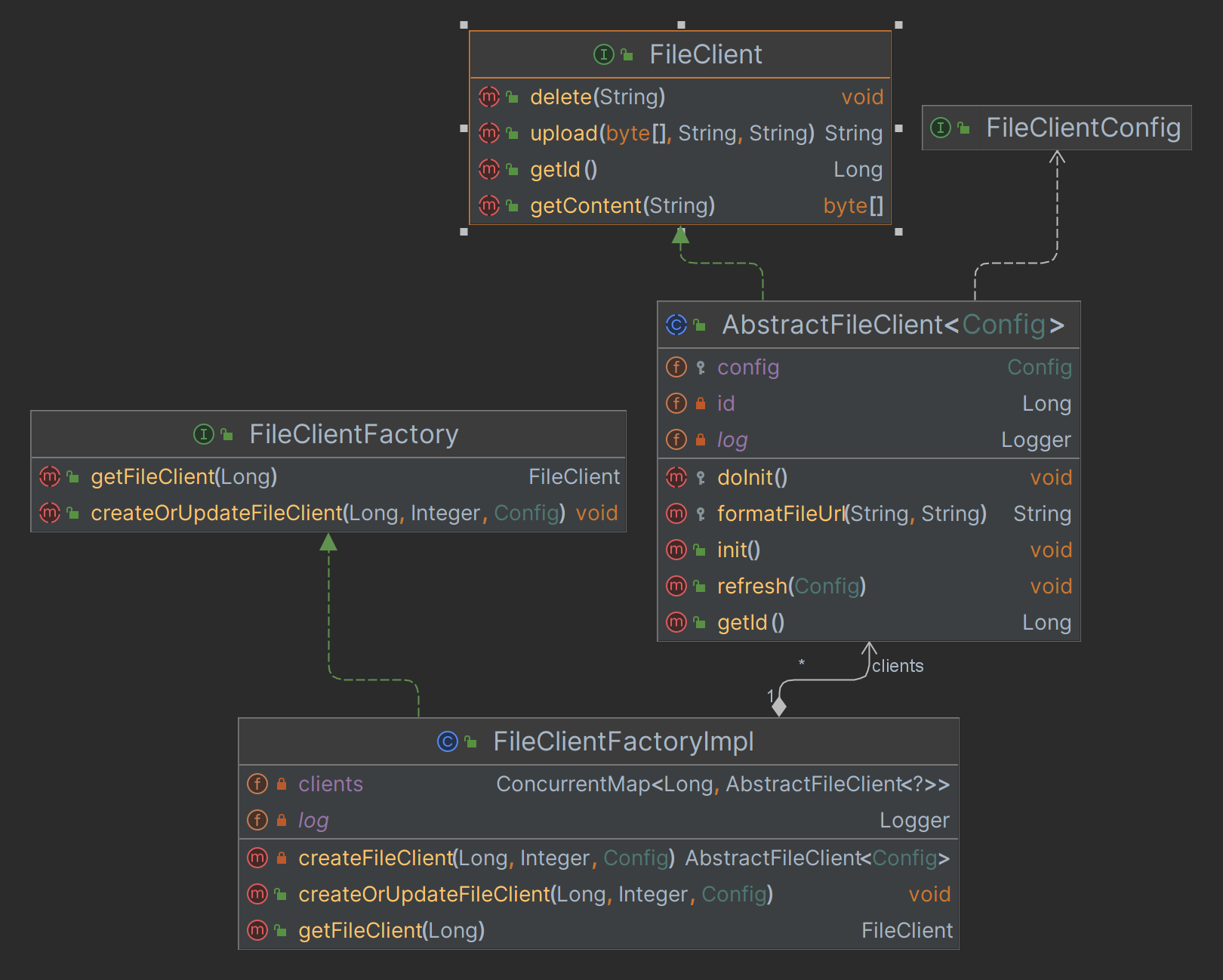
文件组件代码结构图
- 简单工厂+工厂模式实现文件上传等功能
- 多种文件客户端
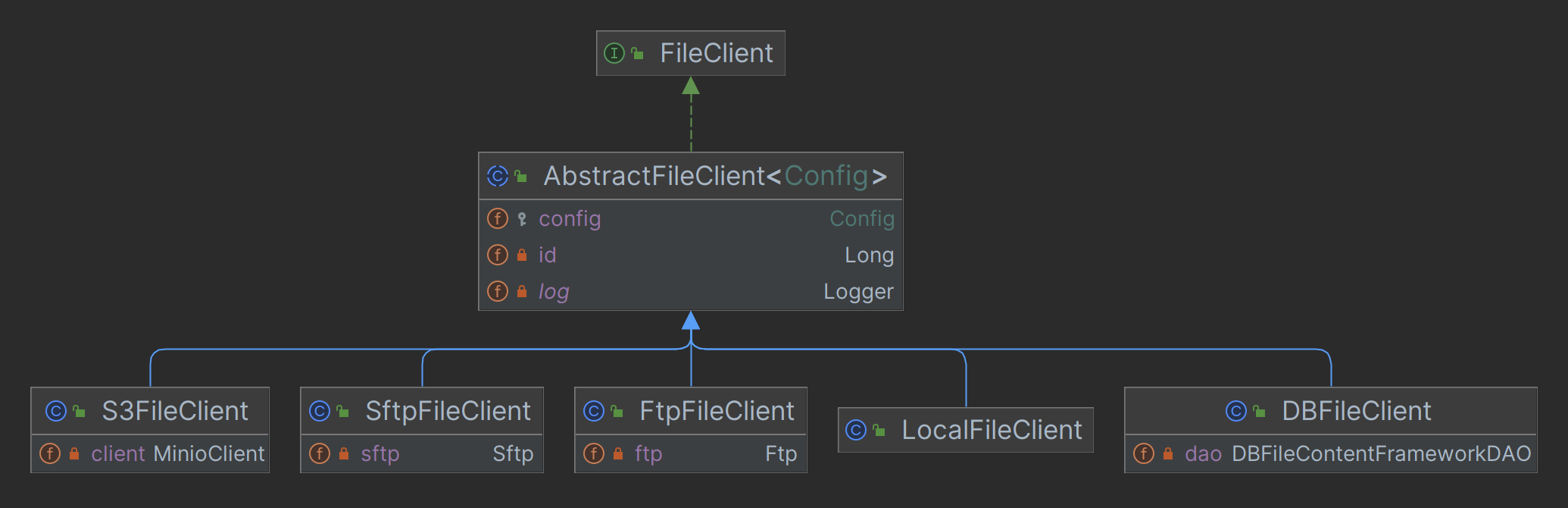
public enum FileStorageEnum { DB(1, DBFileClientConfig.class, DBFileClient.class), LOCAL(10, LocalFileClientConfig.class, LocalFileClient.class), FTP(11, FtpFileClientConfig.class, FtpFileClient.class), SFTP(12, SftpFileClientConfig.class, SftpFileClient.class), S3(20, S3FileClientConfig.class, S3FileClient.class), ; /** * 存储器 */ private final Integer storage; /** * 配置类 */ private final Class<? extends FileClientConfig> configClass; /** * 客户端类 */ private final Class<? extends FileClient> clientClass; public static FileStorageEnum getByStorage(Integer storage) { return ArrayUtil.firstMatch(o -> o.getStorage().equals(storage), values()); } }
private <Config extends FileClientConfig> AbstractFileClient<Config> createFileClient( Long configId, Integer storage, Config config) { FileStorageEnum storageEnum = FileStorageEnum.getByStorage(storage); Assert.notNull(storageEnum, String.format("文件配置(%s) 为空", storageEnum)); // 创建客户端 return (AbstractFileClient<Config>) ReflectUtil.newInstance(storageEnum.getClientClass(), configId, config); }
- 通过
ReflectUtil.newInstance反射创建客户端实例(hutool提供)
- 多种文件客户端配置
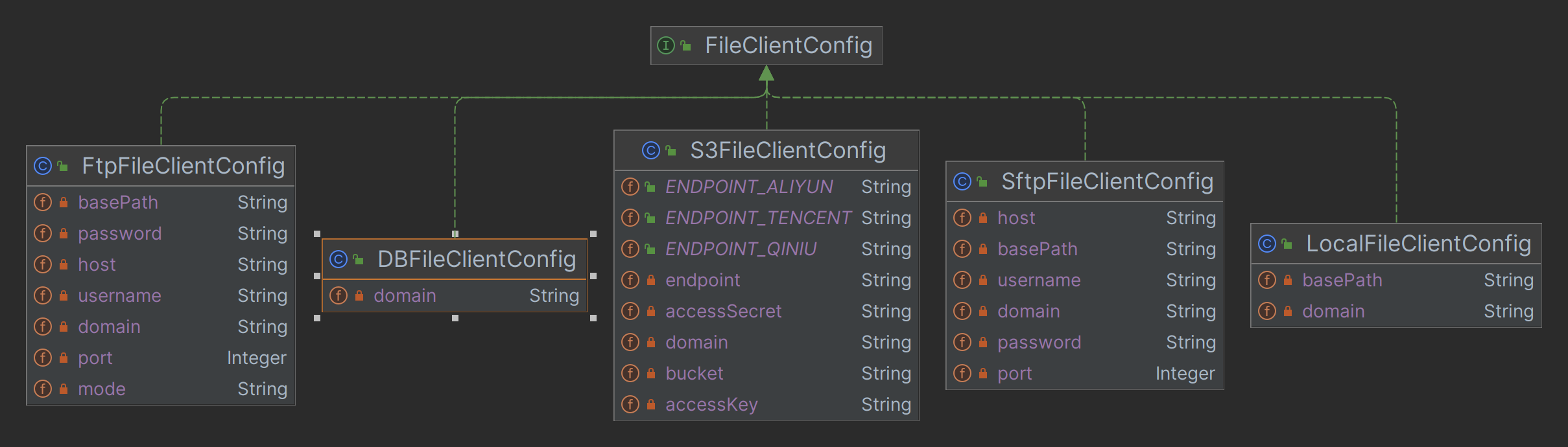
/** * 文件客户端的配置 * 不同实现的客户端,需要不同的配置,通过子类来定义 * * @author 芋道源码 */ @JsonTypeInfo(use = JsonTypeInfo.Id.CLASS) // @JsonTypeInfo 注解的作用,Jackson 多态 // 1. 序列化到时数据库时,增加 @class 属性。 // 2. 反序列化到内存对象时,通过 @class 属性,可以创建出正确的类型 public interface FileClientConfig { }
-
@JsonTypeInfo:- 序列化到时数据库时,增加 @class 属性。
- 反序列化到内存对象时,通过 @class 属性,可以创建出正确的类型
@JsonTypeInfo(use = JsonTypeInfo.Id.CLASS)是 Jackson 库中用于序列化和反序列化 Java 对象的注解。它的主要作用是为对象添加类型信息,以便在反序列化时能够正确还原对象的类型。这对于处理多态类型、子类对象和泛型类型非常有用。具体来说,
@JsonTypeInfo注解中的use属性定义了类型信息的存储方式,而JsonTypeInfo.Id枚举提供了不同的选项,其中包括以下几种常见的选项:-
JsonTypeInfo.Id.CLASS:使用类的全限定名作为类型标识,将类型信息作为属性添加到序列化后的 JSON 数据中。这允许在反序列化时将 JSON 转换回正确的 Java 类型。 -
JsonTypeInfo.Id.MINIMAL_CLASS:与JsonTypeInfo.Id.CLASS类似,但只存储最小限定的类名信息,以减少类型信息的大小。 -
JsonTypeInfo.Id.NAME:使用类名的简单名称作为类型标识,将类型信息作为属性添加到序列化后的 JSON 数据中。 -
JsonTypeInfo.Id.CUSTOM:允许自定义类型标识的存储和检索方式,需要提供自定义的TypeResolverBuilder实现。
@JsonTypeInfo注解通常与@JsonSubTypes注解一起使用,后者用于指定多态类型的子类。这样,Jackson 库在反序列化时能够正确地选择适当的子类来还原对象。示例:
@JsonTypeInfo(use = JsonTypeInfo.Id.CLASS) @JsonSubTypes({ @Type(value = Dog.class, name = "dog"), @Type(value = Cat.class, name = "cat") }) public abstract class Animal { // ... } public class Dog extends Animal { // ... } public class Cat extends Animal { // ... }
在上述示例中,
@JsonTypeInfo用于存储类型信息,并@JsonSubTypes用于定义多态类型的子类。这使得 Jackson 能够在反序列化时正确选择Dog或Cat类型的子类。
-
使用
tika做文件类型的识别<dependency> <groupId>org.apache.tika</groupId> <artifactId>tika-core</artifactId> <!-- 文件类型的识别 --> </dependency>
/** * 文件类型 Utils * * @author 芋道源码 */ public class FileTypeUtils { private static final ThreadLocal<Tika> TIKA = TransmittableThreadLocal.withInitial(Tika::new); /** * 获得文件的 mineType,对于doc,jar等文件会有误差 * * @param data 文件内容 * @return mineType 无法识别时会返回“application/octet-stream” */ @SneakyThrows public static String getMineType(byte[] data) { return TIKA.get().detect(data); } /** * 已知文件名,获取文件类型,在某些情况下比通过字节数组准确,例如使用jar文件时,通过名字更为准确 * * @param name 文件名 * @return mineType 无法识别时会返回“application/octet-stream” */ public static String getMineType(String name) { return TIKA.get().detect(name); } /** * 在拥有文件和数据的情况下,最好使用此方法,最为准确 * * @param data 文件内容 * @param name 文件名 * @return mineType 无法识别时会返回“application/octet-stream” */ public static String getMineType(byte[] data, String name) { return TIKA.get().detect(data, name); } }
-
文件客户端的缓存和更新
//主文件客户端id private static final Long CACHE_MASTER_ID = 0L; /** * {@link FileClient} 缓存,通过它异步刷新 fileClientFactory */ @Getter private final LoadingCache<Long, FileClient> clientCache = buildAsyncReloadingCache(Duration.ofSeconds(10L), new CacheLoader<Long, FileClient>() { @Override public FileClient load(Long id) { FileConfigDO config = Objects.equals(CACHE_MASTER_ID, id) ? fileConfigMapper.selectByMaster() : fileConfigMapper.selectById(id); if (config != null) { fileClientFactory.createOrUpdateFileClient(config.getId(), config.getStorage(), config.getConfig()); } return fileClientFactory.getFileClient(null == config ? id : config.getId()); } });
-
按链接访问文件
@GetMapping("/{configId}/get/**") @LoginFree @Operation(summary = "下载文件") @Parameter(name = "configId", description = "配置编号", required = true) public void getFileContent(HttpServletRequest request, HttpServletResponse response, @PathVariable("configId") Long configId) throws Exception { // 获取请求的路径 String path = StrUtil.subAfter(request.getRequestURI(), "/get/", false); if (StrUtil.isEmpty(path)) { throw new IllegalArgumentException("结尾的 path 路径必须传递"); } // 读取内容 byte[] content = fileService.getFileContent(configId, URLUtil.decode(path)); if (content == null) { log.warn("[getFileContent][configId({}) path({}) 文件不存在]", configId, path); response.setStatus(HttpStatus.NOT_FOUND.value()); return; } ServletUtils.writeAttachment(response, path, content); }
- 通过
/{configId}/get/**匹配所有文件访问请求
- 通过
-
文件管理数据库模型
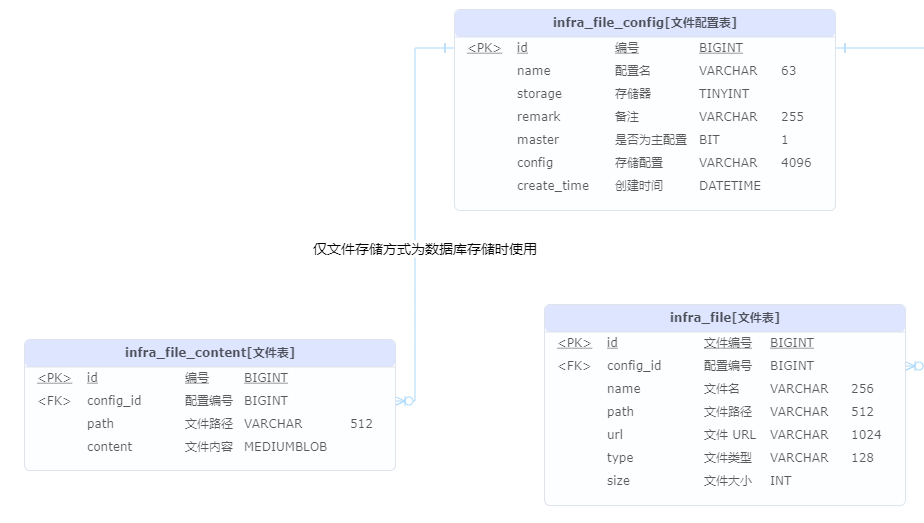
-
用户个人中心支持上传用户个人头像
-
S3 协议
S3(Simple Storage Service)协议是亚马逊 Web 服务(AWS)提供的对象存储服务的协议。S3 协议定义了一组 API 操作,用于存储和检索数据对象,这些对象可以是文件、图像、视频、文档等。AWS S3 是一种高度可扩展、安全和耐用的云存储服务,广泛用于存储和管理大量的数据。
MinIO,又称为MinIO Server,是一个开源的对象存储服务器,它实现了S3协议,使您能够在本地或私有云环境中构建和运行自己的对象存储服务。MinIO 的设计目标是提供与 AWS S3 兼容的存储服务,以便您可以使用现有的 S3 工具和库来访问和管理数据。MinIO 支持高度可扩展的架构,并具有出色的性能和可靠性,使其成为存储大规模数据的理想选择。
以下是 S3 协议和 MinIO 的关键特点和关系:
- S3 协议:
- S3 协议是 AWS 提供的对象存储服务的协议,定义了一组 API 操作,用于存储和检索数据对象。
- S3 协议是一种标准的云存储协议,广泛用于云存储服务和应用程序之间的数据交互。
- 它支持多种功能,包括对象存储、数据版本控制、数据加密、访问控制和数据生命周期管理。
- MinIO:
- MinIO 是一个开源的对象存储服务器,实现了 S3 协议,允许您在本地或私有云环境中构建和运行对象存储服务。
- MinIO 提供与 AWS S3 兼容的 API,使您可以使用 S3 工具和库来与 MinIO 交互。
- 它是一个高度可扩展的存储解决方案,适用于大规模数据存储和分发。
- 阿里云、腾讯云、七牛云、华为云等也提供了与 S3 协议兼容的对象存储服务或解决方案,使开发人员能够使用 S3 工具和库来与这些云服务交互
- MinIO 使用 S3 工具和库可以与阿里云、腾讯云、七牛云、华为云等进行交互
MinIO 的出现使开发人员能够搭建自己的 S3 兼容的对象存储服务器,而不必依赖于云服务提供商。这对于构建私有云存储、数据存档、备份和恢复解决方案以及开发基于对象存储的应用程序非常有用。MinIO 可以在 Docker 容器中运行,也可以部署到本地服务器或云环境中,使其非常灵活和易于管理。
- S3 协议:




-
API日志web组件apilog
-
访问日志记录
-
使用
Filter记录用户访问 API 的访问日志ApiAccessLogFilter.java@Override protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException { // 获得开始时间 LocalDateTime beginTime = LocalDateTime.now(); // 提前获得参数,避免 XssFilter 过滤处理 Map<String, String> queryString = ServletUtils.getParamMap(request); String requestBody = ServletUtils.isJsonRequest(request) ? ServletUtils.getBody(request) : null; try { // 继续过滤器 filterChain.doFilter(request, response); // 正常执行,记录日志 createApiAccessLog(request, beginTime, queryString, requestBody, null); } catch (Exception ex) { // 异常执行,记录日志 createApiAccessLog(request, beginTime, queryString, requestBody, ex); throw ex; } }
-
ServletUtils.isJsonRequest(request)判断是否为application/json亲求public static boolean isJsonRequest(ServletRequest request) { return StrUtil.startWithIgnoreCase(request.getContentType(), MediaType.APPLICATION_JSON_VALUE); }
-
-
构建访问日志
private void buildApiAccessLogDTO(ApiAccessLog accessLog, HttpServletRequest request, LocalDateTime beginTime, Map<String, String> queryString, String requestBody, Exception ex) { // 处理用户信息 accessLog.setUserId(WebFrameworkUtils.getLoginUserId(request)); accessLog.setUserType(WebFrameworkUtils.getLoginUserType(request)); // 设置访问结果 CommonResult<?> result = WebFrameworkUtils.getCommonResult(request); if (result != null) { accessLog.setResultCode(result.getCode()); accessLog.setResultMsg(result.getMsg()); } else if (ex != null) { accessLog.setResultCode(GlobalErrorCodeConstants.INTERNAL_SERVER_ERROR.getCode()); accessLog.setResultMsg(ExceptionUtil.getRootCauseMessage(ex)); } else { accessLog.setResultCode(0); accessLog.setResultMsg(""); } // 设置其它字段 accessLog.setTraceId("");// TODO: 2/11/2023 trace accessLog.setApplicationName(applicationName); accessLog.setRequestUrl(request.getRequestURI()); Map<String, Object> requestParams = MapUtil.<String, Object>builder().put("query", queryString).put("body", requestBody).build(); accessLog.setRequestParams(toJsonString(requestParams)); accessLog.setRequestMethod(request.getMethod()); accessLog.setUserAgent(ServletUtils.getUserAgent(request)); accessLog.setUserIp(ServletUtils.getClientIP(request)); // 持续时间 accessLog.setBeginTime(beginTime); accessLog.setEndTime(LocalDateTime.now()); accessLog.setDuration((int) LocalDateTimeUtil.between(accessLog.getBeginTime(), accessLog.getEndTime(), ChronoUnit.MILLIS)); }
ExceptionUtil.getRootCauseMessage(ex):获取异常链中最尾端的异常的消息(hutool提供)- WebFrameworkUtils.getCommonResult(request):获取访问结果.由GlobalResponseBodyHandler.java进行结果数据填充
-
-
错误日志记录
-
在系统异常中进行错误日志记录GlobalExceptionHandler.java
/** * 处理系统异常,兜底处理所有的一切 */ @ExceptionHandler(value = Exception.class) public CommonResult<?> defaultExceptionHandler(HttpServletRequest req, Throwable ex) { // 省略部分代码... // 情况三:处理异常 log.error("[defaultExceptionHandler]", ex); // 插入异常日志 this.createExceptionLog(req, ex); // 返回 ERROR CommonResult return CommonResult.error(INTERNAL_SERVER_ERROR.getCode(), INTERNAL_SERVER_ERROR.getMsg()); }
-
构建错误日志
private void initExceptionLog(ApiErrorLog errorLog, HttpServletRequest request, Throwable e) { // 处理用户信息 errorLog.setUserId(WebFrameworkUtils.getLoginUserId(request)); errorLog.setUserType(WebFrameworkUtils.getLoginUserType(request)); // 设置异常字段 errorLog.setExceptionName(e.getClass().getName()); errorLog.setExceptionMessage(ExceptionUtil.getMessage(e)); errorLog.setExceptionRootCauseMessage(ExceptionUtil.getRootCauseMessage(e)); errorLog.setExceptionStackTrace(ExceptionUtils.getStackTrace(e)); StackTraceElement[] stackTraceElements = e.getStackTrace(); Assert.notEmpty(stackTraceElements, "异常 stackTraceElements 不能为空"); StackTraceElement stackTraceElement = stackTraceElements[0]; errorLog.setExceptionClassName(stackTraceElement.getClassName()); errorLog.setExceptionFileName(stackTraceElement.getFileName()); errorLog.setExceptionMethodName(stackTraceElement.getMethodName()); errorLog.setExceptionLineNumber(stackTraceElement.getLineNumber()); // 设置其它字段 errorLog.setTraceId("");// TODO: 2/11/2023 trace errorLog.setApplicationName(applicationName); errorLog.setRequestUrl(request.getRequestURI()); Map<String, Object> requestParams = MapUtil.<String, Object>builder() .put("query", ServletUtils.getParamMap(request)) .put("body", ServletUtils.getBody(request)).build(); errorLog.setRequestParams(JsonUtils.toJsonString(requestParams)); errorLog.setRequestMethod(request.getMethod()); errorLog.setUserAgent(ServletUtils.getUserAgent(request)); errorLog.setUserIp(ServletUtils.getClientIP(request)); errorLog.setExceptionTime(LocalDateTime.now()); }
-
errorLog.setExceptionName(e.getClass().getName());:- 设置异常名.e.g:
java.lang.NullPointerException
- 设置异常名.e.g:
-
errorLog.setExceptionClassName(stackTraceElement.getClassName());- 设置异常发生的类全名: .e.g:
cn.hutool.core.collection.CollUtil
- 设置异常发生的类全名: .e.g:
-
errorLog.setExceptionMethodName(stackTraceElement.getMethodName());:- 设置异常发生的方法名: e.g:subtract
-
errorLog.setExceptionLineNumber(stackTraceElement.getLineNumber()):- 设置异常发生的方法所在行
-
errorLog.setExceptionStackTrace(ExceptionUtils.getStackTrace(e));-
设置异常的栈轨迹
java.lang.NullPointerException: Cannot invoke "Object.getClass()" because "coll1" is null at cn.hutool.core.collection.CollUtil.subtract(CollUtil.java:370) at cn.iocoder.yudao.module.system.service.user.AdminUserServiceImpl.updateUserPost(AdminUserServiceImpl.java:121) at cn.iocoder.yudao.module.system.service.user.AdminUserServiceImpl.updateUser(AdminUserServiceImpl.java:113) at //省略
-
ExceptionUtils.getStackTrace(e):从 Throwable 获取堆栈跟踪.(commons-lang3提供)
-
-
-
-
-
在request的attribute中存储响应结果(供ApiAccessLogFilter使用)
- 使用全局响应结果(ResponseBody)处理器进行响应结果存储,便于ApiAccessLogFilter进行读取
-
构建Request Body 缓存 Filter,实现它的可重复读取(供ApiAccessLogFilter使用)
-
CacheRequestBodyFilter:CacheRequestBodyFilter.java/** * Request Body 缓存 Filter,实现它的可重复读取 * * @author 芋道源码 */ public class CacheRequestBodyFilter extends OncePerRequestFilter { @Override protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws IOException, ServletException { filterChain.doFilter(new CacheRequestBodyWrapper(request), response); } @Override protected boolean shouldNotFilter(HttpServletRequest request) { // 只处理 json 请求内容 return !ServletUtils.isJsonRequest(request); } }
-
CacheRequestBodyWrapper:CacheRequestBodyFilter.java/** * Request Body 缓存 Wrapper * * @author 芋道源码 */ public class CacheRequestBodyWrapper extends HttpServletRequestWrapper { /** * 缓存的内容 */ private final byte[] body; public CacheRequestBodyWrapper(HttpServletRequest request) { super(request); body = ServletUtils.getBodyBytes(request); } @Override public BufferedReader getReader() throws IOException { return new BufferedReader(new InputStreamReader(this.getInputStream())); } @Override public ServletInputStream getInputStream() throws IOException { final ByteArrayInputStream inputStream = new ByteArrayInputStream(body); // 返回 ServletInputStream return new ServletInputStream() { @Override public int read() { return inputStream.read(); } @Override public boolean isFinished() { return false; } @Override public boolean isReady() { return false; } @Override public void setReadListener(ReadListener readListener) {} @Override public int available() { return body.length; } }; } }
-
CacheRequestBodyWrapper这段代码定义了一个名为
CacheRequestBodyWrapper的类,它是HttpServletRequestWrapper的子类。它的主要目的是包装原始的 HTTP 请求,以便在需要时缓存请求体(HTTP请求的主体内容)。这通常在处理请求体多次的情况下有用,因为 HTTP 请求体的数据流通常只能被读取一次。以下是代码的解释:-
CacheRequestBodyWrapper继承自HttpServletRequestWrapper,它是一个装饰器类,用于包装HttpServletRequest对象,以便在不改变原始请求对象的情况下增强其功能。 -
在构造函数中,它接受一个
HttpServletRequest对象作为参数,并调用ServletUtils.getBodyBytes(request)方法,将请求体的数据读取到body字节数组中。这个body数组将用于缓存请求体数据。 -
getReader()(读json字符时用)方法被重写,以便返回一个BufferedReader对象,该对象从包装的输入流中读取数据并提供字符流的读取。 -
getInputStream()(读文件时yon)方法也被重写,以返回一个自定义的ServletInputStream对象。这个对象通过body字节数组提供输入流,允许多次读取请求体数据。这是通过创建一个ByteArrayInputStream对象并重写ServletInputStream中的方法来实现的。read()方法用于读取一个字节的数据。isFinished()和isReady()方法通常用于异步处理,这里都返回false。setReadListener()方法通常用于异步处理,这里没有实现。available()方法返回缓存的请求体数据的可用字节数。
通过使用这个
CacheRequestBodyWrapper,你可以在需要多次访问请求体数据时,避免原始请求体数据只能读取一次的限制,而且可以在多个地方访问请求体数据,而不必每次都重新解析和读取请求体。这在某些情况下对性能优化和处理请求体数据的需求非常有用。 -
-
HttpServletRequestWrapper:HttpServletRequestWrapper是 Java Servlet API 中的一个类,用于包装HttpServletRequest对象,以便在处理 HTTP 请求时修改或增强请求的功能。它是 Servlet 编程中的一种设计模式,称为装饰器模式,允许你在不改变原始请求对象的情况下,对请求进行定制化的处理。使用
HttpServletRequestWrapper,你可以重写或添加方法,以满足你的需求,例如修改请求参数、请求头、URL,或者验证请求数据等。这可以在过滤器中进行,以实现对请求的全局处理,例如安全性检查、日志记录等。以下是一个简单的示例,演示如何使用
HttpServletRequestWrapper来修改请求参数:import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletRequestWrapper; public class MyHttpServletRequestWrapper extends HttpServletRequestWrapper { public MyHttpServletRequestWrapper(HttpServletRequest request) { super(request); } @Override public String getParameter(String name) { String originalValue = super.getParameter(name); if (name.equals("exampleParam")) { // 修改名为 "exampleParam" 的参数的值 return "modifiedValue"; } return originalValue; } }
然后,你可以在过滤器中使用这个包装器:
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { if (request instanceof HttpServletRequest) { HttpServletRequest httpRequest = (HttpServletRequest) request; MyHttpServletRequestWrapper wrappedRequest = new MyHttpServletRequestWrapper(httpRequest); // 将修改后的请求对象传递给下一个过滤器或 Servlet chain.doFilter(wrappedRequest, response); } else { chain.doFilter(request, response); } }
这是一个非常简单的示例,你可以根据需要定制
HttpServletRequestWrapper来满足你的具体要求,例如对请求数据的加密、解密,或者进行其他自定义处理。
-
-
-
错误日志的处理:
- 未处理
- 已处理
- 已忽略
-
API日志数据库模型
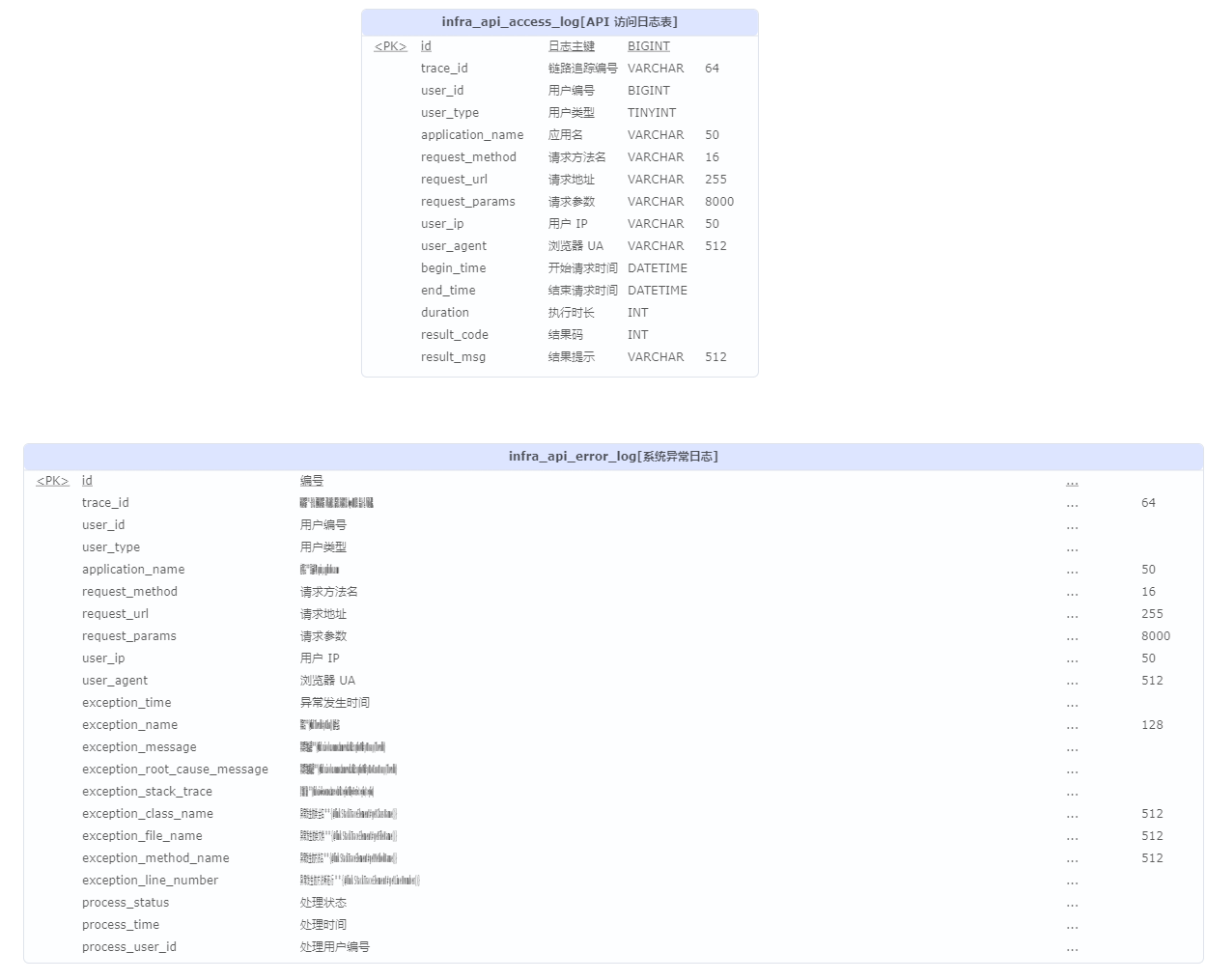

-
开启Druid的监控统计功能
spring: # 数据源配置项 datasource: druid: # Druid 【监控】相关的全局配置 web-stat-filter: #ruoyi-vue-pro自定义的广告过滤器 enabled: true stat-view-servlet: #Druid的监控统计功能过滤器 enabled: true #开启Druid的监控统计功能页面 allow: # 设置IP白名单,不填则允许所有访问 deny: 127.0.0.1 # IP 黑名单,若白名单也存在,则优先使用 url-pattern: /druid/* #配置druid管理后台的访问路径 e.g.: /aa/* 则访问路径为: http://localhost:48080/aa/index.html reset-enable: false # 禁用 HTML 中 Reset All 按钮 login-username: root # 控制台管理用户名和密码 login-password: 123456
-
过滤掉druid的广告
-
指定
DruidAdRemoveFilter过滤器拦截/druid/js/common.js请求/** * 创建 DruidAdRemoveFilter 过滤器,过滤 common.js 的广告 */ @Bean @ConditionalOnProperty(name = "spring.datasource.druid.web-stat-filter.enabled", havingValue = "true") public FilterRegistrationBean<DruidAdRemoveFilter> druidAdRemoveFilterFilter(DruidStatProperties properties) { // 获取 druid web 监控页面的参数 DruidStatProperties.StatViewServlet config = properties.getStatViewServlet(); // 提取 common.js 的配置路径 String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*"; String commonJsPattern = pattern.replaceAll("\\*", "js/common.js"); // 创建 DruidAdRemoveFilter Bean FilterRegistrationBean<DruidAdRemoveFilter> registrationBean = new FilterRegistrationBean<>(); registrationBean.setFilter(new DruidAdRemoveFilter()); registrationBean.addUrlPatterns(commonJsPattern); return registrationBean; }
-
Druid 底部广告过滤器
DruidAdRemoveFilter/** * Druid 底部广告过滤器 * * @author 芋道源码 */ public class DruidAdRemoveFilter extends OncePerRequestFilter { /** * common.js 的路径 */ private static final String COMMON_JS_ILE_PATH = "support/http/resources/js/common.js"; @Override protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain chain) throws ServletException, IOException { chain.doFilter(request, response); // 重置缓冲区,响应头不会被重置 response.resetBuffer(); // 获取 common.js String text = Utils.readFromResource(COMMON_JS_ILE_PATH); // 正则替换 banner, 除去底部的广告信息 text = text.replaceAll("<a.*?banner\"></a><br/>", ""); text = text.replaceAll("powered.*?shrek.wang</a>", ""); response.getWriter().write(text); } }
-
esponse.resetBuffer();这行代码的作用
response.resetBuffer()是用于重置响应缓冲区的方法。在Servlet中,HTTP响应的内容通常是通过响应缓冲区来构建的,然后一次性发送给客户端。这个缓冲区允许在生成响应时将内容暂时存储,以便在后续的处理过程中进行修改或处理。response.resetBuffer()的作用是清空响应缓冲区中的任何先前内容,以确保后续的响应内容将从头开始构建。这通常用于在过滤器或Servlet中进行响应内容的修改,以避免旧内容与新内容混合在一起。在给定的代码中,
response.resetBuffer()被用于重置响应缓冲区,以便在后续代码中修改text变量的内容,并将修改后的内容写入响应,而不会受到之前可能存在的任何响应内容的干扰。这是因为doFilterInternal方法可能被多个过滤器链式调用,每个过滤器都可以操作响应内容,因此需要确保每个过滤器在操作响应内容时有一个干净的起点。 -
chain.doFilter(request, response);为什么不写在最后面的位置
chain.doFilter(request, response)写在doFilterInternal方法最后面,起不到去除广告的功能.原因未知
-
-
-
获取Redis监控信息
@GetMapping("/get-monitor-info") @Operation(summary = "获得 Redis 监控信息") @PreAuthorize("@ss.hasPermission('infra:redis:get-monitor-info')") public CommonResult<RedisMonitorRespVO> getRedisMonitorInfo() { // 获得 Redis 统计信息 Properties info = stringRedisTemplate.execute((RedisCallback<Properties>) RedisServerCommands::info); Long dbSize = stringRedisTemplate.execute(RedisServerCommands::dbSize); Properties commandStats = stringRedisTemplate.execute(( RedisCallback<Properties>) connection -> connection.info("commandstats")); assert commandStats != null; // 断言,避免警告 // 拼接结果返回 return success(RedisConvert.INSTANCE.build(info, dbSize, commandStats)); }
info:Redis info 指令结果,具体字段,查看 Redis 文档dbSize:Redis key 数量commandStats:Redis 命令统计信息,包括命令执行次数、执行时间
-
引入依赖
<dependency> <groupId>de.codecentric</groupId> <artifactId>spring-boot-admin-starter-server</artifactId> <!-- 实现 Spring Boot Admin Server 服务端 --> <version>${spring-boot-admin.version}</version> <exclusions> <exclusion> <groupId>de.codecentric</groupId> <artifactId>spring-boot-admin-server-cloud</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>de.codecentric</groupId> <artifactId>spring-boot-admin-starter-client</artifactId> <!-- 实现 Spring Boot Admin Server 服务端 --> <version>${spring-boot-admin.version}</version> </dependency>
-
yaml配置
--- #################### 监控相关配置 #################### # Actuator 监控端点的配置项 management: endpoints: web: base-path: /actuator # Actuator 提供的 API 接口的根目录。默认为 /actuator exposure: include: '*' # 需要开放的端点。默认值只打开 health 和 info 两个端点。通过设置 * ,可以开放所有端点。 # Spring Boot Admin 配置项 spring: boot: admin: # Spring Boot Admin Client 客户端的相关配置 client: url: http://127.0.0.1:${server.port}/${spring.boot.admin.context-path} # 设置 Spring Boot Admin Server 地址 instance: service-host-type: IP # 注册实例时,优先使用 IP [IP, HOST_NAME, CANONICAL_HOST_NAME] # Spring Boot Admin Server 服务端的相关配置 context-path: /admin # 配置 Spring
-
开启AdminServer
@Configuration(proxyBeanMethods = false) @EnableAdminServer public class AdminServerConfiguration { }
-
开启Admin Client
<dependency> <groupId>de.codecentric</groupId> <artifactId>spring-boot-admin-starter-client</artifactId> </dependency>
-
spring security允许匿名访问
@Value("${spring.boot.admin.context-path:''}") private String adminSeverContextPath; @Bean("infraAuthorizeRequestsCustomizer") public AuthorizeRequestsCustomizer authorizeRequestsCustomizer() { return new AuthorizeRequestsCustomizer() { @Override public void customize(ExpressionUrlAuthorizationConfigurer<HttpSecurity>.ExpressionInterceptUrlRegistry registry) { // Spring Boot Actuator 的安全配置 registry.antMatchers("/actuator").anonymous() .antMatchers("/actuator/**").anonymous(); // Spring Boot Admin Server 的安全配置 registry.antMatchers(adminSeverContextPath).anonymous() .antMatchers(adminSeverContextPath + "/**").anonymous(); } }; }
-
Quartz作业调度框架(前置知识)
-
Quartz其中的核心类和执行流程
Quartz的核心类和执行流程涉及多个关键概念和组件。以下是其中一些核心类以及执行流程的简要描述:
核心类:
-
Scheduler(调度器):Scheduler是Quartz的核心组件,负责触发和执行作业。它是整个调度系统的控制中心,用于安排作业的执行。Scheduler可以创建、删除、暂停和恢复作业,并提供了对作业的管理接口。
-
Job(作业):Job是您要执行的任务的抽象表示。您需要实现Job接口并编写具体的任务逻辑。每个Job都有一个关联的JobDetail对象,它包含有关Job的详细信息,如Job的名称、组别、描述等。
-
Trigger(触发器):Trigger用于定义作业的执行时机。它指定了作业何时执行,可以基于简单的时间间隔、Cron表达式或日历规则触发作业的执行。Quartz提供了不同类型的Trigger,包括SimpleTrigger和CronTrigger。
-
JobDetail(作业详情):JobDetail包含有关特定作业的详细信息,包括作业类的引用、作业的名称和组别等。每个Job都需要关联一个JobDetail,以便Scheduler知道要执行哪个Job。
-
JobExecutionContext(作业执行上下文):在作业执行时,Quartz会将一个JobExecutionContext对象传递给Job,其中包含了有关作业执行的信息,如作业的名称、触发器的信息、Scheduler的引用等。Job可以使用这个上下文来访问和操作执行环境。
执行流程:
-
创建和配置调度器:首先,您需要创建一个Scheduler实例,并配置它。配置包括设置调度器的属性、添加作业和触发器、定义作业的详细信息等。
-
定义作业和触发器:您需要创建Job和Trigger的实例,并将它们与JobDetail相关联。Trigger定义了作业的执行时机,可以是SimpleTrigger或CronTrigger,根据您的需求选择。
-
将作业和触发器添加到调度器:将JobDetail和Trigger添加到调度器中,使它们能够被调度器管理和执行。
-
启动调度器:一旦配置完成,您需要启动调度器,它会开始根据触发器的定义来执行作业。
-
作业执行:根据触发器的触发条件,Scheduler会选择相应的作业,并执行它们。在执行过程中,Job可以访问作业执行上下文,执行特定的任务逻辑。
-
监控和管理:您可以使用Quartz提供的监控和管理工具来实时监视作业的执行情况、触发器的状态,并进行手动操作,如暂停、恢复或删除作业。
-
停止调度器:当不再需要调度作业时,可以停止调度器,以释放资源和停止作业的执行。
这是Quartz的核心类和执行流程的简要概述。Quartz提供了更复杂的特性和选项,以满足各种调度需求,但以上所述是基本的工作原理。
-
-
JobStoreJobStore 是 Quartz 调度框架中的一个关键组件,它负责管理和存储作业(Job)和触发器(Trigger)的信息,实现了作业的持久性和可靠的调度。JobStore 的主要作用包括:
-
持久性存储:JobStore 将作业和触发器的信息存储在数据库中,这意味着即使应用程序关闭或重启,调度器的信息仍然得以保留。这是实现作业持久性的关键,因为作业的调度信息需要在应用程序生命周期内存储并恢复。
-
集群支持:JobStore 可以支持分布式的集群部署,多个 Quartz 调度器实例可以共享相同的数据库,以便在多个节点上协同执行作业。JobStore 负责协调不同节点上的调度器,确保作业不会重复执行,同时实现负载均衡。
-
作业调度管理:JobStore 负责跟踪触发器和作业之间的关联关系,以确保触发器按照预定的时间表执行相关的作业。它管理触发器的触发状态、上次触发时间和下次触发时间等信息。
-
触发器状态维护:JobStore 负责维护触发器的状态,包括触发器的状态(如等待、运行中、暂停等)以及触发器的错过触发处理。这确保触发器的行为是可控和可管理的。
-
作业执行历史记录:JobStore 可以记录作业执行的历史信息,包括成功执行、失败执行、触发时间等。这有助于监控和审计作业的执行情况。
Quartz 提供了不同的 JobStore 实现,包括 RAMJobStore、JDBCJobStore 和 TerracottaJobStore,您可以根据应用程序的需求选择适合的 JobStore 实现。不同的 JobStore 实现可以使用不同的持久性存储方式(内存、数据库、分布式存储等),但它们都实现了相同的接口,以提供一致的调度功能。 JobStore 是 Quartz 调度框架的核心组件之一,确保了调度器的可靠性、持久性和高可用性。
-
-
Quartz各个表结构的关系
Quartz 调度器使用数据库来存储调度信息,以便支持作业的持久性和集群部署。它定义了多个数据库表来管理不同方面的调度信息,这些表之间有着特定的关系。以下是Quartz数据库表结构之间的关系:
-
QRTZ_SCHEDULER_STATE表:该表存储调度器的状态信息,如调度器的名称、调度器实例的标识符、调度器实例的版本等。这个表通常只有一行记录。
-
QRTZ_TRIGGERS表:Triggers表存储所有的触发器信息,包括触发器的名称、组别、作业的关联、触发器的类型(SimpleTrigger或CronTrigger)等。它与作业之间存在一对多的关系,因为一个作业可以有多个触发器。
-
QRTZ_SIMPLE_TRIGGERS表:如果触发器是SimpleTrigger类型的,那么触发器的详细信息将存储在这个表中,包括重复计数、重复间隔等。
-
QRTZ_CRON_TRIGGERS表:如果触发器是CronTrigger类型的,那么CronTrigger的表达式将存储在这个表中。
-
QRTZ_JOB_DETAILS表:JobDetails表存储了作业的详细信息,包括作业的名称、组别、作业类、作业描述等。它与触发器之间存在一对多的关系,因为一个作业可以关联多个触发器。
-
QRTZ_JOB_LISTENERS表:这个表存储作业监听器的信息,它定义了与作业关联的监听器,以便在作业执行时触发监听器的事件。
-
QRTZ_TRIGGER_LISTENERS表:与作业监听器类似,这个表存储触发器监听器的信息,以便在触发器触发时触发监听器的事件。
-
QRTZ_CAL_TRIGGERS表:这个表存储与日历相关的触发器的信息,用于指定触发器的调度时间。通常,它们与CronTrigger一起使用。
-
QRTZ_PAUSED_TRIGGER_GRPS表:这个表用于存储被暂停的触发器组的信息。
-
QRTZ_PAUSED_JOB_GROUPS表:类似于暂停的触发器组,这个表用于存储被暂停的作业组的信息。
-
QRTZ_LOCKS表:该表用于协调多个调度器实例之间的操作,以确保在集群环境下只有一个调度器实例能够执行给定的任务。
这些表之间的关系构成了Quartz调度器的持久性存储结构,使其能够在不同的调度器实例之间共享调度信息,并在重启后保持一致的状态。这些表和关系使Quartz能够有效地进行作业调度和管理,无论是在单机还是分布式的环境中。
-
-
-
创建job组件
-
引入quartz依赖:yudao-spring-boot-starter-job
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-quartz</artifactId> </dependency>
-
配置quartz配置
--- #################### 定时任务相关配置 #################### # Quartz 配置项,对应 QuartzProperties 配置类 spring: quartz: auto-startup: true # 本地开发环境,尽量不要开启 Job scheduler-name: schedulerName # Scheduler 名字。默认为 schedulerName job-store-type: jdbc # Job 存储器类型。默认为 memory 表示内存,可选 jdbc 使用数据库。 wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true properties: # 添加 Quartz Scheduler 附加属性,更多可以看 http://www.quartz-scheduler.org/documentation/2.4.0-SNAPSHOT/configuration.html 文档 org: quartz: # Scheduler 相关配置 scheduler: instanceName: schedulerName instanceId: AUTO # 自动生成 instance ID # JobStore 相关配置 jobStore: # JobStore 实现类。可见博客:https://blog.csdn.net/weixin_42458219/article/details/122247162 class: org.springframework.scheduling.quartz.LocalDataSourceJobStore isClustered: true # 是集群模式 clusterCheckinInterval: 15000 # 集群检查频率,单位:毫秒。默认为 15000,即 15 秒 misfireThreshold: 60000 # misfire 阀值,单位:毫秒。 # 线程池相关配置 threadPool: threadCount: 25 # 线程池大小。默认为 10 。 threadPriority: 5 # 线程优先级 class: org.quartz.simpl.SimpleThreadPool # 线程池类型 jdbc: # 使用 JDBC 的 JobStore 的时候,JDBC 的配置 initialize-schema: NEVER # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。
-
核心代码
-
org.quartz.Scheduler的管理器,负责管理任务- 添加 Job 到 Quartz 中
- 更新 Job 到 Quartz
- 删除 Quartz 中的 Job
- 暂停 Quartz 中的 Job
- 启动 Quartz 中的 Job
- 立即触发一次 Quartz 中的 Job
- 使用
jobHandlerName属性作为唯一标识jobDetail的唯一标识为jobHandlerNameTrigger的唯一标识为jobHandlerName- jobHandlerName 对应到
任务处理器JobHandlerSpring Bean 的名字,可以直接调用
-
-
是一个
Job -
负责调用
JobHandler(执行任务) -
负责记录任务日志
-
辅助参数(辅助任务执行)
- refireCount:第几次执行
- retryCount:最大重试次数
- retryInterval:每次重试间隔
- jobHandlerName:
JobHandler的bean名称 - jobHandlerParam:任务参数,也是
JobHandler的execute方法的参数
-
@DisallowConcurrentExecution@DisallowConcurrentExecution是一个注解(Annotation),通常用于标记 Quartz 作业(Job)类,以确保同一个作业实例不会同时并发执行。这个注解的作用是防止多个触发器同时触发同一个作业实例,从而避免并发执行的情况。在 Quartz 中,默认情况下,如果一个触发器触发了一个作业,而该作业的执行时间较长,那么当下一个触发器触发同一个作业时,Quartz 会创建一个新的作业实例来处理这次触发。这可能导致多个作业实例并发执行同一个作业。
使用
@DisallowConcurrentExecution注解可以解决这个问题,它告诉 Quartz 不要同时执行同一个作业实例,即使多个触发器触发了它。当一个触发器触发作业时,如果前一个作业实例还在执行,新的触发器会等待前一个作业完成后再执行。这确保了作业实例的互斥执行,避免了并发执行导致的潜在问题。示例:
import org.quartz.DisallowConcurrentExecution; import org.quartz.Job; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; @DisallowConcurrentExecution public class MyJob implements Job { @Override public void execute(JobExecutionContext context) throws JobExecutionException { // 作业逻辑 } }
在上面的示例中,
@DisallowConcurrentExecution注解被添加到MyJob类上,这意味着不会出现多个触发器同时触发MyJob实例的情况。如果前一个触发器触发了MyJob,而MyJob的执行时间较长,后续触发器会等待前一个执行完成后再执行。这个注解通常用于确保作业实例的独占性,特别是当作业逻辑具有并发问题或资源竞争时,使用
@DisallowConcurrentExecution可以确保作业的安全执行。 -
@PersistJobDataAfterExecution@PersistJobDataAfterExecution是一个注解(Annotation),通常用于标记 Quartz 作业(Job)类,以指示 Quartz 在每次作业执行后持久化作业数据,即在每次作业执行后更新作业数据。通常,Quartz 允许作业实例关联一些数据,这些数据可以在作业执行过程中使用。这些数据可以存储在作业实例的 JobDataMap 中,而
@PersistJobDataAfterExecution注解的作用是告诉 Quartz 在每次作业执行后,将 JobDataMap 中的数据持久化到数据库中,以确保在下次执行作业时,这些数据依然是最新的。使用
@PersistJobDataAfterExecution注解的主要作用包括:-
持久化作业数据:在每次作业执行后,JobDataMap 中的数据将被保存到 Quartz 数据库中,以确保作业的状态和数据持久化。这对于需要跟踪作业执行状态或存储作业的执行历史非常有用。
-
动态参数更新:通过持久化作业数据,您可以在不停止 Quartz 调度器的情况下更新作业的参数。这允许您在运行时修改作业的参数,而不需要修改触发器或作业的配置。
示例:
import org.quartz.PersistJobDataAfterExecution; import org.quartz.Job; import org.quartz.JobDataMap; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; @PersistJobDataAfterExecution public class MyJob implements Job { @Override public void execute(JobExecutionContext context) throws JobExecutionException { JobDataMap jobDataMap = context.getJobDetail().getJobDataMap(); // 获取作业参数 String parameter = jobDataMap.getString("parameter"); // 执行作业逻辑 System.out.println("Job is running with parameter: " + parameter); // 更新作业参数 jobDataMap.put("parameter", "UpdatedParameter"); } }
在上面的示例中,
@PersistJobDataAfterExecution注解被添加到MyJob类上,以指示 Quartz 在每次执行后持久化作业数据。在作业的execute方法中,我们可以获取作业参数、执行作业逻辑,然后更新参数。更新后的参数将在下次执行作业时使用,而不需要修改触发器或作业的配置。这个注解非常有用,特别是在需要动态管理和更新作业参数时,以及需要跟踪作业状态和执行历史时。
-
-
-
- 任务处理器,包含具体任务的执行逻辑
- 一个接口,有业务方进行具体实现
- 会被
JobHandlerInvoker进行调用 - 各个业务的
JobHandler- DemoJob.java
- AccessLogCleanJob.java :物理删除 N 天前的访问日志的 Job
- ErrorLogCleanJob.java:物理删除 N 天前的错误日志的 Job
- JobLogCleanJob.java:物理删除 N 天前的任务日志的 Job
-
-
-
管理后台定时任务和定时任务日志crud
-
管理后台定时任务数据库模型

-
租户组件对job的适配
- 忽略多租户的 Aspect
- 基于 TenantIgnore 注解实现,用于一些全局忽略多租户的逻辑.比如
AccessLogCleanJob
- 基于 TenantIgnore 注解实现,用于一些全局忽略多租户的逻辑.比如
- 多租户 Aspect
- 多租户 JobHandler AOP 任务执行时,会按照租户逐个执行 Job 的逻辑
- 注意,需要保证 JobHandler 的幂等性。因为 Job 因为某个租户执行失败重试时,之前执行成功的租户也会再次执行。(被AOP catch掉了异常,因此某个租户执行失败后不会发生重试)
- 忽略多租户的 Aspect

-
会员标签数据库模型
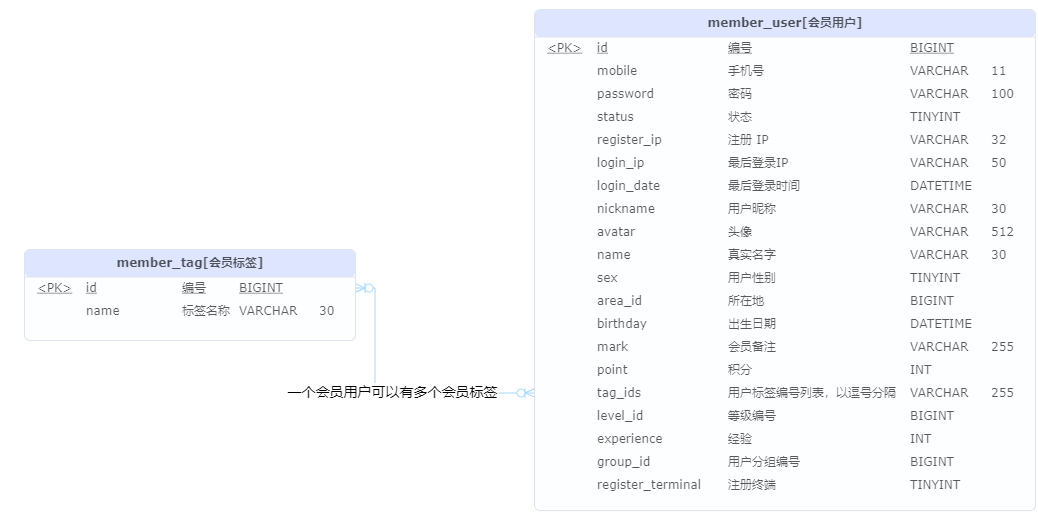

-
会员分组数据库模型
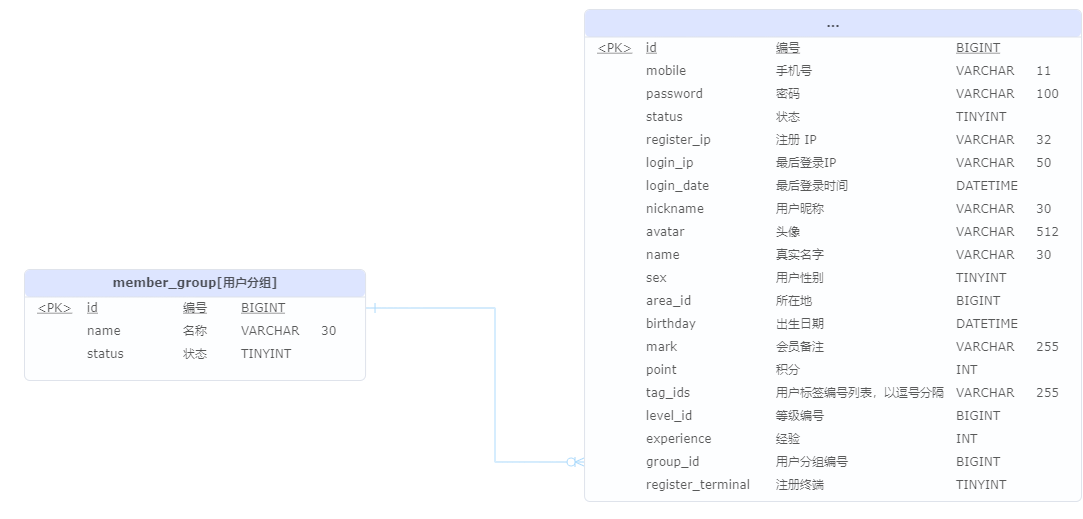

-
会员管理-会员用户分页数据库模型

-
sql函数
FIND_IN_SETSELECT COUNT(*) AS total FROM member_user WHERE deleted = 0 AND (FIND_IN_SET(1, tag_ids)) AND tenant_id = 1
FIND_IN_SET是 MySQL 中的一个函数,用于在逗号分隔的字符串(e.g: 1,2)中查找某个值是否存在。函数的语法如下:FIND_IN_SET(search_value, string_list)
search_value: 要查找的值。string_list: 逗号分隔的字符串列表。
FIND_IN_SET返回搜索值在字符串列表中的位置。如果找到,则返回位置索引(从 1 开始),如果未找到,则返回 0。在你的查询中,它被用于检查在tag_ids字段中是否包含值1。在你提供的 SQL 查询中,具体的使用是:
FIND_IN_SET(1, tag_ids)这将返回
1或0。如果tag_ids字段中包含值1,则返回1,否则返回0。在你的查询中,这个条件用于过滤满足以下条件的记录:deleted字段的值为0。tag_ids字段中包含值1。tenant_id字段的值为1。
因此,这个查询计算了符合这些条件的记录的总数,并将其作为
total返回。

-
会员积分-数据库模型
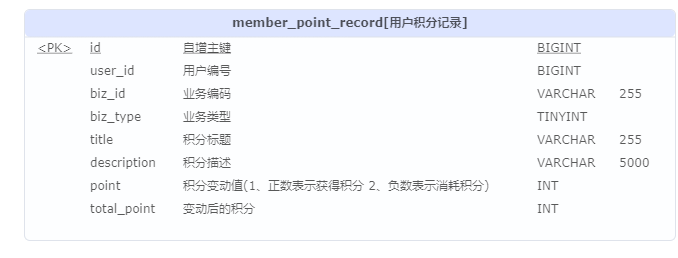
- biz_type
- 1-签到
- 2-管理员修改
- 11-订单积分抵扣
- 12-订单积分抵扣(整单取消)
- 13-订单积分抵扣(单个退款)
- 21-订单积分奖励
- 22-订单积分奖励(整单取消)
- 23-订单积分奖励(单个退款)
- point: 1、正数表示获得积分 2、负数表示消耗积分
- biz_type

-
会员等级-数据库模型
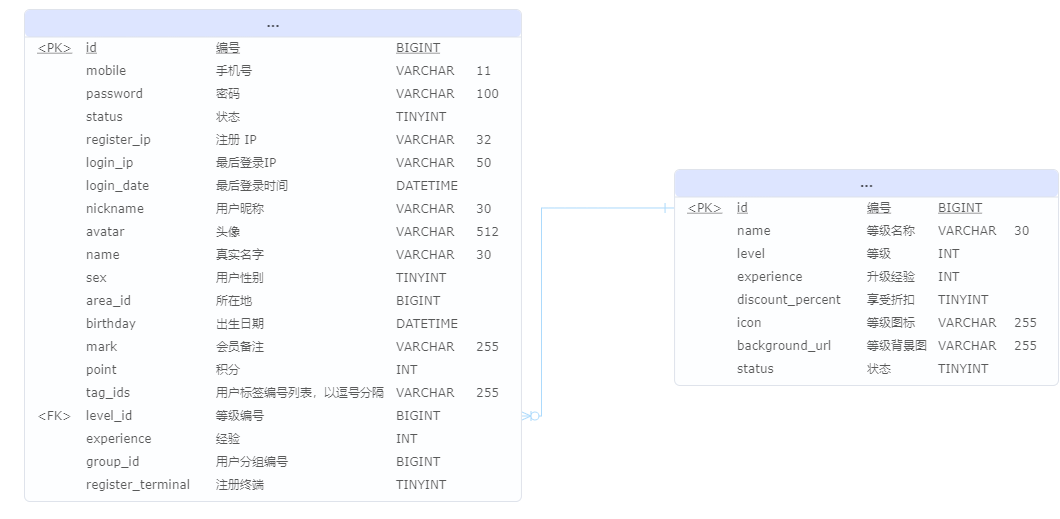
- 用户是和等级id关联会导致的问题
- 如果后台更新用户等级该级别所需经验值之后,可能会导致用户实际经验和等级不匹配.
- 后台可以修改等级表的级别,用户的级别发生变更后,导致用户实际经验和等级不匹配.
- 后台关闭某等级后,会导致对应等级用户有经验值无等级
- 用户是和等级id关联会导致的问题
-
会员等级crud
- 等级之间不连贯,可以跳级.
- 高低等级间的折扣率大小没做校验
-
积分扣减的代码(不在本次提交)
/** * 更新用户积分(减少) * * @param id 用户编号 * @param incrCount 增加积分(负数) * @return 更新行数 */ default int updatePointDecr(Long id, Integer incrCount) { Assert.isTrue(incrCount < 0); LambdaUpdateWrapper<MemberUserDO> lambdaUpdateWrapper = new LambdaUpdateWrapper<MemberUserDO>() .setSql(" point = point + " + incrCount) // 负数,所以使用 + 号 .eq(MemberUserDO::getId, id); return update(null, lambdaUpdateWrapper); }
- 可能会导致积分扣减为负数,下单扣减积分时未在sql语句中判断积分是否充足,订单取消时不用判断

-
会员配置数据库模型


- 业务代码缺少很多校验
-
会员签到数据库模型
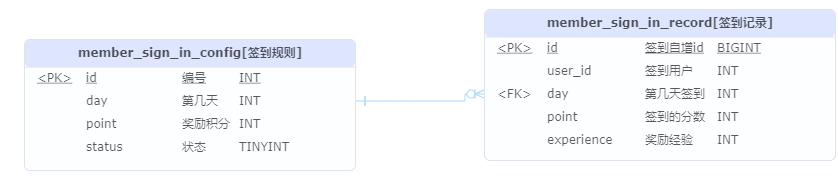

- 只是配置,
- 不知如何实现累计签到的
- 以及中间第5天未配置签到,签到奖励如何处理
- 数据库模型
-
会员等级
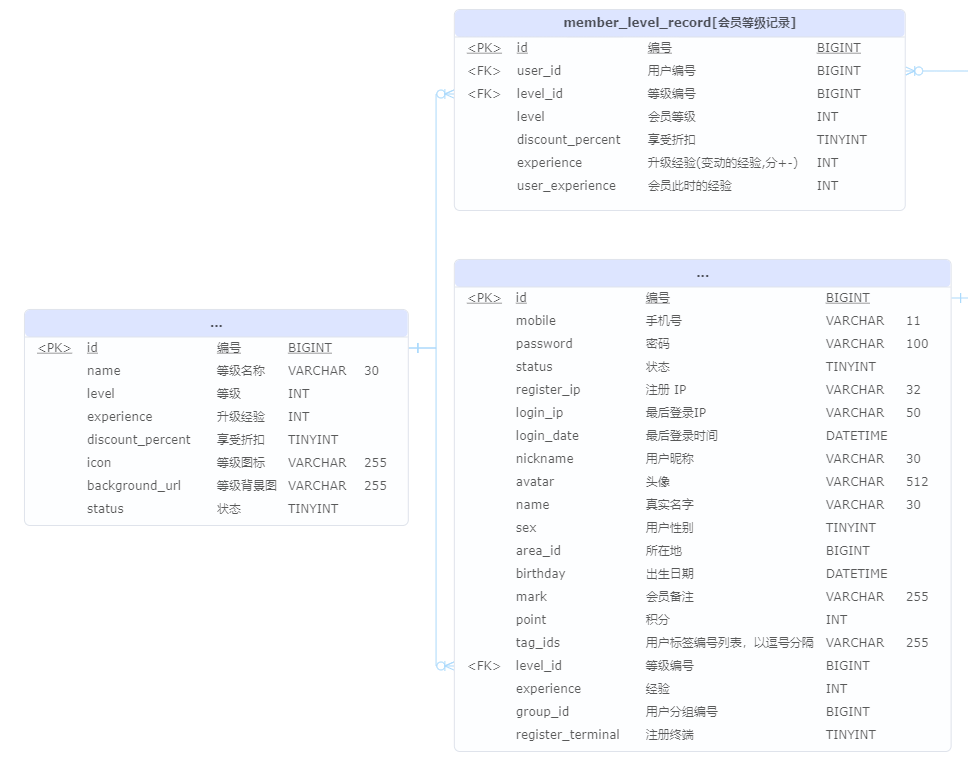
-
会员经验值

- 业务类型
- 0-管理员调整
- 1-邀新奖励
- 4-签到奖励
- 5-抽奖奖励
- 11-下单奖励
- 12-下单奖励(整单取消)
- 13-下单奖励(单个退款)
- 业务类型
-
会员积分
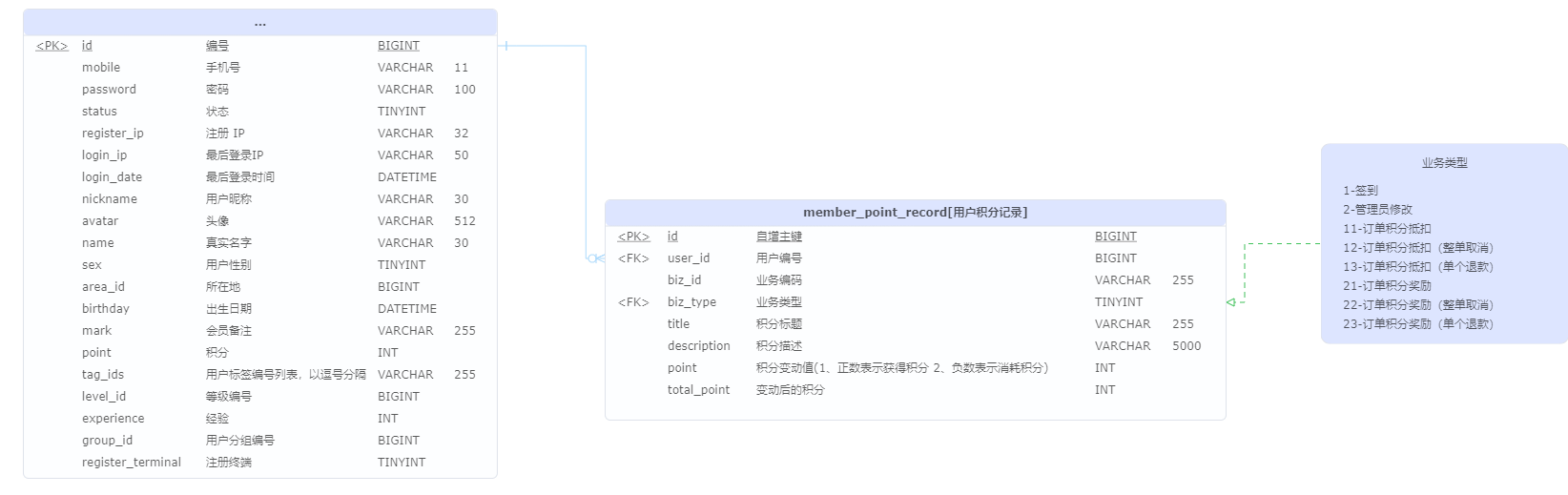
- 业务类型
- 1-签到
- 2-管理员修改
- 11-订单积分抵扣
- 12-订单积分抵扣(整单取消)
- 13-订单积分抵扣(单个退款)
- 21-订单积分奖励
- 22-订单积分奖励(整单取消)
- 23-订单积分奖励(单个退款)
- 业务类型
-
- 修改等级(或删除等级)
- 记录等级修改记录
- 记录经验修改记录
- 等级变动,会触发经验变动
- 修改用户等级
- 给会员发送等级变动消息(todo)
- 修改积分
- 校验用户积分余额
- 更新用户积分
- 增加积分记录



-
收货地址数据库模型

-
mapstruct自定义字段映射
@Mapper public interface AddressConvert { AddressConvert INSTANCE = Mappers.getMapper(AddressConvert.class); @Named("convertAreaIdToAreaName") default String convertAreaIdToAreaName(Integer areaId) { return AreaUtils.format(areaId); } }
在
MemberUserConvert中使用AddressConvert的convertAreaIdToAreaName方法进行VO转换@Mapper(uses = {AddressConvert.class}) public interface MemberUserConvert { @Mapping(source = "areaId", target = "areaName", qualifiedByName = "convertAreaIdToAreaName") MemberUserRespVO convert03(MemberUserDO bean); }

-
商品分类数据库模型
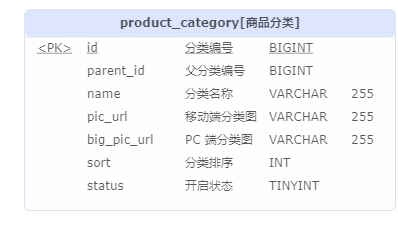

- 仅支持二级类目
-
商品品牌数据库模型

- 品牌名称逻辑上保证唯一

-
商品属性数据库模型
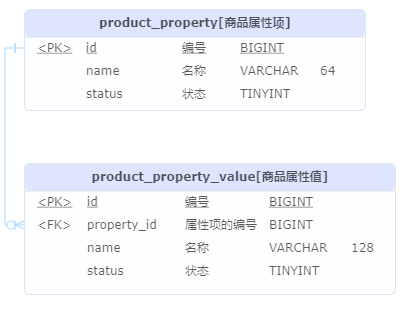
- 属性名称逻辑上保证唯一
- 属性值名称在同一属性下逻辑上保证唯一

-
商品数据库模型
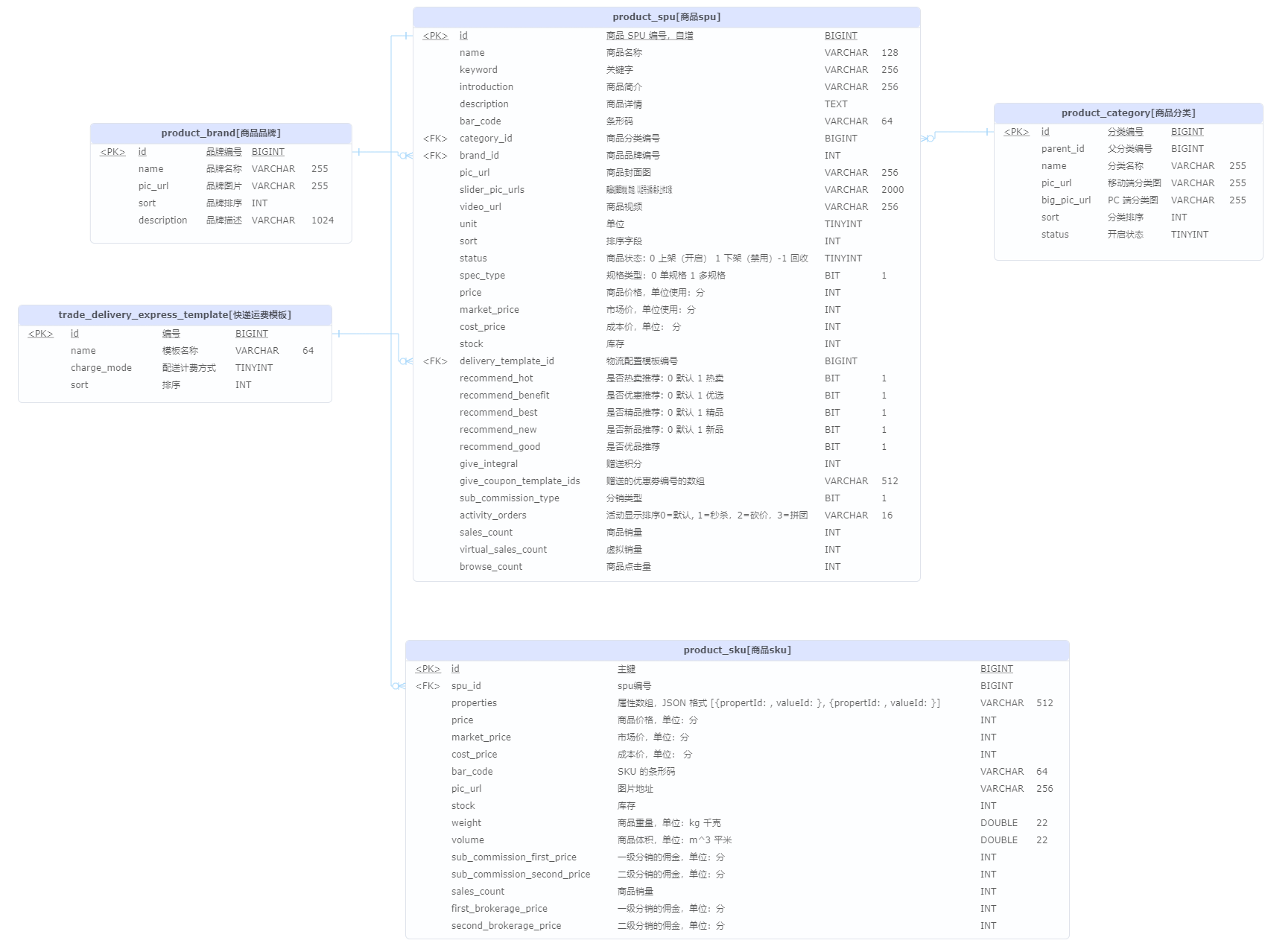
price:取单价最低的商品的价格market_price:取单价最低的商品的市场价格cost_price:取单价最低的商品的成本价格stock:sku的库存总数activity_orders:获得显示排序数组.e.g:[2,1,3]
-
商品新增
- 校验分类、品牌
- 校验 SKU
- 单规格,赋予单规格默认属性
- 校验属性项存在(缺属性值存在校验)
- 校验,一个 SKU 下,没有重复的属性。(无重复属性,应该也就不会有重复属性值,属性值挂在属性下)
- 校验,每个 Sku 的属性值的数量,是一致的
- 校验,每个 Sku 之间不是重复的
- 初始化 SPU 中 SKU 相关属性
pricemarket_pricecost_pricestock等的设置
- 插入spu
- 插入sku
-
商品修改
- 校验分类、品牌
- 校验 SKU
- 单规格,赋予单规格默认属性
- 校验属性项存在(缺属性值存在校验)
- 校验,一个 SKU 下,没有重复的属性。(无重复属性,应该也就不会有重复属性值,属性值挂在属性下)
- 校验,每个 Sku 的属性值的数量,是一致的
- 校验,每个 Sku 之间不是重复的
- 初始化 SPU 中 SKU 相关属性
pricemarket_pricecost_pricestock等的设置
- 更新spu
- 更新sku
- sku拆分三个集合,新插入的、需要更新的、需要删除的

- sku表无status字段,不能单独对某个sku进行上下架
-
商品评论数据库模型

- 评论不能盖楼,只有用户评论和商家回复
-
功能:
- 创建虚拟评论
- 商家回复评论(可反复修改)
- 可显示或隐藏评论
-
mapstruct对象映射(对象转换)的示例
这段代码是使用 MapStruct 库进行对象映射(对象转换)的示例。MapStruct 是一个在 Java 中用于简化对象映射的注解处理器,它能够根据你定义的映射关系自动生成映射代码。
让我们逐一解释这个例子:
-
自定义转换方法
convertScores:@Named("convertScores") default Integer convertScores(Integer descriptionScores, Integer benefitScores) { // 计算评价最终综合评分 最终星数 = (商品评星 + 服务评星) / 2 BigDecimal sumScore = new BigDecimal(descriptionScores + benefitScores); BigDecimal divide = sumScore.divide(BigDecimal.valueOf(2L), 0, RoundingMode.DOWN); return divide.intValue(); }
- 这是一个默认方法,用于计算评分的综合值,将商品评星和服务评星的平均值转换为整数。
- 通过
@Named("convertScores")注解,该方法可以在后面的映射中以命名的方式调用。
-
MapStruct 的映射配置:
@Mapping(target = "visible", constant = "true") @Mapping(target = "replyStatus", constant = "false") @Mapping(target = "userId", constant = "0L") @Mapping(target = "orderId", constant = "0L") @Mapping(target = "orderItemId", constant = "0L") @Mapping(target = "anonymous", expression = "java(Boolean.FALSE)") @Mapping(target = "scores", expression = "java(convertScores(createReq.getDescriptionScores(), createReq.getBenefitScores()))") ProductCommentDO convert(ProductCommentCreateReqVO createReq);
- 这是一个用于将
ProductCommentCreateReqVO转换为ProductCommentDO的映射方法。 - 使用
@Mapping注解来定义映射关系。例如,@Mapping(target = "visible", constant = "true")表示将visible属性映射为常量值 "true"。 expression属性用于执行复杂的表达式,例如调用convertScores方法来计算评分。@Named("convertScores")用于指定使用convertScores方法进行评分的转换。
- 这是一个用于将
-
调用映射方法:
ProductCommentDO convert(ProductCommentCreateReqVO createReq);
- 这是一个接口的抽象方法,MapStruct 会自动生成其实现。该方法的作用是将
ProductCommentCreateReqVO类型的对象转换为ProductCommentDO类型的对象,根据上述配置实现了属性的映射。
- 这是一个接口的抽象方法,MapStruct 会自动生成其实现。该方法的作用是将
总体来说,MapStruct 通过简单的注解配置,自动生成了对象之间的映射代码,避免了手动编写繁琐的映射逻辑。这样可以提高代码的可维护性和可读性。
-

-
收藏记录数据库模型
- 商品收藏是spu维度

-
交易配置数据库模型
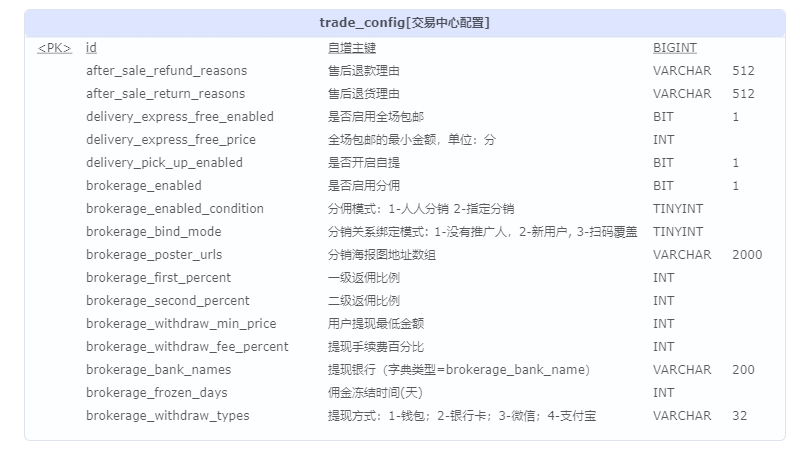

-
快递公司数据库模型
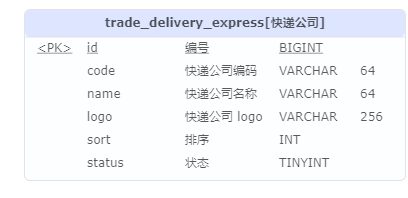

-
运费模版数据库模型
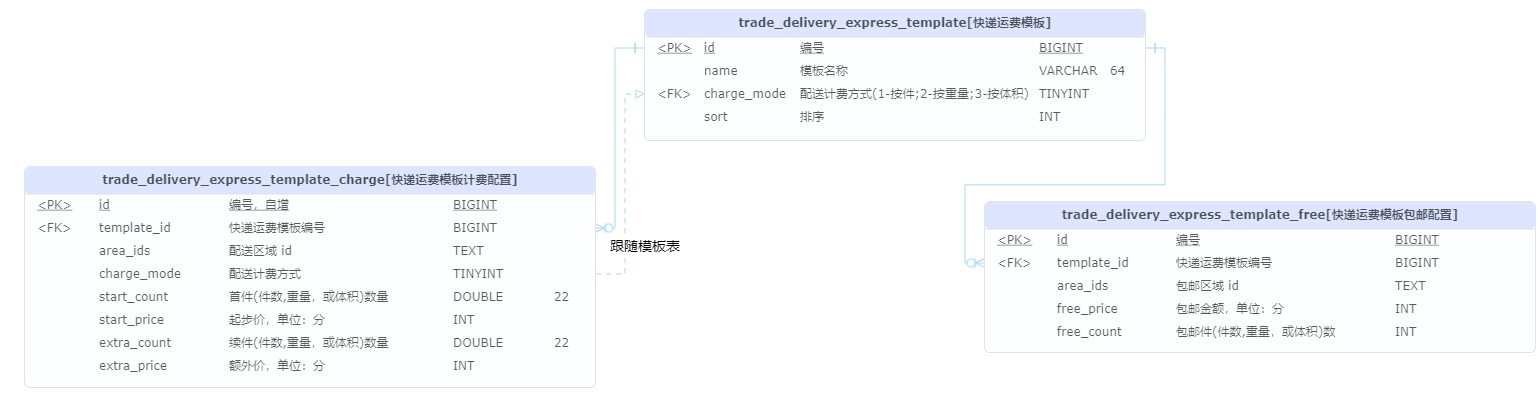
-
代码片段(对比老、新两个列表,找出新增、修改、删除的数据)
/** * 对比老、新两个列表,找出新增、修改、删除的数据 * * @param oldList 老列表 * @param newList 新列表 * @param sameFunc 对比函数,返回 true 表示相同,返回 false 表示不同 * 注意,same 是通过每个元素的“标识”,判断它们是不是同一个数据 * @return [新增列表、修改列表、删除列表] */ public static <T> List<List<T>> diffList(Collection<T> oldList, Collection<T> newList, BiFunction<T, T, Boolean> sameFunc) { List<T> createList = new LinkedList<>(newList); // 默认都认为是新增的,后续会进行移除 List<T> updateList = new ArrayList<>(); List<T> deleteList = new ArrayList<>(); // 通过以 oldList 为主遍历,找出 updateList 和 deleteList for (T oldObj : oldList) { // 1. 寻找是否有匹配的 T foundObj = null; for (Iterator<T> iterator = createList.iterator(); iterator.hasNext(); ) { T newObj = iterator.next(); // 1.1 不匹配,则直接跳过 if (!sameFunc.apply(oldObj, newObj)) { continue; } // 1.2 匹配,则移除,并结束寻找 iterator.remove(); foundObj = newObj; break; } // 2. 匹配添加到 updateList;不匹配则添加到 deleteList 中 if (foundObj != null) { updateList.add(foundObj); } else { deleteList.add(oldObj); } } return asList(createList, updateList, deleteList); }
-
问题

- 没在模板所勾选的区域怎么办
- 免邮和计运费的存在区域重叠冲突的怎么算
- 计运费的区域之间存在重叠冲突的怎么算
-
自提门店数据库模型

-
使用腾讯地图实现门店地址搜索和经纬度的录入

-
订单数据库模型
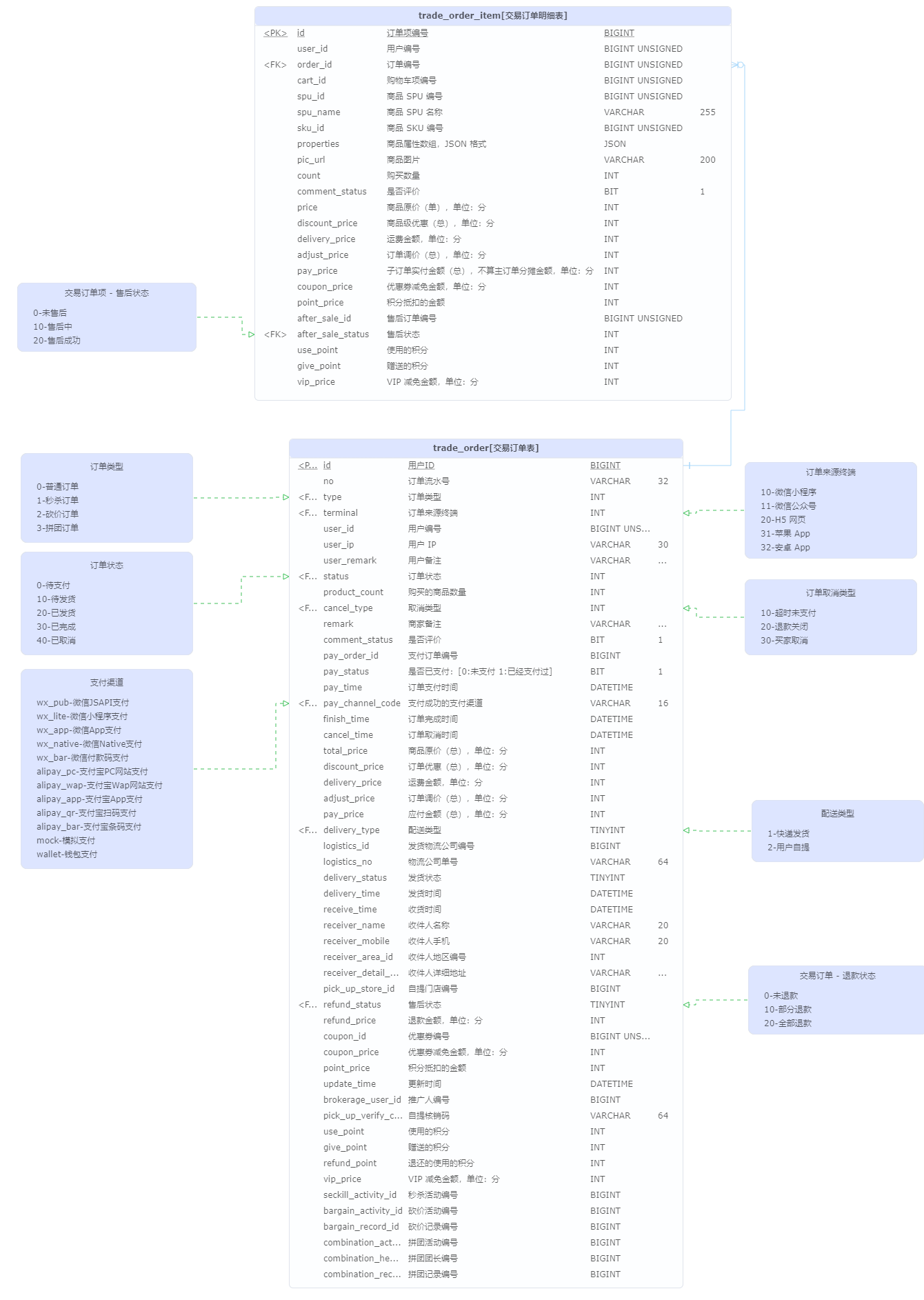

-
售后退款-列表数据库模型
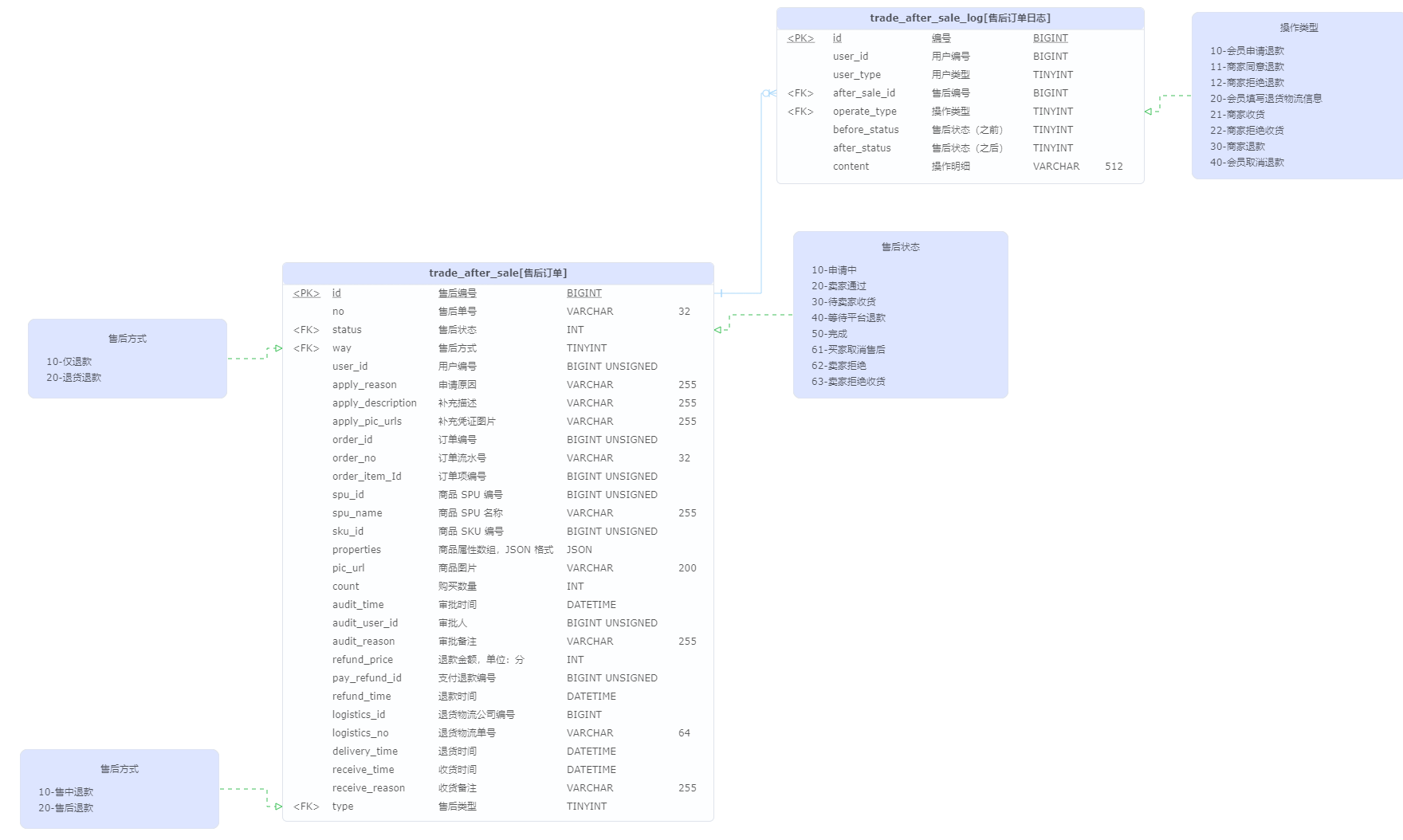

-
售后退款数据库模型