Automatische Erkennung und Konvertierung von Tabellen in Bilddokumenten mit Hilfe von Machine Learning
- refactor this repo
- refactor frontend with Angular
- deploy on Amazon Web Server
-> https://github.com/huichen5796/website_for_tabelextrakt
For detailed implementation process, please see the presentation and studienarbeit.
Die ist ein Tool zur...
- Erkennung
- Extraktion
- Rekonstruktion
... von komplexen Tabellen aus Bilddokumenten.

Es basiert auf:
- Python
- Opencv und Pillow
- Tesseract
- Pytorch
- Elasticsearch
Es wurde für Windows entwickelt, lässt sich aber auch auf anderen Betriebssystemen zum Laufen bringen. Das Tool besteht aus zwei wesentlichen Teilen:
-
Training von neuronalen Netzen mittels Torch. Dieses Training wird idealerweise auf einer rechenstarken Maschine ausgeführt (z.B. Google Collab mit GPUs).
-
Erkennung von Tabellen in Bild- oder PDF-Dokumenten auf Basis des zuvor trainierten neuronalen Netzes.
Um beide Programmbausteine lauffähig zu machen, müssen folgende Schritte ausgreführt werden:
- Installation von Python
- Installation von Python-Paketen
- Installation von Elasticsearch
- Installation von Tesseract
-
Letzte Version von Python hier herunterladen und installieren.
-
Geforderte Pakete installieren:
pip install -r requirements.txt
- Elasticsearch kann nach folgender Anleitung installiert werden: Installation Elasticsearch
- Elasticsearch hier herunterladen (bitte Version 7.17.1 verwenden, andernfalls müssen das Package elasticsearch 7.17.1 deinstalliert werden und entsprechende Package mit entsprechenen Version heruntergeladen werden).
- Archiv entpacken (z.B. nach
D:\elasticsearch\) - Navigation in den Ordner
elasticsearch\bin elasticsearch.batausführen, um die Installation zu starten.localhost:9200im Browser eingeben, um erfolgreiche Installation zu testen. → Folgender Text sollte im Browser lesbar sein: "You know you search."
Hinweis: Die Version des pip-Packages für Elasticsearch muss zur installierten Version auf dem System passen!
- Anleitung zur Installation: Installing and using Tesseract 4 on windows 10
- Installationsdateien hier runterladen (getestete Version:
tesseract-ocr-w64-setup-v5.1.0.20220510.exe) und ausführen. - "Additional script data (doiwnload)" und "Additional language data (download)" auswählen.

- Installationspfad wählen.
- Pfad von
tesseract.exezu der Codezeile 22 von functions.py hinzufügen.pytesseract.pytesseract.tesseract_cmd = '/*Installationspfad*/'
Der Ablauf des Programmes kann anhand den Folgenden nachvollzogen werden:
- Die Verarbeitung einzeles Bilds

- Stapelverarbeitung mehrer Bilder

-
Die Verarbeitung einzeles Bilds
- Vorbreitung und Normalizierung

- Erkennung des Tablebreichs
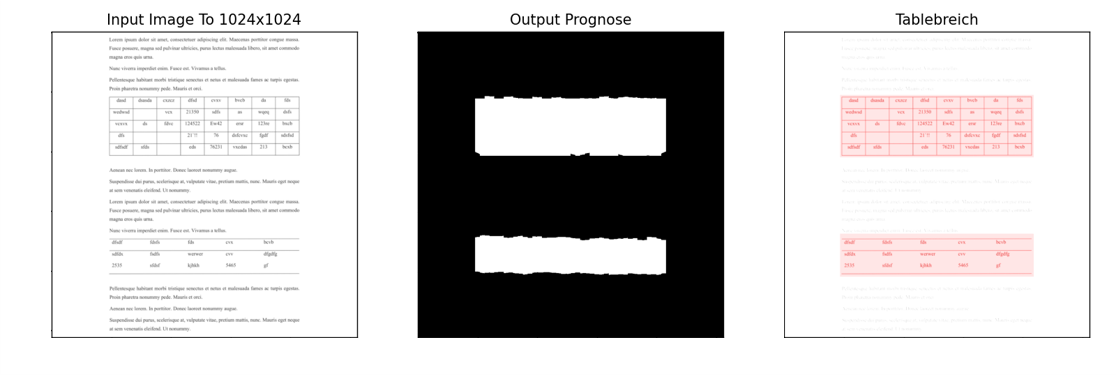
- Erkennung der Zelle
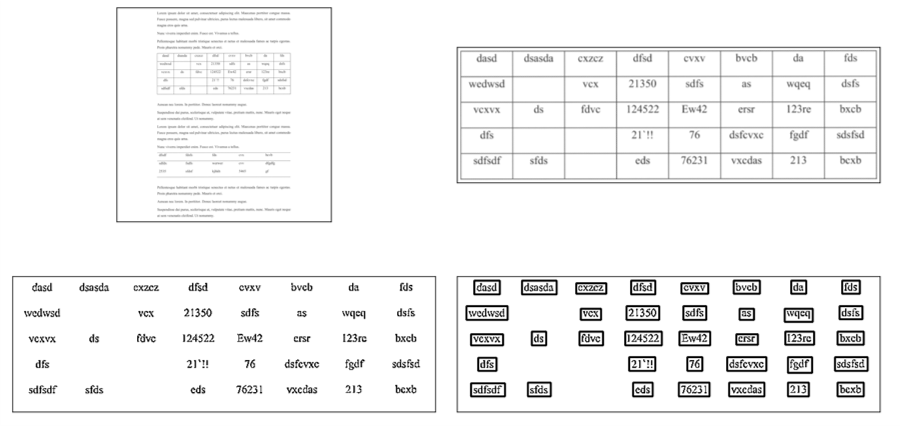
-
Rekonstruktion
- Columen Detection mittels ML Modell, somit werden Labels von Columen erstellt.

(Die rote Linie ist die Mittellinie der durch maschinelles Lernen erkannten Tabellenspalte, und die Zellen, die sich auf beiden Seiten der roten Linie innerhalb der grünen Linien befinden, werden in einer Spalte gruppiert.)
-
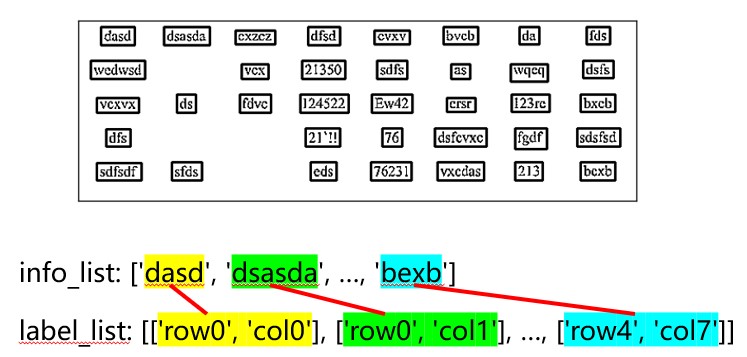
Zuweisung der Labels
Labels werden anhand Positon von jeder Zelle erstellt.
-
Rekonstruktion
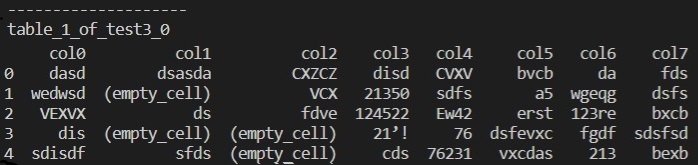
-
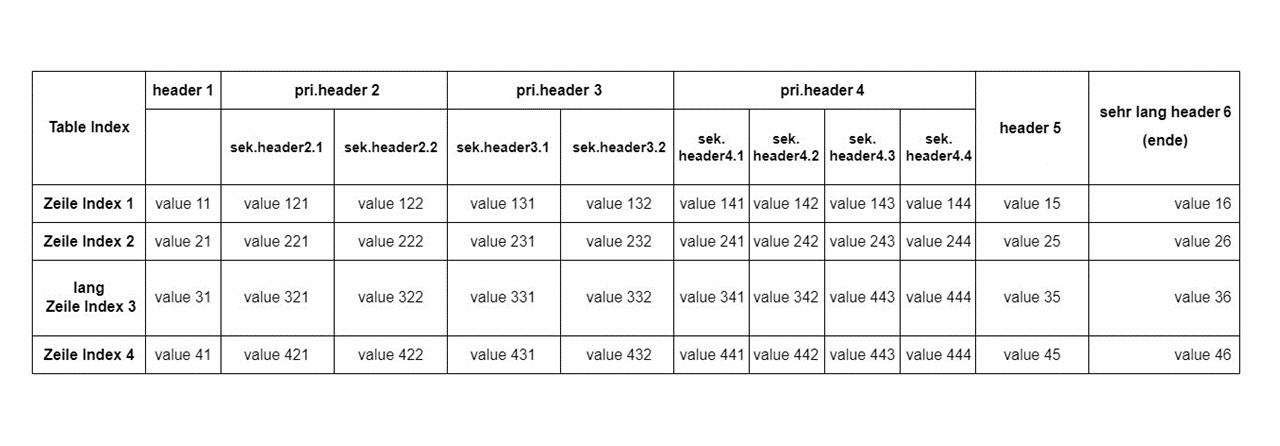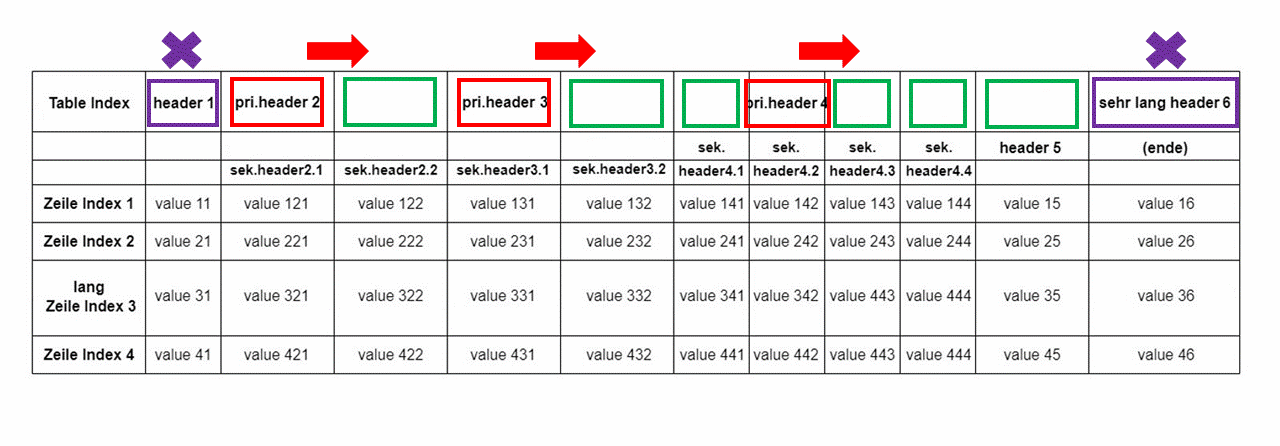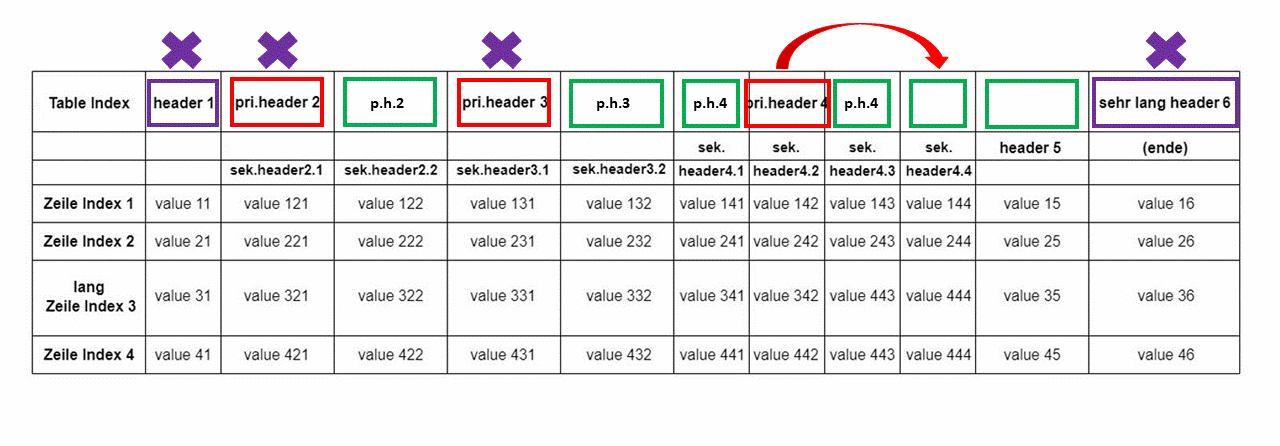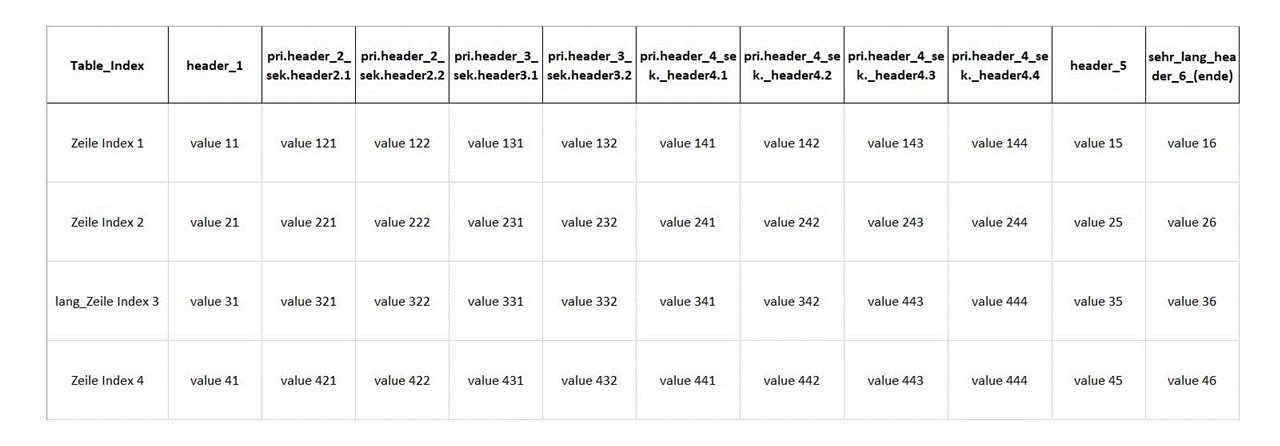
Strukturnormalize
- vertikales Schmelzen von zwei geschmelzbaren Zeilen
- horizonales Schmelzen von der ersten und zweiten Spalte
- Bestimmen der Zeilennummer von header
- Bestimmen der Qualifikationen der Zellen in erster Zeile, dilatiert zu werden und ausgefüllt zu werden
- Verarbeitung der erster Zeile
- Schmelzen von header
-
Stapelverarbeitung mehrer Bilder
- Die Bilder im Verzeichnis werden zuerst formatiert, alle PDFs werden Seite für Seite in das PNG-Dateiformat konvertiert.
- Dann wird jedes Bild verarbeitet und in Elasticsearch geschrieben.

-
Leistung bei komplexer Tabelle











nach Strukturnormalize:
