Based on OpenCSV(3.6) on http://opencsv.sourceforge.net, please visit the address for its original usage. Requires JRE 1.7+.
- Performance and memory optimization by NIO, buffering and the reduction of object creations
- Convert ResultSet to CSV file, refer to CSVWriter.writeAll(<Resuleset>,...)
- Convert ResultSet to SQL file, refer to SQLWriter.writeAll2SQL(<Resuleset>,...)
- Convert CSV file to SQL file, refer to SQLWriter.writeAll2SQL(<CSVFilePath>,...)
- Convert ResultSet/CSV to Oracle SQL*Loader Files(Automatically)
- Support automatically compression if destination file extension is ".zip" or ".gz"
- Support Multi-threads processing to speed up performance, refer to CSVWriter.setAsyncMode(boolean)
//Extract ResultSet to CSV file, auto-compress if the fileName extension is ".zip" or ".gz"
//Returns number of records extracted
public int ResultSet2CSV(final ResultSet rs, final String fileName, final String header, final boolean aync) throws Exception {
try (CSVWriter writer = new CSVWriter(fileName)) {
//Define fetch size(default as 30000 rows), higher to be faster performance but takes more memory
ResultSetHelperService.RESULT_FETCH_SIZE=10000;
//Define MAX extract rows, -1 means unlimited.
ResultSetHelperService.MAX_FETCH_ROWS=20000;
writer.setAsyncMode(aync);
int result = writer.writeAll(rs, true);
return result - 1;
}
}
//Extract ResultSet to SQL file, returns number of records extracted
//Parameter "header" defines the extract information to be appended into the file, can be ""
//Parameter "rs" can be null, which helps the engine identifying the column list and data types
public int ResultSet2SQL(final ResultSet rs, final String fileName, final String header, final boolean aync) throws Exception {
try (SQLWriter writer = new SQLWriter(fileName)) {
//Define the max line width(default as 1500), which determines if split the SQL stmt as cross-lines
SQLWriter.maxLineWidth=32767;
writer.setAsyncMode(aync);
writer.setFileHead(header);
int count = writer.writeAll2SQL(rs, "", 1500);
return count;
}
}
//Convert CSV file to SQL file, returns number of records extracted
public int CSV2SQL(final ResultSet rs, final String SQLFileName, final String CSVfileName, final String header) throws Exception {
try (SQLWriter writer = new SQLWriter(SQLFileName)) {
writer.setFileHead(header);
return writer.writeAll2SQL(CSVfileName, rs);
}
}
//Fetch ResultSet into string array, be noted that the cell value can be null
//Parameter "rows" means the number of records to be extracted, -1 means unlimited
public Object[][] fetchResult(final ResultSet rs, final int rows) throws Exception {
if (rs.getStatement().isClosed() || rs.isClosed()) throw new IOException("Statement is aborted.");
ArrayList<Object[]> ary = (ArrayList) new ResultSetHelperService(rs).fetchRows(rows);
return ary.toArray(new Object[][]{});
}
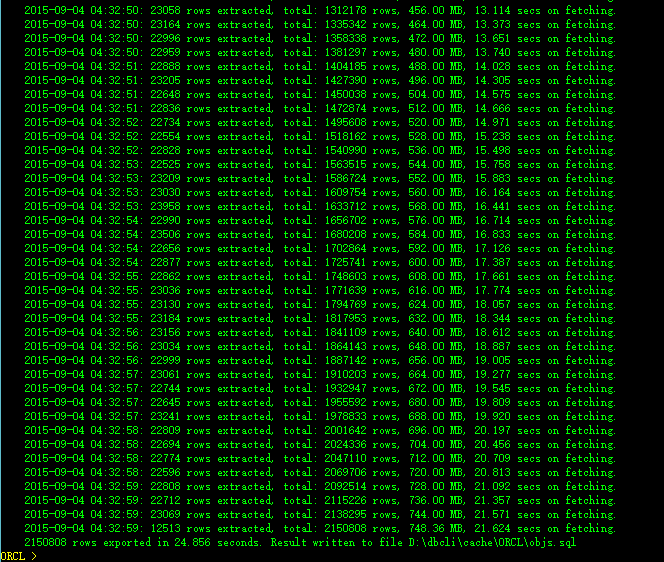
In async mode, the program spends very few time on converting fields and writing file.
Almost all the time is used on fetching data, so the performance highly depends on network speed.
And as a test result on Oracle database in guest virtual machine, to generate 2.15 million records into a file with 750 MB size, only takes extra 3 seconds on writing, total time cost is 25 seconds.