RootNet of "Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image"


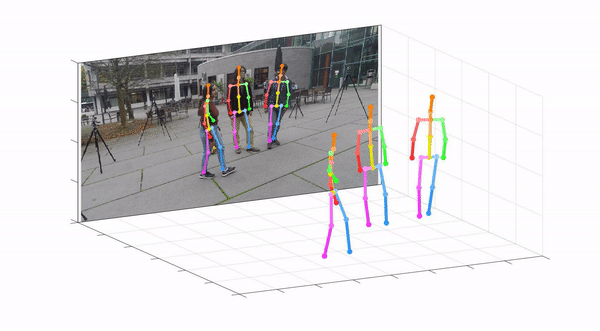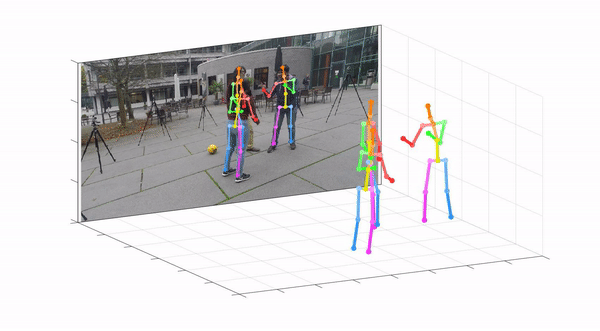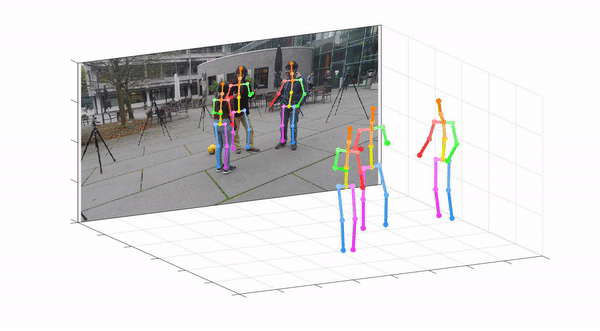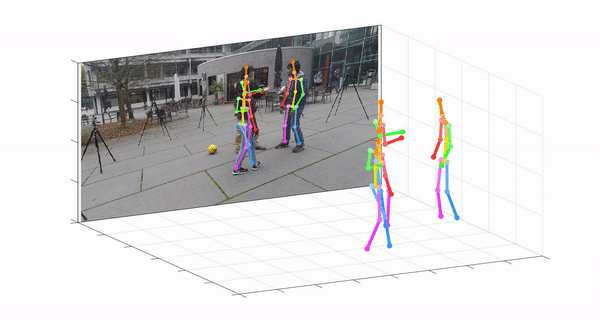
This repo is official PyTorch implementation of Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image (ICCV 2019). It contains RootNet part.
What this repo provides:
- PyTorch implementation of Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image (ICCV 2019).
- Flexible and simple code.
- Compatibility for most of the publicly available 2D and 3D, single and multi-person pose estimation datasets including Human3.6M, MPII, MS COCO 2017, MuCo-3DHP and MuPoTS-3D.
- Human pose estimation visualization code.
This code is tested under Ubuntu 16.04, CUDA 9.0, cuDNN 7.1 environment with two NVIDIA 1080Ti GPUs.
Python 3.6.5 version with Anaconda 3 is used for development.
The ${POSE_ROOT} is described as below.
${POSE_ROOT}
|-- data
|-- common
|-- main
`-- output
datacontains data loading codes and soft links to images and annotations directories.commoncontains kernel codes for 3d multi-person pose estimation system.maincontains high-level codes for training or testing the network.outputcontains log, trained models, visualized outputs, and test result.
You need to follow directory structure of the data as below.
${POSE_ROOT}
|-- data
|-- |-- Human36M
| `-- |-- bbox
| | |-- bbox_human36m_output.json
| |-- images
| `-- annotations
|-- |-- MPII
| `-- |-- images
| `-- annotations
|-- |-- MSCOCO
| `-- |-- images
| | |-- train/
| | |-- val/
| `-- annotations
|-- |-- MuCo
| `-- |-- data
| | |-- augmented_set
| | |-- unaugmented_set
| | `-- MuCo-3DHP.json
`-- |-- MuPoTS
| `-- |-- bbox
| | |-- bbox_mupots_output.json
| |-- data
| | |-- MultiPersonTestSet
| | `-- MuPoTS-3D.json
- Download Human3.6M parsed data [images][annotations]
- Download MPII parsed data [images][annotations]
- Download MuCo parsed and composited data [images_1][images_2][annotations]
- Download MuPoTS parsed parsed data [images][annotations]
- All annotation files follow MS COCO format.
- If you want to add your own dataset, you have to convert it to MS COCO format.
You need to follow the directory structure of the output folder as below.
${POSE_ROOT}
|-- output
|-- |-- log
|-- |-- model_dump
|-- |-- result
`-- |-- vis
- Creating
outputfolder as soft link form is recommended instead of folder form because it would take large storage capacity. logfolder contains training log file.model_dumpfolder contains saved checkpoints for each epoch.resultfolder contains final estimation files generated in the testing stage.visfolder contains visualized results.
- In the
main/config.py, you can change settings of the model including dataset to use, network backbone, and input size and so on.
In the main folder, run
python train.py --gpu 0-1to train the network on the GPU 0,1.
If you want to continue experiment, run
python train.py --gpu 0-1 --continue--gpu 0,1 can be used instead of --gpu 0-1.
Place trained model at the output/model_dump/.
In the main folder, run
python test.py --gpu 0-1 --test_epoch 20to test the network on the GPU 0,1 with 20th epoch trained model. --gpu 0,1 can be used instead of --gpu 0-1.
Here I report the performance of the RootNet. Also, I provide bounding box estimations and trained models of the RootNet.
For the evaluation, you can run test.py or there are evaluation codes in Human36M and MuPoTS.
| Method | MRPE | MRPE_x | MRPE_y | MRPE_z |
|---|---|---|---|---|
| RootNet | 120.0 | 23.3 | 23.0 | 108.1 |
- Bounding box [H36M_protocol1][H36M_protocol2]
- Bounding box + 3D Human root coordinatees in camera space [H36M_protocol1][H36M_protocol2]
- RootNet model trained on H36M protocol 1 + MPII [model]
- RootNet model trained on H36M protocol 2 + MPII [model]
| Method | AP_25 |
|---|---|
| RootNet | 31.0 |
- Bounding box [MuPoTS-3D]
- Bounding box + 3D Human root coordinatees in camera space [MuPoTS-3D]
- RootNet model trained on MuCo-3DHP + MSCOCO [model]
We additionally provide estimated 3D human root coordinates in on the MSCOCO dataset. The coordinates are in 3D camera coordinate system, and focal lengths are set to 1500mm for both x and y axis. You can change focal length and corresponding distance using equation 2 or equation in supplementarial material of my paper
- Bounding box + 3D Human root coordinates in camera space [MSCOCO]
@InProceedings{Moon_2019_ICCV_3DMPPE,
author = {Moon, Gyeongsik and Chang, Juyong and Lee, Kyoung Mu},
title = {Camera Distance-aware Top-down Approach for 3D Multi-person Pose Estimation from a Single RGB Image},
booktitle = {The IEEE Conference on International Conference on Computer Vision (ICCV)},
year = {2019}
}