简体中文🀄 | English🌎







PaddleNLP是一款简单易用且功能强大的自然语言处理和大语言模型(LLM)开发库。聚合业界优质预训练模型并提供开箱即用的开发体验,覆盖NLP多场景的模型库搭配产业实践范例可满足开发者灵活定制的需求。
-
2024.01.04 PaddleNLP v2.7: 大模型体验全面升级,统一工具链大模型入口。统一预训练、精调、压缩、推理以及部署等环节的实现代码,到
PaddleNLP/llm目录。全新大模型工具链文档,一站式指引用户从大模型入门到业务部署上线。全断点存储机制 Unified Checkpoint,大大提高大模型存储的通用性。高效微调升级,支持了高效微调+LoRA同时使用,支持了QLoRA等算法。 -
2023.08.15 PaddleNLP v2.6: 发布全流程大模型工具链,涵盖预训练,精调,压缩,推理以及部署等各个环节,为用户提供端到端的大模型方案和一站式的开发体验;内置4D并行分布式Trainer,高效微调算法LoRA/Prefix Tuning, 自研INT8/INT4量化算法等等;全面支持LLaMA 1/2, BLOOM, ChatGLM 1/2, GLM, OPT等主流大模型
- python >= 3.7
- paddlepaddle >= 2.6.0
- 如需大模型功能,请使用 paddlepaddle-gpu >= 2.6.0
pip install --upgrade paddlenlp或者可通过以下命令安装最新 develop 分支代码:
pip install --pre --upgrade paddlenlp -f https://www.paddlepaddle.org.cn/whl/paddlenlp.html更多关于PaddlePaddle和PaddleNLP安装的详细教程请查看Installation。
PaddleNLP提供了方便易用的Auto API,能够快速的加载模型和Tokenizer。这里以使用 linly-ai/chinese-llama-2-7b 大模型做文本生成为例:
>>> from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("linly-ai/chinese-llama-2-7b")
>>> model = AutoModelForCausalLM.from_pretrained("linly-ai/chinese-llama-2-7b", dtype="float16")
>>> input_features = tokenizer("你好!请自我介绍一下。", return_tensors="pd")
>>> outputs = model.generate(**input_features, max_length=128)
>>> tokenizer.batch_decode(outputs[0])
['\n你好!我是一个AI语言模型,可以回答你的问题和提供帮助。']PaddleNLP提供一键预测功能,无需训练,直接输入数据即可开放域抽取结果。这里以信息抽取-命名实体识别任务,UIE模型为例:
>>> from pprint import pprint
>>> from paddlenlp import Taskflow
>>> schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
>>> ie = Taskflow('information_extraction', schema=schema)
>>> pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中**选手谷爱凌以188.25分获得金牌!"))
[{'时间': [{'end': 6,
'probability': 0.9857378532924486,
'start': 0,
'text': '2月8日上午'}],
'赛事名称': [{'end': 23,
'probability': 0.8503089953268272,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,
'probability': 0.8981548639781138,
'start': 28,
'text': '谷爱凌'}]}]更多PaddleNLP内容可参考:
- 大模型全流程工具链,包含主流中文大模型的全流程方案。
- 精选模型库,包含优质预训练模型的端到端全流程使用。
- 多场景示例,了解如何使用PaddleNLP解决NLP多种技术问题,包含基础技术、系统应用与拓展应用。
- 交互式教程,在🆓免费算力平台AI Studio上快速学习PaddleNLP。
Taskflow提供丰富的📦开箱即用的产业级NLP预置模型,覆盖自然语言理解与生成两大场景,提供💪产业级的效果与⚡️极致的推理性能。
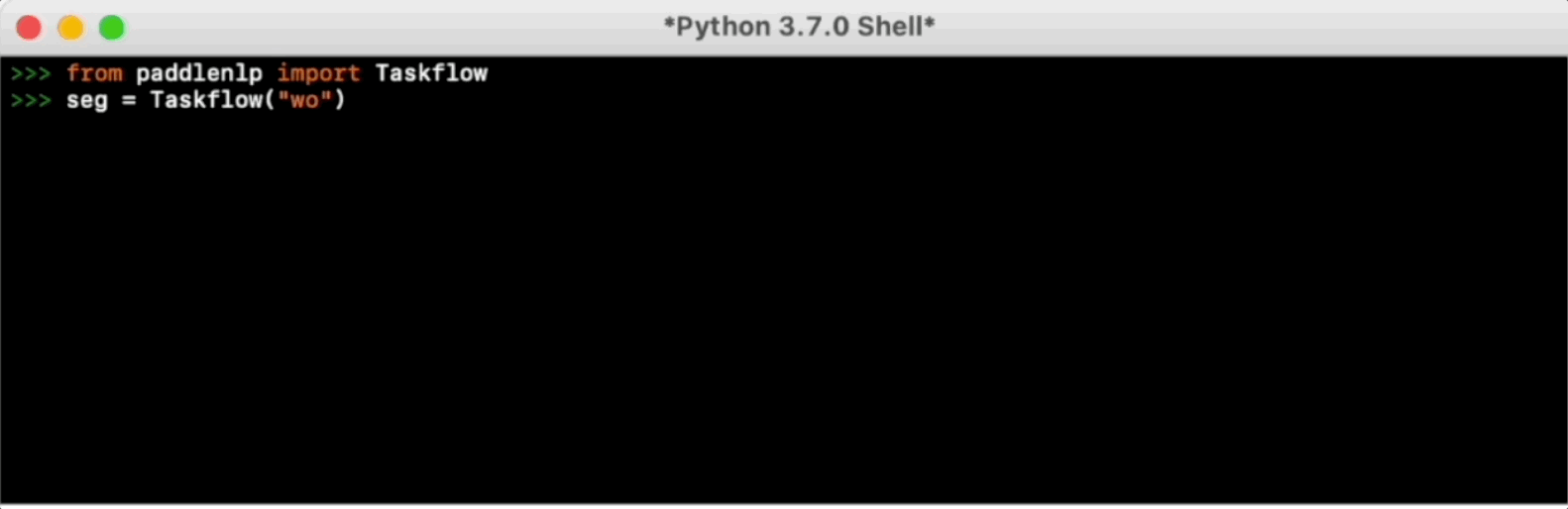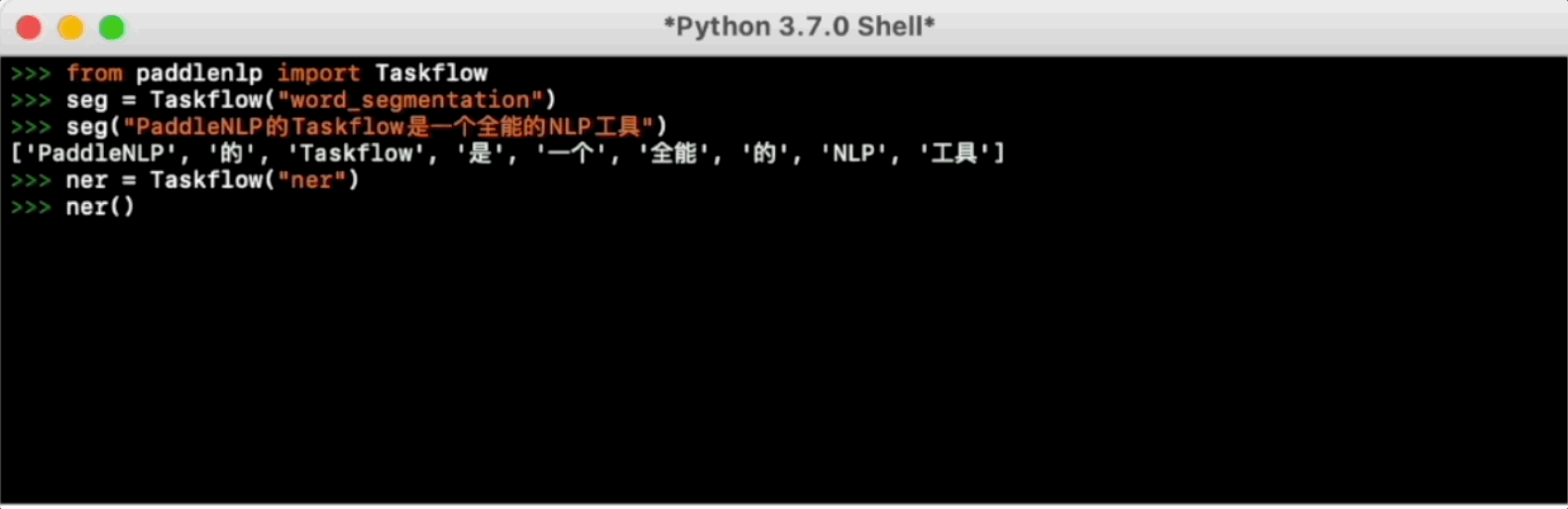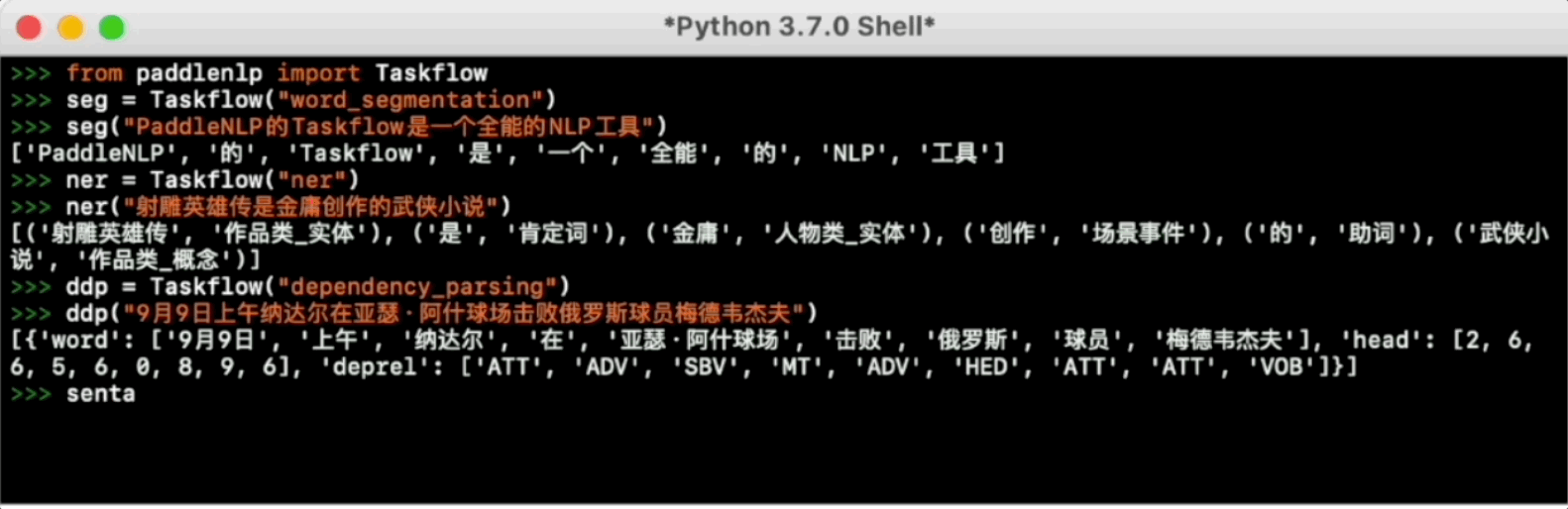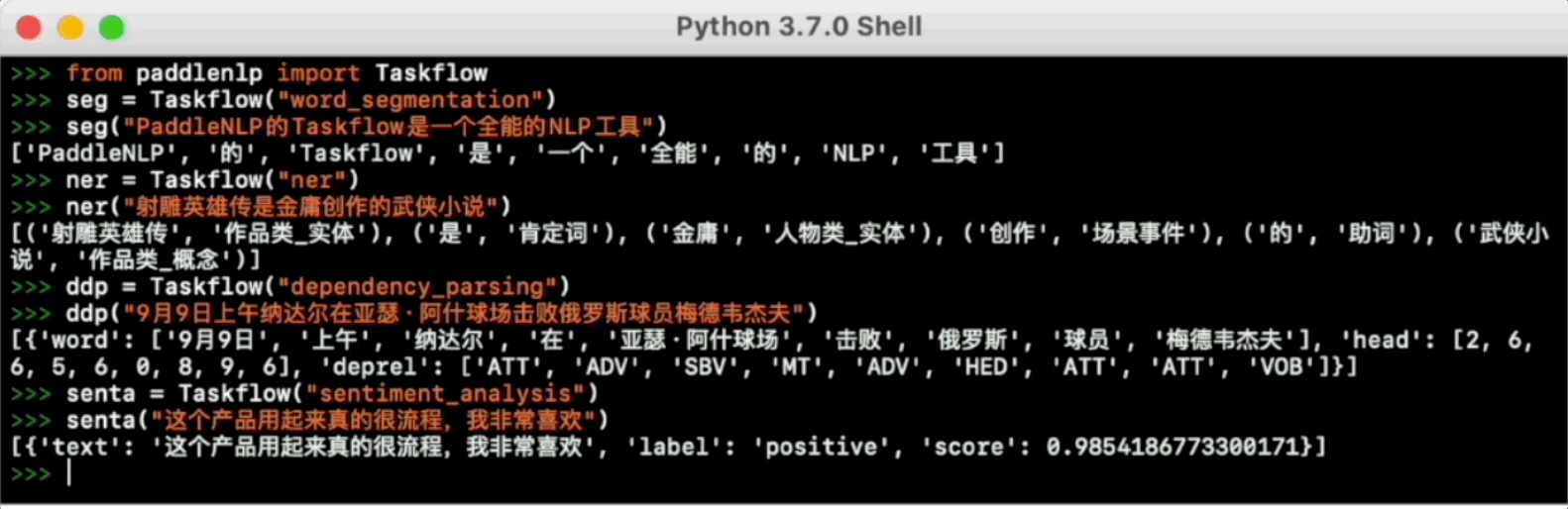
更多使用方法可参考Taskflow文档。
精选 45+ 个网络结构和 500+ 个预训练模型参数,涵盖业界最全的中文预训练模型:既包括文心NLP大模型的ERNIE、PLATO等,也覆盖BERT、GPT、RoBERTa、T5等主流结构。通过AutoModel API一键⚡高速下载⚡。
from paddlenlp.transformers import *
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
bert = AutoModel.from_pretrained('bert-wwm-chinese')
albert = AutoModel.from_pretrained('albert-chinese-tiny')
roberta = AutoModel.from_pretrained('roberta-wwm-ext')
electra = AutoModel.from_pretrained('chinese-electra-small')
gpt = AutoModelForPretraining.from_pretrained('gpt-cpm-large-cn')针对预训练模型计算瓶颈,可以使用API一键使用文心ERNIE-Tiny全系列轻量化模型,降低预训练模型部署难度。
# 6L768H
ernie = AutoModel.from_pretrained('ernie-3.0-medium-zh')
# 6L384H
ernie = AutoModel.from_pretrained('ernie-3.0-mini-zh')
# 4L384H
ernie = AutoModel.from_pretrained('ernie-3.0-micro-zh')
# 4L312H
ernie = AutoModel.from_pretrained('ernie-3.0-nano-zh')对预训练模型应用范式如语义表示、文本分类、句对匹配、序列标注、问答等,提供统一的API体验。
import paddle
from paddlenlp.transformers import *
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
text = tokenizer('自然语言处理')
# 语义表示
model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
sequence_output, pooled_output = model(input_ids=paddle.to_tensor([text['input_ids']]))
# 文本分类 & 句对匹配
model = AutoModelForSequenceClassification.from_pretrained('ernie-3.0-medium-zh')
# 序列标注
model = AutoModelForTokenClassification.from_pretrained('ernie-3.0-medium-zh')
# 问答
model = AutoModelForQuestionAnswering.from_pretrained('ernie-3.0-medium-zh')覆盖从学术到产业的NLP应用示例,涵盖NLP基础技术、NLP系统应用以及拓展应用。全面基于飞桨核心框架2.0全新API体系开发,为开发者提供飞桨文本领域的最佳实践。
精选预训练模型示例可参考Model Zoo,更多场景示例文档可参考examples目录。更有免费算力支持的AI Studio平台的Notbook交互式教程提供实践。
PaddleNLP预训练模型适用任务汇总(点击展开详情)
| Model | Sequence Classification | Token Classification | Question Answering | Text Generation | Multiple Choice |
|---|---|---|---|---|---|
| ALBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BART | ✅ | ✅ | ✅ | ✅ | ❌ |
| BERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| BigBird | ✅ | ✅ | ✅ | ❌ | ✅ |
| BlenderBot | ❌ | ❌ | ❌ | ✅ | ❌ |
| ChineseBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ConvBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| CTRL | ✅ | ❌ | ❌ | ❌ | ❌ |
| DistilBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| ELECTRA | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE | ✅ | ✅ | ✅ | ❌ | ✅ |
| ERNIE-CTM | ❌ | ✅ | ❌ | ❌ | ❌ |
| ERNIE-Doc | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-GEN | ❌ | ❌ | ❌ | ✅ | ❌ |
| ERNIE-Gram | ✅ | ✅ | ✅ | ❌ | ❌ |
| ERNIE-M | ✅ | ✅ | ✅ | ❌ | ❌ |
| FNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| Funnel-Transformer | ✅ | ✅ | ✅ | ❌ | ❌ |
| GPT | ✅ | ✅ | ❌ | ✅ | ❌ |
| LayoutLM | ✅ | ✅ | ❌ | ❌ | ❌ |
| LayoutLMv2 | ❌ | ✅ | ❌ | ❌ | ❌ |
| LayoutXLM | ❌ | ✅ | ❌ | ❌ | ❌ |
| LUKE | ❌ | ✅ | ✅ | ❌ | ❌ |
| mBART | ✅ | ❌ | ✅ | ❌ | ✅ |
| MegatronBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| MobileBERT | ✅ | ❌ | ✅ | ❌ | ❌ |
| MPNet | ✅ | ✅ | ✅ | ❌ | ✅ |
| NEZHA | ✅ | ✅ | ✅ | ❌ | ✅ |
| PP-MiniLM | ✅ | ❌ | ❌ | ❌ | ❌ |
| ProphetNet | ❌ | ❌ | ❌ | ✅ | ❌ |
| Reformer | ✅ | ❌ | ✅ | ❌ | ❌ |
| RemBERT | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoBERTa | ✅ | ✅ | ✅ | ❌ | ✅ |
| RoFormer | ✅ | ✅ | ✅ | ❌ | ❌ |
| SKEP | ✅ | ✅ | ❌ | ❌ | ❌ |
| SqueezeBERT | ✅ | ✅ | ✅ | ❌ | ❌ |
| T5 | ❌ | ❌ | ❌ | ✅ | ❌ |
| TinyBERT | ✅ | ❌ | ❌ | ❌ | ❌ |
| UnifiedTransformer | ❌ | ❌ | ❌ | ✅ | ❌ |
| XLNet | ✅ | ✅ | ✅ | ❌ | ✅ |
可参考Transformer 文档 查看目前支持的预训练模型结构、参数和详细用法。
PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高频NLP场景,提供了端到端系统范例,打通数据标注-模型训练-模型调优-预测部署全流程,持续降低NLP技术产业落地门槛。更多详细的系统级产业范例使用说明请参考Applications。
针对无监督数据、有监督数据等多种数据情况,结合SimCSE、In-batch Negatives、ERNIE-Gram单塔模型等,推出前沿的语义检索方案,包含召回、排序环节,打通训练、调优、高效向量检索引擎建库和查询全流程。
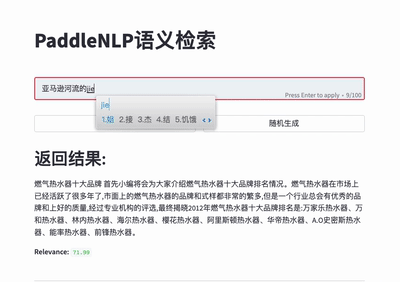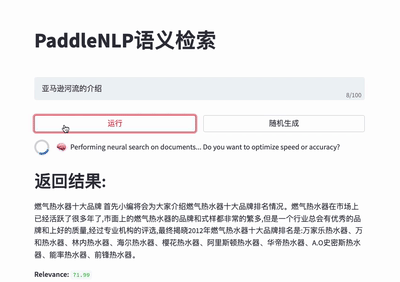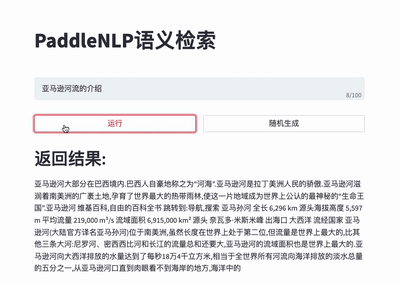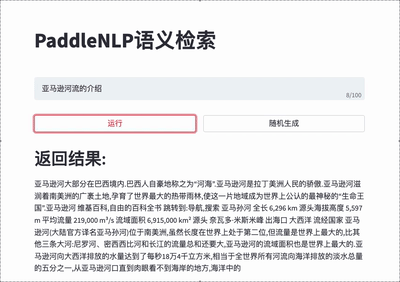
更多使用说明请参考语义检索系统。
基于🚀RocketQA技术的检索式问答系统,支持FAQ问答、说明书问答等多种业务场景。

基于情感知识增强预训练模型SKEP,针对产品评论进行评价维度和观点抽取,以及细粒度的情感分析。

更多使用说明请参考情感分析。
集成了PaddleSpeech和百度开放平台的语音识别和UIE通用信息抽取等技术,打造智能一体化的语音指令解析系统范例,该方案可应用于智能语音填单、智能语音交互、智能语音检索等场景,提高人机交互效率。

更多使用说明请参考智能语音指令解析。
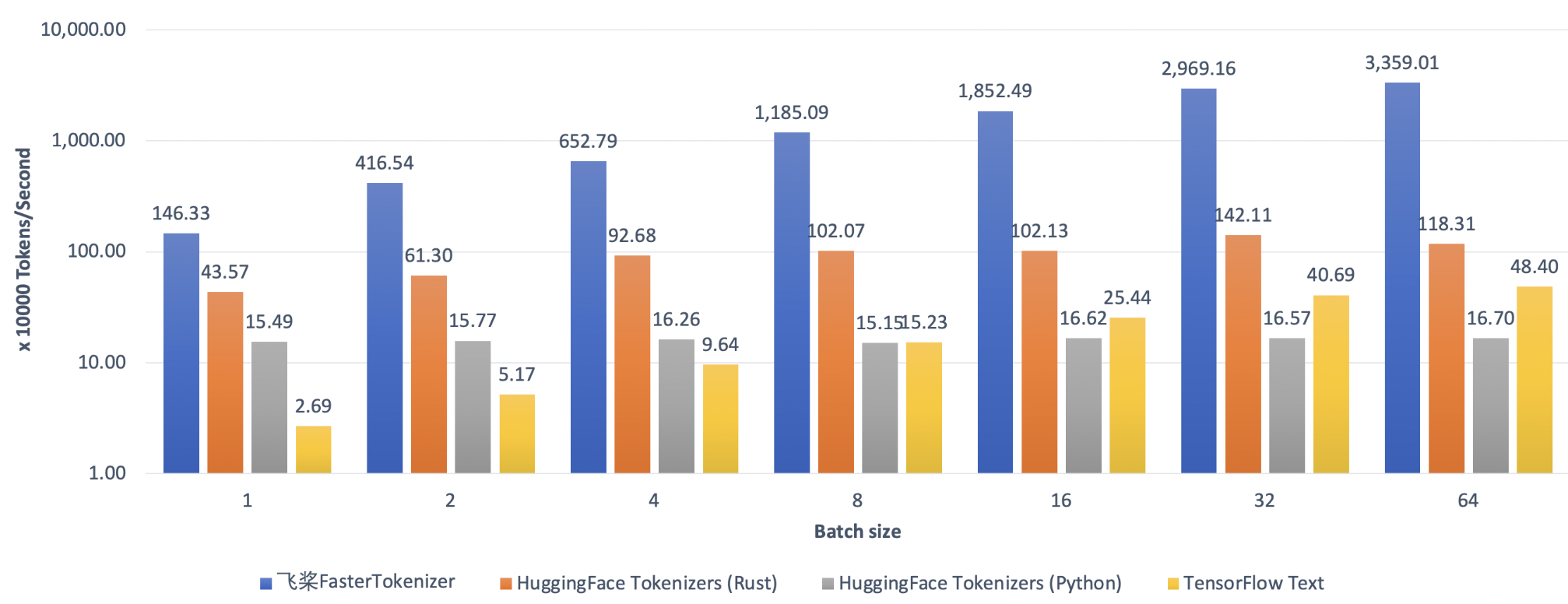
AutoTokenizer.from_pretrained("ernie-3.0-medium-zh", use_fast=True)为了实现更极致的模型部署性能,安装FastTokenizer后只需在AutoTokenizer API上打开 use_fast=True选项,即可调用C++实现的高性能分词算子,轻松获得超Python百余倍的文本处理加速,更多使用说明可参考FastTokenizer文档。

model = GPTLMHeadModel.from_pretrained('gpt-cpm-large-cn')
...
outputs, _ = model.generate(
input_ids=inputs_ids, max_length=10, decode_strategy='greedy_search',
use_fast=True)简单地在generate()API上打开use_fast=True选项,轻松在Transformer、GPT、BART、PLATO、UniLM等生成式预训练模型上获得5倍以上GPU加速,更多使用说明可参考FastGeneration文档。

更多关于千亿级AI模型的分布式训练使用说明可参考GPT-3。
-
微信扫描二维码并填写问卷,回复小助手关键词(NLP)之后,即可加入交流群领取福利
- 与众多社区开发者以及官方团队深度交流。
- 10G重磅NLP学习大礼包!

如果PaddleNLP对您的研究有帮助,欢迎引用
@misc{=paddlenlp,
title={PaddleNLP: An Easy-to-use and High Performance NLP Library},
author={PaddleNLP Contributors},
howpublished = {\url{https://github.com/PaddlePaddle/PaddleNLP}},
year={2021}
}
我们借鉴了Hugging Face的Transformers🤗关于预训练模型使用的优秀设计,在此对Hugging Face作者及其开源社区表示感谢。
PaddleNLP遵循Apache-2.0开源协议。