批量抓取微信公众号的历史文章与评论。
Inspired by vWeChatCrawl。相比之下,本工具的优点是能够抓取文章评论、断点续抓。
抓取微信公众号通常有以下几种方式:
- 使用 Sogou 的微信搜索接口。优点是非常简单,成本低;缺点是只能抓取最近的 10 篇文章,且无法抓取评论。
- 使用微信 App 的原生接口,在安卓虚拟机中安装微信 App,使用 adt 进行调试抓取。缺点是成本太高。
- 使用 Fiddler 对 Windows 微信进行抓包,然后仿造请求信息。优点是开发简单,且能够抓取评论;缺点是需要人工参与,不能实现完全自动化。
由于微信严格的防御机制,cookie 等请求参数会迅速过期,难以稳定抓取(文章评论接口的相关参数会在几十分钟内过期并更新,文章内容接口则相对稳定)。这导致任何通过破解请求接口进行抓取的方式都不能完全自动化。
本仓库采用第三种方式,具体原理如下:
- 使用 Windows 微信请求历史文章列表页面,同时使用 Fiddler 对其抓包,保存抓取到的文章列表。
- 解析 Fiddler 保存的文章列表,其中包含文章的元信息与 URL 地址。依次访问并下载每一篇文章,保存为 html 格式。
- 从 Fiddler 抓到的 Cookies 以及文章内的 script 标签中提取必要字段,构造出请求文章评论的 URL。关键字段包括
comment_id,pass_ticket等。评论接口的具体形式可以通过 Fiddler 抓包获取。 - 把文章整合成单个 HTML 文件,将元信息、图片、评论等嵌入其中。
-
下载并安装最新版 Fiddler。
-
打开 Fiddler 即开始监听本地所有 HTTP 请求。由于很多软件都会进行网络访问,为了减少干扰,需要在 Fiddler 中设置 filter。如下图所示,将其中的 Hosts 设为
mp.weixin.qq.com,URL contains 设为/mp/profile_ext?action=home /mp/profile_ext?action=getmsg。如此以来,Fiddler 就只会监控对微信公众号历史文章列表的请求。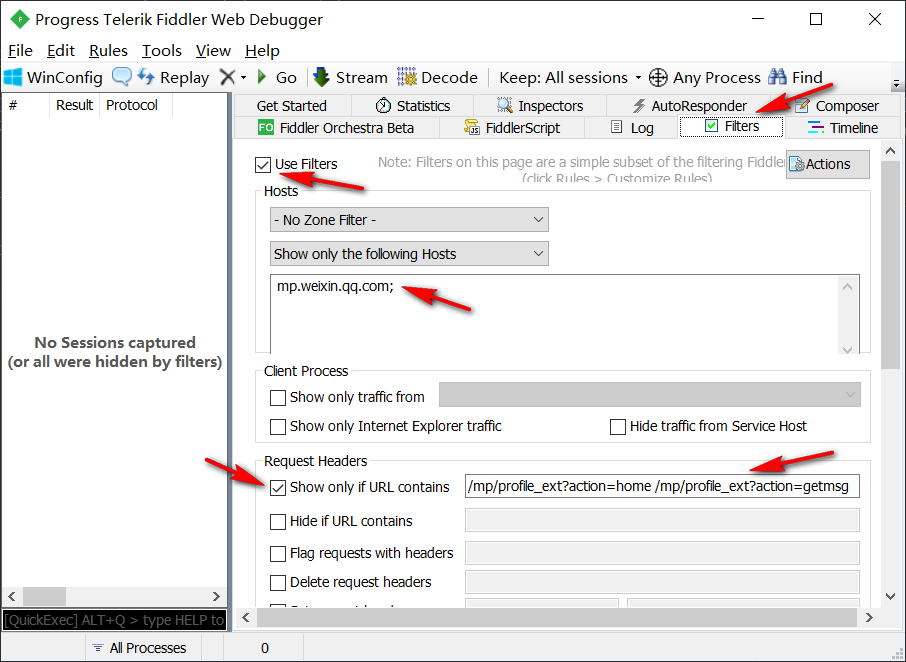
-
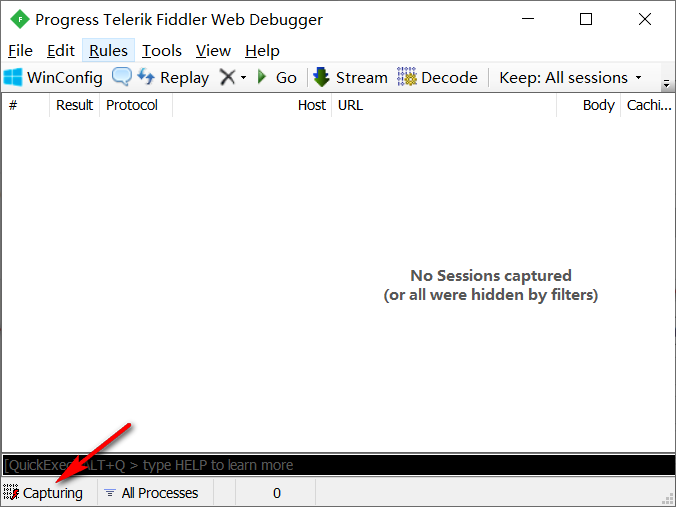
确保 Fiddler 窗口左下角出现“Capturing”字样,此时处于监控状态。如果是空白的,就用鼠标点击一下。
-
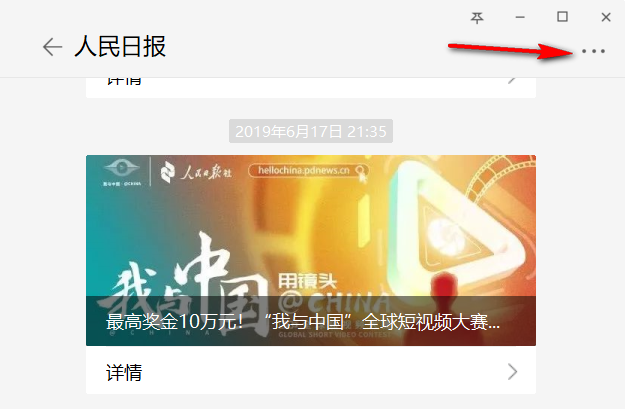
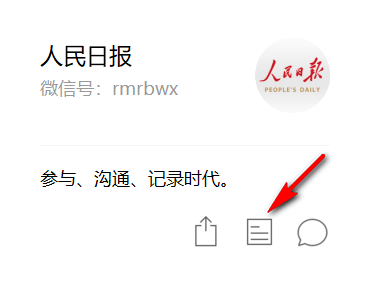
打开电脑版微信,进入要抓取的公众号,并打开其历史文章列表页面。打开方式见下图
-
打开历史文章列表后,可以看到 Fiddler 已经记录了一条请求,这条请求对应历史文章主页。在历史文章页继续向下滚动,当观察到底部出现刷新动画时,Fiddler 会增加一条新的记录。不断向下滚动,所有刷新出来的文章均会被 Fiddler 抓取。
-
Fiddler 抓到的请求中包含着文章列表的完整信息,我们需要将其保存下来供爬虫使用。选中待抓取的请求(由于已经设置了过滤规则,所以全选即可),点击菜单栏“File -> Export Sessions -> Selected Sessions”,保存格式选择 “Raw File”,然后指定输出目录即可。如下图所示:
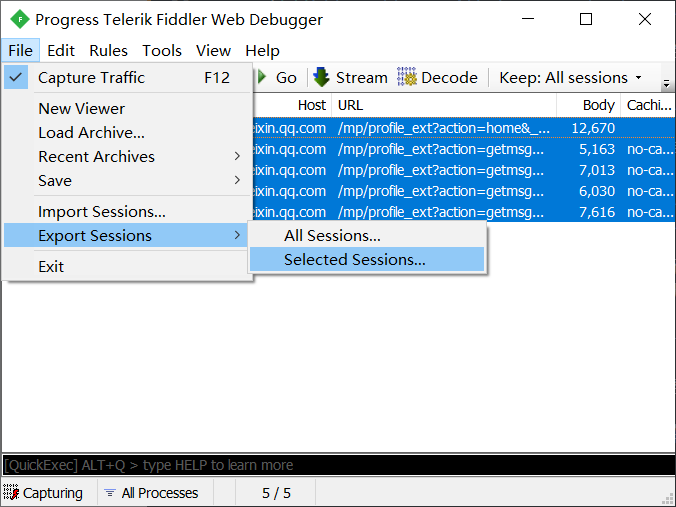
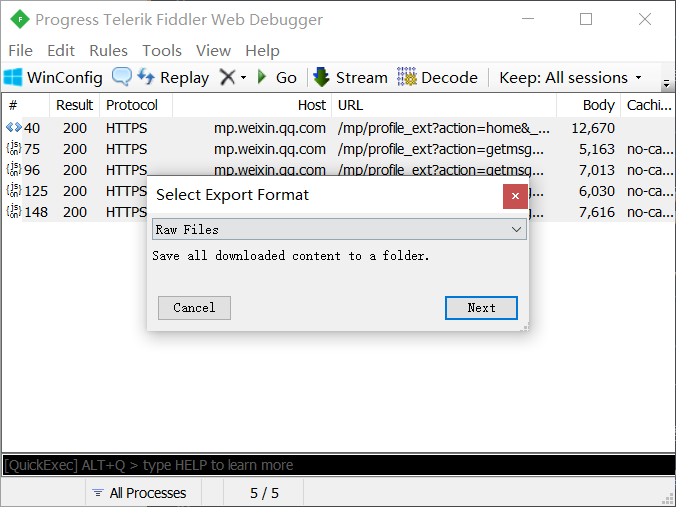
-
此时文章列表及其链接地址已经就绪,但要成功抓取文章还需要完成“认证”这一步。认证中会用到很多参数和 Cookie 等,想要破解这些参数的生成规则是非常困难的,因此我们直接借用 Fiddler 截获到的 Cookies。选中最后一个请求,点击菜单栏“File -> Save -> Request -> Entire Request”,将其保存到上一步的输出目录,并命名为
request.txt。如下图所示: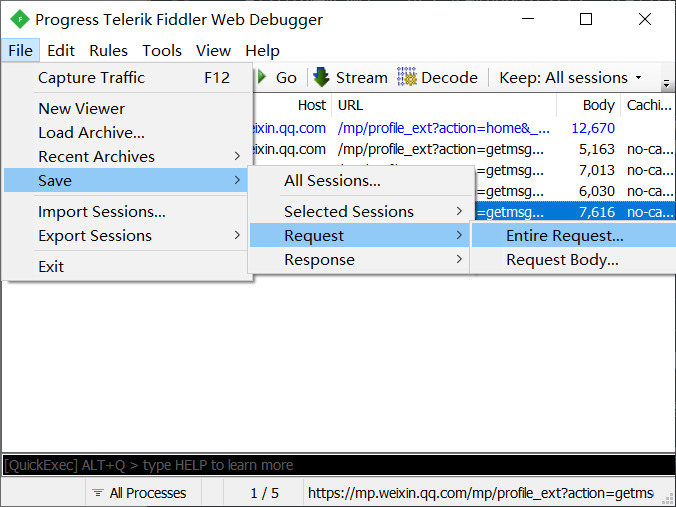
-
经过一定时间后,
request.txt中的参数将会过期,导致抓取失败。此时不必重新导出文章列表,只需要单独更新request.txt即可。因此导出文章列表是一劳永逸的。注意:有些抓取方案中并没有导出request.txt这一步,这种方案只能抓取文章内容,不能抓取文章评论。
爬虫会从 config.json 中读取必要的配置项,配置文件内容如下:
{
// 爬虫的输入目录,也就是 Fiddler 的导出目录
"input_dir": "C:\\Users\\Zhangsan\\Desktop\\Dump-1031-16-31-31",
// request 文件名,对应之前导出的 request.txt
"raw_request": "request.txt",
// 抓取后的输出目录
"output_dir": ".\\output\\人民日报"
}打开控制台,执行 main.py 即开始抓取:
python main.py文件命名形式为 日期-标题.html,方便浏览:
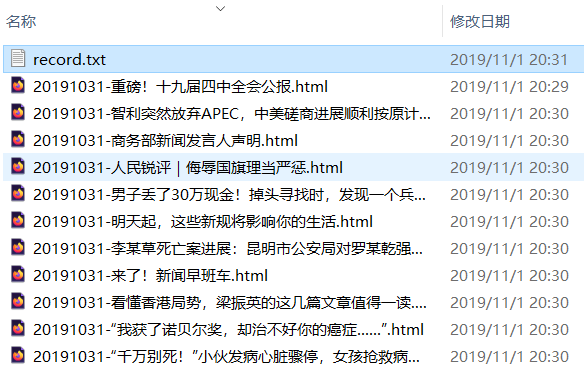
文章的内容、日期等元信息、图片、评论等会被打包到单个 HTML 文件中,使用浏览器打开即可阅读,如下图所示:
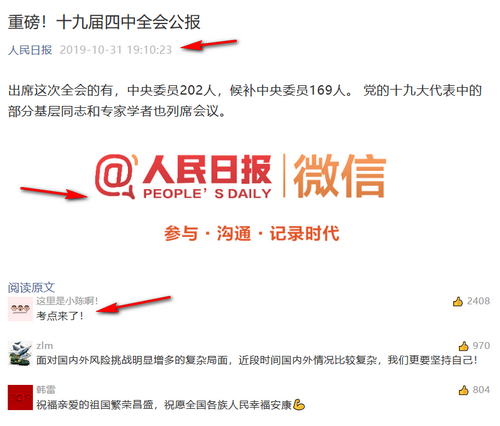
爬虫支持断点续抓,在出错或人为中断后,重新执行抓取命令将继续之前的进度。抓取进度实时保存在输出目录的 record.txt 文件中。