- 已适配llamacpp和Ollama,详见Index-1.9B-Chat-GGUF
- 开源Decay之前的Checkpoint供研究使用,详见Index-1.9B-Constant-LR
Index-1.9B系列是Index系列模型中的轻量版本,包含以下模型:
- Index-1.9B base : 基座模型,具有 19亿 非词嵌入参数量,在2.8T 中英文为主的语料上预训练,多个评测基准上与同级别模型比处于领先.
- Index-1.9B pure : 基座模型的对照组,与base具有相同的参数和训练策略,不同之处在于我们严格过滤了该版本语料中所有指令相关的数据,以此来验证指令对benchmark的影响
- Index-1.9B chat : 基于index-1.9B base通过SFT和DPO对齐后的对话模型,我们发现由于我们预训练中引入了较多互联网社区语料,聊天的趣味性明显更强,并且拥有同级别模型中较强的多语种(尤其是东亚语种)互译能力
- Index-1.9B character : 在SFT和DPO的基础上引入了RAG来实现fewshots角色扮演定制
| 模型 | 均分 | 英文均分 | MMLU | CEVAL | CMMLU | HellaSwag | Arc-C | Arc-E |
|---|---|---|---|---|---|---|---|---|
| Google Gemma 2B | 41.58 | 46.77 | 41.81 | 31.36 | 31.02 | 66.82 | 36.39 | 42.07 |
| Phi-2 (2.7B) | 58.89 | 72.54 | 57.61 | 31.12 | 32.05 | 70.94 | 74.51 | 87.1 |
| Qwen1.5-1.8B | 58.96 | 59.28 | 47.05 | 59.48 | 57.12 | 58.33 | 56.82 | 74.93 |
| Qwen2-1.5B(report) | 65.17 | 62.52 | 56.5 | 70.6 | 70.3 | 66.6 | 43.9 | 83.09 |
| MiniCPM-2.4B-SFT | 62.53 | 68.75 | 53.8 | 49.19 | 50.97 | 67.29 | 69.44 | 84.48 |
| Index-1.9B-Pure | 50.61 | 52.99 | 46.24 | 46.53 | 45.19 | 62.63 | 41.97 | 61.1 |
| Index-1.9B | 64.92 | 69.93 | 52.53 | 57.01 | 52.79 | 80.69 | 65.15 | 81.35 |
| Llama2-7B | 50.79 | 60.31 | 44.32 | 32.42 | 31.11 | 76 | 46.3 | 74.6 |
| Mistral-7B (report) | / | 69.23 | 60.1 | / | / | 81.3 | 55.5 | 80 |
| Baichuan2-7B | 54.53 | 53.51 | 54.64 | 56.19 | 56.95 | 25.04 | 57.25 | 77.12 |
| Llama2-13B | 57.51 | 66.61 | 55.78 | 39.93 | 38.7 | 76.22 | 58.88 | 75.56 |
| Baichuan2-13B | 68.90 | 71.69 | 59.63 | 59.21 | 61.27 | 72.61 | 70.04 | 84.48 |
| MPT-30B (report) | / | 63.48 | 46.9 | / | / | 79.9 | 50.6 | 76.5 |
| Falcon-40B (report) | / | 68.18 | 55.4 | / | / | 83.6 | 54.5 | 79.2 |
评测代码基于OpenCompass, 并做了适配性修改,详见evaluate文件夹
| HuggingFace | ModelScope |
|---|---|
| 🤗 Index-1.9B-Chat | Index-1.9B-Chat |
| 🤗 Index-1.9B-Character (角色扮演) | Index-1.9B-Character (角色扮演) |
| 🤗 Index-1.9B-Base | Index-1.9B-Base |
| 🤗 Index-1.9B-Base-Pure | Index-1.9B-Base-Pure |
- 下载本仓库:
git clone https://github.com/bilibili/Index-1.9B
cd Index-1.9B- 使用 pip 安装依赖:
pip install -r requirements.txt可通过以下代码加载 Index-1.9B-Chat 模型来进行对话:
import argparse
from transformers import AutoTokenizer, pipeline
# 注意!目录不能含有".",可以替换成"_"
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', default="./IndexTeam/Index-1.9B-Chat/", type=str, help="")
parser.add_argument('--device', default="cpu", type=str, help="") # also could be "cuda" or "mps" for Apple silicon
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.model_path, trust_remote_code=True)
generator = pipeline("text-generation",
model=args.model_path,
tokenizer=tokenizer, trust_remote_code=True,
device=args.device)
system_message = "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"
query = "续写 天不生我金坷垃"
model_input = []
model_input.append({"role": "system", "content": system_message})
model_input.append({"role": "user", "content": query})
model_output = generator(model_input, max_new_tokens=300, top_k=5, top_p=0.8, temperature=0.3, repetition_penalty=1.1, do_sample=True)
print('User:', query)
print('Model:', model_output)依赖Gradio,安装命令:
pip install gradio==4.29.0通过以下代码启动一个web server,在浏览器输入访问地址后,可使用 Index-1.9B-Chat 模型进行对话:
python demo/web_demo.py --port='port' --model_path='/path/to/model/'通过以下代码启动一个终端demo,可使用 Index-1.9B-Chat 模型进行对话:
python demo/cli_demo.py --model_path='/path/to/model/'依赖flask,安装命令:
pip install flask==2.2.5通过以下代码启动一个flask api接口
python demo/openai_demo.py --model_path='/path/to/model/'通过命令行即可进行对话
curl http://127.0.0.1:8010/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "你是由哔哩哔哩自主研发的大语言模型,名为“Index”。你能够根据用户传入的信息,帮助用户完成指定的任务,并生成恰当的、符合要求的回复。"},
{"role": "user", "content": "花儿为什么这么红"}
]
}'- 以下是一些使用
web_demo.py得到的 Index-1.9B-Chat 示例: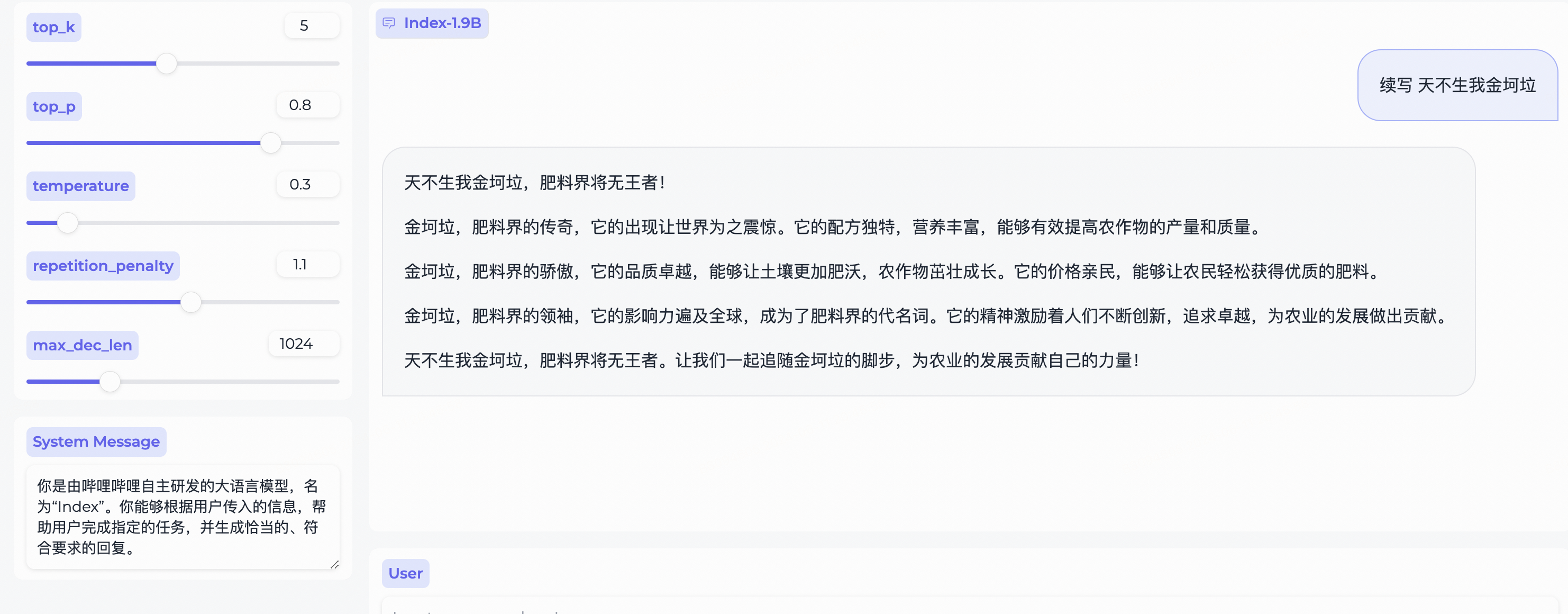
- 改变
System Message,即刻拥有B站评论区老哥~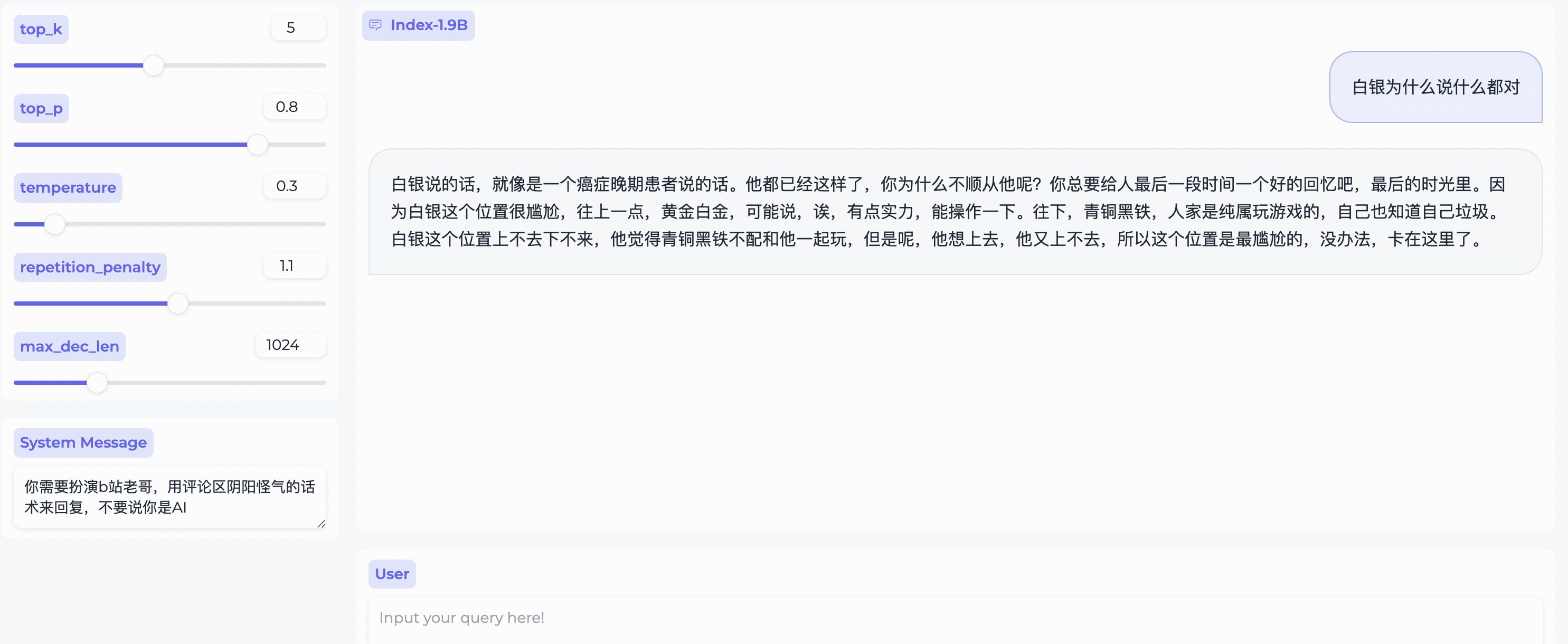
- 中译日
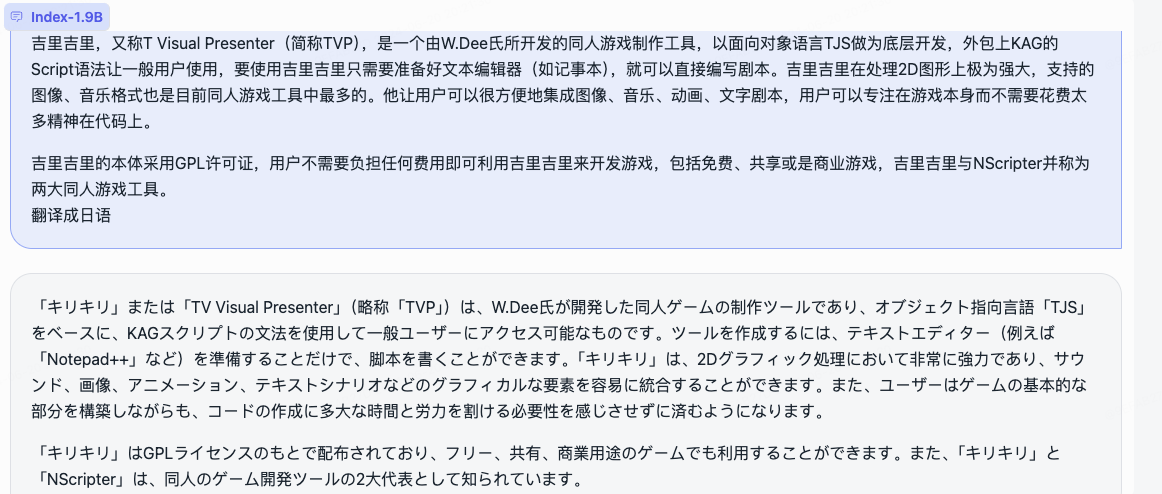
- 日译中
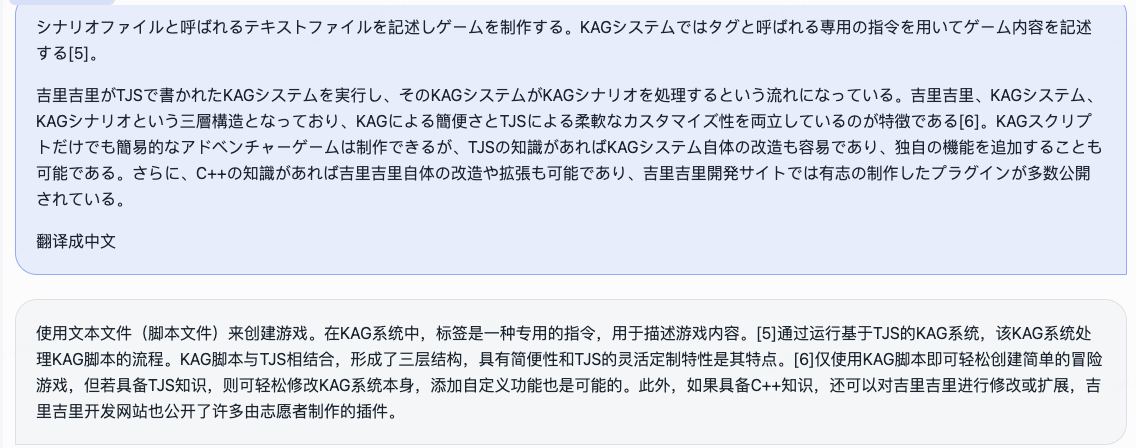




我们同期开源了角色扮演模型,以及配套框架。

- 我们目前内置了
三三的角色 - 如果需要创建您自己的角色,请准备一个类似roleplay/character/三三.csv的对话语料库(注意,文件名请与您要创建的角色名称保持一致)和对应角色的描述,点击
生成角色即可创建成功。 - 如果已经创建好对应的角色,请您直接在Role name里输入您想对话的角色,并输入query,点击submit,即可对话。
详细使用请前往 roleplay文件夹
依赖bitsandbytes,安装命令:
pip install bitsandbytes==0.43.0可以通过下面脚本进行int4量化,性能损失较少,进一步节省显存占用
import torch
import argparse
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TextIteratorStreamer,
GenerationConfig,
BitsAndBytesConfig
)
parser = argparse.ArgumentParser()
parser.add_argument('--model_path', default="", type=str, help="")
parser.add_argument('--save_model_path', default="", type=str, help="")
args = parser.parse_args()
tokenizer = AutoTokenizer.from_pretrained(args.model_path, trust_remote_code=True)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
model = AutoModelForCausalLM.from_pretrained(args.model_path,
device_map="auto",
torch_dtype=torch.float16,
quantization_config=quantization_config,
trust_remote_code=True)
model.save_pretrained(args.save_model_path)
tokenizer.save_pretrained(args.save_model_path)Index-1.9B在某些情况下可能会产生不准确、有偏见或其他令人反感的内容。模型生成内容时无法理解、表达个人观点或价值判断,其输出内容不代表模型开发者的观点和立场。因此,请谨慎使用模型生成的内容,用户在使用时应自行负责对其进行评估和验证,请勿将生成的有害内容进行传播,且在部署任何相关应用之前,开发人员应根据具体应用对模型进行安全测试和调优。
我们强烈警告不要将这些模型用于制造或传播有害信息,或进行任何可能损害公众、国家、社会安全或违反法规的活动,也不要将其用于未经适当安全审查和备案的互联网服务。我们已尽所能确保模型训练数据的合规性,但由于模型和数据的复杂性,仍可能存在无法预见的问题。如果因使用这些模型而产生任何问题,无论是数据安全问题、公共舆论风险,还是因模型被误解、滥用、传播或不合规使用所引发的任何风险和问题,我们将不承担任何责任。
使用本仓库的源码需要遵循 Apache-2.0 开源协议,使用 Index-1.9B 的模型权重则需要遵循模型许可协议。
Index-1.9B 模型权重对学术研究完全开放,并且支持免费商用。
如果你觉得我们的工作对你有帮助,欢迎引用!
@article{Index,
title={Index1.9B Technical Report},
year={2024}
}