
![]()
Please read the contents of the LICENSE file located directly under each folder before using the model. My model conversion scripts are released under the MIT license, but the license of the source model itself is subject to the license of the provider repository.
Made with contrib.rocks.
A repository for storing models that have been inter-converted between various frameworks. Supported frameworks are TensorFlow, PyTorch, ONNX, OpenVINO, TFJS, TFTRT, TensorFlowLite (Float32/16/INT8), EdgeTPU, CoreML.
TensorFlow Lite, OpenVINO, CoreML, TensorFlow.js, TF-TRT, MediaPipe, ONNX [.tflite, .h5, .pb, saved_model, tfjs, tftrt, mlmodel, .xml/.bin, .onnx]
I have been working on quantization of various models as a hobby, but I have skipped the work of making sample code to check the operation because it takes a lot of time. I welcome a pull request from volunteers to provide sample code. 😄
[Note Jan 05, 2020] Currently, the MobileNetV3 backbone model and the Full Integer Quantization model do not return correctly.
[Note Jan 08, 2020] If you want the best performance with RaspberryPi4/3, install Ubuntu 19.10 aarch64 (64bit) instead of Raspbian armv7l (32bit). The official Tensorflow Lite is performance tuned for aarch64. On aarch64 OS, performance is about 4 times higher than on armv7l OS.
-
Conversion of PyTorch->ONNX->OpenVINO IR model to Tensorflow saved_model / h5 / tflite / pb
-
[TF2 Object Detection] Converting SSD models into .tflite uint8 format #9371
-
[Japanese] Custom Operation入りのtfliteを逆コンバートしてJSON化し標準OPへ置き換えたうえでtfliteを再生成する方法
-
Add a custom OP to the TFLite runtime to build the whl installer (for Python),
MaxPoolingWithArgmax2D,MaxUnpooling2D,Convolution2DTransposeBias -
Inverse Quantization of tflite's Sparse Tensor Densify to Refine a Clean Float32 Model
-
Simple node deletion tool for onnx. I only test very miscellaneous and limited patterns as a hobby.
-
Simple tool to combine onnx models. Simple Network Combine Tool for ONNX.
-

-

* WQ = Weight Quantization ** OV = OpenVINO IR *** CM = CoreML **** DQ = Dynamic Range Quantization
| No. | Model Name | Link | FP32 | FP16 | INT8 | DQ | TPU | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 004 | Efficientnet | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 010 | Mobilenetv3 | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 011 | Mobilenetv2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 016 | Efficientnet-lite | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 070 | age-gender-recognition | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 083 | Person_Reidentification | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 248,277,286,287,288,300 | ||
| 087 | DeepSort | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 124 | person-attributes-recognition-crossroad-0230 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 125 | person-attributes-recognition-crossroad-0234 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 126 | person-attributes-recognition-crossroad-0238 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 175 | face-recognition-resnet100-arcface-onnx | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | RGB/BGR,112x112,[1,512] | |
| 187 | vehicle-attributes-recognition-barrier-0039 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 72x72 |
| 188 | vehicle-attributes-recognition-barrier-0042 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 72x72 |
| 191 | anti-spoof-mn3 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 128x128 | |
| 192 | open-closed-eye-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 32x32 | |
| 194 | face_recognizer_fast | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 112x112 |
| 195 | person_reid_youtu | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x128, ReID |
| 199 | NSFW | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 224x224 |
| 244 | FINNger | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 96x96 | ||
| 256 | SFace | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 112x112 | |
| 257 | PiCANet | ■■■ | ⚫ | ⚫ | BDDA,SAGE/224x224 | |||||||||
| 259 | Emotion_FERPlus | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 64x64 | |
| 290 | AdaFace | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 112x112 | ||
| 317 | MobileOne | ■■■ | ⚫ | 224x224 | ||||||||||
| 346 | facial_expression_recognition_mobilefacenet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 112x112 | |||||
| 379 | PP-LCNetV2 | ■■■ | ⚫ | ⚫ | ⚫ | 224x224 | ||||||||
| 429 | OSNet | ■■■ | ⚫ | 256x128, ReID | ||||||||||
| 430 | FastReID | ■■■ | ⚫ | 384x128, ReID | ||||||||||
| 431 | NITEC | ■■■ | ⚫ | 224x224, Gaze Estimation | ||||||||||
| 432 | face-reidentification-retail-0095 | ■■■ | ⚫ | ⚫ | ⚫ | 128x128, FaceReID |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 002 | Mobilenetv3-SSD | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 006 | Mobilenetv2-SSDlite | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 008 | Mask_RCNN_Inceptionv2 | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 018 | EfficientDet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 023 | Yolov3-nano | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 024 | Yolov3-lite | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 031 | Yolov4 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 034 | SSD_Mobilenetv2_mnasfpn | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 038 | SSDlite_MobileDet_edgetpu | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 039 | SSDlite_MobileDet_cpu | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 042 | Centernet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 045 | SSD_Mobilenetv2_oid_v4 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 046 | Yolov4-tiny | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 047 | SpineNetMB_49 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Mobile RetinaNet | ||||||
| 051 | East_Text_Detection | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 054 | KNIFT | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |||||
| 056 | TextBoxes++ with dense blocks, separable convolution and Focal Loss | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 058 | keras-retinanet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | resnet50_coco_best_v2.1.0.h5,320x320 | ||||
| 072 | NanoDet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | issue #274 | |
| 073 | RetinaNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 074 | Yolact | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 085 | Yolact_Edge | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 21/10/05 new MobileNetV2(550x550) |
| 089 | DETR | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x256 | ||||||
| 103 | EfficientDet_lite | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | lite0,lite1,lite2,lite3,lite4 | ||
| 116 | DroNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DroNet,DroNetV3 | |
| 123 | YOLOR | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ssss_s2d/320x320,640x640,960x960,1280x1280 | ||
| 132 | YOLOX | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | nano,tiny,s,m,l,x/256x320,320x320,416x416,480x640,544x960,736x1280,1088x1920 | |
| 143 | RAPiD | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Fisheye, cepdof/habbof/mw_r, 608x608/1024x1024 | |||||
| 145 | text_detection_db | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 480x640 | ||
| 151 | object_detection_mobile_object_localizer | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x192 | |
| 169 | spaghettinet_edgetpu | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 320x320,S/M/L | |
| 174 | PP-PicoDet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | S/M/L,320x320/416x416/640x640 | |
| 178 | vehicle-detection-0200 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x256,PriorBoxClustered->ndarray(0.npy) |
| 179 | person-detection-0202 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 512x512,PriorBoxClustered->ndarray(0.npy) |
| 183 | pedestrian-detection-adas-0002 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 384x672,PriorBox->ndarray(0.npy) |
| 184 | pedestrian-and-vehicle-detector-adas-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 384x672,PriorBox->ndarray(0.npy) |
| 185 | person-vehicle-bike-detection-crossroad-0078 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 1024x1024,PriorBoxClustered->ndarray(0.npy) | |
| 186 | person-vehicle-bike-detection-crossroad-1016 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 512x512,PriorBoxClustered->ndarray(0.npy) |
| 189 | vehicle-license-plate-detection-barrier-0106 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 300x300,PriorBoxClustered->ndarray(0.npy) |
| 190 | person-detection-asl-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 320x320 | ||||
| 197 | yolact-resnet50-fpn | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | RGB,550x550 | |
| 198 | YOLOF | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | BGR/RGB,608x608 | |
| 221 | YOLACT-PyTorch | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,240x320,320x480,480x640,544x544,720x1280 | ||
| 226 | CascadeTableNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | General,320x320 only | |||||
| 262 | ByteTrack | ■■■ | ⚫ | YOLOX/nano,tiny,s,m,l,x,mot17,ablation/128x320,192x320,192x448,192x640,256x320,256x448,256x640,384x640,512x1280,736x1280 | ||||||||||
| 264 | object_localization_network | ■■■ | ⚫ | 180x320,240x320,270x480,360x480,360x480,360x640,480x640,720x1280 | ||||||||||
| 307 | YOLOv7 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | YOLOv7,YOLOv7-tiny | |||
| 308 | FastestDet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,256x320,320x480,352x352,352x640,480x640,736x1280 | ||
| 329 | YOLOX-PAI | ■■■ | ⚫ | |||||||||||
| 332 | CrowdDet | ■■■ | ⚫ | |||||||||||
| 334 | DAMO-YOLO | ■■■ | ⚫ | |||||||||||
| 336 | PP-YOLOE-Plus | ■■■ | ⚫ | |||||||||||
| 337 | FreeYOLO | ■■■ | ⚫ | |||||||||||
| 341 | YOLOv6 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 356 | EdgeYOLO | ■■■ | ⚫ | |||||||||||
| 376 | RT-DETR | ■■■ | ⚫ | ResNet50,ResNet101,HgNetv2-L,HgNetv2-X | ||||||||||
| 386 | naruto_handsign_detection | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||||||
| 422 | Gold-YOLO-Head-Hand | ■■■ | ⚫ | Head,Hand | ||||||||||
| 424 | Gold-YOLO-Body | ■■■ | ⚫ | Body | ||||||||||
| 425 | Gold-YOLO-Body-Head-Hand | ■■■ | ⚫ | Body,Head,Hand | ||||||||||
| 426 | YOLOX-Body-Head-Hand | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | Body,Head,Hand, tflite float16 XNNPACK boost (ARMv8.2) | |||||||
| 434 | YOLOX-Body-Head-Hand-Face | ■■■ | ⚫ | Body,Head,Hand,Face | ||||||||||
| 441 | YOLOX-Body-Head-Hand-Face-Dist | ■■■ | ⚫ | Body,Head,Hand,Face,Complex Distorted | ||||||||||
| 442 | YOLOX-Body-Head-Face-HandLR-Dist | ■■■ | ⚫ | Body,Head,Hands,Left-Hand,Right-Hand,Face,Complex Distorted | ||||||||||
| 444 | YOLOX-Foot-Dist | ■■■ | ⚫ | Foot,Complex Distorted | ||||||||||
| 445 | YOLOX-Body-Head-Face-HandLR-Foot-Dist | ■■■ | ⚫ | Body,Head,Face,Hands,Left-Hand,Right-Hand,Foot,Complex Distorted | ||||||||||
| 446 | YOLOX-Body-With-Wheelchair | ■■■ | ⚫ | Body with WheelChair | ||||||||||
| 447 | YOLOX-Wholebody-with-Wheelchair | ■■■ | ⚫ | Wholebody with WheelChair | ||||||||||
| 448 | YOLOX-Eye-Nose-Mouth-Ear | ■■■ | ⚫ | |||||||||||
| 449 | YOLOX-WholeBody12 | ■■■ | ⚫ | Body,BodyWithWheelchair,Head,Face,Eye,Nose,Mouth,Ear,Hand,Hand-Left,Hand-Right,Foot |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 036 | Objectron | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe/camera,chair,chair_1stage,cup,sneakers,sneakers_1stage,ssd_mobilenetv2_oidv4_fp16 |
| 063 | 3D BoundingBox estimation for autonomous driving | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | YouTube | ||
| 107 | SFA3D | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 263 | EgoNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 321 | DID-M3D | ■■■ | ⚫ | |||||||||||
| 363 | YOLO-6D-Pose | ■■■ | ⚫ | ⚫ | ⚫ | Texas Instruments ver, PINTO Special ver |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 025 | Head_Pose_Estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 030 | BlazeFace | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |
| 032 | FaceMesh | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |
| 040 | DSFD_vgg | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 041 | DBFace | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MobileNetV2/V3, 320x320,480x640,640x960,800x1280 | |
| 043 | Face_Landmark | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 049 | Iris_Landmark | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe |
| 095 | CenterFace | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 096 | RetinaFace | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 106 | WHENet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Real-time Fine-Grained Estimation for Wide Range Head Pose | |
| 129 | SCRFD | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | All types | |
| 134 | head-pose-estimation-adas-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 60x60 |
| 144 | YuNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 120x160 | |
| 227 | face-detection-adas-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 384x672,PriorBox->ndarray(0.npy) |
| 250 | Face-Mask-Detection | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | PriorBox->ndarray(0.npy) | |
| 282 | face_landmark_with_attention | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe,192x192 | |||
| 289 | face-detection-0100 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x256,PriorBoxClustered->ndarray(0.npy) | |
| 293 | Lightweight-Head-Pose-Estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | HeadPose, 224x224 | ||
| 300 | 6DRepNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 6D HeadPose, 224x224 | |||
| 301 | YOLOv4_Face | ■■■ | ⚫ | 480x640 | ||||||||||
| 302 | SLPT | ■■■ | ⚫ | decoder=6/12,256x256 | ||||||||||
| 303 | FAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Face Alignment,128x128/256x256 | ||
| 304 | SynergyNet | ■■■ | ⚫ | 6D HeadPose,224x224 | ||||||||||
| 305 | DMHead | ■■■ | ⚫ | 6D HeadPose,Multi-Model-Fused,224x224,PINTO's custom models | ||||||||||
| 311 | HHP-Net | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 6D HeadPose,No-LICENSE | ||
| 319 | ACR-Loss | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Face Alignment | ||
| 322 | YOLOv7_Head | ■■■ | ⚫ | PINTO's custom models | ||||||||||
| 383 | DirectMHP | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 387 | YuNetV2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 640x640 | ||||||
| 390 | BlendshapeV2 | ■■■ | ⚫ | ⚫ | ⚫ | 1x146x2,Nx146x2,MediaPipe | ||||||||
| 399 | RetinaFace_MobileNetv2 | ■■■ | ⚫ | |||||||||||
| 410 | FaceMeshV2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |||||
| 414 | STAR | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 421 | Gold-YOLO-Head | ■■■ | ⚫ | Head (not Face) | ||||||||||
| 423 | 6DRepNet360 | ■■■ | ⚫ | 6D HeadPose, FullRange, 224x224 | ||||||||||
| 433 | FaceBoxes.PyTorch | ■■■ | ⚫ | 2D Face | ||||||||||
| 435 | MobileFaceNet | ■■■ | ⚫ | Face Alignment,112x112 | ||||||||||
| 436 | Peppa_Pig_Face_Landmark | ■■■ | ⚫ | Face Alignment,128x128,256x256 | ||||||||||
| 437 | PIPNet | ■■■ | ⚫ | Face Alignment,256x256 | ||||||||||
| 443 | Opal23_HeadPose | ■■■ | ⚫ | 6D HeadPose, FullRange, 128x128 |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 027 | Minimal-Hand | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 033 | Hand_Detection_and_Tracking | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe |
| 094 | hand_recrop | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |
| 403 | trt_pose_hand | ■■■ | ⚫ | 2D | ||||||||||
| 420 | Gold-YOLO-Hand | ■■■ | ⚫ | 2D | ||||||||||
| 438 | PeCLR | ■■■ | ⚫ | 2D+3D |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 003 | Posenet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 007 | Mobilenetv2_Pose_Estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 029 | Human_Pose_Estimation_3D | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | RGB,180x320,240x320,360x640,480x640,720x1280 |
| 053 | BlazePose | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |
| 065 | ThreeDPoseUnityBarracuda | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | YouTube | |
| 080 | tf_pose_estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 084 | EfficientPose | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | SinglePose | ||
| 088 | Mobilenetv3_Pose_Estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 115 | MoveNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | lightning,thunder | |
| 137 | MoveNet_MultiPose | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | lightning,192x192,192x256,256x256,256x320,320x320,480x640,720x1280,1280x1920 | ||
| 156 | MobileHumanPose | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 3D |
| 157 | 3DMPPE_POSENET | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 3D,192x192/256x256/320x320/416x416/480x640/512x512 | |
| 265 | PoseAug | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 2D->3D/GCN,MLP,STGCN,VideoPose/Nx16x2 | ||
| 268 | Lite-HRNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | COCO,MPII/Top-Down | ||
| 269 | Higher-HRNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x320,256x320,320x480,384x640,480x640,512x512,576x960,736x1280/Bottom-Up | ||
| 271 | HRNet | ■■■ | ⚫ | COCO,MPII/Top-Down | ||||||||||
| 333 | E2Pose | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | COCO/CrowdPose,End-to-End | ||||||
| 350 | P-STMO | ■■■ | ⚫ | 2D->3D,in_the_wild | ||||||||||
| 355 | MHFormer | ■■■ | ⚫ | ⚫ | ⚫ | 2D->3D | ||||||||
| 365 | HTNet | ■■■ | ⚫ | ⚫ | ⚫ | 2D->3D | ||||||||
| 392 | STCFormer | ■■■ | ⚫ | ⚫ | ⚫ | 2D->3D | ||||||||
| 393 | RTMPose_WholeBody | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 2D | ||||||
| 394 | RTMPose_Animal | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 2D | ||||||
| 402 | trt_pose | ■■■ | ⚫ | 2D | ||||||||||
| 412 | pytorch_cpn | ■■■ | ⚫ | ⚫ | ⚫ | 2D | ||||||||
| 427 | RTMPose_Hand | ■■■ | ⚫ | 2D | ||||||||||
| 440 | ViTPose | ■■■ | ⚫ | 2D |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 009 | Multi-Scale Local Planar Guidance for Monocular Depth Estimation | ■■■ | ⚫ | |||||||||||
| 014 | tf-monodepth2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 028 | struct2depth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 064 | Dense Depth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 066 | Footprints | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 067 | MiDaS | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 081 | MiDaS v2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 135 | CoEx | ■■■ | ⚫ | ⚫ | WIP, onnx/OpenVINO only | |||||||||
| 142 | HITNET | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | WIP issue1,issue2,flyingthings_finalpass_xl/eth3d/middlebury_d400,120x160/240x320/256x256/480x640/720x1280 | |||||||
| 146 | FastDepth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 128x160,224x224,256x256,256x320,320x320,480x640,512x512,768x1280 | |
| 147 | PackNet-SfM | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ddad/kitti,Convert all ResNet18 backbones only | ||
| 148 | LapDepth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | kitti/nyu,192x320/256x320/368x640/480x640/720x1280 | ||
| 149 | depth_estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | nyu,180x320/240x320/360x640/480x640/720x1280 | |
| 150 | MobileStereoNet | ■■■ | WIP. Conversion script only. | |||||||||||
| 153 | MegaDepth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x256,384x512 | |
| 158 | HR-Depth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 159 | EPCDepth | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 160 | msg_chn_wacv20 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x320,240x320,256x256,352x480,368x480,368x640,480x640,720x1280,1280x1920 | ||
| 162 | PyDNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 164 | MADNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Real-time-self-adaptive-deep-stereo (perform only inference mode, no-backprop, kitti) | |||
| 165 | RealtimeStereo | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,216x384,240x320,270x480,360x480,360x640,480x640,720x1280 | |||
| 166 | Insta-DM | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x320,256x320,256x832,384x640,480x640,736x1280 | |
| 167 | DPT | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | dpt-hybrid,480x640,ViT,ONNX 96x128/256x320/384x480/480x640 | ||
| 173 | MVDepthNet | ■■■ | ⚫ | ⚫ | 256x320 | |||||||||
| 202 | stereoDNN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | NVSmall_321x1025,NVTiny_161x513,ResNet18_321x1025,ResNet18_2d_257x513 | |||
| 203 | SRHNet | ■■■ | ⚫ | finetune2_kitti/sceneflow,maxdisp192,320x480/480x640 | ||||||||||
| 210 | SC_Depth_pl | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | kitti/nyu,320x320,320x480,480x640,640x800 | |
| 211 | Lac-GwcNet | ■■■ | ⚫ | kitti,240x320,320x480,480x640,720x1280 | ||||||||||
| 219 | StereoNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Left/180x320,240x320,320x480,360x640,480x640 | |||
| 235 | W-Stereo-Disp | ■■■ | ⚫ | Kitti,Sceneflow/320x480,384x576,480x640 | ||||||||||
| 236 | A-TVSNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Stereo only/192x320,256x320,320x480,480x640 | ||||||
| 239 | CasStereoNet | ■■■ | ⚫ | Stereo KITTI only/256x320,384x480,480x640,736x1280 | ||||||||||
| 245 | GLPDepth | ■■■ | ⚫ | ⚫ | Kitti,NYU/192x320,320x480,384x640,480x640,736x1280,non-commercial use only | |||||||||
| 258 | TinyHITNet | ■■■ | ⚫ | ⚫ | 180x320,240x320,300x400,360x640,384x512,480x640,720x960,720x1280 | |||||||||
| 266 | ACVNet | ■■■ | ⚫ | ⚫ | sceneflow,kitti/240x320,320x480,384x640,480x640,544x960,720x1280 | |||||||||
| 280 | GASDA | ■■■ | ⚫ | No-LICENSE | ||||||||||
| 284 | CREStereo | ■■■ | ⚫ | ITER2,ITER5,ITER10,ITER20/240x320,320x480,360x640,480x640,480x640,720x1280 | ||||||||||
| 292 | Graft-PSMNet | ■■■ | ⚫ | 192x320,240x320,320x480,368x640,480x640,720x1280 | ||||||||||
| 294 | FSRE-Depth | ■■■ | ⚫ | ⚫ | 192x320,256x320,320x480,368x640,480x640,736x1280 | |||||||||
| 296 | MGNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 240x320,360x480,360x640,360x1280,480x640,720x1280 | |||
| 312 | NeWCRFs | ■■■ | ⚫ | 384x384,384x576,384x768,384x960,576x768,768x1344 | ||||||||||
| 313 | PyDNet2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Mono-Depth | |
| 327 | EMDC | ■■■ | ⚫ | RGB+SarseDepth | ||||||||||
| 338 | Fast-ACVNet | ■■■ | ⚫ | Stereo/grid_sample opset=16,no_grid_sample opset=11 | ||||||||||
| 358 | CGI-Stereo | ■■■ | ⚫ | ⚫ | ⚫ | Stereo | ||||||||
| 362 | ZoeDepth | ■■■ | ⚫ | Mono-Depth | ||||||||||
| 364 | IGEV | ■■■ | ⚫ | Stereo | ||||||||||
| 371 | Lite-Mono | ■■■ | ⚫ | Mono | ||||||||||
| 384 | TCMonoDepth | ■■■ | ⚫ | Mono | ||||||||||
| 397 | MiDaSv3.1 | ■■■ | ⚫ | Mono | ||||||||||
| 415 | High-frequency-Stereo-Matching-Network | ■■■ | ⚫ | Stereo | ||||||||||
| 439 | Depth-Anything | ■■■ | ⚫ | Mono |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 001 | deeplabv3 | ■■■ | ⚫ | ⚫ | ||||||||||
| 015 | Faster-Grad-CAM | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 020 | EdgeTPU-Deeplab | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 021 | EdgeTPU-Deeplab-slim | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 026 | Mobile-Deeplabv3-plus | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 035 | BodyPix | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe,MobileNet0.50/0.75/1.00,ResNet50 | |
| 057 | BiSeNetV2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 060 | Hair Segmentation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | WIP,MediaPipe | ||||||
| 061 | U^2-Net | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 069 | ENet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Cityscapes,512x1024 | |||||
| 075 | ERFNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Cityscapes,256x512,384x786,512x1024 | ||
| 078 | MODNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 128x128,192x192,256x256,512x512 | ||
| 082 | MediaPipe_Meet_Segmentation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe,128x128,144x256,96x160 | |
| 104 | DeeplabV3-plus | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | cityscapes,200x400,400x800,800x1600 | |||
| 109 | Selfie_Segmentation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x256 | ||
| 136 | road-segmentation-adas-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 138 | BackgroundMattingV2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 720x1280,2160x4096 | ||||||
| 181 | models_edgetpu_checkpoint_and_tflite_vision_segmentation-edgetpu_tflite_default_argmax | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |
| 182 | models_edgetpu_checkpoint_and_tflite_vision_segmentation-edgetpu_tflite_fused_argmax | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |
| 196 | human_segmentation_pphumanseg | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |
| 201 | CityscapesSOTA | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,240x320,360x640,480x640,720x1280 | ||
| 206 | Matting | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | PaddleSeg/modnet_mobilenetv2,modnet_hrnet_w18,modnet_resnet50_vd/256x256,384x384,512x512,640x640 | ||
| 228 | Fast-SCNN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x384,384x384,384x576,576x576,576x768,768x1344 |
| 238 | SUIM-Net | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | RSB,VGG/240x320,256x320,320x480,360x640,384x480,384x640,480x640,720x1280 | |||
| 242 | RobustVideoMatting | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Mbnv3,ResNet50/192x320,240x320,320x480,384x640,480x640,720x1280,1088x1920,2160x3840 | |
| 246 | SqueezeSegV3 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 21,53/180x320,240x320,320x480,360x640,480x640,720x1280 | |||
| 267 | LIOT | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,240x320,320x480,360x640,480x640,540x960,720x1280,1080x1920 | ||
| 287 | Topformer | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Tiny,Small,Base/448x448,512x512 | ||
| 295 | SparseInst | ■■■ | ⚫ | ⚫ | r50_giam_aug/192x384,384x384,384x576,384x768,576x576,576x768,768x1344 | |||||||||
| 299 | DGNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 313 | IS-Net | ■■■ | ⚫ | 180x320,240x320,320x480,360x640,480x640,720x1280,1080x1920,1080x2048,2160x4096,N-batch,Dynamic-HeightxWidth | ||||||||||
| 335 | PIDNet | ■■■ | ⚫ | Cityscapes,CamVid/Dynamic-HeightxWidth | ||||||||||
| 343 | PP-MattingV2 | ■■■ | ⚫ | ⚫ | ⚫ | HumanSeg | ||||||||
| 347 | RGBX_Semantic_Segmentation | ■■■ | ⚫ | |||||||||||
| 369 | Segment_Anything | ■■■ | ⚫ | |||||||||||
| 380 | Skin-Clothes-Hair-Segmentation-using-SMP | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 391 | MagicTouch | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | MediaPipe | |||||||
| 405 | Ear_Segmentation | ■■■ | ⚫ | Ear | ||||||||||
| 417 | PopNet | ■■■ | ⚫ | Saliency |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 005 | One_Class_Anomaly_Detection | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | |||||||
| 099 | Efficientnet_Anomaly_Detection_Segmentation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 017 | Artistic-Style-Transfer | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 019 | White-box-Cartoonization | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 037 | First_Neural_Style_Transfer | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 044 | Selfie2Anime | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||||
| 050 | AnimeGANv2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 062 | Facial Cartoonization | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 068 | Colorful_Image_Colorization | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | experimental | ||||
| 101 | arbitrary_image_stylization | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | magenta | |
| 113 | Anime2Sketch | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 161 | EigenGAN-Tensorflow | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Anime,CelebA | ||
| 193 | CoCosNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | RGB,256x256 |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 012 | Fast_Accurate_and_Lightweight_Super-Resolution | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 022 | Learning_to_See_Moving_Objects_in_the_Dark | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||||
| 071 | Noise2Noise | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | srresnet/clear only | |||||
| 076 | Deep_White_Balance | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 077 | ESRGAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 50x50->x4, 100x100->x4 | |
| 079 | MIRNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/40x40,80x80,120x120,120x160,120x320,120x480,120x640,120x1280,180x480,180x640,180x1280,180x320,240x320,240x480,360x480,360x640,480x640,720x1280 |
| 086 | Defocus Deblurring Using Dual-Pixel | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 090 | Ghost-free_Shadow_Removal | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x256 | ||||
| 111 | SRN-Deblur | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 240x320,480x640,720x1280,1024x1280 | ||
| 112 | DeblurGANv2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | inception/mobilenetv2:256x256,320x320,480x640,736x1280,1024x1280 | ||
| 114 | Two-branch-dehazing | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 240x320,480x640,720x1280 | |||
| 133 | Real-ESRGAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 16x16,32x32,64x64,128x128,240x320,256x256,320x320,480x640 | |||
| 152 | DeepLPF | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||||||
| 170 | Learning-to-See-in-the-Dark | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | sony/fuji, 240x320,360x480,360x640,480x640 | ||
| 171 | Fast-SRGAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 120x160,128x128,240x320,256x256,480x640,512x512 | |||
| 172 | Real-Time-Super-Resolution | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 64x64,96x96,128x128,256x256,240x320,480x640 | |
| 176 | StableLLVE | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image/Video Enhancement,180x240,240x320,360x640,480x640,720x1280 | |
| 200 | AGLLNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image/Video Enhancement,256x256,256x384,384x512,512x640,768x768,768x1280 | |||
| 204 | HINet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeBlur,DeNoise,DeRain/256x320,320x480,480x640 | |
| 205 | MBLLEN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image/Video Enhancement,180x320,240x320,360x640,480x640,720x1280 |
| 207 | GLADNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image/Video Enhancement,180x320,240x320,360x640,480x640,720x1280,No-LICENSE |
| 208 | SAPNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeRain,180x320,240x320,360x640,480x640,720x1280 | ||
| 209 | MSBDN-DFF | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Dehazing,192x320,240x320,320x480,384x640,480x640,720x1280,No-LICENSE | ||
| 212 | GFN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeBlur+SuperResolution,x4/64x64,96x96,128x128,192x192,240x320,256x256,480x640,720x1280 |
| 213 | TBEFN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,360x640,480x640,720x1280 |
| 214 | EnlightenGAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/192x320,240x320,320x480,368x640,480x640,720x1280 | |
| 215 | AOD-Net | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeHazing/180x320,240x320,320x480,360x640,480x640,720x1280 |
| 216 | Zero-DCE-TF | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,360x640,480x640,720x1280 |
| 217 | RUAS | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,360x640,480x640,720x1280,No-LICENSE |
| 218 | DSLR | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/256x256,256x384,256x512,384x640,512x640,768x1280 | ||
| 220 | HEP | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,360x640,480x640 | |
| 222 | LFT | ■■■ | ⚫ | Transformer/2x,4x/65x65 | ||||||||||
| 223 | DA_dahazing | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeHazing/192x320,240x320,320x480,360x640,480x640,720x1280,No-LICENSE | ||
| 224 | Y-net | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeHazing/192x320,240x320,320x480,384x640,480x640,720x1280 | |
| 225 | DRBL | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeHazing/192x320,240x320,320x480,384x640,480x640,720x1280 | ||
| 230 | Single-Image-Desnowing-HDCWNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeSnowing/512x672 | |||||
| 231 | DRBL | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,360x640,480x640,720x1280,No-LICENSE | |
| 232 | MIMO-UNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeBlur/180x320,240x320,320x480,360x640,480x640,720x1280,No-LICENSE | |
| 234 | FBCNN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeNoise/180x320,240x320,320x480,360x640,480x640,720x1280 | ||
| 240 | BSRGAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | x2,x4/64x64,96x96,128x128,160x160,180x320,240x320,No-LICENSE | ||
| 241 | SCL-LLE | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,480x640,720x1280,No-LICENSE |
| 243 | Zero-DCE-improved | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,320x480,360x640,480x640,720x1280,academic use only | |
| 249 | Real-CUGAN | ■■■ | ⚫ | ⚫ | 2x,3x,4x/64x64,96x96,128x128,120x160,160x160,180x320,240x320 | |||||||||
| 251 | AU-GAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/128x256,240x320,240x640,256x512,480x640,512x1024,720x1280 | ||
| 253 | TransWeather | ■■■ | ⚫ | ⚫ | DeRain,DeHaizing,DeSnow/192x320,256x320,320x480,384x640,480x640,736x1280 | |||||||||
| 261 | EfficientDerain | ■■■ | ⚫ | v4_SPA,v4_rain100H,v4_rain1400/192x320,256x320,320x480,384x640,480x640,608x800,736x1280 | ||||||||||
| 270 | HWMNet | ■■■ | ⚫ | Low-light Image Enhancement/192x320,256x320,320x480,384x640,480x640,544x960,720x1280 | ||||||||||
| 275 | FD-GAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeHaizing/192x320,256x320,384x640,480x640,720x1280,1080x1920,No-LICENSE | ||
| 277 | EDN-GTM | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeHaizing/192x320,240x320,384x480,480x640,512x512,720x1280,1088x1920 | |||
| 281 | IMDN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | x4/64x64,96x96,128x128,120x160,160x160,180x320,192x192,256x256,180x320,240x320,360x640,480x640 | ||
| 283 | UIE-WD | ■■■ | ⚫ | Underwater Image Enhancement/WIP issue #97/192x320,240x320,320x480,360x640,480x640,720x1280,1080x1920 | ||||||||||
| 285 | Decoupled-Low-light-Image-Enhancement | ■■■ | ⚫ | Low-light Image Enhancement/180x320,240x320,360x480,360x640,480x640,720x1280 | ||||||||||
| 286 | SCI | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Low-light Image Enhancement/180x320,240x320,360x480,360x640,480x640,720x1280 | |
| 315 | Illumination-Adaptive-Transformer | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 316 | night_enhancement | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 320 | Dehamer | ■■■ | ⚫ | Dehazing | ||||||||||
| 323 | Stripformer | ■■■ | ⚫ | DeBlur | ||||||||||
| 325 | DehazeFormer | ■■■ | ⚫ | Dehazing | ||||||||||
| 344 | XYDeblur | ■■■ | ⚫ | DeBlur | ||||||||||
| 348 | Bread | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 348 | PMN | ■■■ | ⚫ | DeNoise, Low-light Image Enhancement | ||||||||||
| 351 | RFDN | ■■■ | ⚫ | x4 | ||||||||||
| 352 | MAXIM | ■■■ | ⚫ | ⚫ | ⚫ | Dehaze only | ||||||||
| 353 | ShadowFormer | ■■■ | ⚫ | Shadow Removal | ||||||||||
| 354 | DEA-Net | ■■■ | ⚫ | ⚫ | ⚫ | DeHaze | ||||||||
| 359 | MSPFN | ■■■ | ⚫ | ⚫ | ⚫ | DeRain | ||||||||
| 361 | KBNet | ■■■ | ⚫ | Real Image Denoising | ||||||||||
| 367 | FLW-Net | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 368 | C2PNet | ■■■ | ⚫ | DeHaze | ||||||||||
| 370 | Semantic-Guided-Low-Light-Image-Enhancement | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 372 | URetinex-Net | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 375 | SCANet | ■■■ | ⚫ | DeHaze | ||||||||||
| 377 | DRSformer | ■■■ | ⚫ | DeRain | ||||||||||
| 385 | PairLIE | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 389 | WGWS-Net | ■■■ | ⚫ | DeRain,DeRainDrop,DeHaize,DeSnow | ||||||||||
| 396 | MixDehazeNet | ■■■ | ⚫ | DeHaize | ||||||||||
| 400 | CSRNet | ■■■ | ⚫ | Low-light Image Enhancement | ||||||||||
| 404 | HDR-Transformer | ■■■ | ⚫ | |||||||||||
| 409 | nighttime_dehaze | ■■■ | ⚫ | DeHaze | ||||||||||
| 411 | UDR-S2Former_deraining | ■■■ | ⚫ | DeRain | ||||||||||
| 418 | Diffusion-Low-Light | ■■■ | ⚫ | ⚫ | ⚫ | Diffusion, Low-light Image Enhancement |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 013 | ml-sound-classifier | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||||
| 097 | YAMNet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 098 | SPICE | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 118 | Speech-enhancement | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | WIP,EdgeTPU(LeakyLeRU) | |
| 120 | FRILL | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | nofrontend | |
| 177 | BirdNET-Lite | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | non-flex | |||||
| 381 | Whisper | ■■■ | ⚫ | |||||||||||
| 382 | Light-SERNet | ■■■ | ⚫ | ⚫ | ⚫ |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 048 | Mobile_BERT | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 121 | GPT2/DistillGPT2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 122 | DistillBert | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 052 | Handwritten_Text_Recognition | ■■■ | ⚫ | ⚫ | ⚫ | ||||||||
| 055 | Handwritten_Japanese_Recognition | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 093 | ocr_japanese | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 120x160 |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 092 | weld-porosity-detection-0001 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 247 | PoseC3D | ■■■ | ⚫ | Skeleton-based/FineGYM,NTU60_XSub,NTU120_XSub,UCF101,HMDB51/1x20x48x64x64 | ||||||||||
| 248 | MS-G3D | ■■■ | ⚫ | Skeleton-based/Kinetics,NTU60,NTU120/1x3xTx25x2 |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 100 | HiFill | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||||||
| 163 | MST_inpainting | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 273 | OPN(Onion-Peel Networks) | ■■■ | ⚫ | |||||||||||
| 274 | DeepFillv2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 105 | MobileStyleGAN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 310 | attentive-gan-derainnet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | DeRain/180x320,240x320,240x360,320x480,360x640,480x640,720x1280 |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 127 | dino | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | experimental,dino_deits8/dino_deits16 |
| No. | Model Name | Link | FP32 | FP16 | INT8 | TPU | DQ | WQ | OV | CM | TFJS | TF-TRT | ONNX | Remarks |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 091 | gaze-estimation-adas-0002 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 102 | Coconet | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | magenta | |||||||
| 108 | HAWP | ■■■ | ⚫ | Line Parsing,WIP | ||||||||||
| 110 | L-CNN | ■■■ | ⚫ | Line Parsing,WIP | ||||||||||
| 117 | DTLN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||
| 119 | M-LSD | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 131 | CFNet | ■■■ | ⚫ | 256x256,512x768 | ||||||||||
| 139 | PSD-Principled-Synthetic-to-Real-Dehazing-Guided-by-Physical-Priors | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||
| 140 | Ultra-Fast-Lane-Detection | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 288x800 | |
| 141 | lanenet-lane-detection | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 256x512 | |
| 154 | driver-action-recognition-adas-0002-encoder | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 155 | driver-action-recognition-adas-0002-decoder | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | |||
| 167 | LSTR | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,240x320,360x640,480x640,720x1280 | ||||
| 229 | DexiNed | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 160x320,320x480,368x640,480x640,720x1280 | |
| 233 | HRNet-for-Fashion-Landmark-Estimation | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 192x320,256x320,320x480,384x640,480x640,736x1280 | ||
| 237 | piano_transcription | ■■■ | ⚫ | ⚫ | 1x160000,Nx160000 | |||||||||
| 252 | RAFT | ■■■ | ⚫ | small,chairs,kitti,sintel,things/iters=10,20/240x320,360x480,480x640 | ||||||||||
| 254 | FullSubNet-plus | ■■■ | ⚫ | 1x1x257x100,200,500,1000,2000,3000,5000,7000,8000,10000 | ||||||||||
| 255 | FILM | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | L1,Style,VGG/256x256,180x320,240x320,360x640,480x640,720x1280,1080x1920 | ||||
| 260 | KP2D | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ResNet/128x320,192x320,192x448,192x640,256x320,256x448,256x640,320x448,384x640,480x640,512x1280,736x1280 | |||||
| 272 | CSFlow | ■■■ | ⚫ | chairs,kitti,things/iters=10,20/192x320,240x320,320x480,384x640,480x640,736x1280 | ||||||||||
| 276 | HybridNets | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | anchor_HxW.npy/256x384,256x512,384x512,384x640,384x1024,512x640,768x1280,1152x1920 | ||
| 278 | DWARF | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | StereoDepth+OpticalFlow,/192x320,256x320,384x640,512x640,512x640,768x1280 | ||
| 279 | F-Clip | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Line Parsing/ALL/192x320,256x320,320x480,384x640,480x640,736x1280 | |||
| 288 | perceptual-reflection-removal | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Reflection-Removal/180x320,240x320,360x480,360x640,480x640,720x1280 | |||
| 291 | SeAFusion | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | 180x320,240x320,360x480,360x640,480x640,720x1280 | ||||
| 297 | GazeNet | ■■■ | ⚫ | 1x7x3x256x192/NxFx3x256x192 | ||||||||||
| 298 | DEQ-Flow | ■■■ | ⚫ | AGPL-3.0 license | ||||||||||
| 306 | GMFlowNet | ■■■ | ⚫ | OpticalFlow/192x320,240x320,320x480,360x640,480x640,720x1280 | ||||||||||
| 309 | ImageForensicsOSN | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | forgery detection/180x320,240x320,320x480,360x640,480x640,720x1280 | |||
| 318 | pips | ■■■ | ⚫ | |||||||||||
| 324 | Ultra-Fast-Lane-Detection-v2 | ■■■ | ⚫ | |||||||||||
| 326 | YOLOPv2 | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 328 | Stable_Diffusion | ■■■ | ⚫ | |||||||||||
| 339 | DeepLSD | ■■■ | ⚫ | |||||||||||
| 342 | ALIKE | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | ||||||
| 357 | Unimatch | ■■■ | ⚫ | ⚫ | ⚫ | OpticalFlow, StereoDepth | ||||||||
| 360 | PARSeq | ■■■ | ⚫ | ⚫ | ⚫ | Scene Text Recognition | ||||||||
| 366 | text_recognition_CRNN | ■■■ | ⚫ | ⚫ | ⚫ | CN/CH/EN | ||||||||
| 373 | LiteTrack | ■■■ | ⚫ | ⚫ | ⚫ | Tracking | ||||||||
| 374 | LaneSOD | ■■■ | ⚫ | Lane Segmentation | ||||||||||
| 378 | P2PNet_tfkeras | ■■■ | ⚫ | ⚫ | ⚫ | |||||||||
| 388 | LightGlue | ■■■ | ⚫ | Keypoint Matching | ||||||||||
| 398 | L2CS-Net | ■■■ | ⚫ | ⚫ | ⚫ | ⚫ | ⚫ | Gaze Pose 448x448 | ||||||
| 401 | CLRerNet | ■■■ | ⚫ | Lane Detection | ||||||||||
| 406 | DeDoDe | ■■■ | ⚫ | ⚫ | ⚫ | Keypoint Detection, Description, Matching | ||||||||
| 407 | Generalizing_Gaze_Estimation | ■■■ | ⚫ | ⚫ | ⚫ | Gaze Pose 160x160 | ||||||||
| 408 | UAED | ■■■ | ⚫ | Edge Detectopm | ||||||||||
| 413 | DocShadow | ■■■ | ⚫ | ⚫ | Document Shadow Removal | |||||||||
| 416 | GeoNet | ■■■ | ⚫ | ⚫ | MonoDepth, CameraPose, OpticalFlow | |||||||||
| 428 | ISR | ■■■ | ⚫ | Person ReID |
- RaspberryPi4 (CPU only)
- Raspbian Buster 64bit
- Tensorflow / Tensorflow Lite with multi-thread acceleration tuning for PythonAPI
- MobileNetV2-SSDLite 300x300 Integer Quantization
- Pascal-VOC Dataset (Japanese article)
- MP4 30FPS, 640x360
- Approximately 14FPS ~ 15FPS for all processes from pre-processing, inference, post-processing, and display
$ cd 006_mobilenetv2-ssdlite/02_voc/03_integer_quantization
$ ./download.sh && cd ..
$ python3 mobilenetv2ssdlite_movie_sync.py
- RaspberryPi4 (CPU only)
- Ubuntu 19.10 64bit
- Tensorflow / Tensorflow Lite with multi-thread acceleration tuning for PythonAPI
- MobileNetV2-SSDLite 300x300 Integer Quantization
- Pascal-VOC Dataset (Japanese article)
- USB Camera, 640x480
- IPS 1080p HDMI Display
- Approximately 12FPS for all processes from pre-processing, inference, post-processing, and display
$ cd 006_mobilenetv2-ssdlite/02_voc/03_integer_quantization
$ ./download.sh && cd ..
$ python3 mobilenetv2ssdlite_usbcam_sync.py
- RaspberryPi4 (CPU only)
- Ubuntu 19.10 64bit
- Tensorflow / Tensorflow Lite with multi-thread acceleration tuning for PythonAPI
- [Model.1] MobileNetV2-SSDLite dm=0.5 300x300, Integer Quantization
- [Model.2] Head Pose Estimation 128x128, Integer Quantization
- WIDERFACE
- USB Camera, 640x480
- IPS 1080p HDMI Display
- Approximately 13FPS for all processes from pre-processing, inference, post-processing, and display
$ cd 025_head_pose_estimation/03_integer_quantization
$ ./download.sh
$ python3 head_pose_estimation.py
- RaspberryPi4 (CPU only)
- Ubuntu 19.10 64bit
- Tensorflow / Tensorflow Lite with multi-thread acceleration tuning for PythonAPI
- DeeplabV3-plus (MobileNetV2) Decoder 256x256, Integer Quantization
- USB Camera, 640x480
- IPS 1080p HDMI Display
- Approximately 8.5 FPS for all processes from pre-processing, inference, post-processing, and display
$ cd 026_mobile-deeplabv3-plus/03_integer_quantization
$ ./download.sh
$ python3 deeplabv3plus_usbcam.py
Sample.5 - MediaPipe/FaceMesh, face_detection_front_128_weight_quant, face_landmark_192_weight_quant
- Ubuntu 18.04 x86_64
- Tensorflow Lite
- C/C++
- OpenGL
- USB Camera, 640x480
$ v4l2-ctl --set-fmt-video=width=640,height=480,pixelformat=YUYV- Test Code - tflite_gles_app - gl2facemesh - @terryky
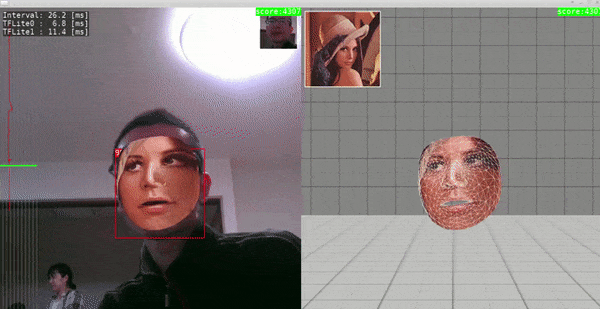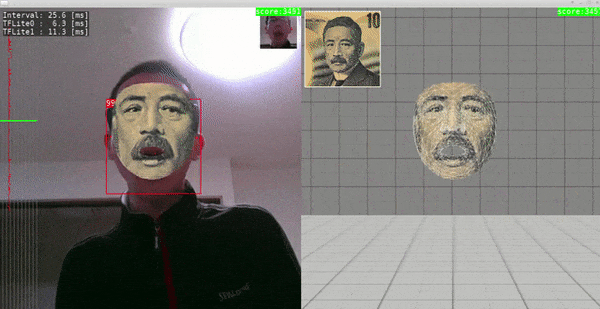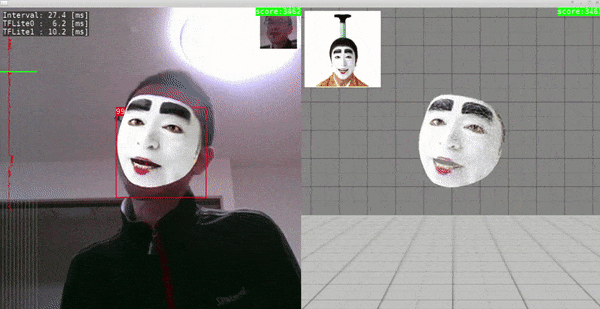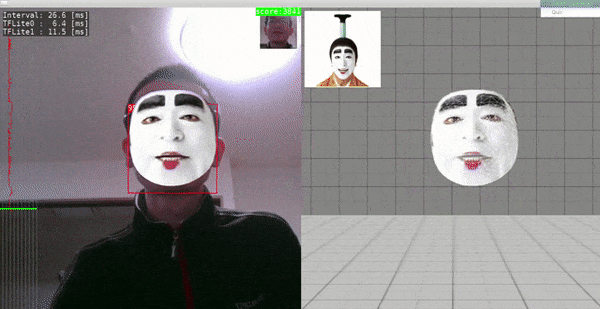

- Ubuntu 18.04 x86_64
- Tensorflow Lite
- C/C++
- OpenGL
- USB Camera, 640x480
$ v4l2-ctl --set-fmt-video=width=640,height=480,pixelformat=YUYV- Test Code - tflite_gles_app - gl2objectron - @terryky
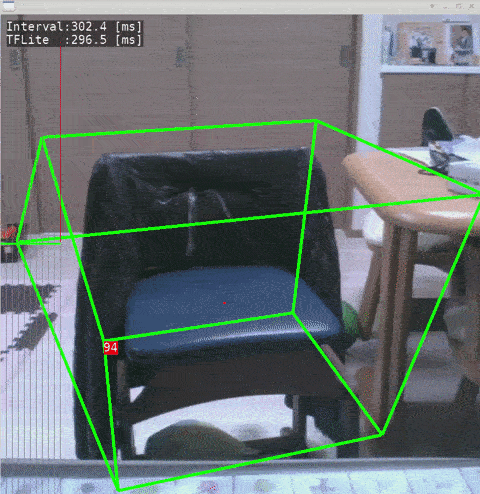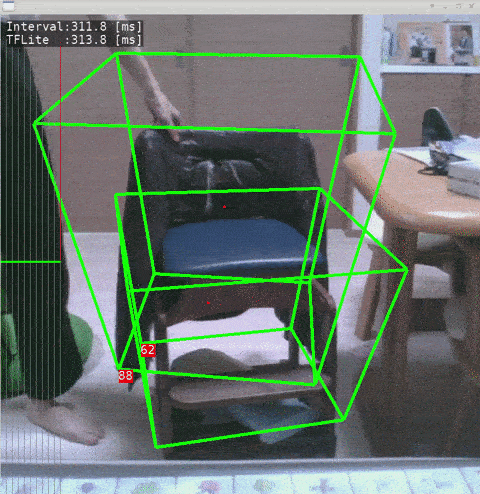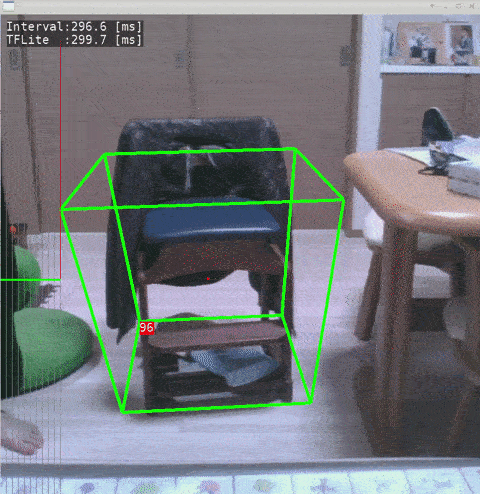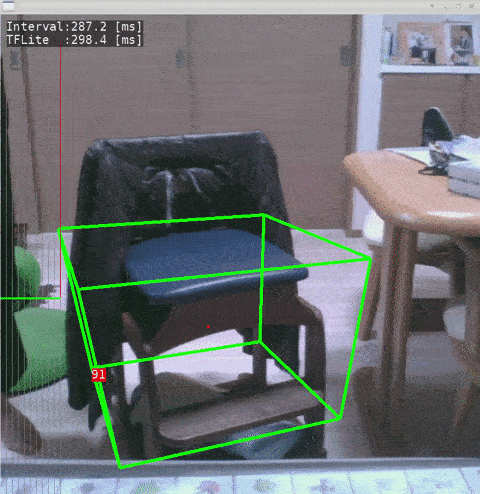

- Ubuntu 18.04 x86_64
- OpenVINO 2020.2
- Python
- Core i7 (CPU only)
- USB Camera, 640x480
- Test Code - objectron-3d-object-detection-openvino - @yas-sim


- RaspberryPi4
- Ubuntu 19.10 aarch64
- Tensorflow Lite
- C/C++
- OpenGL
- USB Camera, 640x480
$ v4l2-ctl --set-fmt-video=width=640,height=480,pixelformat=YUYV- Test Code - tflite_gles_app - gl2blazeface - @terryky


Sample.9 - MediaPipe/Hand_Detection_and_Tracking(3D Hand Pose), hand_landmark_3d_256_integer_quant.tflite + palm_detection_builtin_256_integer_quant.tflite
- RaspberryPi4
- Tensorflow Lite
- C/C++
- OpenGL
- Test Code - tflite_gles_app - gl2handpose - @terryky


- Ubuntu 18.04 x86_64
- OpenVINO 2020.2
- Python
- Core i7 (CPU only)
- USB Camera, 640x480
- Test Code - DBFace-on-OpenVINO - @yas-sim


- Ubuntu 18.04 x86_64
- Tensorflow.js
- USB Camera, 640x480
- Test Code - tfjs_webgl_app - @terryky
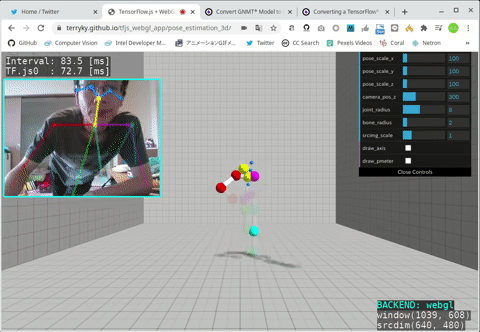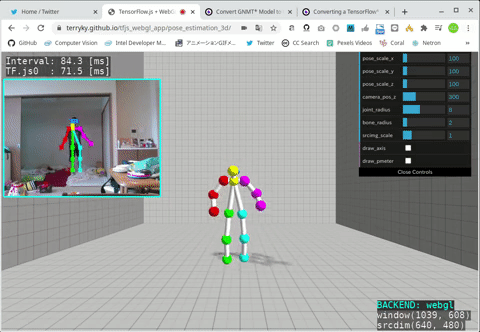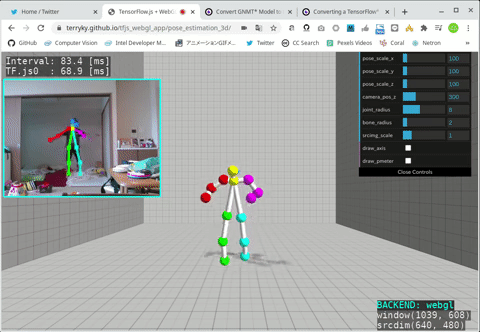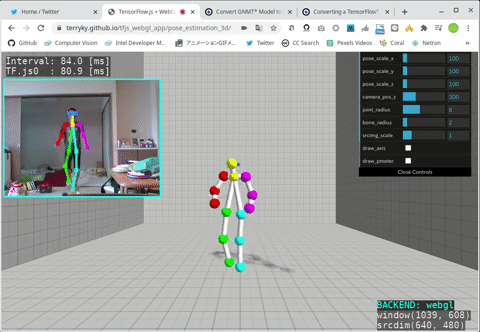

- Ubuntu 18.04 x86_64
- Tensorflow.js
- USB Camera, 640x480
- Test Code - tfjs_webgl_app - @terryky


- Ubuntu 18.04 x86_64
- OpenVINO
- USB Camera, 640x480
- Test Code
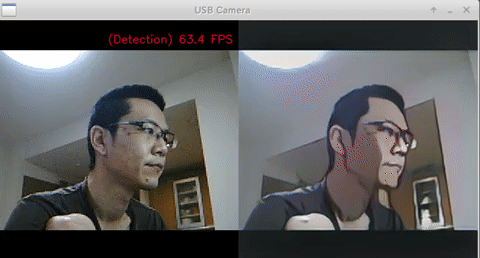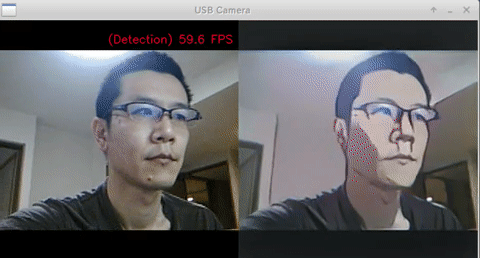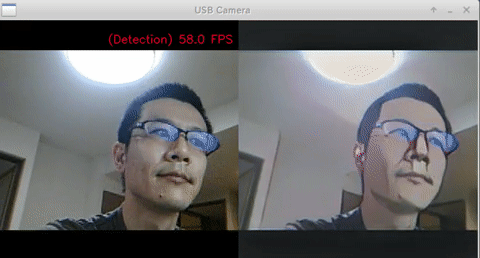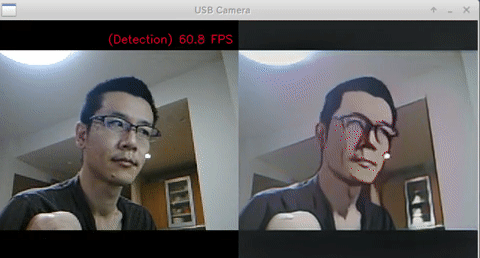

- Ubuntu 18.04 x86_64
- RaspberryPi4 Raspbian Buster 32bit / Raspbian Buster 64bit / Ubuntu 19.10 aarch64
- Tensorflow-GPU v1.15.2 or Tensorflow v2.3.1+
- OpenVINO 2020.2+
- PyTorch 1.6.0+
- ONNX Opset12
- Python 3.6.8
- PascalVOC Dataset
- COCO Dataset
- Cityscapes Dataset
- Imagenette Dataset
- CelebA Dataset
- Audio file (.wav)
- WIDERFACE
- Google Colaboratory
Procedure examples
$ cd ~
$ mkdir deeplab;cd deeplab
$ git clone --depth 1 https://github.com/tensorflow/models.git
$ cd models/research/deeplab/datasets
$ mkdir pascal_voc_seg
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1rATNHizJdVHnaJtt-hW9MOgjxoaajzdh" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1rATNHizJdVHnaJtt-hW9MOgjxoaajzdh" \
-o pascal_voc_seg/VOCtrainval_11-May-2012.tar
$ sed -i -e "s/python .\/remove_gt_colormap.py/python3 .\/remove_gt_colormap.py/g" \
-i -e "s/python .\/build_voc2012_data.py/python3 .\/build_voc2012_data.py/g" \
download_and_convert_voc2012.sh
$ sh download_and_convert_voc2012.sh
$ cd ../..
$ mkdir -p deeplab/datasets/pascal_voc_seg/exp/train_on_train_set/train
$ mkdir -p deeplab/datasets/pascal_voc_seg/exp/train_on_train_set/eval
$ mkdir -p deeplab/datasets/pascal_voc_seg/exp/train_on_train_set/vis
$ export PATH_TO_TRAIN_DIR=${HOME}/deeplab/models/research/deeplab/datasets/pascal_voc_seg/exp/train_on_train_set/train
$ export PATH_TO_DATASET=${HOME}/deeplab/models/research/deeplab/datasets/pascal_voc_seg/tfrecord
$ export PYTHONPATH=${HOME}/deeplab/models/research:${HOME}/deeplab/models/research/deeplab:${HOME}/deeplab/models/research/slim:${PYTHONPATH}# See feature_extractor.network_map for supported model variants.
# models/research/deeplab/core/feature_extractor.py
networks_map = {
'mobilenet_v2': _mobilenet_v2,
'mobilenet_v3_large_seg': mobilenet_v3_large_seg,
'mobilenet_v3_small_seg': mobilenet_v3_small_seg,
'resnet_v1_18': resnet_v1_beta.resnet_v1_18,
'resnet_v1_18_beta': resnet_v1_beta.resnet_v1_18_beta,
'resnet_v1_50': resnet_v1_beta.resnet_v1_50,
'resnet_v1_50_beta': resnet_v1_beta.resnet_v1_50_beta,
'resnet_v1_101': resnet_v1_beta.resnet_v1_101,
'resnet_v1_101_beta': resnet_v1_beta.resnet_v1_101_beta,
'xception_41': xception.xception_41,
'xception_65': xception.xception_65,
'xception_71': xception.xception_71,
'nas_pnasnet': nas_network.pnasnet,
'nas_hnasnet': nas_network.hnasnet,
}$ python3 deeplab/train.py \
--logtostderr \
--training_number_of_steps=500000 \
--train_split="train" \
--model_variant="mobilenet_v3_small_seg" \
--decoder_output_stride=16 \
--train_crop_size="513,513" \
--train_batch_size=8 \
--dataset="pascal_voc_seg" \
--save_interval_secs=300 \
--save_summaries_secs=300 \
--save_summaries_images=True \
--log_steps=100 \
--train_logdir=${PATH_TO_TRAIN_DIR} \
--dataset_dir=${PATH_TO_DATASET}$ python3 deeplab/train.py \
--logtostderr \
--training_number_of_steps=1000000 \
--train_split="train" \
--model_variant="mobilenet_v3_large_seg" \
--decoder_output_stride=16 \
--train_crop_size="513,513" \
--train_batch_size=8 \
--dataset="pascal_voc_seg" \
--save_interval_secs=300 \
--save_summaries_secs=300 \
--save_summaries_images=True \
--log_steps=100 \
--train_logdir=${PATH_TO_TRAIN_DIR} \
--dataset_dir=${PATH_TO_DATASET}$ tensorboard \
--logdir ${HOME}/deeplab/models/research/deeplab/datasets/pascal_voc_seg/exp/train_on_train_set/train
$ cd ~
$ mkdir -p git/deeplab && cd git/deeplab
$ git clone --depth 1 https://github.com/tensorflow/models.git
$ cd models/research/deeplab/datasets
$ mkdir cityscapes && cd cityscapes
# Clone the script to generate Cityscapes Dataset.
$ git clone --depth 1 https://github.com/mcordts/cityscapesScripts.git
$ mv cityscapesScripts cityscapesScripts_ && \
mv cityscapesScripts_/cityscapesscripts . && \
rm -rf cityscapesScripts_
# Download Cityscapes Dataset.
# https://www.cityscapes-dataset.com/
# You will need to sign up and issue a userID and password to download the data set.
$ wget --keep-session-cookies --save-cookies=cookies.txt \
--post-data 'username=(userid)&password=(password)&submit=Login' \
https://www.cityscapes-dataset.com/login/
$ wget --load-cookies cookies.txt \
--content-disposition https://www.cityscapes-dataset.com/file-handling/?packageID=1
$ wget --load-cookies cookies.txt \
--content-disposition https://www.cityscapes-dataset.com/file-handling/?packageID=3
$ unzip gtFine_trainvaltest.zip && rm gtFine_trainvaltest.zip
$ rm README && rm license.txt
$ unzip leftImg8bit_trainvaltest.zip && rm leftImg8bit_trainvaltest.zip
$ rm README && rm license.txt
# Convert Cityscapes Dataset to TFRecords format.
$ cd ..
$ sed -i -e "s/python/python3/g" convert_cityscapes.sh
$ export PYTHONPATH=${HOME}/git/deeplab/models/research/deeplab/datasets/cityscapes:${PYTHONPATH}
$ sh convert_cityscapes.sh
# Create a checkpoint storage folder for training. If training is not required,
# there is no need to carry out.
$ cd ../..
$ mkdir -p deeplab/datasets/cityscapes/exp/train_on_train_set/train && \
mkdir -p deeplab/datasets/cityscapes/exp/train_on_train_set/eval && \
mkdir -p deeplab/datasets/cityscapes/exp/train_on_train_set/vis
# Download the DeepLabV3 trained model of the MobileNetV3 backbone.
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1f5ccaJmJBYwBmHvRQ77yGIUcXnqQIRY_" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1f5ccaJmJBYwBmHvRQ77yGIUcXnqQIRY_" \
-o deeplab_mnv3_small_cityscapes_trainfine_2019_11_15.tar.gz
$ tar -zxvf deeplab_mnv3_small_cityscapes_trainfine_2019_11_15.tar.gz
$ rm deeplab_mnv3_small_cityscapes_trainfine_2019_11_15.tar.gz
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1QxS3G55rUQvuiBF-hztQv5zCkfPfwlVU" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1QxS3G55rUQvuiBF-hztQv5zCkfPfwlVU" \
-o deeplab_mnv3_large_cityscapes_trainfine_2019_11_15.tar.gz
$ tar -zxvf deeplab_mnv3_large_cityscapes_trainfine_2019_11_15.tar.gz
$ rm deeplab_mnv3_large_cityscapes_trainfine_2019_11_15.tar.gz
$ export PATH_TO_INITIAL_CHECKPOINT=${HOME}/git/deeplab/models/research/deeplab_mnv3_small_cityscapes_trainfine/model.ckpt
$ export PATH_TO_DATASET=${HOME}/git/deeplab/models/research/deeplab/datasets/cityscapes/tfrecord
$ export PYTHONPATH=${HOME}/git/deeplab/models/research:${HOME}/git/deeplab/models/research/deeplab:${HOME}/git/deeplab/models/research/slim:${PYTHONPATH}
# Fix a bug in the data generator.
$ sed -i -e \
"s/splits_to_sizes={'train_fine': 2975,/splits_to_sizes={'train': 2975,/g" \
deeplab/datasets/data_generator.py
# Back up the trained model.
$ cd ${HOME}/git/deeplab/models/research
$ cp deeplab/export_model.py deeplab/export_model.py_org
$ cp deeplab_mnv3_small_cityscapes_trainfine/frozen_inference_graph.pb \
deeplab_mnv3_small_cityscapes_trainfine/frozen_inference_graph_org.pb
$ cp deeplab_mnv3_large_cityscapes_trainfine/frozen_inference_graph.pb \
deeplab_mnv3_large_cityscapes_trainfine/frozen_inference_graph_org.pb
# Customize "export_model.py" according to the input resolution. Must be (multiple of 8 + 1).
# (example.1) 769 = 8 * 96 + 1
# (example.2) 512 = 8 * 64 + 1
# (example.3) 320 = 8 * 40 + 1
# And it is necessary to change from tf.uint8 type to tf.float32 type.
$ sed -i -e \
"s/tf.placeholder(tf.uint8, \[1, None, None, 3\], name=_INPUT_NAME)/tf.placeholder(tf.float32, \[1, 769, 769, 3\], name=_INPUT_NAME)/g" \
deeplab/export_model.py# crop_size and image_pooling_crop_size are multiples of --decoder_output_stride + 1
# 769 = 8 * 96 + 1
# 513 = 8 * 64 + 1
# 321 = 8 * 40 + 1
# --initialize_last_layer=True initializes the final layer with the weight of
# tf_initial_checkpoint (inherits the weight)
# Named tuple to describe the dataset properties.
# deeplab/datasets/data_generator.py
DatasetDescriptor = collections.namedtuple(
'DatasetDescriptor',
[
'splits_to_sizes', # Splits of the dataset into training, val and test.
'num_classes', # Number of semantic classes, including the
# background class (if exists). For example, there
# are 20 foreground classes + 1 background class in
# the PASCAL VOC 2012 dataset. Thus, we set
# num_classes=21.
'ignore_label', # Ignore label value.
])
_CITYSCAPES_INFORMATION = DatasetDescriptor(
splits_to_sizes={'train': 2975,
'train_coarse': 22973,
'trainval_fine': 3475,
'trainval_coarse': 23473,
'val_fine': 500,
'test_fine': 1525},
num_classes=19,
ignore_label=255,
)
_PASCAL_VOC_SEG_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 1464,
'train_aug': 10582,
'trainval': 2913,
'val': 1449,
},
num_classes=21,
ignore_label=255,
)
_ADE20K_INFORMATION = DatasetDescriptor(
splits_to_sizes={
'train': 20210, # num of samples in images/training
'val': 2000, # num of samples in images/validation
},
num_classes=151,
ignore_label=0,
)
_DATASETS_INFORMATION = {
'cityscapes': _CITYSCAPES_INFORMATION,
'pascal_voc_seg': _PASCAL_VOC_SEG_INFORMATION,
'ade20k': _ADE20K_INFORMATION,
}
# A map from network name to network function. model_variant.
# deeplab/core/feature_extractor.py
networks_map = {
'mobilenet_v2': _mobilenet_v2,
'mobilenet_v3_large_seg': mobilenet_v3_large_seg,
'mobilenet_v3_small_seg': mobilenet_v3_small_seg,
'resnet_v1_18': resnet_v1_beta.resnet_v1_18,
'resnet_v1_18_beta': resnet_v1_beta.resnet_v1_18_beta,
'resnet_v1_50': resnet_v1_beta.resnet_v1_50,
'resnet_v1_50_beta': resnet_v1_beta.resnet_v1_50_beta,
'resnet_v1_101': resnet_v1_beta.resnet_v1_101,
'resnet_v1_101_beta': resnet_v1_beta.resnet_v1_101_beta,
'xception_41': xception.xception_41,
'xception_65': xception.xception_65,
'xception_71': xception.xception_71,
'nas_pnasnet': nas_network.pnasnet,
'nas_hnasnet': nas_network.hnasnet,
}Generate Freeze Graph (.pb) with INPUT Placeholder changed from checkpoint file (.ckpt).
$ python3 deeplab/export_model.py \
--checkpoint_path=./deeplab_mnv3_small_cityscapes_trainfine/model.ckpt \
--export_path=./deeplab_mnv3_small_cityscapes_trainfine/frozen_inference_graph.pb \
--num_classes=19 \
--crop_size=769 \
--crop_size=769 \
--model_variant="mobilenet_v3_small_seg" \
--image_pooling_crop_size="769,769" \
--image_pooling_stride=4,5 \
--aspp_convs_filters=128 \
--aspp_with_concat_projection=0 \
--aspp_with_squeeze_and_excitation=1 \
--decoder_use_sum_merge=1 \
--decoder_filters=19 \
--decoder_output_is_logits=1 \
--image_se_uses_qsigmoid=1 \
--image_pyramid=1 \
--decoder_output_stride=8Generate Freeze Graph (.pb) with INPUT Placeholder changed from checkpoint file (.ckpt).
$ python3 deeplab/export_model.py \
--checkpoint_path=./deeplab_mnv3_large_cityscapes_trainfine/model.ckpt \
--export_path=./deeplab_mnv3_large_cityscapes_trainfine/frozen_inference_graph.pb \
--num_classes=19 \
--crop_size=769 \
--crop_size=769 \
--model_variant="mobilenet_v3_large_seg" \
--image_pooling_crop_size="769,769" \
--image_pooling_stride=4,5 \
--aspp_convs_filters=128 \
--aspp_with_concat_projection=0 \
--aspp_with_squeeze_and_excitation=1 \
--decoder_use_sum_merge=1 \
--decoder_filters=19 \
--decoder_output_is_logits=1 \
--image_se_uses_qsigmoid=1 \
--image_pyramid=1 \
--decoder_output_stride=8If you follow the Google Colaboratory sample procedure, copy the "deeplab_mnv3_small_cityscapes_trainfine" folder and "deeplab_mnv3_large_cityscapes_trainfine" to your Google Drive "My Drive". It is not necessary if all procedures described in Google Colaboratory are performed in a PC environment.


- Weight Quantization
- Integer Quantization
- Full Integer Quantization
https://colab.research.google.com/drive/1TtCJ-uMNTArpZxrf5DCNbZdn08DsiW8F
$ cd ${HOME}/git/deeplab/models/research
$ export PATH_TO_TRAINED_FLOAT_MODEL=${HOME}/git/deeplab/models/research/deeplab_mnv3_small_cityscapes_trainfine/model.ckpt
$ export PATH_TO_TRAIN_DIR=${HOME}/git/deeplab/models/research/deeplab/datasets/cityscapes/exp/train_on_train_set/train
$ export PATH_TO_DATASET=${HOME}/git/deeplab/models/research/deeplab/datasets/cityscapes/tfrecord
# deeplab_mnv3_small_cityscapes_trainfine
$ python3 deeplab/train.py \
--logtostderr \
--training_number_of_steps=5000 \
--train_split="train" \
--model_variant="mobilenet_v3_small_seg" \
--train_crop_size="769,769" \
--train_batch_size=8 \
--dataset="cityscapes" \
--initialize_last_layer=False \
--base_learning_rate=3e-5 \
--quantize_delay_step=0 \
--image_pooling_crop_size="769,769" \
--image_pooling_stride=4,5 \
--aspp_convs_filters=128 \
--aspp_with_concat_projection=0 \
--aspp_with_squeeze_and_excitation=1 \
--decoder_use_sum_merge=1 \
--decoder_filters=19 \
--decoder_output_is_logits=1 \
--image_se_uses_qsigmoid=1 \
--image_pyramid=1 \
--decoder_output_stride=8 \
--save_interval_secs=300 \
--save_summaries_secs=300 \
--save_summaries_images=True \
--log_steps=100 \
--tf_initial_checkpoint=${PATH_TO_TRAINED_FLOAT_MODEL} \
--train_logdir=${PATH_TO_TRAIN_DIR} \
--dataset_dir=${PATH_TO_DATASET}$ cd ${HOME}/git/deeplab/models/research
$ export PATH_TO_TRAINED_FLOAT_MODEL=${HOME}/git/deeplab/models/research/deeplab_mnv3_large_cityscapes_trainfine/model.ckpt
$ export PATH_TO_TRAIN_DIR=${HOME}/git/deeplab/models/research/deeplab/datasets/cityscapes/exp/train_on_train_set/train
$ export PATH_TO_DATASET=${HOME}/git/deeplab/models/research/deeplab/datasets/cityscapes/tfrecord
# deeplab_mnv3_large_cityscapes_trainfine
$ python3 deeplab/train.py \
--logtostderr \
--training_number_of_steps=4350 \
--train_split="train" \
--model_variant="mobilenet_v3_large_seg" \
--train_crop_size="769,769" \
--train_batch_size=8 \
--dataset="cityscapes" \
--initialize_last_layer=False \
--base_learning_rate=3e-5 \
--quantize_delay_step=0 \
--image_pooling_crop_size="769,769" \
--image_pooling_stride=4,5 \
--aspp_convs_filters=128 \
--aspp_with_concat_projection=0 \
--aspp_with_squeeze_and_excitation=1 \
--decoder_use_sum_merge=1 \
--decoder_filters=19 \
--decoder_output_is_logits=1 \
--image_se_uses_qsigmoid=1 \
--image_pyramid=1 \
--decoder_output_stride=8 \
--save_interval_secs=300 \
--save_summaries_secs=300 \
--save_summaries_images=True \
--log_steps=100 \
--tf_initial_checkpoint=${PATH_TO_TRAINED_FLOAT_MODEL} \
--train_logdir=${PATH_TO_TRAIN_DIR} \
--dataset_dir=${PATH_TO_DATASET}The orange line is "deeplab_mnv3_small_cityscapes_trainfine" loss.
The blue line is "deeplab_mnv3_large_cityscapes_trainfine" loss.

$ cd ${HOME}/git/deeplab/models/research
$ wget http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz
$ tar -zxvf deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz
$ rm deeplabv3_mnv2_dm05_pascal_trainaug_2018_10_01.tar.gz
$ wget http://download.tensorflow.org/models/deeplabv3_mnv2_dm05_pascal_trainval_2018_10_01.tar.gz
$ tar -zxvf deeplabv3_mnv2_dm05_pascal_trainval_2018_10_01.tar.gz
$ rm deeplabv3_mnv2_dm05_pascal_trainval_2018_10_01.tar.gz
$ wget http://download.tensorflow.org/models/deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz
$ tar -zxvf deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz
$ rm deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz
$ sed -i -e \
"s/tf.placeholder(tf.uint8, \[1, None, None, 3\], name=_INPUT_NAME)/tf.placeholder(tf.float32, \[1, 257, 257, 3\], name=_INPUT_NAME)/g" \
deeplab/export_model.py
$ export PYTHONPATH=${HOME}/git/deeplab/models/research:${HOME}/git/deeplab/models/research/deeplab:${HOME}/git/deeplab/models/research/slim:${PYTHONPATH}
$ python3 deeplab/export_model.py \
--checkpoint_path=./deeplabv3_mnv2_dm05_pascal_trainaug/model.ckpt \
--export_path=./deeplabv3_mnv2_dm05_pascal_trainaug/frozen_inference_graph.pb \
--model_variant="mobilenet_v2" \
--crop_size=257 \
--crop_size=257 \
--depth_multiplier=0.5
$ python3 deeplab/export_model.py \
--checkpoint_path=./deeplabv3_mnv2_dm05_pascal_trainval/model.ckpt \
--export_path=./deeplabv3_mnv2_dm05_pascal_trainval/frozen_inference_graph.pb \
--model_variant="mobilenet_v2" \
--crop_size=257 \
--crop_size=257 \
--depth_multiplier=0.5
$ python3 deeplab/export_model.py \
--checkpoint_path=./deeplabv3_mnv2_pascal_train_aug/model.ckpt-30000 \
--export_path=./deeplabv3_mnv2_pascal_train_aug/frozen_inference_graph.pb \
--model_variant="mobilenet_v2" \
--crop_size=257 \
--crop_size=257$ cd ~
$ sudo pip3 install tensorflow-gpu==1.15.0
$ git clone --depth 1 https://github.com/tensorflow/models.git
$ cd models/research
$ git clone https://github.com/cocodataset/cocoapi.git
$ cd cocoapi/PythonAPI
$ make
$ cp -r pycocotools ../..
$ cd ../..
$ wget -O protobuf.zip https://github.com/google/protobuf/releases/download/v3.0.0/protoc-3.0.0-linux-x86_64.zip
$ unzip protobuf.zip
$ ./bin/protoc object_detection/protos/*.proto --python_out=.
$ sudo apt-get install -y protobuf-compiler python3-pil python3-lxml python3-tk
$ sudo -H pip3 install Cython contextlib2 jupyter matplotlib
$ export PYTHONPATH=${PWD}:${PWD}/object_detection:${PWD}/slim:${PYTHONPATH}
$ mkdir -p ssd_mobilenet_v3_small_coco_2019_08_14 && cd ssd_mobilenet_v3_small_coco_2019_08_14
$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1uqaC0Y-yRtzkpu1EuZ3BzOyh9-i_3Qgi" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1uqaC0Y-yRtzkpu1EuZ3BzOyh9-i_3Qgi" -o ssd_mobilenet_v3_small_coco_2019_08_14.tar.gz
$ tar -zxvf ssd_mobilenet_v3_small_coco_2019_08_14.tar.gz
$ rm ssd_mobilenet_v3_small_coco_2019_08_14.tar.gz
$ cd ..
$ mkdir -p ssd_mobilenet_v3_large_coco_2019_08_14 && cd ssd_mobilenet_v3_large_coco_2019_08_14
$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1NGLjKRWDQZ_kibQHlLZ7Eetuuz1waC7X" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1NGLjKRWDQZ_kibQHlLZ7Eetuuz1waC7X" -o ssd_mobilenet_v3_large_coco_2019_08_14.tar.gz
$ tar -zxvf ssd_mobilenet_v3_large_coco_2019_08_14.tar.gz
$ rm ssd_mobilenet_v3_large_coco_2019_08_14.tar.gz
$ cd ..import tensorflow as tf
import os
import shutil
from tensorflow.python.saved_model import tag_constants
from tensorflow.python.tools import freeze_graph
from tensorflow.python import ops
from tensorflow.tools.graph_transforms import TransformGraph
def freeze_model(saved_model_dir, output_node_names, output_filename):
output_graph_filename = os.path.join(saved_model_dir, output_filename)
initializer_nodes = ''
freeze_graph.freeze_graph(
input_saved_model_dir=saved_model_dir,
output_graph=output_graph_filename,
saved_model_tags = tag_constants.SERVING,
output_node_names=output_node_names,
initializer_nodes=initializer_nodes,
input_graph=None,
input_saver=False,
input_binary=False,
input_checkpoint=None,
restore_op_name=None,
filename_tensor_name=None,
clear_devices=True,
input_meta_graph=False,
)
def get_graph_def_from_file(graph_filepath):
tf.reset_default_graph()
with ops.Graph().as_default():
with tf.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
return graph_def
def optimize_graph(model_dir, graph_filename, transforms, input_name, output_names, outname='optimized_model.pb'):
input_names = [input_name] # change this as per how you have saved the model
graph_def = get_graph_def_from_file(os.path.join(model_dir, graph_filename))
optimized_graph_def = TransformGraph(
graph_def,
input_names,
output_names,
transforms)
tf.train.write_graph(optimized_graph_def,
logdir=model_dir,
as_text=False,
name=outname)
print('Graph optimized!')
def convert_graph_def_to_saved_model(export_dir, graph_filepath, input_name, outputs):
graph_def = get_graph_def_from_file(graph_filepath)
with tf.Session(graph=tf.Graph()) as session:
tf.import_graph_def(graph_def, name='')
tf.compat.v1.saved_model.simple_save(
session,
export_dir,# change input_image to node.name if you know the name
inputs={input_name: session.graph.get_tensor_by_name('{}:0'.format(node.name))
for node in graph_def.node if node.op=='Placeholder'},
outputs={t.rstrip(":0"):session.graph.get_tensor_by_name(t) for t in outputs}
)
print('Optimized graph converted to SavedModel!')
tf.compat.v1.enable_eager_execution()
# Look up the name of the placeholder for the input node
graph_def=get_graph_def_from_file('./ssd_mobilenet_v3_small_coco_2019_08_14/frozen_inference_graph.pb')
input_name_small=""
for node in graph_def.node:
if node.op=='Placeholder':
print("##### ssd_mobilenet_v3_small_coco_2019_08_14 - Input Node Name #####", node.name) # this will be the input node
input_name_small=node.name
# Look up the name of the placeholder for the input node
graph_def=get_graph_def_from_file('./ssd_mobilenet_v3_large_coco_2019_08_14/frozen_inference_graph.pb')
input_name_large=""
for node in graph_def.node:
if node.op=='Placeholder':
print("##### ssd_mobilenet_v3_large_coco_2019_08_14 - Input Node Name #####", node.name) # this will be the input node
input_name_large=node.name
# ssd_mobilenet_v3 output names
output_node_names = ['raw_outputs/class_predictions','raw_outputs/box_encodings']
outputs = ['raw_outputs/class_predictions:0','raw_outputs/box_encodings:0']
# Optimizing the graph via TensorFlow library
transforms = []
optimize_graph('./ssd_mobilenet_v3_small_coco_2019_08_14', 'frozen_inference_graph.pb', transforms, input_name_small, output_node_names, outname='optimized_model_small.pb')
optimize_graph('./ssd_mobilenet_v3_large_coco_2019_08_14', 'frozen_inference_graph.pb', transforms, input_name_large, output_node_names, outname='optimized_model_large.pb')
# convert this to a s TF Serving compatible mode - ssd_mobilenet_v3_small_coco_2019_08_14
shutil.rmtree('./ssd_mobilenet_v3_small_coco_2019_08_14/0', ignore_errors=True)
convert_graph_def_to_saved_model('./ssd_mobilenet_v3_small_coco_2019_08_14/0',
'./ssd_mobilenet_v3_small_coco_2019_08_14/optimized_model_small.pb', input_name_small, outputs)
# convert this to a s TF Serving compatible mode - ssd_mobilenet_v3_large_coco_2019_08_14
shutil.rmtree('./ssd_mobilenet_v3_large_coco_2019_08_14/0', ignore_errors=True)
convert_graph_def_to_saved_model('./ssd_mobilenet_v3_large_coco_2019_08_14/0',
'./ssd_mobilenet_v3_large_coco_2019_08_14/optimized_model_large.pb', input_name_large, outputs)$ saved_model_cli show --dir ./ssd_mobilenet_v3_small_coco_2019_08_14/0 --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['normalized_input_image_tensor'] tensor_info:
dtype: DT_FLOAT
shape: (1, 320, 320, 3)
name: normalized_input_image_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['raw_outputs/box_encodings'] tensor_info:
dtype: DT_FLOAT
shape: (1, 2034, 4)
name: raw_outputs/box_encodings:0
outputs['raw_outputs/class_predictions'] tensor_info:
dtype: DT_FLOAT
shape: (1, 2034, 91)
name: raw_outputs/class_predictions:0
Method name is: tensorflow/serving/predict$ saved_model_cli show --dir ./ssd_mobilenet_v3_large_coco_2019_08_14/0 --all
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['normalized_input_image_tensor'] tensor_info:
dtype: DT_FLOAT
shape: (1, 320, 320, 3)
name: normalized_input_image_tensor:0
The given SavedModel SignatureDef contains the following output(s):
outputs['raw_outputs/box_encodings'] tensor_info:
dtype: DT_FLOAT
shape: (1, 2034, 4)
name: raw_outputs/box_encodings:0
outputs['raw_outputs/class_predictions'] tensor_info:
dtype: DT_FLOAT
shape: (1, 2034, 91)
name: raw_outputs/class_predictions:0
Method name is: tensorflow/serving/predict$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1Uk9F4Tc-9UgnvARIVkloSoePUynyST6E" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1Uk9F4Tc-9UgnvARIVkloSoePUynyST6E" -o TFDS.tar.gz
$ tar -zxvf TFDS.tar.gz
$ rm TFDS.tar.gzimport tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (320, 320))
image = image[np.newaxis,:,:,:]
yield [image]
tf.compat.v1.enable_eager_execution()
# Generating a calibration data set
#raw_test_data, info = tfds.load(name="coco/2017", with_info=True, split="test", data_dir="./TFDS")
raw_test_data, info = tfds.load(name="coco/2017", with_info=True, split="test", data_dir="./TFDS", download=False)
print(info)
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./ssd_mobilenet_v3_small_coco_2019_08_14/0')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('./ssd_mobilenet_v3_small_coco_2019_08_14/mobilenet_v3_small_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - mobilenet_v3_small_weight_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./ssd_mobilenet_v3_small_coco_2019_08_14/0')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./ssd_mobilenet_v3_small_coco_2019_08_14/mobilenet_v3_small_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - mobilenet_v3_small_integer_quant.tflite")
# Full Integer Quantization - Input/Output=int8
converter = tf.lite.TFLiteConverter.from_saved_model('./ssd_mobilenet_v3_small_coco_2019_08_14/0')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_quant_model = converter.convert()
with open('./ssd_mobilenet_v3_small_coco_2019_08_14/mobilenet_v3_small_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - mobilenet_v3_small_full_integer_quant.tflite")import tensorflow as tf
import tensorflow_datasets as tfds
import numpy as np
def representative_dataset_gen():
for data in raw_test_data.take(100):
image = data['image'].numpy()
image = tf.image.resize(image, (320, 320))
image = image[np.newaxis,:,:,:]
yield [image]
tf.compat.v1.enable_eager_execution()
# Generating a calibration data set
#raw_test_data, info = tfds.load(name="coco/2017", with_info=True, split="test", data_dir="./TFDS")
raw_test_data, info = tfds.load(name="coco/2017", with_info=True, split="test", data_dir="./TFDS", download=False)
# Weight Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./ssd_mobilenet_v3_large_coco_2019_08_14/0')
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
tflite_quant_model = converter.convert()
with open('./ssd_mobilenet_v3_large_coco_2019_08_14/mobilenet_v3_large_weight_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Weight Quantization complete! - mobilenet_v3_large_weight_quant.tflite")
# Integer Quantization - Input/Output=float32
converter = tf.lite.TFLiteConverter.from_saved_model('./ssd_mobilenet_v3_large_coco_2019_08_14/0')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
tflite_quant_model = converter.convert()
with open('./ssd_mobilenet_v3_large_coco_2019_08_14/mobilenet_v3_large_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Integer Quantization complete! - mobilenet_v3_large_integer_quant.tflite")
# Full Integer Quantization - Input/Output=int8
converter = tf.lite.TFLiteConverter.from_saved_model('./ssd_mobilenet_v3_large_coco_2019_08_14/0')
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.representative_dataset = representative_dataset_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_quant_model = converter.convert()
with open('./ssd_mobilenet_v3_large_coco_2019_08_14/mobilenet_v3_large_full_integer_quant.tflite', 'wb') as w:
w.write(tflite_quant_model)
print("Full Integer Quantization complete! - mobilenet_v3_large_full_integer_quant.tflite")Learning with the MobileNetV2-SSDLite Pascal-VOC dataset [Remake of Docker version]
06_mobilenetv2-ssdlite/02_voc/01_float32/00_export_tflite_model.txt
06_mobilenetv2-ssdlite/02_voc/01_float32/03_integer_quantization_with_postprocess.py
$ sudo apt-get install python-future
## Bazel for Ubuntu18.04 x86_64 install
$ wget https://github.com/bazelbuild/bazel/releases/download/2.0.0/bazel-2.0.0-installer-linux-x86_64.sh
$ sudo chmod +x bazel-2.0.0-installer-linux-x86_64.sh
$ ./bazel-2.0.0-installer-linux-x86_64.sh
$ sudo apt-get install -y openjdk-8-jdk
## Bazel for RaspberryPi3/4 Raspbian/Debian Buster armhf install
$ wget https://github.com/PINTO0309/Bazel_bin/raw/main/3.1.0/Raspbian_Debian_Buster_armhf/openjdk-8-jdk/install.sh
$ ./install.sh
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1LQUSal55R6fmawZS9zZuk6-5ZFOdUqRK" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1LQUSal55R6fmawZS9zZuk6-5ZFOdUqRK" \
-o adoptopenjdk-8-hotspot_8u222-b10-2_armhf.deb
$ sudo apt-get install -y ./adoptopenjdk-8-hotspot_8u222-b10-2_armhf.deb
## Bazel for RaspberryPi3/4 Raspbian/Debian Buster aarch64 install
$ wget https://github.com/PINTO0309/Bazel_bin/raw/main/3.1.0/Raspbian_Debian_Buster_aarch64/openjdk-8-jdk/install.sh
$ ./install.sh
$ curl -sc /tmp/cookie \
"https://drive.google.com/uc?export=download&id=1VwLxzT3EOTbhSzwvRF2H4ChTQyTQBt3x" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie \
"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1VwLxzT3EOTbhSzwvRF2H4ChTQyTQBt3x" \
-o adoptopenjdk-8-hotspot_8u222-b10-2_arm64.deb
$ sudo apt-get install -y ./adoptopenjdk-8-hotspot_8u222-b10-2_arm64.deb
## Clone Tensorflow v2.1.0+
$ git clone --depth 1 https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
## Build and run TFLite Model Benchmark Tool
$ bazel run -c opt tensorflow/lite/tools/benchmark:benchmark_model -- \
--graph=${HOME}/Downloads/deeplabv3_257_mv_gpu.tflite \
--num_threads=4 \
--warmup_runs=1 \
--enable_op_profiling=true
$ bazel run -c opt tensorflow/lite/tools/benchmark:benchmark_model -- \
--graph=${HOME}/Downloads/deeplabv3_257_mv_gpu.tflite \
--num_threads=4 \
--warmup_runs=1 \
--use_xnnpack=true \
--enable_op_profiling=true
$ bazel run \
-c opt \
--config=noaws \
--config=nohdfs \
--config=nonccl \
tensorflow/lite/tools/benchmark:benchmark_model_plus_flex -- \
--graph=${HOME}/git/tf-monodepth2/monodepth2_flexdelegate_weight_quant.tflite \
--num_threads=4 \
--warmup_runs=1 \
--enable_op_profiling=true
$ bazel run \
-c opt \
--config=noaws \
--config=nohdfs \
--config=nonccl \
tensorflow/lite/tools/benchmark:benchmark_model_plus_flex -- \
--graph=${HOME}/git/tf-monodepth2/monodepth2_flexdelegate_weight_quant.tflite \
--num_threads=4 \
--warmup_runs=1 \
--use_xnnpack=true \
--enable_op_profiling=truex86_64 deeplab_mnv3_small_weight_quant_769.tflite Benchmark
Number of nodes executed: 171
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 45 1251.486 67.589% 67.589% 0.000 0
DEPTHWISE_CONV_2D 11 438.764 23.696% 91.286% 0.000 0
HARD_SWISH 16 54.855 2.963% 94.248% 0.000 0
ARG_MAX 1 24.850 1.342% 95.591% 0.000 0
RESIZE_BILINEAR 5 23.805 1.286% 96.876% 0.000 0
MUL 30 14.914 0.805% 97.682% 0.000 0
ADD 18 10.646 0.575% 98.257% 0.000 0
SPACE_TO_BATCH_ND 7 9.567 0.517% 98.773% 0.000 0
BATCH_TO_SPACE_ND 7 7.431 0.401% 99.175% 0.000 0
SUB 2 6.131 0.331% 99.506% 0.000 0
AVERAGE_POOL_2D 10 5.435 0.294% 99.799% 0.000 0
RESHAPE 6 2.171 0.117% 99.916% 0.000 0
PAD 1 0.660 0.036% 99.952% 0.000 0
CAST 2 0.601 0.032% 99.985% 0.000 0
STRIDED_SLICE 1 0.277 0.015% 100.000% 0.000 0
Misc Runtime Ops 1 0.008 0.000% 100.000% 33.552 0
DEQUANTIZE 8 0.000 0.000% 100.000% 0.000 0
Timings (microseconds): count=52 first=224 curr=1869070 min=224 max=2089397 avg=1.85169e+06 std=373988
Memory (bytes): count=0
171 nodes observedx86_64 deeplab_mnv3_large_weight_quant_769.tflite Benchmark
Number of nodes executed: 194
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 51 4123.348 82.616% 82.616% 0.000 0
DEPTHWISE_CONV_2D 15 628.139 12.586% 95.202% 0.000 0
HARD_SWISH 15 90.448 1.812% 97.014% 0.000 0
MUL 32 29.393 0.589% 97.603% 0.000 0
ARG_MAX 1 22.866 0.458% 98.061% 0.000 0
ADD 25 22.860 0.458% 98.519% 0.000 0
RESIZE_BILINEAR 5 22.494 0.451% 98.970% 0.000 0
SPACE_TO_BATCH_ND 8 18.518 0.371% 99.341% 0.000 0
BATCH_TO_SPACE_ND 8 15.522 0.311% 99.652% 0.000 0
AVERAGE_POOL_2D 9 7.855 0.157% 99.809% 0.000 0
SUB 2 5.896 0.118% 99.928% 0.000 0
RESHAPE 6 2.133 0.043% 99.970% 0.000 0
PAD 1 0.631 0.013% 99.983% 0.000 0
CAST 2 0.575 0.012% 99.994% 0.000 0
STRIDED_SLICE 1 0.260 0.005% 100.000% 0.000 0
Misc Runtime Ops 1 0.012 0.000% 100.000% 38.304 0
DEQUANTIZE 12 0.003 0.000% 100.000% 0.000 0
Timings (microseconds): count=31 first=193 curr=5276579 min=193 max=5454605 avg=4.99104e+06 std=1311782
Memory (bytes): count=0
194 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 deeplab_v3_plus_mnv3_decoder_256_integer_quant.tflite Benchmark
Number of nodes executed: 180
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 38 37.595 45.330% 45.330% 0.000 38
ADD 37 12.319 14.854% 60.184% 0.000 37
DEPTHWISE_CONV_2D 17 11.424 13.774% 73.958% 0.000 17
RESIZE_BILINEAR 4 7.336 8.845% 82.804% 0.000 4
MUL 9 4.204 5.069% 87.873% 0.000 9
QUANTIZE 13 3.976 4.794% 92.667% 0.000 13
AVERAGE_POOL_2D 9 1.809 2.181% 94.848% 0.000 9
DIV 9 1.167 1.407% 96.255% 0.000 9
ARG_MAX 1 1.137 1.371% 97.626% 0.000 1
CONCATENATION 2 0.780 0.940% 98.566% 0.000 2
FULLY_CONNECTED 16 0.715 0.862% 99.428% 0.000 16
DEQUANTIZE 9 0.473 0.570% 99.999% 0.000 9
RESHAPE 16 0.001 0.001% 100.000% 0.000 16
Timings (microseconds): count=50 first=83065 curr=82874 min=82675 max=85743 avg=83036 std=499
Memory (bytes): count=0
180 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 deeplab_v3_plus_mnv2_decoder_256_integer_quant.tflite Benchmark
Number of nodes executed: 81
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 41 47.427 65.530% 65.530% 0.000 41
DEPTHWISE_CONV_2D 19 11.114 15.356% 80.887% 0.000 19
RESIZE_BILINEAR 4 7.342 10.145% 91.031% 0.000 4
QUANTIZE 3 2.953 4.080% 95.112% 0.000 3
ADD 10 1.633 2.256% 97.368% 0.000 10
ARG_MAX 1 1.137 1.571% 98.939% 0.000 1
CONCATENATION 2 0.736 1.017% 99.956% 0.000 2
AVERAGE_POOL_2D 1 0.032 0.044% 100.000% 0.000 1
Timings (microseconds): count=50 first=72544 curr=72425 min=72157 max=72745 avg=72412.9 std=137
Memory (bytes): count=0
81 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 mobilenet_v3_small_full_integer_quant.tflite Benchmark
Number of nodes executed: 176
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 61 10.255 36.582% 36.582% 0.000 61
DEPTHWISE_CONV_2D 27 5.058 18.043% 54.625% 0.000 27
MUL 26 5.056 18.036% 72.661% 0.000 26
ADD 14 4.424 15.781% 88.442% 0.000 14
QUANTIZE 13 1.633 5.825% 94.267% 0.000 13
HARD_SWISH 10 0.918 3.275% 97.542% 0.000 10
LOGISTIC 1 0.376 1.341% 98.883% 0.000 1
AVERAGE_POOL_2D 9 0.199 0.710% 99.593% 0.000 9
CONCATENATION 2 0.084 0.300% 99.893% 0.000 2
RESHAPE 13 0.030 0.107% 100.000% 0.000 13
Timings (microseconds): count=50 first=28827 curr=28176 min=27916 max=28827 avg=28121.2 std=165
Memory (bytes): count=0
176 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 mobilenet_v3_small_weight_quant.tflite Benchmark
Number of nodes executed: 186
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 61 82.600 79.265% 79.265% 0.000 61
DEPTHWISE_CONV_2D 27 8.198 7.867% 87.132% 0.000 27
MUL 26 4.866 4.670% 91.802% 0.000 26
ADD 14 4.863 4.667% 96.469% 0.000 14
LOGISTIC 1 1.645 1.579% 98.047% 0.000 1
AVERAGE_POOL_2D 9 0.761 0.730% 98.777% 0.000 9
HARD_SWISH 10 0.683 0.655% 99.433% 0.000 10
CONCATENATION 2 0.415 0.398% 99.831% 0.000 2
RESHAPE 13 0.171 0.164% 99.995% 0.000 13
DEQUANTIZE 23 0.005 0.005% 100.000% 0.000 23
Timings (microseconds): count=50 first=103867 curr=103937 min=103708 max=118926 avg=104299 std=2254
Memory (bytes): count=0
186 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 Posenet model-mobilenet_v1_101_257_integer_quant.tflite Benchmark
Number of nodes executed: 38
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 18 31.906 83.360% 83.360% 0.000 0
DEPTHWISE_CONV_2D 13 5.959 15.569% 98.929% 0.000 0
QUANTIZE 1 0.223 0.583% 99.511% 0.000 0
Misc Runtime Ops 1 0.148 0.387% 99.898% 96.368 0
DEQUANTIZE 4 0.030 0.078% 99.976% 0.000 0
LOGISTIC 1 0.009 0.024% 100.000% 0.000 0
Timings (microseconds): count=70 first=519 curr=53370 min=519 max=53909 avg=38296 std=23892
Memory (bytes): count=0
38 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 MobileNetV2-SSDLite ssdlite_mobilenet_v2_coco_300_integer_quant.tflite Benchmark
Number of nodes executed: 128
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 55 27.253 71.185% 71.185% 0.000 0
DEPTHWISE_CONV_2D 33 8.024 20.959% 92.143% 0.000 0
ADD 10 1.565 4.088% 96.231% 0.000 0
QUANTIZE 11 0.546 1.426% 97.657% 0.000 0
Misc Runtime Ops 1 0.368 0.961% 98.618% 250.288 0
LOGISTIC 1 0.253 0.661% 99.279% 0.000 0
DEQUANTIZE 2 0.168 0.439% 99.718% 0.000 0
CONCATENATION 2 0.077 0.201% 99.919% 0.000 0
RESHAPE 13 0.031 0.081% 100.000% 0.000 0
Timings (microseconds): count=70 first=1289 curr=53049 min=1289 max=53590 avg=38345.2 std=23436
Memory (bytes): count=0
128 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 ml-sound-classifier mobilenetv2_fsd2018_41cls_weight_quant.tflite Benchmark
Number of nodes executed: 111
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
MINIMUM 35 10.020 45.282% 45.282% 0.000 35
CONV_2D 34 8.376 37.852% 83.134% 0.000 34
DEPTHWISE_CONV_2D 18 1.685 7.615% 90.749% 0.000 18
MEAN 1 1.422 6.426% 97.176% 0.000 1
FULLY_CONNECTED 2 0.589 2.662% 99.837% 0.000 2
ADD 10 0.031 0.140% 99.977% 0.000 10
SOFTMAX 1 0.005 0.023% 100.000% 0.000 1
DEQUANTIZE 10 0.000 0.000% 100.000% 0.000 10
Timings (microseconds): count=50 first=22417 curr=22188 min=22041 max=22417 avg=22182 std=70
Memory (bytes): count=0
111 nodes observedUbuntu 19.10 aarch64 + RaspberryPi4 ml-sound-classifier mobilenetv2_fsd2018_41cls_integer_quant.tflite Benchmark
Number of nodes executed: 173
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
QUANTIZE 70 1.117 23.281% 23.281% 0.000 0
MINIMUM 35 1.104 23.010% 46.290% 0.000 0
CONV_2D 34 0.866 18.049% 64.339% 0.000 0
MEAN 1 0.662 13.797% 78.137% 0.000 0
DEPTHWISE_CONV_2D 18 0.476 9.921% 88.058% 0.000 0
FULLY_CONNECTED 2 0.251 5.231% 93.289% 0.000 0
Misc Runtime Ops 1 0.250 5.211% 98.499% 71.600 0
ADD 10 0.071 1.480% 99.979% 0.000 0
SOFTMAX 1 0.001 0.021% 100.000% 0.000 0
DEQUANTIZE 1 0.000 0.000% 100.000% 0.000 0
Timings (microseconds): count=198 first=477 curr=9759 min=477 max=10847 avg=4876.6 std=4629
Memory (bytes): count=0
173 nodes observedRaspbian Buster aarch64 + RaspberryPi4 deeplabv3_mnv2_pascal_trainval_257_integer_quant.tflite Benchmark
Number of nodes executed: 82
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 38 103.576 56.077% 56.077% 0.000 38
DEPTHWISE_CONV_2D 17 33.151 17.948% 74.026% 0.000 17
RESIZE_BILINEAR 3 15.143 8.199% 82.224% 0.000 3
SUB 2 10.908 5.906% 88.130% 0.000 2
ADD 11 9.821 5.317% 93.447% 0.000 11
ARG_MAX 1 8.824 4.777% 98.225% 0.000 1
PAD 1 1.024 0.554% 98.779% 0.000 1
QUANTIZE 2 0.941 0.509% 99.289% 0.000 2
MUL 1 0.542 0.293% 99.582% 0.000 1
CONCATENATION 1 0.365 0.198% 99.780% 0.000 1
AVERAGE_POOL_2D 1 0.150 0.081% 99.861% 0.000 1
RESHAPE 2 0.129 0.070% 99.931% 0.000 2
EXPAND_DIMS 2 0.128 0.069% 100.000% 0.000 2
Timings (microseconds): count=50 first=201226 curr=176476 min=176476 max=201226 avg=184741 std=4791
Memory (bytes): count=0
82 nodes observedUbuntu 18.04 x86_64 + XNNPACK enabled + 10 Threads deeplabv3_257_mv_gpu.tflite Benchmark
Number of nodes executed: 8
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
DELEGATE 3 6.716 61.328% 61.328% 0.000 3
RESIZE_BILINEAR 3 3.965 36.207% 97.534% 0.000 3
CONCATENATION 1 0.184 1.680% 99.215% 0.000 1
AVERAGE_POOL_2D 1 0.086 0.785% 100.000% 0.000 1
Timings (microseconds): count=91 first=11051 curr=10745 min=10521 max=12552 avg=10955.4 std=352
Memory (bytes): count=0
8 nodes observed
Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion.
Peak memory footprint (MB): init=3.58203 overall=56.0703Ubuntu 18.04 x86_64 + XNNPACK disabled + 10 Threads deeplabv3_257_mv_gpu.tflite Benchmark
Number of nodes executed: 70
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
DEPTHWISE_CONV_2D 17 41.704 68.372% 68.372% 0.000 17
CONV_2D 38 15.932 26.120% 94.491% 0.000 38
RESIZE_BILINEAR 3 3.060 5.017% 99.508% 0.000 3
ADD 10 0.149 0.244% 99.752% 0.000 10
CONCATENATION 1 0.109 0.179% 99.931% 0.000 1
AVERAGE_POOL_2D 1 0.042 0.069% 100.000% 0.000 1
Timings (microseconds): count=50 first=59929 curr=60534 min=59374 max=63695 avg=61031.6 std=1182
Memory (bytes): count=0
70 nodes observed
Note: as the benchmark tool itself affects memory footprint, the following is only APPROXIMATE to the actual memory footprint of the model at runtime. Take the information at your discretion.
Peak memory footprint (MB): init=0 overall=13.7109Ubuntu 18.04 x86_64 + XNNPACK enabled + 4 Threads Faster-Grad-CAM weights_weight_quant.tflite Benchmark
umber of nodes executed: 74
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 31 4.947 77.588% 77.588% 0.000 31
DELEGATE 17 0.689 10.806% 88.394% 0.000 17
DEPTHWISE_CONV_2D 10 0.591 9.269% 97.663% 0.000 10
MEAN 1 0.110 1.725% 99.388% 0.000 1
PAD 5 0.039 0.612% 100.000% 0.000 5
DEQUANTIZE 10 0.000 0.000% 100.000% 0.000 10
Timings (microseconds): count=155 first=6415 curr=6443 min=6105 max=6863 avg=6409.22 std=69
Memory (bytes): count=0
74 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads Faster-Grad-CAM weights_integer_quant.tflite Benchmark
Number of nodes executed: 72
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 35 0.753 34.958% 34.958% 0.000 0
PAD 5 0.395 18.338% 53.296% 0.000 0
MEAN 1 0.392 18.199% 71.495% 0.000 0
Misc Runtime Ops 1 0.282 13.092% 84.587% 89.232 0
DEPTHWISE_CONV_2D 17 0.251 11.653% 96.240% 0.000 0
ADD 10 0.054 2.507% 98.747% 0.000 0
QUANTIZE 1 0.024 1.114% 99.861% 0.000 0
DEQUANTIZE 2 0.003 0.139% 100.000% 0.000 0
Timings (microseconds): count=472 first=564 curr=3809 min=564 max=3950 avg=2188.51 std=1625
Memory (bytes): count=0
72 nodes observedUbuntu 18.04 x86_64 + XNNPACK enabled + 4 Threads EfficientNet-lite efficientnet-lite0-fp32.tflite Benchmark
Number of nodes executed: 5
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
DELEGATE 2 5.639 95.706% 95.706% 0.000 2
FULLY_CONNECTED 1 0.239 4.056% 99.762% 0.000 1
AVERAGE_POOL_2D 1 0.014 0.238% 100.000% 0.000 1
RESHAPE 1 0.000 0.000% 100.000% 0.000 1
Timings (microseconds): count=168 first=5842 curr=5910 min=5749 max=6317 avg=5894.55 std=100
Memory (bytes): count=0
5 nodes observedUbuntu 18.04 x86_64 + XNNPACK enabled + 4 Threads EfficientNet-lite efficientnet-lite4-fp32.tflite Benchmark
Number of nodes executed: 5
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
DELEGATE 2 33.720 99.235% 99.235% 0.000 2
FULLY_CONNECTED 1 0.231 0.680% 99.915% 0.000 1
AVERAGE_POOL_2D 1 0.029 0.085% 100.000% 0.000 1
RESHAPE 1 0.000 0.000% 100.000% 0.000 1
Timings (microseconds): count=50 first=32459 curr=34867 min=31328 max=35730 avg=33983.5 std=1426
Memory (bytes): count=0
5 nodes observedUbuntu 18.04 x86_64 + XNNPACK enabled + 4 Threads White-box-Cartoonization white_box_cartoonization_weight_quant.tflite Benchmark
Number of nodes executed: 47
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 18 10731.842 97.293% 97.293% 0.000 18
LEAKY_RELU 13 236.792 2.147% 99.440% 0.000 13
TfLiteXNNPackDelegate 10 45.534 0.413% 99.853% 0.000 10
RESIZE_BILINEAR 2 11.237 0.102% 99.954% 0.000 2
SUB 3 4.053 0.037% 99.991% 0.000 3
DIV 1 0.977 0.009% 100.000% 0.000 1
Timings (microseconds): count=14 first=10866837 curr=11292015 min=10697744 max=12289882 avg=1.10305e+07 std=406791
Memory (bytes): count=0
47 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads edgetpu_deeplab_257_os16_integer_quant.tflite Benchmark
Number of nodes executed: 91
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 49 54.679 58.810% 58.810% 0.000 49
SUB 2 11.043 11.877% 70.687% 0.000 2
ADD 16 8.909 9.582% 80.269% 0.000 16
ARG_MAX 1 7.184 7.727% 87.996% 0.000 1
RESIZE_BILINEAR 3 6.654 7.157% 95.153% 0.000 3
DEPTHWISE_CONV_2D 13 3.409 3.667% 98.819% 0.000 13
MUL 1 0.548 0.589% 99.408% 0.000 1
QUANTIZE 2 0.328 0.353% 99.761% 0.000 2
RESHAPE 2 0.162 0.174% 99.935% 0.000 2
AVERAGE_POOL_2D 1 0.043 0.046% 99.982% 0.000 1
CONCATENATION 1 0.017 0.018% 100.000% 0.000 1
Timings (microseconds): count=50 first=92752 curr=93058 min=92533 max=94478 avg=93021.2 std=274
Memory (bytes): count=0
91 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads edgetpu_deeplab_257_os32_integer_quant.tflite Benchmark
Number of nodes executed: 91
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 49 39.890 52.335% 52.335% 0.000 49
SUB 2 11.043 14.488% 66.823% 0.000 2
ADD 16 8.064 10.580% 77.403% 0.000 16
ARG_MAX 1 7.011 9.198% 86.601% 0.000 1
RESIZE_BILINEAR 3 6.623 8.689% 95.290% 0.000 3
DEPTHWISE_CONV_2D 13 2.503 3.284% 98.574% 0.000 13
MUL 1 0.544 0.714% 99.288% 0.000 1
QUANTIZE 2 0.313 0.411% 99.698% 0.000 2
RESHAPE 2 0.178 0.234% 99.932% 0.000 2
AVERAGE_POOL_2D 1 0.041 0.054% 99.986% 0.000 1
CONCATENATION 1 0.011 0.014% 100.000% 0.000 1
Timings (microseconds): count=50 first=75517 curr=75558 min=75517 max=97776 avg=76262.5 std=3087
Memory (bytes): count=0
91 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads human_pose_estimation_3d_0001_256x448_integer_quant.tflite Benchmark
Number of nodes executed: 165
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 69 343.433 78.638% 78.638% 0.000 69
PAD 38 51.637 11.824% 90.462% 0.000 38
DEPTHWISE_CONV_2D 14 15.306 3.505% 93.967% 0.000 14
ADD 15 14.535 3.328% 97.295% 0.000 15
ELU 6 5.071 1.161% 98.456% 0.000 6
QUANTIZE 11 4.481 1.026% 99.482% 0.000 11
DEQUANTIZE 9 1.851 0.424% 99.906% 0.000 9
CONCATENATION 3 0.410 0.094% 100.000% 0.000 3
Timings (microseconds): count=50 first=425038 curr=423469 min=421348 max=969226 avg=436808 std=77255
Memory (bytes): count=0
165 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + BlazeFace face_detection_front_128_integer_quant.tflite Benchmark
Number of nodes executed: 79
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
ADD 16 2.155 34.120% 34.120% 0.000 16
CONV_2D 21 2.017 31.935% 66.054% 0.000 21
PAD 11 1.014 16.054% 82.109% 0.000 11
DEPTHWISE_CONV_2D 16 0.765 12.112% 94.221% 0.000 16
QUANTIZE 4 0.186 2.945% 97.166% 0.000 4
MAX_POOL_2D 3 0.153 2.422% 99.588% 0.000 3
DEQUANTIZE 2 0.017 0.269% 99.857% 0.000 2
CONCATENATION 2 0.006 0.095% 99.952% 0.000 2
RESHAPE 4 0.003 0.047% 100.000% 0.000 4
Timings (microseconds): count=144 first=6415 curr=6319 min=6245 max=6826 avg=6359.12 std=69
Memory (bytes): count=0
79 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + ssd_mobilenet_v2_mnasfpn_shared_box_predictor_320_coco_integer_quant.tflite Benchmark
Number of nodes executed: 588
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 119 109.253 52.671% 52.671% 0.000 119
DEPTHWISE_CONV_2D 61 33.838 16.313% 68.984% 0.000 61
TFLite_Detection_PostProcess 1 22.711 10.949% 79.933% 0.000 1
LOGISTIC 1 17.696 8.531% 88.465% 0.000 1
ADD 59 12.300 5.930% 94.395% 0.000 59
RESHAPE 8 4.175 2.013% 96.407% 0.000 8
CONCATENATION 2 3.416 1.647% 98.054% 0.000 2
RESIZE_NEAREST_NEIGHBOR 12 1.873 0.903% 98.957% 0.000 12
MAX_POOL_2D 13 1.363 0.657% 99.614% 0.000 13
MUL 16 0.737 0.355% 99.970% 0.000 16
DEQUANTIZE 296 0.063 0.030% 100.000% 0.000 296
Timings (microseconds): count=50 first=346007 curr=196005 min=192539 max=715157 avg=207709 std=75605
Memory (bytes): count=0
588 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + object_detection_3d_chair_640x480_integer_quant.tflite Benchmark
Number of nodes executed: 126
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 60 146.537 63.805% 63.805% 0.000 60
DEPTHWISE_CONV_2D 26 45.022 19.604% 83.409% 0.000 26
ADD 23 23.393 10.186% 93.595% 0.000 23
TRANSPOSE_CONV 3 9.930 4.324% 97.918% 0.000 3
QUANTIZE 5 3.103 1.351% 99.269% 0.000 5
CONCATENATION 4 1.541 0.671% 99.940% 0.000 4
DEQUANTIZE 3 0.117 0.051% 99.991% 0.000 3
EXP 1 0.018 0.008% 99.999% 0.000 1
NEG 1 0.002 0.001% 100.000% 0.000 1
Timings (microseconds): count=50 first=218224 curr=217773 min=217174 max=649357 avg=229732 std=62952
Memory (bytes): count=0
126 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + ssdlite_mobiledet_cpu_320x320_coco_integer_quant.tflite Benchmark
Number of nodes executed: 288
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 96 22.996 33.342% 33.342% 0.000 96
HARD_SWISH 57 11.452 16.604% 49.946% 0.000 57
MUL 19 9.423 13.662% 63.608% 0.000 19
AVERAGE_POOL_2D 19 8.439 12.236% 75.843% 0.000 19
DEPTHWISE_CONV_2D 35 7.810 11.324% 87.167% 0.000 35
TFLite_Detection_PostProcess 1 5.650 8.192% 95.359% 0.000 1
ADD 12 1.690 2.450% 97.809% 0.000 12
QUANTIZE 12 0.879 1.274% 99.084% 0.000 12
LOGISTIC 20 0.277 0.402% 99.485% 0.000 20
DEQUANTIZE 2 0.234 0.339% 99.825% 0.000 2
CONCATENATION 2 0.079 0.115% 99.939% 0.000 2
RESHAPE 13 0.042 0.061% 100.000% 0.000 13
Timings (microseconds): count=50 first=69091 curr=68590 min=68478 max=83971 avg=69105.3 std=2147
Memory (bytes): count=0
288 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + mobilenet_v2_pose_256_256_dm100_integer_quant.tflite Benchmark
Number of nodes executed: 189
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 86 51.819 70.575% 70.575% 0.000 86
DEPTHWISE_CONV_2D 73 18.207 24.797% 95.372% 0.000 73
ADD 8 1.243 1.693% 97.065% 0.000 8
QUANTIZE 13 1.132 1.542% 98.607% 0.000 13
CONCATENATION 7 0.607 0.827% 99.433% 0.000 7
RESIZE_BILINEAR 1 0.354 0.482% 99.916% 0.000 1
DEQUANTIZE 1 0.062 0.084% 100.000% 0.000 1
Timings (microseconds): count=50 first=73752 curr=73430 min=73191 max=75764 avg=73524.8 std=485
Memory (bytes): count=0
189 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + mobilenet_v2_pose_368_432_dm100_integer_quant.tflite Benchmark
Number of nodes executed: 189
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 86 141.296 69.289% 69.289% 0.000 86
DEPTHWISE_CONV_2D 73 53.244 26.110% 95.399% 0.000 73
QUANTIZE 13 3.059 1.500% 96.899% 0.000 13
ADD 8 3.014 1.478% 98.377% 0.000 8
CONCATENATION 7 2.302 1.129% 99.506% 0.000 7
RESIZE_BILINEAR 1 0.852 0.418% 99.924% 0.000 1
DEQUANTIZE 1 0.155 0.076% 100.000% 0.000 1
Timings (microseconds): count=50 first=189613 curr=579873 min=189125 max=579873 avg=204021 std=70304
Memory (bytes): count=0
189 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + mobilenet_v2_pose_256_256_dm050_integer_quant.tflite Benchmark
Number of nodes executed: 189
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 86 40.952 71.786% 71.786% 0.000 86
DEPTHWISE_CONV_2D 73 13.508 23.679% 95.465% 0.000 73
QUANTIZE 13 1.123 1.969% 97.434% 0.000 13
ADD 8 0.710 1.245% 98.678% 0.000 8
CONCATENATION 7 0.498 0.873% 99.551% 0.000 7
RESIZE_BILINEAR 1 0.193 0.338% 99.890% 0.000 1
DEQUANTIZE 1 0.063 0.110% 100.000% 0.000 1
Timings (microseconds): count=50 first=57027 curr=57048 min=56773 max=58042 avg=57135 std=229
Memory (bytes): count=0
189 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + mobilenet_v2_pose_368_432_dm050_integer_quant.tflite Benchmark
Number of nodes executed: 189
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 86 104.618 71.523% 71.523% 0.000 86
DEPTHWISE_CONV_2D 73 34.527 23.605% 95.128% 0.000 73
QUANTIZE 13 2.572 1.758% 96.886% 0.000 13
CONCATENATION 7 2.257 1.543% 98.429% 0.000 7
ADD 8 1.683 1.151% 99.580% 0.000 8
RESIZE_BILINEAR 1 0.460 0.314% 99.894% 0.000 1
DEQUANTIZE 1 0.155 0.106% 100.000% 0.000 1
Timings (microseconds): count=50 first=172545 curr=146065 min=145260 max=172545 avg=146362 std=3756
Memory (bytes): count=0
189 nodes observedRaspberryPi4 + Ubuntu 19.10 aarch64 + 4 Threads + yolov4_tiny_voc_416x416_integer_quant.tflite Benchmark
Number of nodes executed: 71
============================== Summary by node type ==============================
[Node type] [count] [avg ms] [avg %] [cdf %] [mem KB] [times called]
CONV_2D 21 149.092 61.232% 61.232% 0.000 21
LEAKY_RELU 19 77.644 31.888% 93.121% 0.000 19
PAD 2 8.036 3.300% 96.421% 0.000 2
QUANTIZE 10 4.580 1.881% 98.302% 0.000 10
CONCATENATION 7 2.415 0.992% 99.294% 0.000 7
MAX_POOL_2D 3 0.982 0.403% 99.697% 0.000 3
SPLIT 3 0.615 0.253% 99.950% 0.000 3
DEQUANTIZE 2 0.082 0.034% 99.984% 0.000 2
RESIZE_NEAREST_NEIGHBOR 1 0.032 0.013% 99.997% 0.000 1
STRIDED_SLICE 1 0.004 0.002% 99.998% 0.000 1
MUL 1 0.004 0.002% 100.000% 0.000 1
SHAPE 1 0.000 0.000% 100.000% 0.000 1
Timings (microseconds): count=50 first=233307 curr=233318 min=232446 max=364068 avg=243522 std=33354
Memory (bytes): count=0
71 nodes observed- [deeplab] what's the parameters of the mobilenetv3 pretrained model?
- When you want to fine-tune DeepLab on other datasets, there are a few cases
- [deeplab] Training deeplab model with ADE20K dataset
- Running DeepLab on PASCAL VOC 2012 Semantic Segmentation Dataset
- Quantize DeepLab model for faster on-device inference
- https://github.com/tensorflow/models/blob/main/research/deeplab/g3doc/model_zoo.md
- https://github.com/tensorflow/models/blob/main/research/deeplab/g3doc/quantize.md
- the quantized form of Shape operation is not yet implemented
- Post-training quantization
- Converter command line reference
- Quantization-aware training
- Converting a .pb file to .meta in TF 1.3
- Minimal code to load a trained TensorFlow model from a checkpoint and export it with SavedModelBuilder
- How to restore Tensorflow model from .pb file in python?
- Error with tag-sets when serving model using tensorflow_model_server tool
- ValueError: No 'serving_default' in the SavedModel's SignatureDefs. Possible values are 'name_of_my_model'
- kerasのモデルをデプロイする手順 - Signature作成方法解説
- TensorFlow で学習したモデルのグラフを
tf.train.import_meta_graphでロードする - Tensorflowのグラフ操作 Part1
- Configure input_map when importing a tensorflow model from metagraph file
- TFLite Model Benchmark Tool
- How to install Ubuntu 19.10 aarch64 (64bit) on RaspberryPi4
- https://github.com/rwightman/posenet-python.git
- https://github.com/sayakpaul/Adventures-in-TensorFlow-Lite.git