- Using Azure API Management (APIM) v2 Service with Azure OpenAI (AOAI)
As of January 29, 2024 this repository will be relying on Azure API Mangement Service, v2. There are also significant updates to the APIM Policy Definitions and set-up, which will be detailed below.
NOTE: Previous policies were not reliably switching services on the back-end during retries. This is due to the back-end-service variable being properly updated and reset, as well as the exponential back-off of the retry policy, but not actually updating the endpoint to be retried.
The new policy definitions create a separate API within APIM for each model. This greatly reduces the complexity of the policies and overhead required to run, and maintain, them as there are fewer variables. The polices are much shorter and are more human-readable as well. Separating the models out, each with their own policy, also gives greater flexibility as they can be independently assigned to Product and Subscriptions within APIM.
The complete mapping of regions, models, versions, and the Named values schema used in this repository are all available in this document 2023_12_12_APIM_v2_Update.xlsx. If you follow that same scheme in your deployments everything will be able to be deployed as-is - this is unlikely. I will note areas you may want to customize or change throughout the write-up.
A major inspriation for this repository was the Azure-Samples OpenAI Python Enterprise Logging Repository and the Journey of the Geek blog which demonstrate how to use APIM for logging from set-up to granular chargebacks. I would also recommend using Kirk Hofer's load testing PowerShell script to verify your set-up is valid after completion.
- Incorporation of Load Balancer in Azure API Management and the usage of the Backends
- How-to-use policy fragments
- Additional load-balancing logic
- Re-incorporate logging and provide a write-up
- Address streaming
-
Owner/Administrator Rights to an Azure Subscription
-
At least 1, prefering 2+, Azure OpenAI (AOAI) Resource(s) deployed
a. Record Endpoint(s) for all deployed AOAI Resources
b. Record Keys(s) for all deployed AOAI Resources
-
An Azure API Mangement Service, v2 deployed
-
An Azure OpenAI Inference API Definition
-
An Azure Key Vault deployed
This write-up will walk through the process of creating an Azure API Management Service v2 deployment supported by multiple back-ends in the Azure Portal. Separately, there is a project to make more automated deployments around this same design and can be found in the The Easy Method
The easiest way to copy this exact set-up is to follow the bicep deployment intructions in the Azure OpenAI Landing Zone. Otherwise, to follow along proceed to read the rest of this write-up.
Note: You MUST take steps if you import a raw json spec. It WILL NOT WORK without taking these steps otherwise. The following steps are unnecessary if you important the pre-edited spec copy. The pre-edited spec is ONLY available for the Azure OpenAI API version 2023-12-01-preview.
- Begin by logging into the Azure Portal and navigating to your API Management v2 instance. On the left-hand menu blade, under the APIs heading, select APIs. A menu blade will open in the middle - select + Add API at the top and then, under the Define a new API header, select HTTP, as in the image below:

-
This next step will vary per model - in this case denoted by {deployment_id} in the image below. The convention followed in my build-out is to use the Display Name, Name, and name under which I deploy that model and version combination all be the same. For instance, GPT-4 version 1106, more commonly referred to as GPT-4-Turbo, is deployed as gpt-4-turbo in my AOAI Resources. Therefore I name my API dedicated to that model the same and can refer to it that way when using SDKs without changing my (or any end-user's) behavior pattern. This pattern is repeated for each model that was available for public deployment as of December 19, 2023. The model naming convention used is as follows:
- dall-e-3
- gpt-35-turbo-0301
- gpt-35-turbo-0613
- gpt-35-turbo-1106
- gpt-35-turbo-16k
- gpt-35-turbo-instruct
- gpt-4
- gpt-4-32k
- gpt-4-turbo
- gpt-4v
- text-embedding-ada-002
- whisper
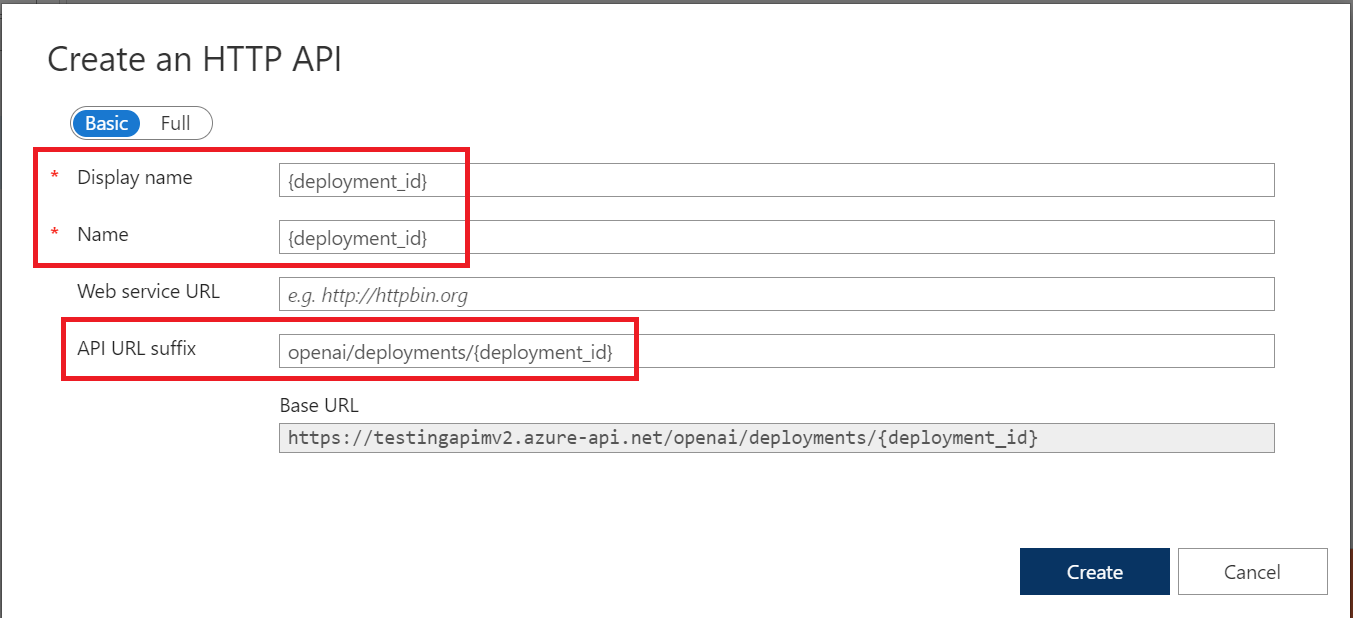
WARNING 1: APIM will read {deployment_id} as a variable!
WARNING 2: The {deployment_id} variable must be changed to what your users expect to be able to call for a model name when using an SDK, for instance:
response = client.chat.completions.create( model={deployment_id}, messages=[ system_role_message, user_message_esg ], stream=False, temperature=aoai_temp_value, top_p=aoai_top_p_value )

Note: You MUST take Steps 3-d through 3-e if you import a raw json spec. This pattern WILL NOT WORK without taking these steps. They are required to allow SDKs to work without reformatting endpoints on the behalf of users. The Pre-edited Spec is ONLY available for the Azure OpenAI API version 2023-12-01-preview version.
-
Once you have created the blank API template with the model name - I will be using gpt-4-turbo going forward - we will need to create the definition for the API. There are two methods (aside from the easy button version at the start of this write-up), both of which I will provide here. They both start the same way and I will cover where they diverge. For the process using the pre-edited API Spec, you can move to the next section after Step #3. If you need to use an API version that is not 2023-12-01-preview you will need to follow the additional steps start at #4.
a. Click the 3 dots next to the API you just created (gpt-4-turbo in this example), in the middle menu blade and select Import.
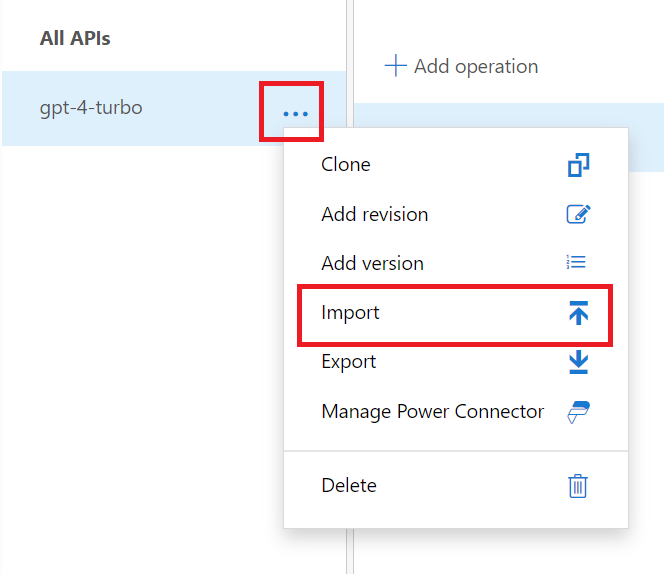
b. Select OpenAI as the API type we wish to import
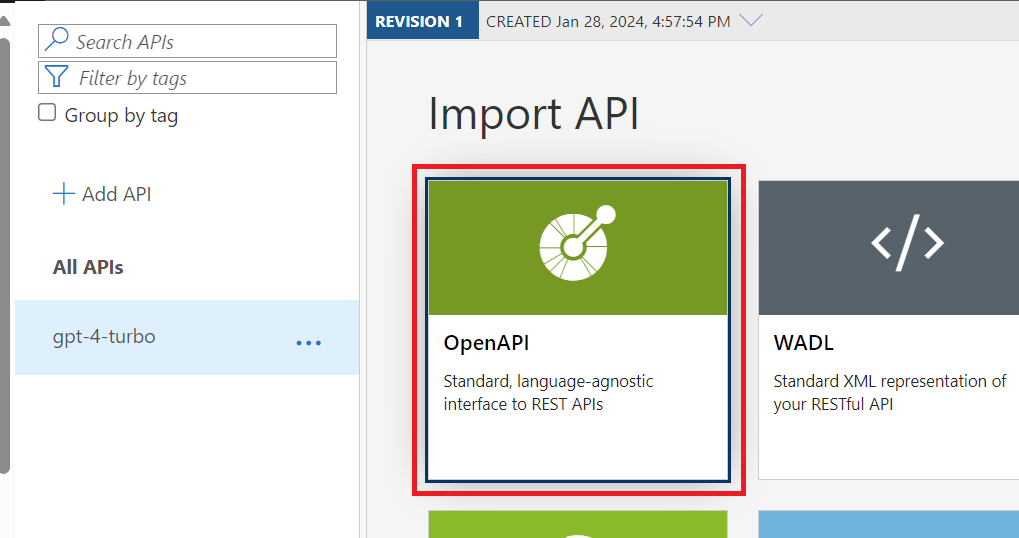
c. Select the Append operation, ensure that Ignore is select for Conflict resolution:, and then Select a File, and then Import a file.
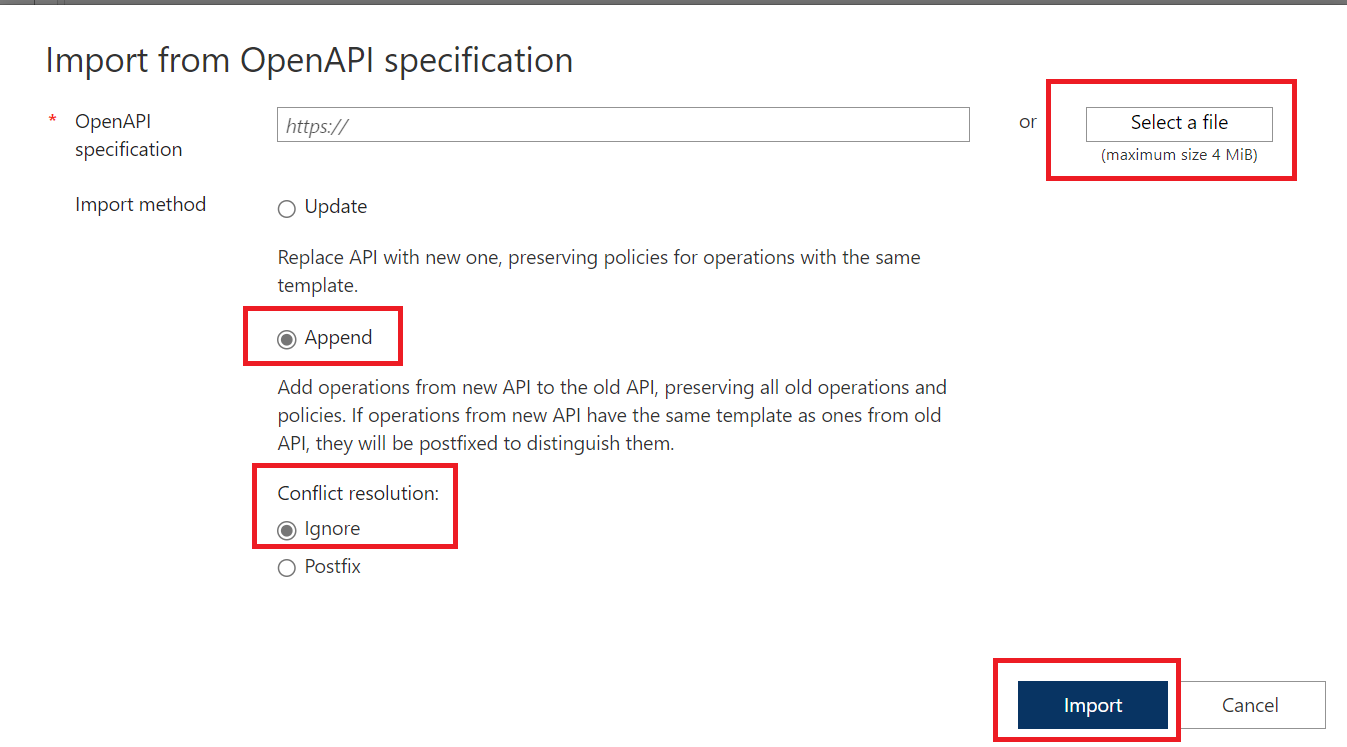
Note: If you import Pre-edited Copy you do not need to do the following steps. However, if you import any of the raw preview of the raw preview or stable specs you will need to undertake the next steps in this section.
d. If you have imported an API spec other than the pre-edited copy, you will need go into each POST operation for the API and remove the Template parameter for deployment-id as follows. First, click on any of the
POSTOperations for the API Spec you just imported. For example, you might choosePOST Creates a completion for the chat messageas in the image below. NOTE: It will show a Template parameters heading and you will see a deplotment-id * marker in the Frontend section on the Design tab of the API. Click on the Pencil Icon to edit as shown below: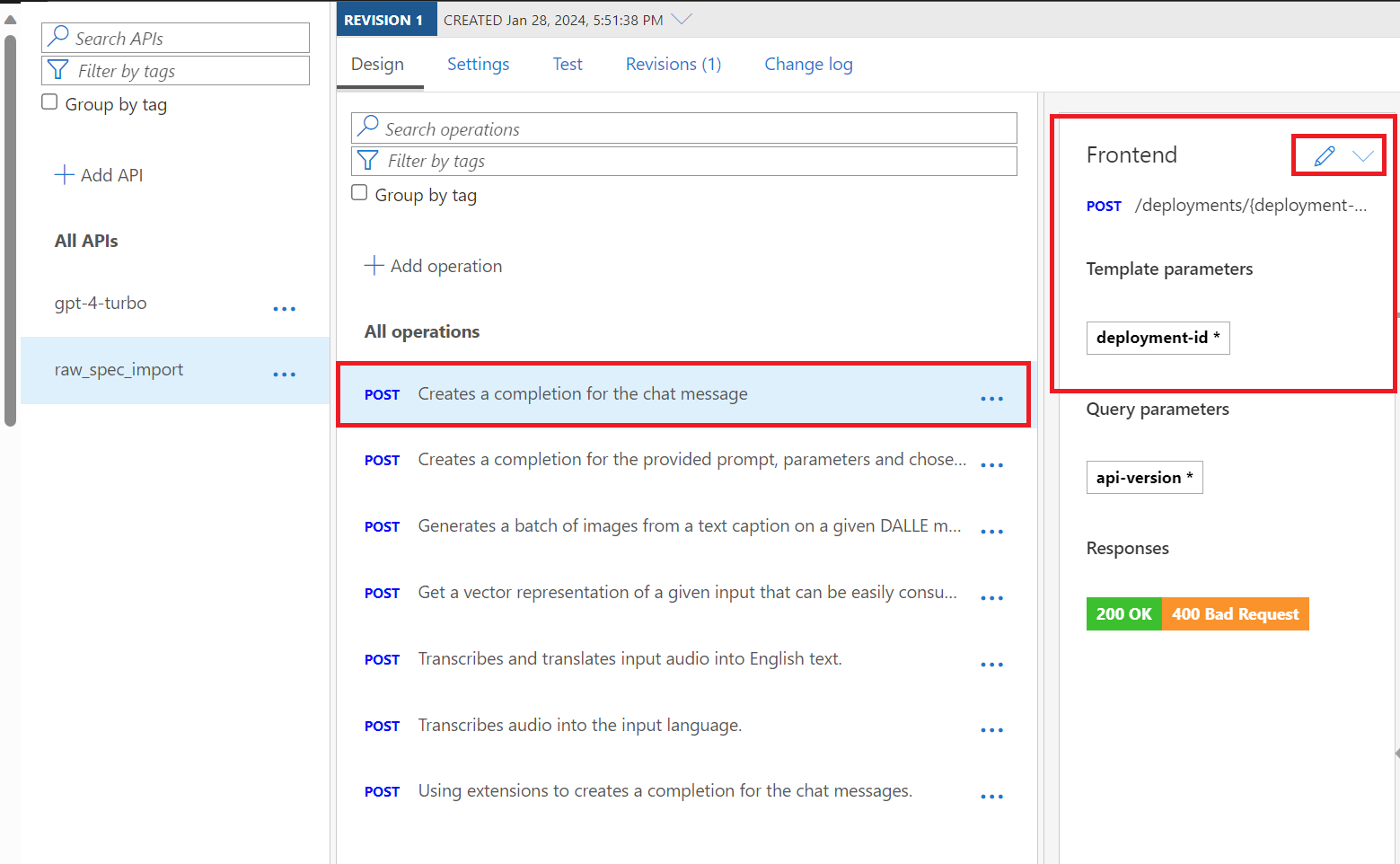
e. We need to remove the Template Parameter for deployment-id and we have two options, both of which are highlighted below. The first, option is to remove the {deployment-id} parameter from the URL Post line where it shows
/deployments/{deployment-id}/chat/completionsso it reads as/deployments/chat/completions. The second option is to click the Tash Can Icon under the Delete header in the Template parameters section.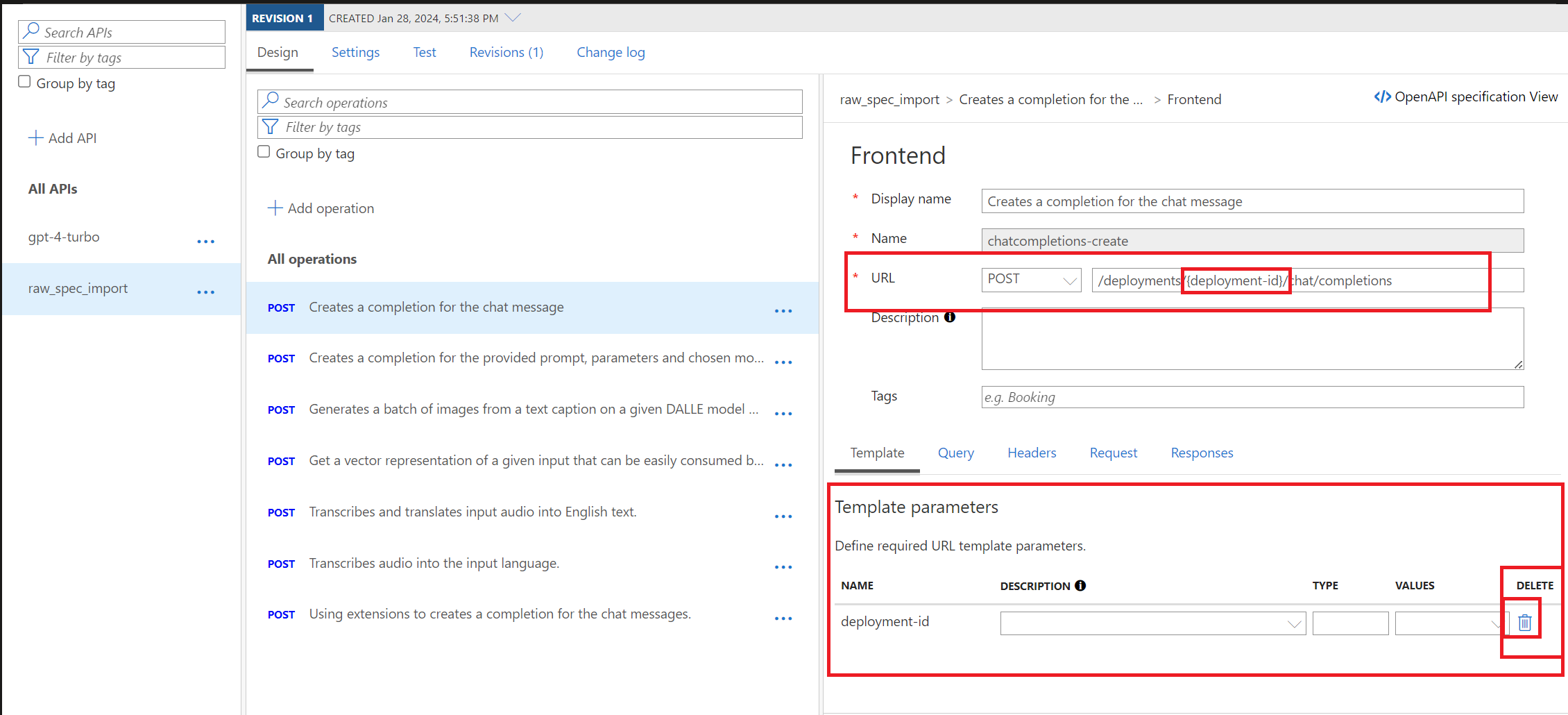
Note: Steps 3-d and 3-e allow the SDK formatted (OpenAI, LangChain etc) formatted requests to flow through without any additional formatting requirements on the End User's behalf i.e. they use your APIM endpoint and Key as they would any Azure OpenAI endpoint and key in their calls.
f. You can verify that the deletion was successful by examining the Operation again and looking at the Frontend section. There should no longer be a listing for the Template parameters, as shown below:

g. Repeat steps 3.d. through 3.f. for all the operations for the API spec you imported (later versions support more functions and therefore have more operations). There are 7 operations in the 2023-12-01-preview spec as shown below:

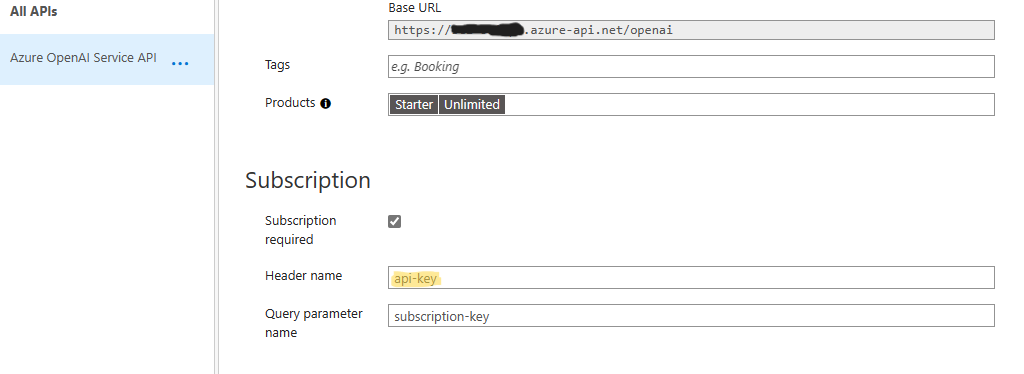
h. Now click where it says All operations at the top of the list of POST Operations, as shown in the image above, and select Settings. Then scroll down in the All Operations Sesttings and set the Subscription Header name to "api-key" to match OpenAI library specifications as shown below
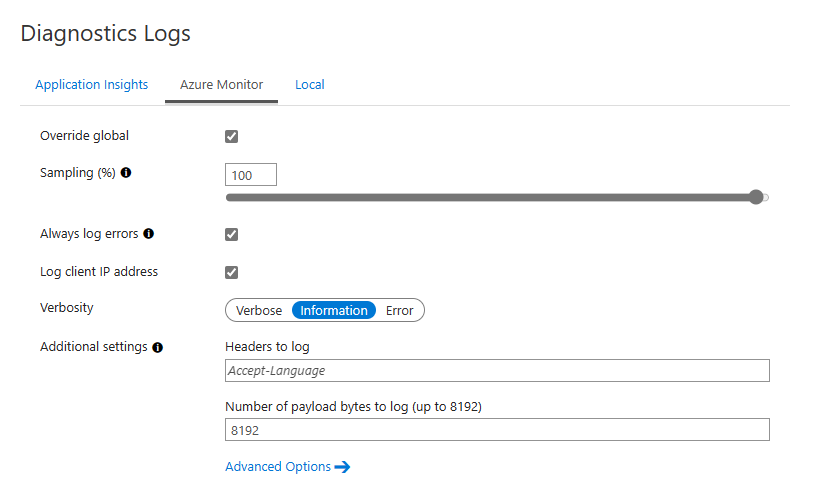
i. Configure the Diagnostic Logs settings: Set the Sampling rate to 100% and Number of payload bytes to log as the maximum; you may choose to use Application Insights or Azure Monitor or Local as per your requirements. More will be added to this step in the future.









-
In this step we create variables for our endpoints and keys on a per-region basis. Essentially, we take our AOAI endpoints and keys and make them into named variables we can call in our policies so we do not expose key value or endpoints unnecessarily and can use them or update them without needing edit our policies. The overall naming scheme for the Named values can be found in the 2023_12_12_APIM_v2_Update.xlsx document on the second tab. This matches the regions where I had Azure OpenAI Resources deployed. The complete mapping of regions, models, versions, and deployment names can be found in that same XLSX document and is accurate with my environment as of January 29, 2023. I have also written it out below:
AOAI Region Endpoint Variable Key Variable Australia East aoai-australiaeast-endpoint aoai-australiaeast-key Canada East aoai-canadaeast-endpoint aoai-canadaeast-key East US aoai-eastus-endpoint aoai-eastus-key East US 2 aoai-eastus2-endpoint aoai-eastus2-key France Central aoai-francecentral-endpoint aoai-francecentral-key Japan East aoai-japaneast-endpoint aoai-japaneast-key North Central aoai-northcentral-endpoint aoai-northcentral-key Norway East aoai-norwayeast-endpoint aoai-norwayeast-key South India aoai-southindia-endpoint aoai-southindia-key Sweden Central aoai-swedencentral-endpoint aoai-swedencentral-key Switzerland North aoai-switzerlandnorth-endpoint aoai-switzerlandnorth-key UK South aoai-uksouth-endpoint aoai-uksouth-key West Europe aoai-westeurope-endpoint aoai-westeurope-key West US aoai-westus-endpoint aoai-westus-key a. To create the Named value pairs, look in the left-hand blade menu under the APIs heading, locate the Named values menu and add your endpoints and keys. WARNING: The names shown below are not the names used in the policies included in this respository.
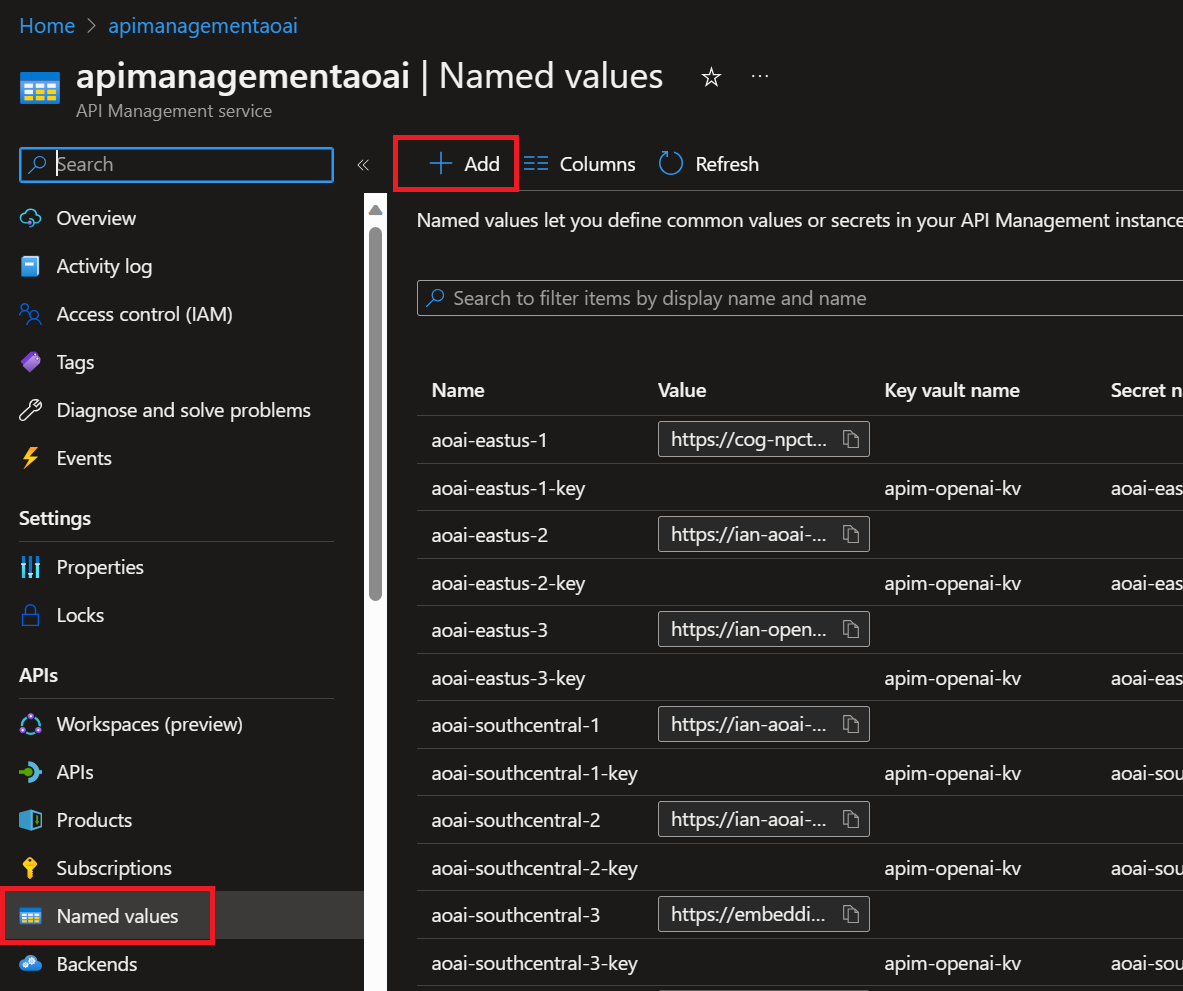
b. Ensure that you add "/openai" to the end of each Azure OpenAI Endpoint as below to ensure proper forwarding:
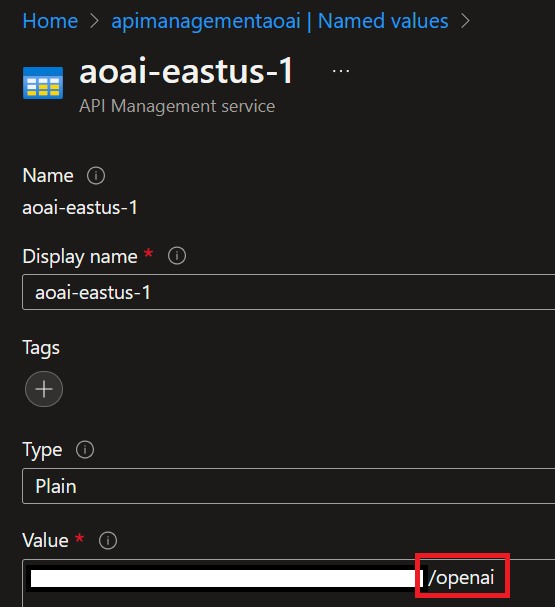
- You may add the keys as either secrets in API-M or with a Key Vault (the Key Vault method is preferred).
NOTE: To utilize the included XML script as-is, you will need to create named-value pair for all the end-points and secrets (14 in total in the example above). Note that the endpoints are named "aoai-eastus-endpoint" and matched with "aoai-eastus-key" etc. These create the variables that we are then able to call in-line in our policy logic.


-
Next we are going to have to define the policy for our hypthetical gpt-4-turbo set-up; this step cannot be taken without having defined the Named values above as you cannot save any policy that references a named value (variable for keys and endpoints) that is not defined in the APIM instance. This same process would need to be followed for model-or-deployment-name you use. For instance, if the Data Science team has "gpt-4-turbo-datascience" and Marketing has "gpt-4-turbo-marketing", they will both require all of the steps in Import the API Definition and this section.
a. Being by navigating to the APIs in the left-hand side blade menu:
b. Then navigate into your API, make sure you're in All operations, and select any of the "</>" icons:
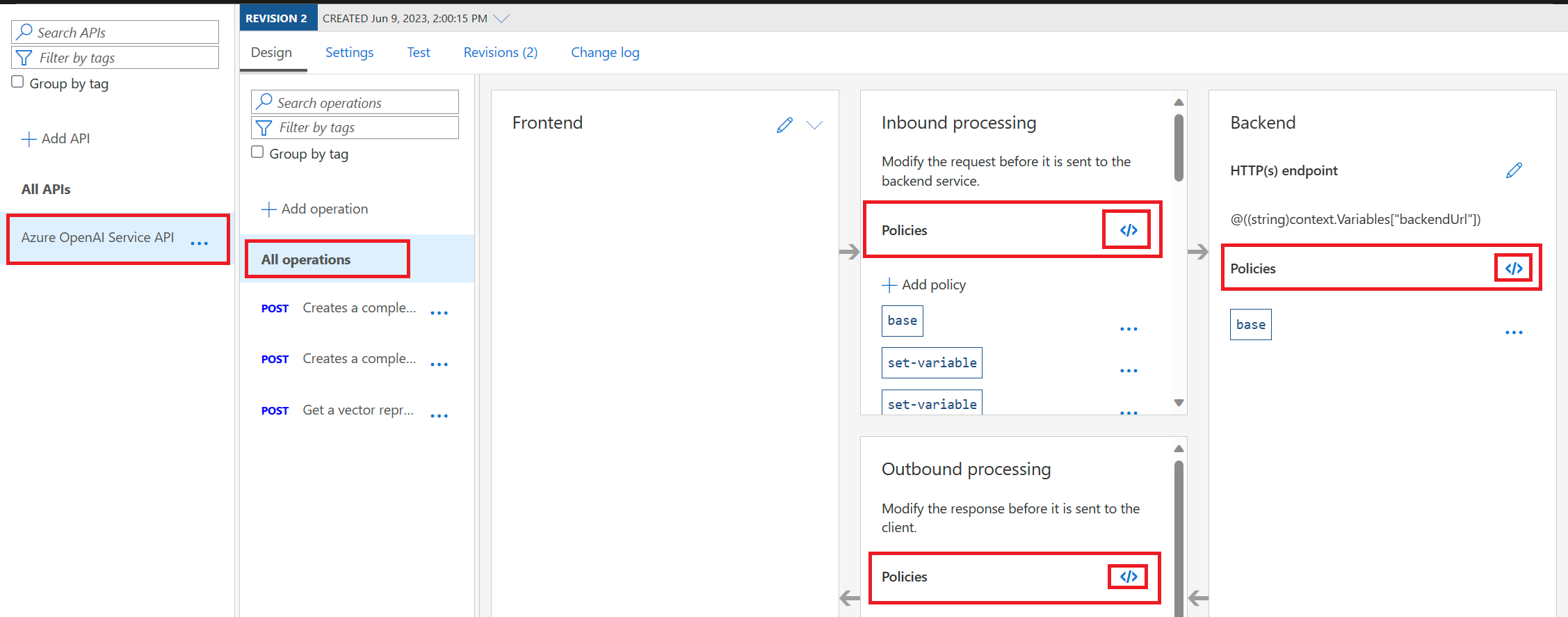
c. Copy-paste in the code within the .XML policy script that corresponds with your desired model deployment. These policies correspond with the model names used earlier Otherwise, you will need to edit the script to utilize the Named values you supplied in the step above.
Note: This Azure API Management Service policy block is an XML code that defines a set of policies to be applied to incoming calls, backend services, and outbound processing for API requests. The primary function of this policy block is to handle inbound requests, route them to different backend services based on a generated random number, and manage the retry mechanism in case of rate-limiting (HTTP 429 status code) responses from the backend services. Previous versions retried the traffic at the original endpoint but the latest update handles the retry across a pool of backend resources.
d. Click Save - if you have correctly supplied the endpoint and key variable names it will save and you can test.


The per-model-policy is far simplified from previous iterations. The Dall-E-3 Policy is the most clear example of how the pieces operate. I have created a prompt that is highly effective in when provided as a system prompt for GPT-4-Turbo to verify your policy fits the pattern's requirements.
The first 12 lines should be the same except for a few minor changes:
-
Line 4: Change what is set to {deployment-id} in the value="/deployments/{deployment-id}" to match what is set for {deployment-id} in when you named a new API
-
Line 5: When you set the random value for urlId in the .Next(#, #) section, the second number should be 1 greater than the actual number of endpoints you have for a given model. This is because the .Next() call is inclusive of the floor, exlusive of the ceiling value. So when we set it with .Next(1,2) we are choosing 1 of 1. If you had a primary endpoint you wanted to direct traffic to you would keep this
-
Line 7: The first .GetValueOrDefault<int>("urlId") == 1 call should be equal to 1 and subsequent calls should count up by integers.
-
Line 8 & 10: The AOAI endpoint and key should be for the same resource
WARNING: The last line before the </inbound> closing tag MUST BE EXACTLY THIS:
<set-backend-service base-url="@((string)context.Variables["backendUrl"] + (string)context.Variables["deploymentId"])" />as it formats the call to the back-end service to point to your AOAI endpoints + deployments/{deployment-id}.
WARNING: The <backend> section will only accept 1 policy and it must be the <retry condition=> policy.
Within the retry policy, you can set:
- count: The number of retries to attempt.
- interval: The amount of time, in seconds, to wait between retries.
- delta: The additional time, in seconds, to wait when using expontential backoff i.e. how many additional seconds to wait on each subsequent attempt
- first-fast-retry: A boolean for whether to immediately retry after the first 429 or not
To walk through each of the endpoints in the retry policy <choose> section, the .GetValueOrDefault<int>("urlId") % 1 + 1), set the first integer in the % # + 1) portion to be equal to the total number of endpoints + key combinations you have in the retry section.
WARNING: Each <when condition> MUST have this element exaclty as it is below. This allows the initial call to go through by verifying that the response body is not empty - and then triggers when the retry condition of a 429 is met. Without this, the call will not go through at all.
<when condition="@(context.Response != null && (context.Response.StatusCode == 429) && context.Variables.GetValueOrDefault<int>("urlId") == 1)">Verify that all endpoint and key combinations match.
The <backend> section ends, and then the <outbound> and <on-error> sections, and the overall </policies> section close with exactly these lines:
<outbound>
<set-header name="Backend-Service-URL" exists-action="override">
<value>@((string)context.Variables["backendUrl"])</value>
</set-header>
<cache-store duration="20" />
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>This APIM policy script is used to define the behavior of an API Management service in processing requests and responses. Here is a synopsis of the policy with its potential variables and key components:
Inbound Policy:
- Base Policy Inheritance:
<base />indicates that the inbound policy inherits from the base policy. - Set Variables: Two variables are set at the beginning:
deploymentId: A static value indicating a deployment identifier.urlId: A dynamic value ranging from 1 to 9, generated based on the context'sRequestId.
- Choose-When Condition: A series of conditional
whenclauses are used to determine thebackendUrlandapi-keybased on the value ofurlId. Each case sets a different backend service endpoint and corresponding API key, which are parameterized and likely stored as named values in the APIM instance. - Cache Lookup: The policy looks up the cache before proceeding to the backend service, varying the cache by the
Accept,Accept-Charset, andAuthorizationheaders. - Set Backend Service: The backend service URL is set by combining the
backendUrlanddeploymentIdvariables.
Backend Policy:
- Retry Policy: If the backend service responds with HTTP status code 429 (Too Many Requests), the policy will retry the request up to 18 times with an interval starting at 4 seconds and increasing by 2 seconds each time. The first retry happens immediately (
first-fast-retry=\"true\"). - Set Variables on Retry: The
urlIdis recalculated and incremented on each retry, ensuring that the subsequent retry is directed to a different backend endpoint. - Set Backend Service on Retry: Similar to the inbound policy, the backend URL and API key are set again based on the new
urlId. - Forward Request: The request is forwarded to the newly determined backend service, with the request body buffered.
Outbound Policy:
- Set Header: A header named
Backend-Service-URLis set with the value of thebackendUrlvariable to be included in the response sent back to the client. - Cache Store: The response is stored in the cache for 20 seconds.
- Base Policy Inheritance: The outbound policy also inherits from the base policy.
On-Error Policy:
- Base Policy Inheritance: In the case of an error, the
on-errorpolicy section inherits from the base policy.
Potential Variables and Key Components:
deploymentId: Indicates the specific deployment used for the backend service.urlId: Determines which backend endpoint and corresponding API key to use.backendUrl: The URL of the backend service to which the API Management service will forward the request.api-key: The key required to authenticate with the backend service.\n- Named values placeholders (e.g.,{{aoai-australiaeast-endpoint}}): These are likely references to named values configured in the APIM instance that store the actual URLs and keys for backend services.\n\nThis policy script essentially implements load distribution across different backend services and incorporates a retry mechanism for handling rate-limiting responses. It also uses caching to optimize performance and reduce backend load.
-
Azure OpenAI Landing Zone Deployments has bicep deployments and walkthroughs on set-ups for many Azure OpenAI architectures and associated Services.
-
Kirk Hofer's Load Testing Script just requires you copy the script and create a file called json.env, in the same directory. Use this format with an array of dictionaries as below - then change a few simple parameters to test our your set-up.
[ {"name": "apim-lz", "endpoint": "{YOU_APIM_ENDPOINT}", "key": "YOUR_APIM_KEY", "enabled": true} ] ```d