The goal of this Kafka streams implementation is to build a new real-time store inventory view from items sold in different stores of a fictive retailer company. The aggregates are kept in state store and exposed via interactive queries.
The goal of this note is to present how to run this store inventory aggregator locally using Event Streams Kafka image, and how to build it.
Updated 03/09/2022:
- move to kafka 2.8.1 and Quarkus 2.7.3
- Remove quarkus kafka stream api
- Simplify readme and reference other content.
For development purpose the following pre-requisites need to be installed on your working computer:
Java
- For the purposes of this lab we suggest Java 11+
- Quarkus (on version 2.7.x)
Git client
Maven
- Maven will be needed for bootstrapping our application from the command-line and running our application.
Docker
If you want to access the end solution clone the following git repository: git clone https://github.com/ibm-cloud-architecture/refarch-eda-store-inventory.
This project uses the Store Inventory Simulator to produce item sold events to kafka topic.
- Start local Kafka:
docker-compose up -dto start one Kafka broker, zookeeper, and the simulator. - Created the
itemsandstore.inventorytopics on your Kafka instance
./scripts/createTopics.sh
######################
create Topics
Created topic items.
Created topic store.inventory.
./scripts/listTopics.sh
######################
List Topics
store.inventory
items- Verify each components runs well with
docker ps:
CONTAINER ID IMAGE PORTS NAMES
f31e4364dec9 quay.io/ibmcase/eda-store-simulator 0.0.0.0:8082->8080/tcp storesimulator
2c2959bbda15 obsidiandynamics/kafdrop 0.0.0.0:9000->9000/tcp kafdrop
3e569f205f6f quay.io/strimzi/kafka:latest-kafka-2.8.1 0.0.0.0:29092->9092/tcp kafka
0cf09684b675 quay.io/strimzi/kafka:latest-kafka-2.8.1 0.0.0.0:2181->2181/tcp zookeeper- Start the app in dev mode:
quarkus devThen see the demonstration script section below to test the application.
- Build locally
quarkus build
# or use the script
./scripts/buildAll.sh
- Build with s2i on OpenShift directly
# Be sure to be in a OpenShift project with a kafka cluster like Strimzi up and running,
# Example rt-inventory-dev
# and have a tls-user defined
./mvnw clean package -Dquarkus.kubernetes.deploy=true -DskipTestsIf needed copy a tls-user secret defined in a project where Kafka Cluster runs, then use
the following command:
oc get secret tls-user -o yaml -n rt-inventory-dev | oc apply -f -The code structure use the 'Onion' architecture. The classes of interest are
- the
infra.ItemStreamto define the Kafka KStreams from theitemstopic, and the serdes based onItemTransactionevent structure. - the
infra.StoreInventoryStreamto define output stream to `` topic. - the
domain.ItemProcessingAgentwhich goal is to compute the store inventory, which mean the number of items per item id per store
The Kstream logic is simple:
@Produces
public Topology processItemTransaction(){
KStream<String,ItemTransaction> items = inItemsAsStream.getItemStreams();
// process items and aggregate at the store level
KTable<String,StoreInventory> storeItemInventory = items
// use store name as key, which is what the item event is also using
.groupByKey(ItemStream.buildGroupDefinitionType())
// update the current stock for this <store,item> pair
// change the value type
.aggregate(
() -> new StoreInventory(), // initializer when there was no store in the table
(store , newItem, existingStoreInventory)
-> existingStoreInventory.updateStockQuantity(store,newItem),
materializeAsStoreInventoryKafkaStore());
produceStoreInventoryToInventoryOutputStream(storeItemInventory);
return inItemsAsStream.run();
}The functions materializeAsStoreInventoryKafkaStore and produceStoreInventoryToInventoryOutputStream are classical Kafka stream plumbing code.
Only the above function has business logic.
For the up to date demonstration script see Refarch-eda.
For development purpose is a quick demo scripts which can be done in
# Once different processes run locally
# If not done yet, use:
./scripts/createTopics.sh
# Verify what is items so far
./scripts/verifyItems.sh
# Trigger the simulator to send few records
curl -X POST http://localhost:8082/api/stores/v1/start -d '{ "backend": "KAFKA","records": 20}'
# Verify store inventory is up to date
curl -X GET "http://localhost:8080/api/v1/stores/inventory/Store_2" -H "accept: application/json"
##################################
# you should get something like
# {"result":{"stock":{"Item_6":-1,"Item_4":7},"storeName":"Store_2"}}
# Verify store inventory
./scripts/verifyInventory.shDetails:
Once started go to one of the Store Aggregator API: swagger-ui/ and select
the /api/v1/stores/inventory/{storeID} end point. Using the Store_1 as storeID you should get an empty response.
-
Using the user interface at http://localhost:8082/
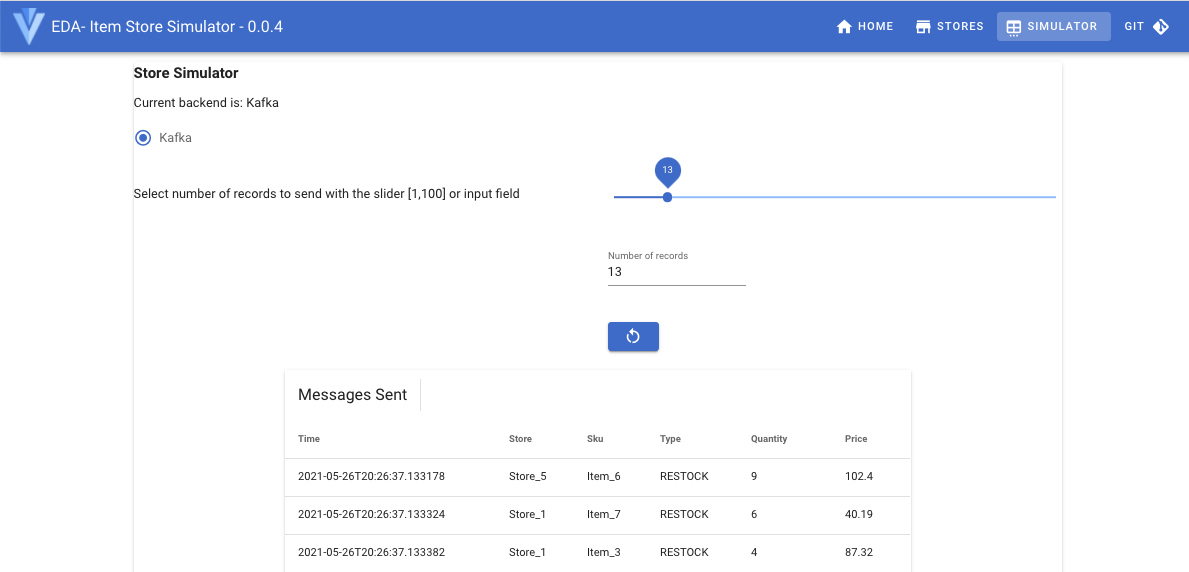
-
Use Kafdrop UI to see messages in
itemstopic.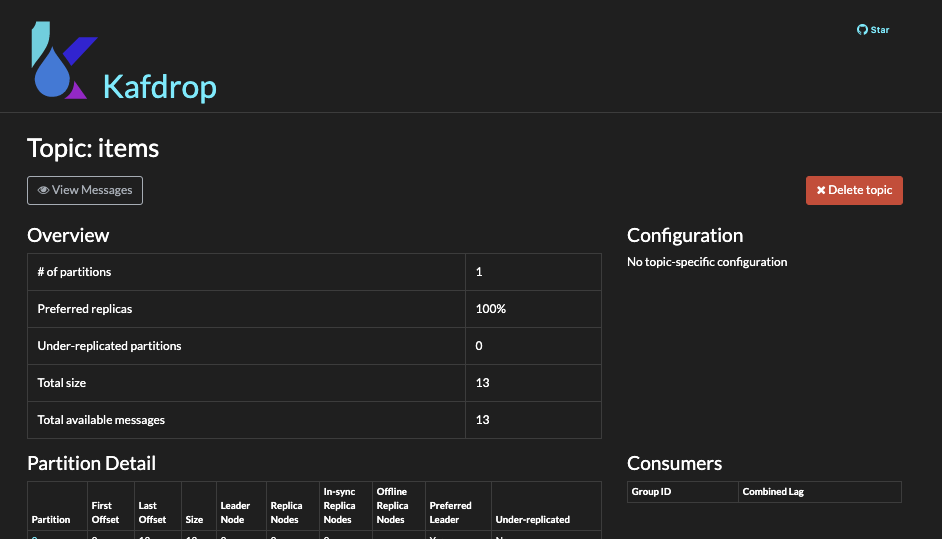
-
Verify the store inventory is updated:
curl -X GET "http://localhost:8080/api/v1/stores/inventory/Store_2" -H "accept: application/json" -
Verify messages are sent to
store.inventorytopic by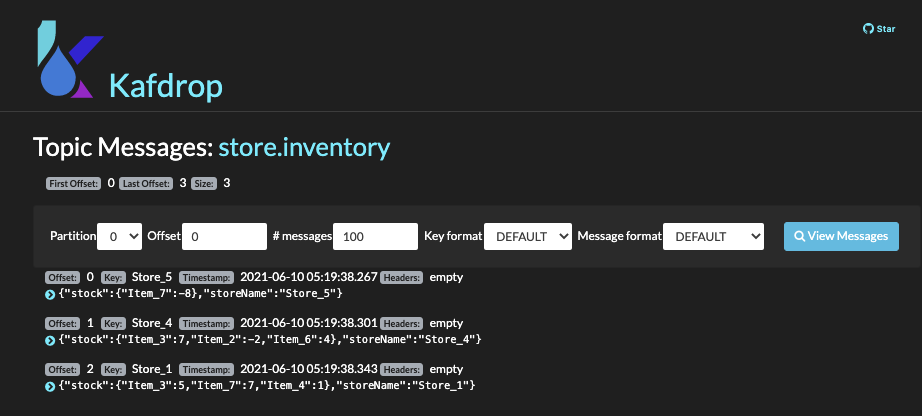



Remark: after the store aggregator consumes some items, you should see some new topics created, used to persist the the stores aggregates.
See the rt-inventory-gitops repository for configuring ArgoCD and Tekton and the solution deployment definitions.
Se we need to have the pipeline operator up and running, and the pipeline for building quarkus app is defined.
# Verify pipeline
oc get pipelines -n rt-inventory-cicd
# Verify you have the needed secrets to get access to github
oc get secrets
# need to see at least
git-host-access-token Opaque 1 4m8s
git-host-basic-auth-token kubernetes.io/basic-auth 2 4m6s
gitops-webhook-secret Opaque 1 4m4s
regcred kubernetes.io/dockerconfigjson 1 12m
webhook-secret-rt-inventory-dev-refarch-eda-store-simulator
# Define resources
# oc apply -f build/resources.yaml
# Run the pipeline
oc create -f build/pipelinerun.yaml