Argument Classification and Clustering using BERT
In our publication Classification and Clustering of Arguments with Contextualized Word Embeddings (ACL 2019) we fine-tuned the BERT network to:
- Perform sentential argument classification (i.e., given a sentence with an argument for a controversial topic, classify this sentence as pro, con, or no argument). Details can be found in argument-classification/README.md
- Estimate the argument similarity (0...1) given two sentences. This argument similarity score can be used in conjuction with hierarchical agglomerative clustering to perform aspect-based argument clustering. Details can be found in argument-similarity/README.md
Citation
If you find the implementation useful, please cite the following paper: Classification and Clustering of Arguments with Contextualized Word Embeddings
@InProceedings{Reimers:2019:ACL,
author = {Reimers, Nils, and Schiller, Benjamin and Beck, Tilman and Daxenberger, Johannes and Stab, Christian and Gurevych, Iryna},
title = {{Classification and Clustering of Arguments with Contextualized Word Embeddings}},
booktitle = {Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
month = {07},
year = {2019},
address = {Florence, Italy},
pages = {567--578},
url = {https://arxiv.org/abs/1906.09821}
}
Contact person: Nils Reimers, Rnils@web.de
https://www.ukp.tu-darmstadt.de/
Don't hesitate to send us an e-mail or report an issue, if something is broken (and it shouldn't be) or if you have further questions.
This repository contains experimental software and is published for the sole purpose of giving additional background details on the respective publication.
Setup
This repository requires Python 3.5+ and PyTorch 0.4.1/1.0.0. It uses pytorch-pretrained-BERT version 0.6.2. See the pytorch-pretrained-BERT readme for further details on the installation. Usually, you can install as follows:
pip install pytorch-pretrained-bert==0.6.2 sklearn scipy
Argument Classification
Please see argument-classification/README.md for full details.
Given a sentence and a topic, classify if the sentence is a pro, con, or no argument. For example:
Topic: zoo
Sentence: Zoo confinement is psychologically damaging to animals.
Output Label: Argument_against
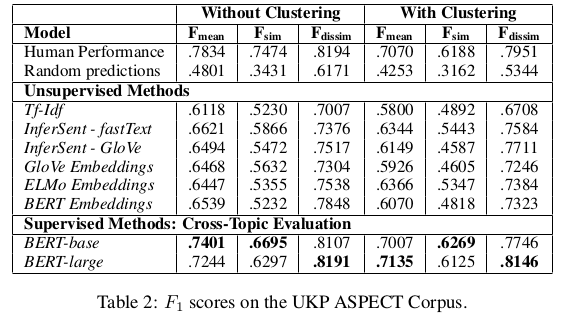
You can download pre-trained models from here, which were trained on all eight topics of the UKP Sentential Argument Mining Corpus:
See argument-classification/inference.py how to use these models for classifying new sentences.
In a leave-one-topic out evaluation, the BERT model achieves the following performance.
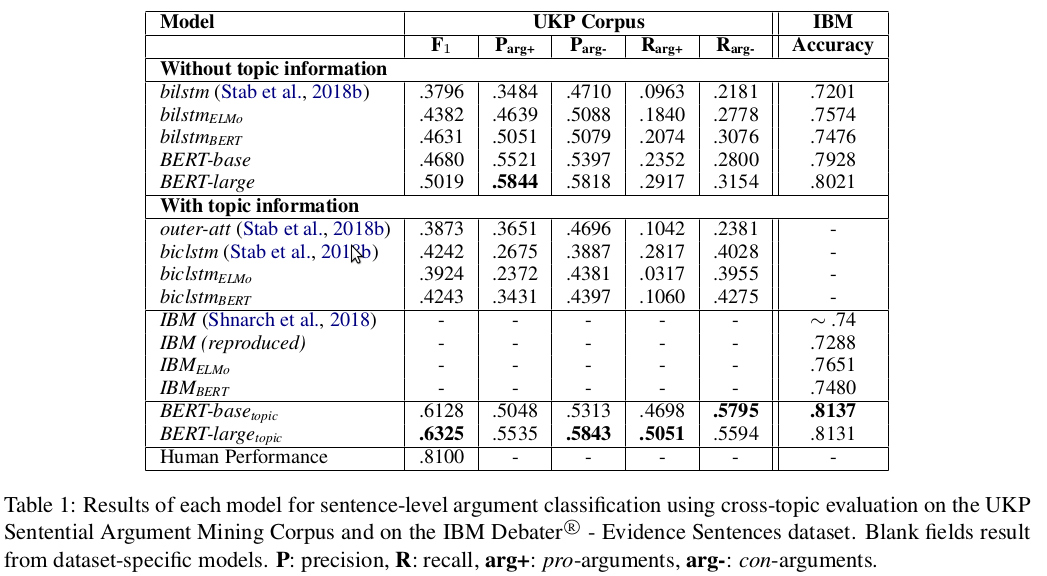
Argument Similarity & Clustering
See argument-similarity/README.md for full details.
Given two sentences, the code in argument-similarity returns a value between 0 and 1 indicating the similarity between the arguments. This can be used for agglomorative clustering to find & cluster similar arguments.
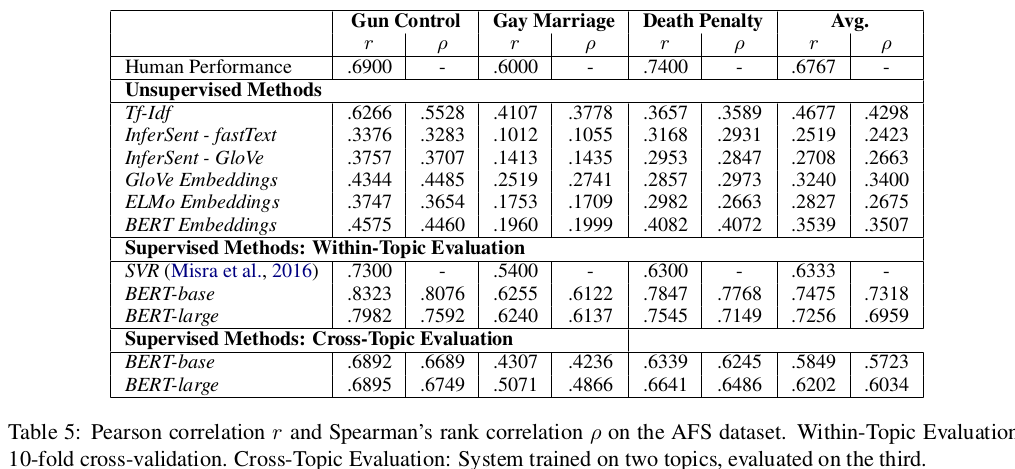
You can download two pre-trained models:
- argument_similarity_ukp_aspects_all.zip - trained on the complete UKP Argument Aspect Similarity Corpus
- argument_similarity_misra_all.zip - trained on the complete Argument Facet Similarity (AFS) Corpus from Misra et al.
See argument-similarity/inference.py for an example. This example computes the pairwise similarity between arguments on different topics. The output should be something like this for the model trained on the UKP corpus:
Predicted similarities (sorted by similarity):
Sentence A: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Sentence B: It is cruel and unethical to kill animals for food when vegetarian options are available
Similarity: 0.99436545
Sentence A: Zoos are detrimental to animals' physical health.
Sentence B: Zoo confinement is psychologically damaging to animals.
Similarity: 0.99386144
[...]
Sentence A: It is cruel and unethical to kill animals for food when vegetarian options are available
Sentence B: Rising levels of human-produced gases released into the atmosphere create a greenhouse effect that traps heat and causes global warming.
Similarity: 0.0057242378
With the Misra AFS model, the output should be something like this:
Predicted similarities (sorted by similarity):
Sentence A: Zoos are detrimental to animals' physical health.
Sentence B: Zoo confinement is psychologically damaging to animals.
Similarity: 0.8723387
Sentence A: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Sentence B: It is cruel and unethical to kill animals for food when vegetarian options are available
Similarity: 0.77635074
[...]
Sentence A: Zoos produce helpful scientific research.
Sentence B: Eating meat is not cruel or unethical; it is a natural part of the cycle of life.
Similarity: 0.20616204