This is an implementation of the research paper "A Short Introduction to Boosting" written by Yoav Freund and Robert E. Schapire.
Machine Learning algorithms specially those concerning classification and regression can perform weakly while encountering huge datasets. In order to overcome such inconveniences, a number of optimisation algorithms were developed that could improve a model's performance significantly. Adaboost is one such boosting technique which we have implemented here to analyse the improvement in the performance of our classification model.
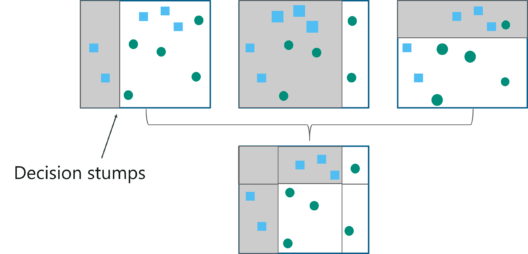
Boosting refers to a general and provably effective method of producing a very accurate prediction rule by combining rough and moderately inaccurate rules of thumb. The AdaBoost algorithm was introduced in 1995 by Freund and Schapire which solved many of the practical difficulties of the earlier boosting algorithms. The algorithm takes as input a training set (x1,y1),...., (xm,ym) where each xi belongs to some domain or instance space, and each label yi is in some label set assuming Y = {-1, 1}. AdaBoost calls a given weak or base learning algorithm repeatedly in a series of rounds t = 1,..., T whose job is to find a weak hypothesis ht and outputs a final hypothesis H which is a weighted majority vote of the T weak hypotheses.

The Dataset used here is a Toy Dataset generated by utilising make_gaussian_quantiles from sklearn.datasets module. This generated our input variable X in a two dimensional plane equivalently explained to have two features and our target variable y which took either -1 or +1.

Our model architecture consists of the following components :-
- The weak learner was decided to be a Decision Tree Classifier with two leaf nodes.
- The output obtained from the weak learners were combined into a weighted sum that represented the final boosted output.

- The custom defined datagenerate module is used to generate the input and the target variables.
- The generated data is plotted in a two dimensional plane through another custom defined module named plot, for visualizing the input.
- The weak learners are defined as Decision Tree Classifiers with two leaf nodes and are used to make predictions for fifty iterations in our case.
- The weighted sum of all the weak learners are computed as the final boosting output to study the performance enhancement.
- Lastly, the decision boundaries are visualized using the visualize module for every iteration.
- After 1st iteration -

- After 50 iterations -

- Training error of Weak Hypothesis vs Training error of Final Hypothesis -

scikit-learn==0.24.1
numpy==1.19.2
matplotlib==3.3.4
typing==3.7.4.3
-
Setting up the Python Environment with dependencies:
pip install -r requirements.txt -
Cloning the Repository:
git clone https://github.com/srijarkoroy/adaboost -
Entering the directory:
cd adaboost -
Running the file:
python3 test.py