![]()
README: English | Japanese (日本語)
A real-time implementation of Voice Activity Projection (VAP) is aimed at controlling behaviors of spoken dialogue systems, such as turn-taking. The VAP model takes stereo audio data (from two dialogue participants) as input and outputs future voice activity (p_now and p_future).
Details about the VAP model can be found in the following repository: https://github.com/ErikEkstedt/VoiceActivityProjection
In this repository, the VAP model can operate in real-time in a CPU environment. Please note that using GPUs can increase the processing speed.
The VAP program operates as a program that receives input and outputs processing results through a TCP/IP connection. It is expected that your program will connect to the VAP program via TCP/IP, input the audio data, and receive the VAP results.
Demo video on YouTube (https://www.youtube.com/watch?v=-uwB6yl2WtI)
- rvap
- vap_main - VAP main directory
- vap_bc - VAP main directory for backchannel prediction
- common - Utility programs for the VAP process, like how to encode and decode data for communication
- input - Sample programs for input function
- output - SAmple programs for output function
- asset - Model files for VAP and CPC
- vap - VAP models
- cpc - Pre-trained CPC models
- Windows - Not support WSL
- Mac - Not support
output/gui.py - Linux
This software requires a Python environment.
Please refer to the required libraries listed in requirements.txt.
You can directory install the libraries using it as
$ pip install -r requirements.txt
$ pip install -e .If you want to use a GPU, please use requirements-gpu.txt
This system can be used in three steps. The first step is the main part of the VAP model, while the second and third steps are optional for input and output. This implies that you should ideally structure your system like the second and third steps, using them to provide input audio from your sensor and receive the processing result from VAP.
When launching the main VAP program, specify both the trained VAP model and the pre-trained CPC model. You can also assign port numbers for input and output.
For the parameters of the model you use, it needs to correctly set vap_process_rate and context_len_sec.
Please check out the description of the model.
$ cd rvap/vap_main
$ python vap_main.py ^
--vap_model ../../asset/vap/vap_state_dict_jp_20hz_2500msec.pt ^
--cpc_model ../../asset/cpc/60k_epoch4-d0f474de.pt ^
--port_num_in 50007 ^
--port_num_out 50008 ^
--vap_process_rate 20 ^
--context_len_sec 2.5If you want to use a GPU, please add an argument --gpu.
Then, you should see the message like
[IN] Waiting for connection of audio input...
To test the WAV audio inputs of the sample data, launch input/wav.py. You can specify the input WAV file names. Please note, this sample input program requires both individual audio files as input for the model, and a mixed 2-channel audio data for playback. Note that you also need to specify the server IP and port number for the main VAP program.
$ cd input
$ python wav.py ^
--server_ip 127.0.0.1 ^
--port_num 50007 ^
--input_wav_left wav_sample/jpn_inoue_16k.wav ^
--input_wav_right wav_sample/jpn_sumida_16k.wav ^
--play_wav_stereo wav_sample/jpn_mix_16k.wavTo capture input audio from the microphone, refer to the sample program input/mic.py. This program takes monaural audio data from the default microphone and concatenates it with zero data to fit the VAP input format. This implies that one participant is speaking while the other remains silent. This application is suitable for implementing the VAP model in spoken dialogue systems.
$ cd input
$ python mic.py ^
--server_ip 127.0.0.1 ^
--port_num 50007You can obtain the processing result of the VAP program via TCP/IP. The sample program output/console.py is designed to demonstrate how to receive data. It will display the received data on the console. Note that you need to specify the server IP and port number for the main VAP program.
$ cd output
$ python console.py ^
--server_ip 127.0.0.1 ^
--port_num 50008We have also prepared another sample to visualize the received data as output/gui.py.
Note that this GUI program does not work in Mac environemtns.
$ cd output
$ python gui.py ^
--server_ip 127.0.0.1 ^
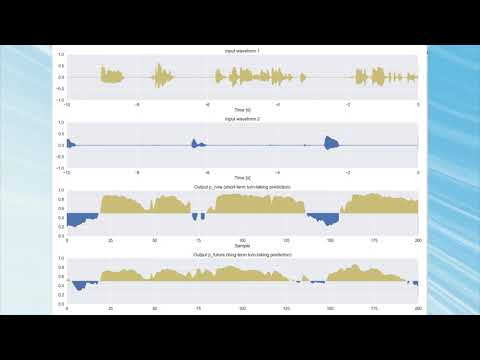
--port_num 50008You would see the GUI visualization like:

It is expected to the users of this repoditory that they would implement the input and output programs according to their own purposes, by referring to the sample programs located in input and output directories.
Each data consists of 160 audio samples in 16,000 Hz, with each sample representing the audio data of two individuals. Each audio data sample is represented as an 8-byte double-precision floating-point number in the range of -1.0 to +1.0, in the little endian.
Transmission Order:
Data samples are transmitted sequentially in pairs. The first 8 bytes of each pair represent the audio data for the first individual, followed by 8 bytes for the second individual.
Example Data Packet Structure:
The size of each input data should be 2,560 bytes.
| Byte Offset | Data type | Description |
|---|---|---|
| 0 - 7 | Double | Audio data (Individual 1) - Sample 1 |
| 8 - 15 | Double | Audio data (Individual 2) - Sample 1 |
| 16 - 23 | Double | Audio data (Individual 1) - Sample 2 |
| 24 - 31 | Double | Audio data (Individual 2) - Sample 2 |
| ... | ... | ... |
| 2544 - 2551 | Double | Audio data (Individual 1) - Sample 160 |
| 2552 - 2559 | Double | Audio data (Individual 2) - Sample 160 |
For more concrete examples, please see the sample programs like input/wav.py and input/mic.wav.
The output data includes both the input audio data and the VAP outputs (p_now and p_future). Note that the framerate for the VAP processing differs from that of the input audio. For instance, with a 20 Hz model, the length of the VAP audio frame is 800 samples. Also, all data is in little-endian.
Example Data Packet Structure:
Under the specified condition, the size of each output data should be 12,860 bytes. This data is distributed after each VAP frame is processed.
| Byte Offset | Data type | Description |
|---|---|---|
| 0 - 3 | Int | Total Data Length (12,860) |
| 4 - 11 | Double | Unix time stamp |
| 12 - 15 | Int | Individual 1 Audio Data Length (800) |
| 16 - 23 | Double | Audio data (Individual 1) - Sample 1 |
| 24 - 31 | Double | Audio data (Individual 1) - Sample 2 |
| ... | ... | ... |
| 6408 - 6415 | Double | Audio data (Individual 1) - Sample 800 |
| 6416 - 6419 | Int | Individual 2 Audio Data Length (800) |
| 6420 - 6427 | Double | Audio data (Individual 2) - Sample 1 |
| 6428 - 6435 | Double | Audio data (Individual 2) - Sample 2 |
| ... | ... | ... |
| 12812 - 12819 | Double | Audio data (Individual 2) - Sample 800 |
| 12820 - 12823 | Int | p_now length (2) |
| 12824 - 12831 | Double | p_now for (Individual 1) |
| 12832 - 12839 | Double | p_now for (Individual 2) |
| 12840 - 12843 | Int | p_future length (2) |
| 12844 - 12851 | Double | p_future for (Individual 1) |
| 12852 - 12859 | Double | p_future for (Individual 2) |
You can also batch process recorded wav files using rvap/vap_main/vap_offline.py.
$ cd rvap/vap_main
$ python vap_offline.py ^
--vap_model '../../asset/vap/vap_state_dict_20hz_jpn.pt' ^
--cpc_model ../../asset/cpc/60k_epoch4-d0f474de.pt ^
--input_wav_left ../../input/wav_sample/jpn_inoue_16k.wav ^
--input_wav_right ../../input/wav_sample/jpn_sumida_16k.wav ^
--filename_output 'output_offline.txt'The output data will be saved in output_offline.txt, where each line contains the timestamp from the wav file (in seconds) followed by p_now (2 float values) and p_future (2 float values), separated by commas, like this:
time_sec,p_now(0=left),p_now(1=right),p_future(0=left),p_future(1=right)
0.07,0.29654383659362793,0.7034487724304199,0.3714706599712372,0.6285228729248047
0.12,0.6943456530570984,0.30564749240875244,0.5658637881278992,0.4341297447681427
0.17,0.8920691013336182,0.10792573541402817,0.7332779169082642,0.26671621203422546
0.22,0.8698683977127075,0.13012604415416718,0.6923539042472839,0.3076401650905609
0.27,0.870344340801239,0.12964950501918793,0.730902373790741,0.26909157633781433
0.32,0.9062888622283936,0.09370578080415726,0.7462385892868042,0.2537555992603302
0.37,0.8965250849723816,0.10346963256597519,0.6949127912521362,0.30508118867874146
0.42,0.9331467151641846,0.06684830039739609,0.7633994221687317,0.2365950644016266
0.47,0.9440065026283264,0.05598851293325424,0.7653886675834656,0.2346058338880539
The visualization app can be used to see the prediction result while listening to the audio.
python output/offline_prediction_visualizer/main.py --left_audio input/wav_sample/jpn_inoue_16k.wav --right_audio input/wav_sample/jpn_sumida_16k.wav --prediction rvap/vap_main/output_offline.txtThere is also a fine-tuned model available for backchannel prediction (generation). Please use the following main program:
$ cd rvap/vap_bc
$ python vap_bc_main.py ^
--vap_model ../../asset/vap_bc/vap-bc_state_dict_erica_20hz_5000msec.pt ^
--cpc_model ../../asset/cpc/60k_epoch4-d0f474de.pt ^
--port_num_in 50007 ^
--port_num_out 50008 ^
--vap_process_rate 20 ^
--context_len_sec 5The input/output format is the same, but the output p_now and p_future are replaced with p_bc_react and p_bc_emo, respectively.
p_bc_react represents the probability of occurrence of continuer backchannels (e.g., "Yeah"), and p_bc_emo represents the probability of occurrence of assessment backchannels (e.g., "Wow").
This model predicts the probability of backchannels occurring 500 milliseconds later.
Also, note that while the model input consists of 2-channel audio, it predicts the backchannels of the speaker on the first channel, meaning the second channel corresponds to the user's voice.
The sample programs for visualization are output/console_bc.py and output/gui_bc.py.
This repository contains several models for VAP and CPC. To use these models, please abide by the lisence.
There are parameters named vap_process_rate and context_len_sec.
The former specifies the number of samples processed in the VAP model per second, and the second one corresponds to the length (sec.) of the context input to the model.
They are fixed during the training so if you want to change those parameters, you need to re-train the models.
Japanese model (trained using a Zoom meeting dialogue from Travel agency dialogue (Inaba 2022))
| Location | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap/vap_state_dict_jp_20hz_2500msec.pt |
20 | 2.5 |
asset/vap/vap_state_dict_jp_10hz_5000msec.pt |
10 | 5 |
asset/vap/vap_state_dict_jp_10hz_3000msec.pt |
10 | 3 |
asset/vap/vap_state_dict_jp_5hz_5000msec.pt |
5 | 5 |
asset/vap/vap_state_dict_jp_5hz_3000msec.pt |
5 | 3 |
English model (trained using Switchboard corpus)
| Location | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap/vap_state_dict_eng_20hz_2500msec.pt |
20 | 2.5 |
asset/vap/vap_state_dict_eng_10hz_5000msec.pt |
10 | 5 |
asset/vap/vap_state_dict_eng_10hz_3000msec.pt |
10 | 3 |
asset/vap/vap_state_dict_eng_5hz_5000msec.pt |
5 | 5 |
asset/vap/vap_state_dict_eng_5hz_3000msec.pt |
5 | 3 |
Multi-lingual model (for English, Mandarin Chinese, and Japanese, trained using Switchboard corpus, HKUST Mandarin Telephone Speech, and Travel agency dialogue (Inaba 2022))
| Location | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap/vap_state_dict_tri_ecj_20hz_2500msec.pt |
20 | 2.5 |
asset/vap/vap_state_dict_tri_ecj_10hz_5000msec.pt |
10 | 5 |
asset/vap/vap_state_dict_tri_ecj_10hz_3000msec.pt |
10 | 3 |
asset/vap/vap_state_dict_tri_ecj_10hz_5000msec.pt |
5 | 5 |
asset/vap/vap_state_dict_tri_ecj_10hz_3000msec.pt |
5 | 3 |
Japanese backchannel model (fine-tuned with an attentive listening dialogue data using ERICA (WoZ))
| Location | vap_process_rate |
context_len_sec |
|---|---|---|
asset/vap-bc/vap-bc_state_dict_erica_20hz_5000msec.pt |
20 | 5 |
asset/vap-bc/vap-bc_state_dict_erica_20hz_3000msec.pt |
20 | 3 |
asset/vap-bc/vap-bc_state_dict_erica_10hz_5000msec.pt |
10 | 5 |
asset/vap-bc/vap-bc_state_dict_erica_10hz_3000msec.pt |
10 | 3 |
asset/vap-bc/vap-bc_state_dict_erica_5hz_5000msec.pt |
5 | 5 |
asset/vap-bc/vap-bc_state_dict_erica_5hz_3000msec.pt |
5 | 3 |
| Type | Location | Description |
|---|---|---|
| Original CPC | asset/cpc/60k_epoch4-d0f474de.pt |
Original CPC model trained with Libri-light 60k speech data |
Please cite the following paper, if you made any publications made with this repository.
Koji Inoue, Bing'er Jiang, Erik Ekstedt, Tatsuya Kawahara, Gabriel Skantze
Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection
International Workshop on Spoken Dialogue Systems Technology (IWSDS), 2024
https://arxiv.org/abs/2401.04868
@inproceedings{inoue2024iwsds,
author = {Koji Inoue and Bing'er Jiang and Erik Ekstedt and Tatsuya Kawahara and Gabriel Skantze},
title = {Real-time and Continuous Turn-taking Prediction Using Voice Activity Projection},
booktitle = {International Workshop on Spoken Dialogue Systems Technology (IWSDS)},
year = {2024},
url = {https://arxiv.org/abs/2401.04868},
}
If you use the multi-lingual VAP model, please also cite the following paper.
Koji Inoue, Bing'er Jiang, Erik Ekstedt, Tatsuya Kawahara, Gabriel Skantze
Multilingual Turn-taking Prediction Using Voice Activity Projection
Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pages 11873-11883, 2024
https://aclanthology.org/2024.lrec-main.1036/
@inproceedings{inoue2024lreccoling,
author = {Koji Inoue and Bing'er Jiang and Erik Ekstedt and Tatsuya Kawahara and Gabriel Skantze},
title = {Multilingual Turn-taking Prediction Using Voice Activity Projection},
booktitle = {Proceedings of the Joint International Conference on Computational Linguistics and Language Resources and Evaluation (LREC-COLING)},
pages = {11873--11883},
year = {2024},
url = {https://aclanthology.org/2024.lrec-main.1036/},
}
The source code in this repository is licensed under the MIT license. The trained models, found in the asset directory, are used for only academic purposes.
A pre-trained CPC model, located at asset/cpc/60k_epoch4-d0f474de.pt, is from the original CPC project and please follow its specific license.
Refer to the original repository at https://github.com/facebookresearch/CPC_audio for more details.