A small dataset with handwritten pictures of hiragana, the images are in grayscale, sized 83x84, comprising 50 differente characters (all 46 hiragana plus 4 hiragana with dakuten or handakuten). Each character has 20 samples, totalizing 1000 images.
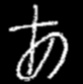



This dataset was made using a Python program that using Image Processing techniques, extracted each individual character from a scanned sheet of paper with the characters written in it.
This is really a small dataset, but it works for testing purposes, such as making a Neural Network to identify each different hiragana using MATLAB, for example. A simple script to import this dataset to MATLAB is available in the repository.
If you used this dataset in any way, please let me know, I'd be glad to know that maybe this small set of pictures helped someone. If you have any questions about this dataset, please let me know as well.
For more information about hiragana (and the Japanese language in general), check this link.