Foi publicado no Kaggle (https://www.kaggle.com/datasets/muratkokludataset/date-fruit-datasets) um dataset sobre 7 tipos diferentes de frutas e vários aspectos de cada uma delas. Seja aspectos geométricos, como o perímetro e a área, como suas cores e de suas flores. Baseado nesse data set foi escrito um artigo (https://www.hindawi.com/journals/mpe/2021/4793293/) na qual usava um algoritmo de rede neural e SVM para classificar o dataset. Aqui neste repositório decidi colocar alguns algoritmos de Machine Learning do scikit learn e a rede neural do Pytorch. Assim como no artigo tem uma parte no código na qual você junta duas predições, e a partir do voto da maioria, é determinado qual a classficação que vai ser predita (foi deixado como Rede Neural e KNN, mas você pode experimentar com os outros algoritmos).
A coleta dos dados foi basntante fácil e só foi necessário baixar do próprio Kaggle. A base de dados, além da Classe, não tinha nenhum problema então normalizei os dados e utilizei os algoritmos. Salvei em arquivos os melhores parâmetros para cada algoritmo usado, eles se criam sozinhos com o código, porém a Rede Neural do scikit learn demora MUITO, então já pense nisso antes de rodar o código. Ele disponibiliza as matrizes de confusão para que possa entender como cada algoritmo foi na base de dados. Os melhores parâmetros vão ser calculados aplicando na base de dados utilizando também o Cross Validation e logo depois quando tempos os melhores parâmetros separamos o dataset em treino e teste e mostra como o algoritmo se sai. No artigo ele combina dois algoritmos e encontra a acurácia da junção, fizemos isso para Rede Neural do scikit learn e o KNN e da Rede Neural do Pytorch com KNN. Você está livre para testar a melhor combinação, mas deixei assim mesmo. Obtemos assim isoladamente uma acurácia de mais de 91% e quando juntos os algoritmos chegam a ter mais de 94% de acurácia, algo maior do que é citado no artigo.
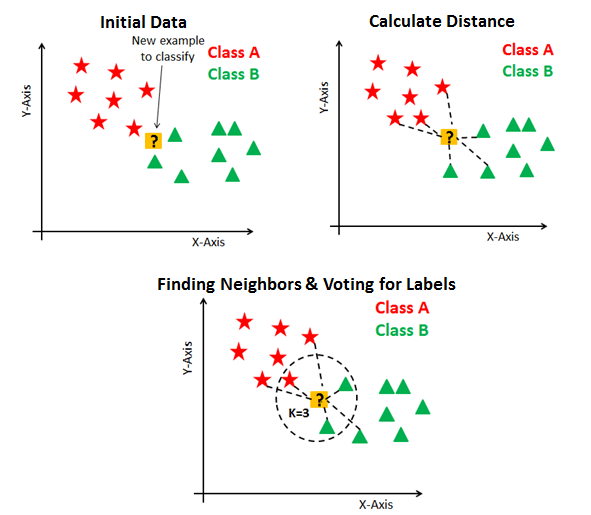
O KNN ou K-Nearst Neightbors (K-viznhos mais próximos) é um algoritmo na qual é utilizado a distância entre os dados para saber a sua classificação. O número K no nome indica quantos vizinhos você quer ser considerado, então no caso de K = 5 serão os 5 vizinhos mais próximos a serem utilizados para classificar o dado. Se os 5 forem de uma classe A, o dado será classificado como da Classe A, caso tenha 3 da Classe B 2 da A e 1 da C, será escolhido o que tiver maior número de classes no caso será classificado como a classe B.

Random Forest é uma variação de outro algoritmo de Machine Learning, o Decision Tree, porém optei por colocar esse por ter uma performasse melhor. Ele irá fazer um cálculo para saber qual é a feature determinante para a escolha de classficação. Escolhido o feature, então a rede cria ramos para cada possibilidade que essa feature possibilita, por exemplo se essa feature for "Cor" poderia se separar entre "Vermelho","Verde","Azul", e a partir dessa separação irá se calcular qual a segunda principal feature para cada ramo que classifica os dados e assim criando outros ramos e se repetindo para todas as features selecionadas. A diferença do Random Forest para o Decision Tree é que neste vão todas as linhas e colunas do seu dataset de treino enquanto aquele é separado vários datasets menores (um parâmetro que pode ser alterdo no código) na qual tem linhas e colunas escolhidas aleatoriamente.
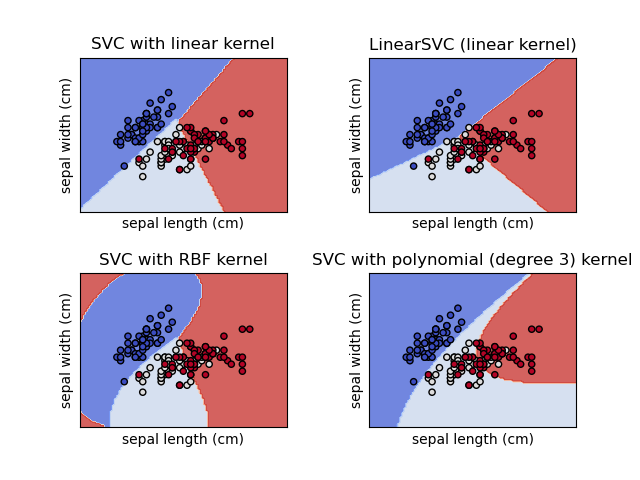
Support Vector Machine é um algoritmo que vai tentar encontrar o hiperplano com menor distância que separa as classes. Ele foi pensando, inicialmente, para conseguir separar usando retas (em 2 dimensões é uma reta mas em 3 é um plano) para separar as classes, hoje em dia é possível separar usando formatos polinomiais ou usando a função sigmoide.

Regressão logística é um algoritmo que tenta prever o caso de uma classe binária, na qual tenta fazer com que oos dados se comportem como uma função 1/(1+e^-x). No nosso caso isso não seria suficiente e por isso usaremos a versão de Multiclasse. Faremos a classficicação utilizando da mesma estratégia da Regressão Logística no caso binário de pertencer ou não a uma determinada classe e faremos isso para todas as classes e todos os dados. A partir disso como a função 1/(1+e^-x) está entre 0 e 1 podemos interpretar como uma probabilidade, a probabilidade de um dado pertencer a uma classe. Com isso aplicaremos a função softmax e calcularemos qual a classe tem maior probabilidade e classificaremos cada dado assim.
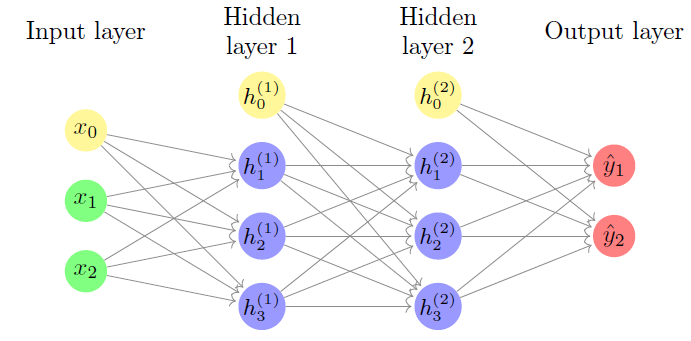
As Redes Neurais tentão simular como seria o aprendizado do nosso cérebro. Nessa estrutura, os padrões são introduzidos na rede neural pela camada de entrada e é comunicada a uma ou mais camadas ocultas presente na rede. As camadas ocultas recebem este nome somente por não constituírem a camada de entrada ou saída, são como camadas intermediárias. São nestas camadas que todo o processamento acontece por meio de um sistema de conexões dos chamados pesos e vieses. A entrada é recebida, o neurônio calcula uma soma ponderada adicionando também o viés e de acordo com o resultado e uma função de ativação predefinida, ele decide se deve ser 'disparado' ou ativado. Posteriormente, o neurônio transmite a informação para outros neurônios conectados em um processo chamado “forward pass”. Ao final desse processo, a última camada oculta é vinculada à camada de saída que possui um neurônio para cada saída possível desejada, tornando, assim, a previsão possível.
KOKLU, M., KURSUN, R., TASPINAR, Y. S., and CINAR, I. (2021). Classification of Date Fruits into Genetic Varieties Using Image Analysis. Mathematical Problems in Engineering, Vol.2021, Article ID: 4793293, DOI:10.1155/2021/4793293 https://en.wikipedia.org/wiki/Support-vector_machine https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm https://en.wikipedia.org/wiki/Neural_network https://en.wikipedia.org/wiki/Logistic_regression https://en.wikipedia.org/wiki/Random_forest