Examples demonstrating how to optimize caffe/tensorflow/darknet models with TensorRT and run inferencing on NVIDIA Jetson or x86_64 PC platforms.
- Run an optimized "yolov4-416" object detector at ~4.6 FPS on Jetson Nano.
- Run an optimized "yolov3-416" object detector at ~4.9 FPS on Jetson Nano.
- Run an optimized "ssd_mobilenet_v1_coco" object detector ("trt_ssd_async.py") at 27~28 FPS on Jetson Nano.
- Run a very accurate optimized "MTCNN" face detector at 6~11 FPS on Jetson Nano.
- Run an optimized "GoogLeNet" image classifier at "~16 ms per image (inference only)" on Jetson Nano.
- In addition to Jetson Nano, all demos also work on Jetson TX2, AGX Xavier, Xavier NX (link and link), and run much faster!
- All demos work on x86_64 PC with NVIDIA GPU(s) as well. Some minor tweaks would be needed. Please refer to README_x86.md for more information.
[2020-08-18 update] I have optimized my "Camera" module code. As a result, the FPS numbers of the TensorRT yolov3/yolov4 models have been improved. With this particular update, I've also simplified the command-line arguments and the API of the Camera. Please refer to step 5 of Demo #1 for details.
The code in this repository was tested on Jetson Nano, TX2, and Xavier NX DevKits. In order to run the demos below, first make sure you have the proper version of image (JetPack) installed on the target Jetson system. For example, Setting up Jetson Nano: The Basics and Setting up Jetson Xavier NX.
More specifically, the target Jetson system must have TensorRT libraries installed.
- Demo #1 and Demo #2: works for TensorRT 3.x+,
- Demo #3: requires TensoRT 5.x+,
- Demo #4 and Demo #5: requires TensorRT 6.x+.
You could check which version of TensorRT has been installed on your Jetson system by looking at file names of the libraries. For example, TensorRT v5.1.6 (JetPack-4.2.2) was present on one of my Jetson Nano DevKits.
$ ls /usr/lib/aarch64-linux-gnu/libnvinfer.so*
/usr/lib/aarch64-linux-gnu/libnvinfer.so
/usr/lib/aarch64-linux-gnu/libnvinfer.so.5
/usr/lib/aarch64-linux-gnu/libnvinfer.so.5.1.6Furthermore, all demo programs in this repository require "cv2" (OpenCV) module for python3. You could use the "cv2" module which came in the JetPack. Or, if you'd prefer building your own, refer to Installing OpenCV 3.4.6 on Jetson Nano for how to build from source and install opencv-3.4.6 on your Jetson system.
If you plan to run Demo #3 (SSD), you'd also need to have "tensorflow-1.x" installed. You could probably use the official tensorflow wheels provided by NVIDIA, or refer to Building TensorFlow 1.12.2 on Jetson Nano for how to install tensorflow-1.12.2 on the Jetson system.
Or if you plan to run Demo #4 and Demo #5, you'd need to have "protobuf" installed. I recommend installing "protobuf-3.8.0" using my install_protobuf-3.8.0.sh script. This script would take a couple of hours on a Jetson system. Alternatively, pip3 install a recent version of "protobuf" should also work (but might run a little bit slowlier).
I use Python 3.6 as my primary test environment. I think other versions of python3 would likely just work without any problem.
In case you are setting up a Jetson Nano or Jetson Xavier NX from scratch to run these demos, you could refer to the following blog posts. They contain the exact steps I applied when I did the testing of JetPack-4.3 and JetPack-4.4.
This demo illustrates how to convert a prototxt file and a caffemodel file into a TensorRT engine file, and to classify images with the optimized TensorRT engine.
Step-by-step:
-
Clone this repository.
$ cd ${HOME}/project $ git clone https://github.com/jkjung-avt/tensorrt_demos $ cd tensorrt_demos
-
Build the TensorRT engine from the pre-trained googlenet (ILSVRC2012) model. Note that I downloaded the pre-trained model files from BVLC caffe and have put a copy of all necessary files in this repository.
$ cd ${HOME}/project/tensorrt_demos/googlenet $ make $ ./create_engine
-
Build the Cython code. Install Cython if not previously installed.
$ sudo pip3 install Cython $ cd ${HOME}/project/tensorrt_demos $ make
-
Run the "trt_googlenet.py" demo program. For example, run the demo using a USB webcam (/dev/video0) as the input.
$ cd ${HOME}/project/tensorrt_demos $ python3 trt_googlenet.py --usb 0 --width 1280 --height 720
Here's a screenshot of the demo (JetPack-4.2.2, i.e. TensorRT 5).
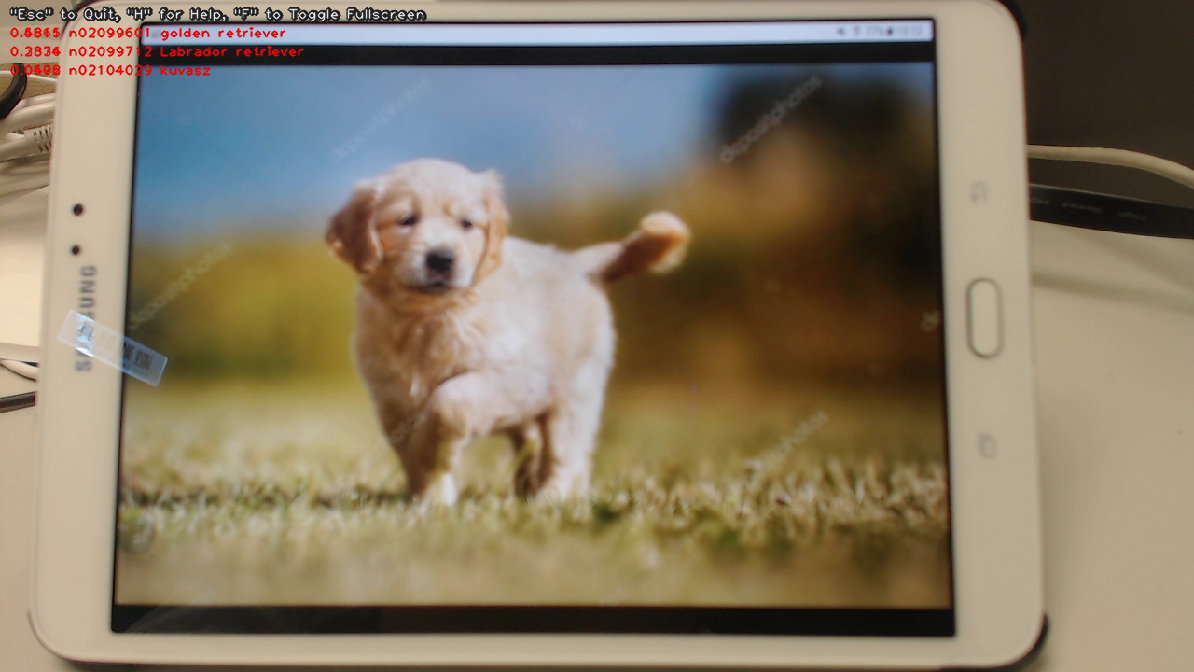
-
The demo program supports 5 different image/video inputs. You could do
python3 trt_googlenet.py --helpto read the help messages. Or more specifically, the following inputs could be specified:--image test_image.jpg: an image file, e.g. jpg or png.--video test_video.mp4: a video file, e.g. mp4 or ts. An optional--video_loopingflag could be enabled if needed.--usb 0: USB webcam (/dev/video0).--rtsp rtsp://admin:123456@192.168.1.1/live.sdp: RTSP source, e.g. an IP cam. An optional--rtsp_latencyargument could be used to adjust the latency setting in this case.--onboard 0: Jetson onboard camera.
In additional, you could use
--widthand--heightto specify the desired input image size, and use--do_resizeto force resizing of image/video file source.The
--usb,--rtspand--onboardvideo sources usually produce image frames at 30 FPS. If the TensorRT engine inference code runs faster than that (which happens easily on a x86_64 PC with a good GPU), one particular image could be inferenced multiple times before the next image frame becomes available. This causes problem in the object detector demos, since the original image could have been altered (bounding boxes drawn) and the altered image is taken for inference again. To cope with this problem, use the optional--copy_frameflag to force copying/cloning image frames internally. -
Check out my blog post for implementation details:
This demo builds upon the previous one. It converts 3 sets of prototxt and caffemodel files into 3 TensorRT engines, namely the PNet, RNet and ONet. Then it combines the 3 engine files to implement MTCNN, a very good face detector.
Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", follow these steps:
-
Build the TensorRT engines from the pre-trained MTCNN model. (Refer to mtcnn/README.md for more information about the prototxt and caffemodel files.)
$ cd ${HOME}/project/tensorrt_demos/mtcnn $ make $ ./create_engines
-
Build the Cython code if it has not been done yet. Refer to step 3 in Demo #1.
-
Run the "trt_mtcnn.py" demo program. For example, I grabbed from the internet a poster of The Avengers for testing.
$ cd ${HOME}/project/tensorrt_demos $ python3 trt_mtcnn.py --image ${HOME}/Pictures/avengers.jpg
Here's the result (JetPack-4.2.2, i.e. TensorRT 5).

-
The "trt_mtcnn.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 for details.
-
Check out my related blog posts:
This demo shows how to convert pre-trained tensorflow Single-Shot Multibox Detector (SSD) models through UFF to TensorRT engines, and to do real-time object detection with the TensorRT engines.
NOTE: This particular demo requires TensorRT "Python API", which is only available in TensorRT 5.x+ on the Jetson systems. In other words, this demo only works on Jetson systems properly set up with JetPack-4.2+, but not JetPack-3.x or earlier versions.
Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", follow these steps:
-
Install requirements (pycuda, etc.) and build TensorRT engines from the pre-trained SSD models.
$ cd ${HOME}/project/tensorrt_demos/ssd $ ./install.sh $ ./build_engines.sh
NOTE: On my Jetson Nano DevKit with TensorRT 5.1.6, the version number of UFF converter was "0.6.3". When I ran "build_engine.py", the UFF library actually printed out:
UFF has been tested with tensorflow 1.12.0. Other versions are not guaranteed to work.So I would strongly suggest you to use tensorflow 1.12.x (or whatever matching version for the UFF library installed on your system) when converting pb to uff. -
Run the "trt_ssd.py" demo program. The demo supports 4 models: "ssd_mobilenet_v1_coco", "ssd_mobilenet_v1_egohands", "ssd_mobilenet_v2_coco", or "ssd_mobilenet_v2_egohands". For example, I tested the "ssd_mobilenet_v1_coco" model with the "huskies" picture.
$ cd ${HOME}/project/tensorrt_demos $ python3 trt_ssd.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \ --model ssd_mobilenet_v1_coco
Here's the result (JetPack-4.2.2, i.e. TensorRT 5). Frame rate was good (over 20 FPS).

NOTE: When running this demo with TensorRT 6 (JetPack-4.3) on the Jetson Nano, I encountered the following error message which could probably be ignored for now. Quote from NVIDIA's NVES_R:
This is a known issue and will be fixed in a future version.[TensorRT] ERROR: Could not register plugin creator: FlattenConcat_TRT in namespaceI also tested the "ssd_mobilenet_v1_egohands" (hand detector) model with a video clip from YouTube, and got the following result. Again, frame rate was pretty good. But the detection didn't seem very accurate though :-(
$ python3 trt_ssd.py --video ${HOME}/Videos/Nonverbal_Communication.mp4 \ --model ssd_mobilenet_v1_egohands(Click on the image below to see the whole video clip...)

-
The "trt_ssd.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 again.
-
Referring to this comment, "#TODO enable video pipeline", in the original TRT_object_detection code, I did implement an "async" version of ssd detection code to do just that. When I tested "ssd_mobilenet_v1_coco" on the same huskies image with the async demo program on the Jetson Nano DevKit, frame rate improved 3~4 FPS.
$ cd ${HOME}/project/tensorrt_demos $ python3 trt_ssd_async.py --image ${HOME}/project/tf_trt_models/examples/detection/data/huskies.jpg \ --model ssd_mobilenet_v1_coco
-
To verify accuracy (mAP) of the optimized TensorRT engines and make sure they do not degrade too much (due to reduced floating-point precision of "FP16") from the original TensorFlow frozen inference graphs, you could prepare validation data and run "eval_ssd.py". Refer to README_mAP.md for details.
I compared mAP of the TensorRT engine and the original tensorflow model for both "ssd_mobilenet_v1_coco" and "ssd_mobilenet_v2_coco" using COCO "val2017" data. The results were good. In both cases, mAP of the optimized TensorRT engine matched the original tensorflow model. The FPS (frames per second) numbers in the table were measured using "trt_ssd_async.py" on my Jetson Nano DevKit with JetPack-4.3.
TensorRT engine mAP @
IoU=0.5:0.95mAP @
IoU=0.5FPS on Nano mobilenet_v1 TF 0.232 0.351 -- mobilenet_v1 TRT (FP16) 0.232 0.351 27.7 mobilenet_v2 TF 0.248 0.375 -- mobilenet_v2 TRT (FP16) 0.248 0.375 22.7 -
Check out my blog posts for implementation details:
- TensorRT UFF SSD
- Speeding Up TensorRT UFF SSD
- Verifying mAP of TensorRT Optimized SSD and YOLOv3 Models
- Or if you'd like to learn how to train your own custom object detectors which could be easily converted to TensorRT engines and inferenced with "trt_ssd.py" and "trt_ssd_async.py": Training a Hand Detector with TensorFlow Object Detection API
(Merged with Demo #5: YOLOv4...)
Along the same line as Demo #3, these 2 demos showcase how to convert pre-trained yolov3 and yolov4 models through ONNX to TensorRT engines. The code for these 2 demos has gone through some significant changes. More specifically, I have recently updated the implementation with a "yolo_layer" plugin to speed up inference time of the yolov3/yolov4 models.
My current "yolo_layer" plugin implementation is based on TensorRT's IPluginV2IOExt. It only works for TensorRT 6+. I'm thinking about updating the code to support TensorRT 5 if I have time late on.
I developed my "yolo_layer" plugin by referencing similar plugin code by wang-xinyu and dongfangduoshou123. So big thanks to both of them.
Assuming this repository has been cloned at "${HOME}/project/tensorrt_demos", follow these steps:
-
Install "pycuda" in case you haven't done so in Demo #3. Note that the installation script resides in the "ssd" folder.
$ cd ${HOME}/project/tensorrt_demos/ssd $ ./install_pycuda.sh
-
Install version "1.4.1" (not the latest version) of python3 "onnx" module. Note that the "onnx" module would depend on "protobuf" as stated in the Prerequisite section. Reference: information provided by NVIDIA.
$ sudo pip3 install onnx==1.4.1
-
Go to the "plugins/" subdirectory and build the "yolo_layer" plugin. When done, a "libyolo_layer.so" would be generated.
$ cd ${HOME}/project/tensorrt_demos/plugins $ make
-
Download the pre-trained yolov3/yolov4 COCO models and convert the targeted model to ONNX and then to TensorRT engine. I use "yolov4-416" as example below. (Supported models: "yolov3-tiny-288", "yolov3-tiny-416", "yolov3-288", "yolov3-416", "yolov3-608", "yolov3-spp-288", "yolov3-spp-416", "yolov3-spp-608", "yolov4-tiny-288", "yolov4-tiny-416", "yolov4-288", "yolov4-416", "yolov4-608", and custom models such as "yolov4-416x256".)
$ cd ${HOME}/project/tensorrt_demos/yolo $ ./download_yolo.sh $ python3 yolo_to_onnx.py -m yolov4-416 $ python3 onnx_to_tensorrt.py -m yolov4-416
The last step ("onnx_to_tensorrt.py") takes a little bit more than half an hour to complete on my Jetson Nano DevKit. When that is done, the optimized TensorRT engine would be saved as "yolov4-416.trt".
-
Test the TensorRT "yolov4-416" engine with the "dog.jpg" image.
$ wget https://raw.githubusercontent.com/pjreddie/darknet/master/data/dog.jpg -O ${HOME}/Pictures/dog.jpg $ python3 trt_yolo.py --image ${HOME}/Pictures/dog.jpg \ -m yolov4-416
This is a screenshot of the demo against JetPack-4.4, i.e. TensorRT 7.

-
The "trt_yolo.py" demo program could also take various image inputs. Refer to step 5 in Demo #1 again.
-
(Optional) Test other models than "yolov4-416".
-
Similar to step 5 of Demo #3, I created an "eval_yolo.py" for evaluating mAP of the TensorRT yolov3/yolov4 engines. Refer to README_mAP.md for details.
$ python3 eval_yolo.py -m yolov3-tiny-288 $ python3 eval_yolo.py -m yolov4-tiny-416 ...... $ python3 eval_yolo.py -m yolov4-608
I evaluated all these TensorRT yolov3/yolov4 engines with COCO "val2017" data and got the following results. I also checked the FPS (frames per second) numbers on my Jetson Nano DevKit with JetPack-4.4 (TensorRT 7).
TensorRT engine mAP @
IoU=0.5:0.95mAP @
IoU=0.5FPS on Nano yolov3-tiny-288 (FP16) 0.077 0.158 35.8 yolov3-tiny-416 (FP16) 0.096 0.201 25.5 yolov3-288 (FP16) 0.331 0.600 8.16 yolov3-416 (FP16) 0.373 0.663 4.93 yolov3-608 (FP16) 0.376 0.664 2.53 yolov3-spp-288 (FP16) 0.339 0.594 8.16 yolov3-spp-416 (FP16) 0.391 0.663 4.82 yolov3-spp-608 (FP16) 0.409 0.685 2.49 yolov4-tiny-288 (FP16) 0.178 0.344 36.6 yolov4-tiny-416 (FP16) 0.195 0.386 25.5 yolov4-288 (FP16) 0.371 0.590 7.93 yolov4-416 (FP16) 0.453 0.698 4.62 yolov4-608 (FP16) 0.483 0.735 2.35 -
Check out my blog posts for implementation details:
- TensorRT ONNX YOLOv3
- TensorRT YOLOv4
- Verifying mAP of TensorRT Optimized SSD and YOLOv3 Models
- For adapting the code to your own custom trained yolov3/yolov4 models: TensorRT YOLOv3 For Custom Trained Models

I referenced source code of NVIDIA/TensorRT samples to develop most of the demos in this repository. Those NVIDIA samples are under Apache License 2.0.