Achieving Connectivity Magic
daviddias opened this issue · 36 comments
I ran an impromptu and presidential design session with @alanshaw, @olizilla and @achingbrain to walk through some of the design decisions on libp2p and we ended up discussing the Connectivity Magic Objective and what exactly I mean by "creativity".
The tl;dr; there are multiple ways to find file, but all of them have tradeoffs.
Here is the sketch we ended up doing:

Here is an annotated version:

I can make a quick video explaining this, but perhaps it would be more valuable to have @alanshaw, @olizilla and @achingbrain explain this to @hugomrdias (who owns the KR to get files from the gateways) through a Zoom Recorded Call or Text, so that we check that the memes have indeed been transferred :)
The focus should be around on why the shortcoming exists and the 3 solutions on the solution spectrum (from hacky to ideal but not necessarily memory efficient).
It took me a while to see this: the three steps proposed are: 1) routing via DNS records 2) delegated routing 3) proper DHT routing
Everyone, thank you for the really awesome sync up. It was lovely to see how everyone came up together so quickly, communicated well their concerns and proposed solutions and eventually converged in a good set of next steps 👏🏽👏🏽👏🏽❤️❤️❤️.
We converged on an alternative solution to (1), we named it 1.5. The gist of it is that we will use preload gateways (aka caching) to get that Connectivity Magic feeling. The action items are:
- @lgierth Deploy "Pre Load gateways" preload.gateway.ipfs.io and update the js-ipfs team as soon as its there.
-
js-ipfs teamAdd new the gateways to the bootstrapper list and hit the preload gateway on every add/get/cat (+ dag.get/put) (like companion does) -
js-ipfs teamrelease js-ipfs 0.31 - @hugomrdias integrate it all on js.ipfs.io
Note on hitting the preload gateway: Use the "x-ipfs-companion-no-redirect" to avoid getting the preload gateway hit redirected to the local daemon.
Here's the pros/cons of 1a) always connecting to ipfs.io gateways, and 1b) separate preload gateways, that were mentioned in the call:
- ipfs.io gateways
- Pro: very easy
- Con: have no PeerIDs in js-ipfs code, but instead fetch fully-qualified multiaddrs from dnsaddrs. Means we can't authenticate these dnsaddr responses.
- Con: have to connect to all ipfs.io gateway nodes, 8 at the moment, but want to add more capacity for Dweb Summit
- Con: coupling libp2p routing cleverness to the gateways, which was a pain for infra team in the past
- preload gateways
- Con: need to add HEAD requests to add/get/cat/dag.get/dag.put
- Pro: can have full addresses of these nodes in js-ipfs code, no dnsaddr requests needed
- Pro: only one connection to a preload node needed
- Pro: can have different garbage collection settings than the ipfs.io gateways
While I'm setting up these preload gateways, you can use the old OVH gateway nodes for testing: the wss0,wss1 addresses in js-ipfs bootstrap config. These run the gateway on :443/ipfs, right next to the /ws transport on :443/ws.
They're crappy fault-prone hardware and will be decomissioned soon, but should be good enough for a few days.
+1
Can we call them "storage peers" rather than "prefetch gateways"? It's confusing to me to use the term gateway when we mean HTTP to IPFS translation, and it seems that storing files directly on the gateways has been the cause of some trouble.
As I see it we are proposing to add some "stable bootstrap peers with a good chunk of storage" to the network that will expose an http interface just to allow us to poke them out of band to trigger a request to fetch content from connected browser nodes.
These "storage peers" will (hopefully, usually) be in the swarm for all the gateway nodes too, so that requests for the content sent to the regular gateway will be 1 hop away (rather than 0 as they used to be, or n as they are currently)... It's not imagined that we'll be using the http address for the storage peers for general purpose http-to-ipfs content access in browsers, that'll still be the job of the regular gateway nodes.
So to clarify, we'd add all of the gateways to the bootstrap list, but HEAD request just one of those after add/get/cat/dag.get/dag.put?
- How do we know which one was HEAD requested (and does that matter)?
- After the HEAD request will we then be able to fetch content over HTTP from ipfs.io, or would we typically request it via the prefetch node? Both I presume but the prefetch would be faster?
Notes on redirect opt-out in Companion and preload:
x-ipfs-companion-no-redirectcan be put in URL as a hash or query parameter – hash semantic is bit better as it does not leave the browser, it is just a hint for Cpmpanion- preload via asynchronous XHR with cheap HTTP HEAD for a CID should be enough, that is what Companion did before gateways were re-architected and preload worked perfectly back then
So, unfortunately JFK Terminal 1 has roughly three power outlets so I can't work on this tonight.
I'll have addresses for you tomorrow morning-ish (http for the preload requests and dnsaddr for peering). We don't have proper hosts for this provisioned yet, but in the meantime the old gateway hosts can be used for testing.
Can we call them "storage peers" rather than "prefetch gateways"?
Let's do preload peers -- not calling them gateways is fair, but "storage" would give a false sense of permanence.
HEAD requests
By the way, a strong alternative to this is calling /api/v0/refs?r=true&arg=QmFoo on the preload peer, and waiting for the complete response to stream in.
@lgierth do you know if ipfs refs --recursive preloads data for entire tree (with leaves), or everything-but-leaves?
do you know if ipfs refs --recursive preloads data for entire tree (with leaves), or everything-but-leaves?
Yes it loads every block that's referenced in that dag -- the nice thing is it enables progress reporting on the "client" side, since you already know the set of all CIDs, and cam compare how much has been fetched already.
Can I get a quick check in on the status of #1459 (comment) ?
- I'm waiting on the new node addresses - @lgierth gave me two addresses but the domain
preload.ipfs.iois not resolving yet - PR ready for review for preloading on
ipfs.add*#1464 - PR ready for review for preloading
mfs.*anddag.put#1468 - PR for
block.put,object.new,object.put,object.patch.*coming shortly - WIP on writing release notes for 0.31 #1458
do you know if ipfs refs --recursive preloads data for entire tree (with leaves), or everything-but-leaves?
Yes it loads every block that's referenced in that dag -- the nice thing is it enables progress reporting on the "client" side, since you already know the set of all CIDs, and cam compare how much has been fetched already.
When we're adding content to IPFS, we don't really want to wait around for it to be uploaded to the preload nodes which is why a HEAD request is nice because it's quick and light and the content can then be slurped from my node asynchronously.
In companion we HEAD request for every CID added, but is this necessary?
Looking at the code it looks as though if you send a HEAD reuqest to a js-ipfs gateway it would load the CID as well as it's descendants (because it doesn't differentiate between HEAD and GET).
it would load the CID as well as it's descendants (because it doesn't differentiate between HEAD and GET).
Actually, HEAD is even a bit more diligent than GET -- the former reads the whole node to calculdate Content-Length, the latter reads only what it has to in order to satisfy the request.
Both don't read into directories, i.e. if you get a directory index, none of the children or subdirs are fetched.
@lgierth gave me two addresses but the domain preload.ipfs.io is not resolving yet
Ah yes -- there's now A/AAAA records for preload.ipfs.io, so if you're connected to all preloader peer in _dnsaddr.preload.ipfs.io, you're sure to hit home.
There is a slightly different option which is individual A/AAAA records for each preloader peer. That'd let you connect to only one preloader peer, and make HTTP requests to exactly that one, instead of connecting to all of them.
These preload peers are now reachable:
/dns4/node0.preload.ipfs.io/tcp/443/wss/ipfs/QmZMxNdpMkewiVZLMRxaNxUeZpDUb34pWjZ1kZvsd16Zic
/dns4/node1.preload.ipfs.io/tcp/443/wss/ipfs/Qmbut9Ywz9YEDrz8ySBSgWyJk41Uvm2QJPhwDJzJyGFsD6
https://node0.preload.ipfs.io/ipfs
https://node1.preload.ipfs.io/ipfs
If js-ipfs can resolve /dnsaddr, these addresses can be shortened to:
/dnsaddr/preload.ipfs.io/ipfs/QmZMxNdpMkewiVZLMRxaNxUeZpDUb34pWjZ1kZvsd16Zic
/dnsaddr/preload.ipfs.io/ipfs/Qmbut9Ywz9YEDrz8ySBSgWyJk41Uvm2QJPhwDJzJyGFsD6
Note that the PeerIDs will change sometime later today as we get the new hosts up -- right now this is two crappy old OVH hosts that I actually want to get rid of. I'll notify here once the PeerIDs are changing.
Sorry I'm a bit late to the party.
@alanshaw Is there a quick and dirty way of making this work on the latest js-ipfs?
It's gonna be in 0.31 very very soon: #1459 (comment)
Update about the PeerID changes mentioned above -- we will not change the PeerIDs, and will keep the PeerIDs mentioned above.
This means the addresses above in #1459 (comment) are the correct ones for the release.
This also means you can safely remove the wss0.bootstrap.libp2p.io and wss1.bootstrap.libp2p.io nodes from any configs, since we'll be shutting these two hosts down, and move their private keys and PeerIDs over to the new preloader hosts.
- This also means you can safely remove the wss0.bootstrap.libp2p.io and wss1.bootstrap.libp2p.io nodes from any configs -> Done
The CORS issue should be fixed
I'm using latest 0.31.0 js-ipfs. Using the files API, I created a bunch of files and a directory with success.
I tried loading it in the gateway, but to no avail.
Please see attached network activity screenshot:
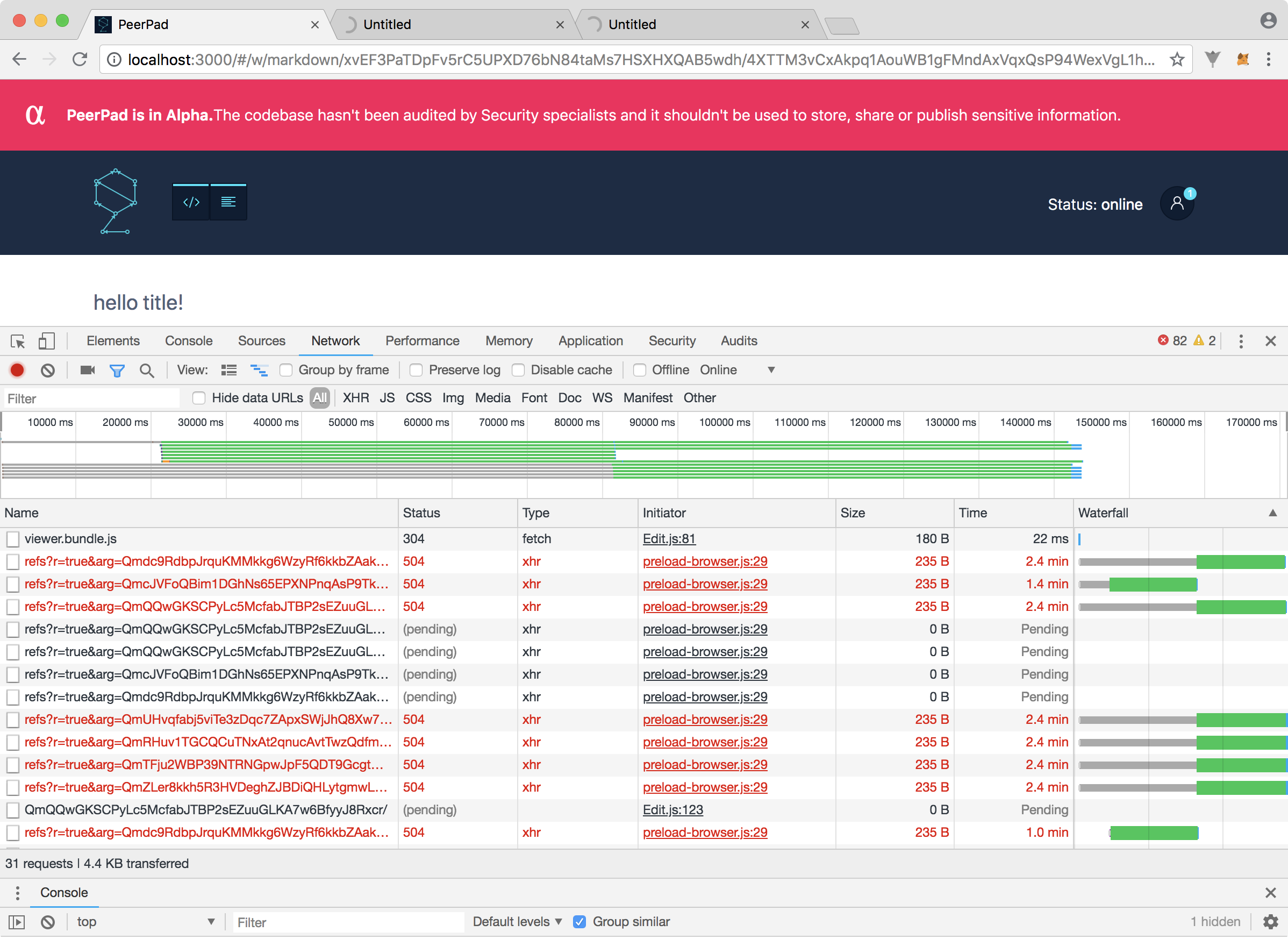
Fewer screenshots, more logs!
Which hosts are these requests going against?
@pgte if you turn on debugging localStorage.debug = 'jsipfs:preload*' you should see errors logged for each of those failed requests with a little more info.
Is there a branch I can checkout to run this code and see for myself?
Also, may I kindly ask that you open a separate issue for this?
is the overall preload lifecycle as it operates currently documented somewhere? (other than https://github.com/ipfs/js-ipfs/blob/2a061520ddea2c3dcafa6f3657551865f33ecca9/README.md#optionspreload)
the main part that I am having trouble with is reasoning about the differences between .add and .get scenarios: most of the discussion focuses on .add (i.e. "added a file to local/browser js node and closed laptop" case where the remote node that we are wss-conntected to pins/caches our content)
however, we also issue the same preload calls on .get: (i.e. "trying to access files somewhere on the DHT" case where we ask the remote wss-connected node to find stuff in the dht for us and cache it)
uniting these two cases (to the extent that the remote can't tell which is which) seems confusing because the direction of data flow is different in each, and the cache lifetime requirements may be quite different (in the .get case you only really need it for the lifetime of whatever the js client is doing, but in the .add case there may be an expectation of macro-scale persistence)
EDIT: bleh meant to post this last weds but chrome just left it in the form?
I'm not sure I understand the question...
- preload on add effectively pushes your data up to the preload nodes for others to consume
- preload on get prompts the preload nodes to fetch the data from a different node
The both solve the problem of connecting nodes to content without a DHT.
@alanshaw I guess it's confusing from a REST verb perspective -- what looks like the same GET call actually represents two different directions of data movement (which also happens out of band from the HTTP request itself), one from your node up to the server (kind of an upload/PUT) and one between some other node and the server (kind of a sideload/???)
at minimum, it's difficult to tell what's happening based on network requests in the console (are these preloads firing because I'm adding things or because I'm attempting to fetch?)
imagine a page that both .gets and .adds some content and preloads are failing (e.g. #1481); some content is also failing to load -- is it because of the failed preloads or something else?
I get that in a sense it doesn't matter and causing a remote .get on a node that you have a p2p connection to is an elegant solution to both problems, but I've found it difficult to reason about in practice
what about adding a (ignored) parameter like ?trigger=add to the URL so it's clear why it's happening?
at minimum, we should add a description of both scenarios here because it is not at all obvious that both can happen
@alanshaw here's another preload related question -- how long is data retained by the remote nodes? is it just a normal pin? do they announce to DHT?
Posting this here for discoverability:
What are the "preload" nodes and why are they necessary to run js-ipfs?
see #1874 (comment)
cc relevant topics:
- Decentralized WebRTC Signaling Protocol: libp2p/specs#159
- Saving previously seen nodes for later bootstrapping ipfs/kubo#3926
- Persist routing table between restarts libp2p/go-libp2p-kad-dht#254
Not a blocker but relevant to the thread libp2p/js-libp2p#385
Closing this because it is very stale.
We now live in the future where browser nodes can dial server nodes via WebTransport and WebRTC without any extra setup a la WebSockets so as these transports proliferate, connectivity will too. Magic!