
Air merupakan salah satu kebutuhan dasar bagi setiap makhluk hidup, tidak terkecuali manusia. Dapat dipastikan manusia tidak akan mampu bertahan hidup tanpa air, karena air merupakan salah satu elemen dasar yang menunjang proses metabolisme tubuh manusia. Ketergantungan manusia terhadap air bersih tidak hanya berhenti pada kebutuhan biologis semata.
Air memiliki peranan yang penting dalam perekonomian. Penyediaan pangan dari yang paling sederhana berupa ladang dan tegalan, hingga pertanian modern berupa sawah maupun penanaman hidroponik pasti membutuhkan air. Sektor industri juga tak dapat lepas dari ketergantungan terhadap air. Bahkan perkembangan suatu wilayah juga ditentukan oleh ketersediaan air bersih yang memadai. Begitu besarnya ketergantungan manusia terhadap air disebabkan oleh sifat air yang tidak dapat disubstitusi dengan barang yang lain.
Seiring meningkatnya populasi manusia maka tingkat kebutuhan terhadap air bersih juga semakin tinggi. Saat ini di berbagai belahan dunia muncul fenomena kelangkaan air. Pada tahun 1998, sebanyak 208 negara mengalami kesulitan atau kelangkaan air, dan diperkirakan akan bertambah 56 negara pada tahun 2025. Pada rentang waktu tahun 1990 hingga 2025, jumlah orang yang yang hidup di negara yang kekurangan air diperkirakan akan meningkat dari 131 juta jiwa menjadi 817 juta jiwa. Fenomena kelangkaan air saat ini telah menjadi isu global yang menjadi permasalahan bersama. Indonesia ternyata juga mengalami permasalahan dengan air. Tentunya kondisi kurangnya sumber daya air yang dapat dimanfaatkan memerlukan sebuah pengelolaan yang memadai untuk mencukupi kebutuhan akan air bersih. Upaya pemenuhan kebutuhan air bersih ini seringkali tidak hanya dihadapkan pada kurangnya sumber air yang dapat dieksploitasi, namun juga kurangnya sumber daya lainnya, seperti modal dan sumber daya manusia yang tidak mendukung upaya pemenuhan kebutuhan air bersih. Pada daerah yang miskin dan jauh dari pusat pelayanan publik, kurangnya sumber air menjadi masalah yang tidak mudah untuk dipecahkan. Pembangunan infrastruktur penunjang upaya pemenuhan kebutuhan air bersih merupakan investasi yang sangat tidak menguntungkan bagi sektor privat untuk dapat mengambil bagian, karena tingkat pengembalian investasi yang sangat kecil.
Di Indonesia, tepatnya di bogor pada tahun 2018 terdapat pengamatan langsung pada air Saluran Kali Bokor, perubahan fisik sudah terjadi antara lain warna air yang tidak jernih, bau yang tidak sedap, serta estetika yang sudah tak layak pandang. Masyarakat sekitar pun mulai mengeluh akibat perubahan fisik yang terjadi pada air Saluran Kali Bokor tersebut. Peraturan Pemerintah Nomor 82 (2001) mengenai Pengelolaan Kualitas Air dan Pengendalian Air menyebutkan bahwa setiap penganggung jawab usaha dan/atau kegiatan yang membuang air limbah ke air atau sumber air wajib mencegah dan menanggulangi terjadinya pencemaran air. Pada kenyataannya, memang masih banyak masyarakat belum bertanggung jawab menangani limbah yang dihasilkan. Upaya pembersihan pada saluran tersebut belum pernah dilakukan. Upaya pengelolaan kualitas air belum pernah dilaksanakan. Selain itu, masyarakat masih terus membuang limbahnya ke sungai tanpa melakukan pengolahan (Rizal, 2018).
Pengaruh tidak langsung adalah pengaruh yang timbul sebagai akibat pendayagunaan air yang dapat meningkatkan ataupun menurunkan kesejahteraan masyarakat. Misalnya air yang dimanfaatkan untuk pembangkit tenaga listrik, industri, irigasi, perikanan, pertanian, dan rekreasi. Pemanfaat air untuk hal tersebut diatas dapat meningkatkan kesejahteraan dan kesehatan masyarakat. Sebaliknya pengotoran dan pencemaran air dapat menurunkan kesejahteraan hidup manusia.
Air jernih yang kita lihat sehari-hari, yang biasa kita minum, apakah sudah bener-benar sehat dan juga layak untuk kita konsumsi? Dari mana kita tahu air tersebut memang bersih. Mengutip Keputusan Menteri Kesehatan Republik Indonesia Nomor 1405/menkes/sk/xi/2002 tentang Persyaratan Kesehatan Lingkungan Kerja Perkantoran dan industri terdapat pengertian mengenai Air Bersih yaitu air yang dipergunakan untuk keperluan sehari-hari dan kualitasnya memenuhi persyaratan kesehatan air bersih sesuai dengan peraturan perundang-undangan yang berlaku dan dapat diminum apabila dimasak. Air bersih disini kita kategorikan hanya untuk yang layak dikonsumsi, bukan layak untuk digunakan sebagai penunjang aktifitas seperti untuk MCK. Karena standar air yang digunakan untuk konsumsi jelas lebih tinggi dari pada untuk keperluan selain dikonsumsi. Ada beberapa persyaratan yang perlu diketahui mengenai kualitas air tersebut baik secara fisik, kimia dan juga mikrobiologi. Berikut beberapa syarat dari beragam kriteria tentang air yang layak dikonsumsi oleh manusia :
- Syarat fisik, antara lain:
- Air harus bersih dan tidak keruh
- Tidak berwarna apapun
- Tidak berasa apapun
- Tidak berbau apaun
- Suhu antara 10-25 C (sejuk)
- Tidak meninggalkan endapan
- Syarat kimiawi, antara lain:
- Tidak mengandung bahan kimiawi yang mengandung racun
- Tidak mengandung zat-zat kimiawi yang berlebihan
- Cukup yodium
- pH air antara 6,5 – 9,2
- Syarat mikrobiologi, antara lain:
- Tidak mengandung kuman-kuman penyakit seperti disentri, tipus, kolera, dan bakteri patogen penyebab penyakit.
Seperti kita ketahui jika standar mutu air sudah diatas standar atau sesuai dengan standar tersebut maka yang terjadi adalah akan menentukan besar kecilnya investasi dalam pengadaan air bersih tersebut, baik instalasi penjernihan air dan biaya operasi serta pemeliharaannya. Sehingga semakin jelek kualitas air semakin berat beban masyarakat untuk membayar harga jual air bersih. Dalam penyediaan air bersih yang layak untuk dikonsumsi oleh masyarakat banyak mengutip Peraturan Menteri Kesehatan Republik Indonesia No. 173/Men.Kes/Per/VII/1977, penyediaan air harus memenuhi kuantitas dan kualitas, yaitu:
- Aman dan higienis.
- Baik dan layak minum.
- Tersedia dalam jumlah yang cukup
- Harganya relatif murah atau terjangkau oleh sebagian besar masyarakat
Parameter yang ada digunakan untuk metode dalam proses perlakuan, operasi dan biaya. Parameter air yang penting ialah parameter fisik, kimia, biologis dan radiologis yaitu sebagai berikut:
Parameter Air Bersih secara Fisika :
- Kekeruhan
- Warna
- Rasa & bau
- Endapan
- Temperatur
Parameter Air Bersih secara Kimia :
- Organik, antara lain: karbohidrat, minyak/ lemak/ gemuk, pestisida, fenol, protein, deterjen, dll.
- Anorganik, antara lain: kesadahan, klorida, logam berat, nitrogen, pH, fosfor,belerang, bahan-bahan beracun.
- Gas-gas, antara lain: hidrogen sulfida, metan, oksigen.
Parameter Air Bersih secara Biologi :
- Bakteri
- Binatang
- Tumbuh-tumbuhan
- Protista
- Virus
Parameter Air Bersih secara Radiologi :
- Konduktivitas atau daya hantar
- Pesistivitas
- PTT atau TDS (Kemampuan air bersih untuk menghantarkan arus listrik)
Dengan standar tersebut maka air konsumsi yang kita gunakan akan aman bagi kesehatan kita, karena itu jadilah manusia yang selektif demi kesehatan dan juga keberlangsungan kita.
- Unsur kimiawi apa saja yang terdapat pada air sehingga dapat dijadikan faktor penentu bahwa air tersebut layak di konsumsi ?
- Bagaimana cara menerapkan model machine learning untuk memprediksi suatu kadar kimiawi pada air ?
- Memahami unsur kimiawi yang terdapat dalam air sehingga dapat dijadikan parameter kualitas air tersebut layak atau tidak untuk di konsumsi oleh manusia
- Mengimplementasikan model machine learning sederhana dengan jenis klasifikasi untuk memprediksi sebuah air dapat di konsumsi atau tidak menurut parameter kimiawi yang terdapat di dataset
- Untuk memahami unsur kimiawi yang terdapat pada air sebagai penentu kualitas air, maka dilakukan beberapa langkah berikut seperti :
- Penerapan EDA (Exploratory Data Analysis) yang berupa visualisasi diagram sehingga kita dapat memahami unsur kimiawi berdasarkan value yang terdapat pada dataset
- Pengecekan Korelasi Feature, Korelasi adalah cara untuk menentukan apakah dua variabel dalam kumpulan data terkait dengan cara apa pun. Korelasi memiliki banyak penerapan di dunia nyata. Kita dapat melihat apakah menggunakan istilah pencarian tertentu berkorelasi dengan penayangan di youtube. Atau, kita dapat melihat apakah iklan berkorelasi dengan penjualan. Saat membuat model pembelajaran mesin, korelasi merupakan faktor penting dalam menentukan fitur. Ini tidak hanya dapat membantu kami untuk melihat fitur mana yang terkait linier, tetapi jika fitur berkorelasi kuat, kami dapat menghapusnya untuk mencegah duplikasi informasi. Dalam ilmu data kita dapat menggunakan nilai r yang disebut juga koefisien korelasi Pearson. Ini mengukur seberapa dekat dua urutan angka (yaitu, kolom, daftar, seri, dll.) Berkorelasi. Nilai r adalah angka antara -1 dan 1. Ini memberitahu kita apakah dua kolom berkorelasi positif, tidak berkorelasi, atau berkorelasi negatif. Semakin mendekati 1, semakin kuat korelasi positifnya. Semakin dekat ke -1, semakin kuat korelasi negatifnya (yaitu, semakin "berlawanan" kolomnya). Semakin dekat ke 0, semakin lemah korelasinya.
- Penerapan Standarisasi pada Feature, Standardisasi mengubah fitur sedemikian rupa sehingga rata-rata (μ) sama dengan 0 dan deviasi standar (σ) sama dengan 1. Kisaran nilai min dan maks baru ditentukan oleh deviasi standar fitur awal yang tidak dinormalisasi.
- Untuk Machine Learning Model yang digunakan dalam kasus ini, umumnya penulis akan menggunakan semua jenis model machine learning bertipe klasifikasi untuk mengukur estimasi terbaik dalam memprediksi kualitas air untuk diminum, berikut machine learning model yang digunakan :
-
Logistic Regression, Regresi logistik, dalam statistika digunakan untuk prediksi probabilitas kejadian suatu peristiwa dengan mencocokkan data pada fungsi logit kurva logistik. Metode ini merupakan model linier umum yang digunakan untuk regresi binomial.
-
Decision Tree Classifier, Pembelajaran pohon keputusan atau induksi pohon keputusan adalah salah satu pendekatan pemodelan prediktif yang digunakan dalam statistik, penambangan data, dan pembelajaran mesin. Ini menggunakan pohon keputusan untuk beralih dari pengamatan tentang suatu item ke kesimpulan tentang nilai target item tersebut.
-
Random Forest Classifiers, Random forest adalah suatu algoritma yang digunakan pada klasifikasi data dalam jumlah yang besar. Klasifikasi random forest dilakukan melalui penggabungan pohon dengan melakukan training pada sampel data yang dimiliki.
-
Xgboost, XGBoost adalah singkatan dari "Extreme Gradient Boosting", di mana istilah "Gradient Boosting" berasal dari makalah Greedy Function Approximation: A Gradient Boosting Machine, oleh Friedman. Pohon yang didorong gradien telah ada untuk sementara waktu, dan ada banyak materi tentang topik ini. Tutorial ini akan menjelaskan pohon yang didorong secara mandiri dan berprinsip menggunakan elemen pembelajaran yang diawasi. Kami pikir penjelasan ini lebih bersih, lebih formal, dan memotivasi formulasi model yang digunakan di XGBoost. XGBoost digunakan untuk masalah pembelajaran yang diawasi, di mana kami menggunakan data pelatihan (dengan banyak fitur) untuk memprediksi variabel target . Sebelum kita mempelajari tentang pohon secara khusus, mari kita mulai dengan meninjau elemen dasar dalam pembelajaran terawasi.
Untuk mempermudah pendefinisian langkah-langkah yang diperlukan dalam penelitian kali ini, penulis membuat visualisasi diagram tentang alur kerja secara keseluruhan.
Dataset yang penulis gunakan dalam penelitian ini diambil dari sumber terbuka kaggle, berikut link nya : water potability
Konteks
Akses ke air minum yang aman sangat penting untuk kesehatan, hak asasi manusia dan komponen kebijakan yang efektif untuk perlindungan kesehatan. Hal ini penting sebagai masalah kesehatan dan pembangunan di tingkat nasional, regional dan lokal. Di beberapa daerah, telah terbukti bahwa investasi dalam penyediaan air dan sanitasi dapat menghasilkan keuntungan ekonomi bersih, karena pengurangan efek kesehatan yang merugikan dan biaya perawatan kesehatan lebih besar daripada biaya melakukan intervensi.
Konten
File water_potability.csv berisi metrik kualitas air untuk 3276 badan air yang berbeda.
- pH Value, PH merupakan parameter penting dalam mengevaluasi keseimbangan asam-basa air. Ini juga merupakan indikator kondisi asam atau basa status air. WHO telah merekomendasikan batas maksimum pH yang diizinkan dari 6,5 hingga 8,5. Rentang investigasi saat ini adalah 6,52-6,83 yang berada dalam kisaran standar WHO.
- Hardness, Kekerasan terutama disebabkan oleh garam kalsium dan magnesium. Garam-garam ini larut dari endapan geologis yang dilalui air. Lamanya waktu kontak air dengan bahan penghasil kesadahan membantu menentukan berapa banyak kesadahan yang ada dalam air baku. Kekerasan awalnya didefinisikan sebagai kapasitas air untuk mengendapkan sabun yang disebabkan oleh Kalsium dan Magnesium.
- Solids (Total dissolved solids - TDS), Air memiliki kemampuan untuk melarutkan berbagai mineral atau garam anorganik dan organik seperti kalium, kalsium, natrium, bikarbonat, klorida, magnesium, sulfat, dll. Mineral ini menghasilkan rasa yang tidak diinginkan dan warna yang encer dalam penampilan air. Ini adalah parameter penting untuk penggunaan air. Air dengan nilai TDS yang tinggi menunjukkan bahwa air tersebut sangat termineralisasi. Batas yang diinginkan untuk TDS adalah 500 mg/l dan batas maksimum adalah 1000 mg/l yang ditentukan untuk tujuan minum.
- Chloramines, Klorin dan kloramin adalah disinfektan utama yang digunakan dalam sistem air publik. Kloramin paling sering terbentuk ketika amonia ditambahkan ke klorin untuk mengolah air minum. Kadar klorin hingga 4 miligram per liter (mg/L atau 4 bagian per juta (ppm)) dianggap aman dalam air minum.
- Sulfate, Sulfat adalah zat alami yang ditemukan di mineral, tanah, dan batuan. Mereka hadir di udara ambien, air tanah, tanaman, dan makanan. Penggunaan komersial utama sulfat adalah dalam industri kimia. Konsentrasi sulfat dalam air laut adalah sekitar 2.700 miligram per liter (mg/L). Ini berkisar antara 3 sampai 30 mg/L di sebagian besar persediaan air tawar, meskipun konsentrasi yang jauh lebih tinggi (1000 mg/L) ditemukan di beberapa lokasi geografis.
- Conductivity, Air murni bukanlah penghantar arus listrik yang baik, melainkan isolator yang baik. Peningkatan konsentrasi ion meningkatkan konduktivitas listrik air. Umumnya, jumlah padatan terlarut dalam air menentukan konduktivitas listrik. Konduktivitas listrik (EC) sebenarnya mengukur proses ionik dari suatu larutan yang memungkinkannya untuk mentransmisikan arus. Menurut standar WHO, nilai EC tidak boleh melebihi 400 S/cm.
- Organic Carbon, Total Organic Carbon (TOC) di perairan sumber berasal dari bahan organik alami (NOM) yang membusuk serta sumber sintetis. TOC adalah ukuran jumlah total karbon dalam senyawa organik dalam air murni. Menurut US EPA < 2 mg/L sebagai TOC pada air olahan/minum, dan < 4 mg/Lit pada sumber air yang digunakan untuk pengolahan.
- Trihalomethanes, THM adalah bahan kimia yang dapat ditemukan dalam air yang diolah dengan klorin. Konsentrasi THM dalam air minum bervariasi sesuai dengan tingkat bahan organik di dalam air, jumlah klorin yang dibutuhkan untuk mengolah air, dan suhu air yang diolah. Kadar THM hingga 80 ppm dianggap aman dalam air minum.
- Turbidity, Kekeruhan air tergantung pada jumlah zat padat yang ada dalam keadaan tersuspensi. Ini adalah ukuran sifat pemancar cahaya air dan tes ini digunakan untuk menunjukkan kualitas pembuangan limbah sehubungan dengan materi koloid. Nilai rata-rata kekeruhan yang diperoleh untuk Kampus Wondo Genet (0,98 NTU) lebih rendah dari nilai rekomendasi WHO sebesar 5,00 NTU.
- Potability, Menunjukkan apakah air aman untuk dikonsumsi manusia di mana 1 berarti Dapat diminum dan 0 berarti Tidak dapat diminum.
- Check Ratio Target
Gambar diatas merupakan visualisasi ratio target 1 & 0, dengan persentase seperti yang tertera di gambar. Ratio dari kedua target tersebut tidak 1:1 sehingga dapat terjadi bias pada proses predictive modeling kedepannya, serta dikarenakan dataset yang digunakan berjenis tabular maka penulis akan mengimplementasikan model imputasi sehingga ratio kedua target bernilai 1:1. Hal ini merupakan langkah yang tidak dapat diduga pada saat pendefinisian alur kerja diagram dikarenakan penulis pada permulaan fokus pada pengetahuan pada bidang terkait, permasalah, target, dan solusi.
- Visualisasi Outliers
Outlier adalah pengamatan terhadap data yang tidak sesuai dengan data lainnya. Kadang-kadang disebut nilai ekstrim. Saat Anda membuat grafik outlier, itu akan tampak tidak sesuai dengan pola grafik. Beberapa outlier disebabkan oleh kesalahan (misalnya, menuliskan 50 bukannya 500) sementara yang lain mungkin menunjukkan bahwa sesuatu yang tidak biasa sedang terjadi.
- Visualisasi Distribusi Data
Plot kepadatan adalah representasi dari distribusi variabel numerik. Ini menggunakan estimasi kepadatan kernel untuk menunjukkan fungsi kepadatan probabilitas variabel (lihat lebih lanjut). Ini adalah versi histogram yang dihaluskan dan digunakan dalam konsep yang sama.
- Visualisasi Pairplot ( Gabungan dari Grafik Skew & Scatter )
Pair Plots adalah cara yang sangat sederhana (satu baris kode sederhana!) untuk memvisualisasikan hubungan antara setiap variabel. Ini menghasilkan matriks hubungan antara setiap variabel dalam data Anda untuk pemeriksaan instan data kami. Ini juga bisa menjadi titik awal yang bagus untuk menentukan jenis analisis regresi yang akan digunakan.
- Simpulan Dari Visualisasi Dari visualisasi outliers, distribusi, dan pairplot ( gabungan dari scatter plot & skew plot) menunjukkan feature-feature pada dataset yang dibagi menjadi 2 domain yaitu 1 & 0 memiliki korelasi yang rendah.
- Check Missing Values dan Imputasi
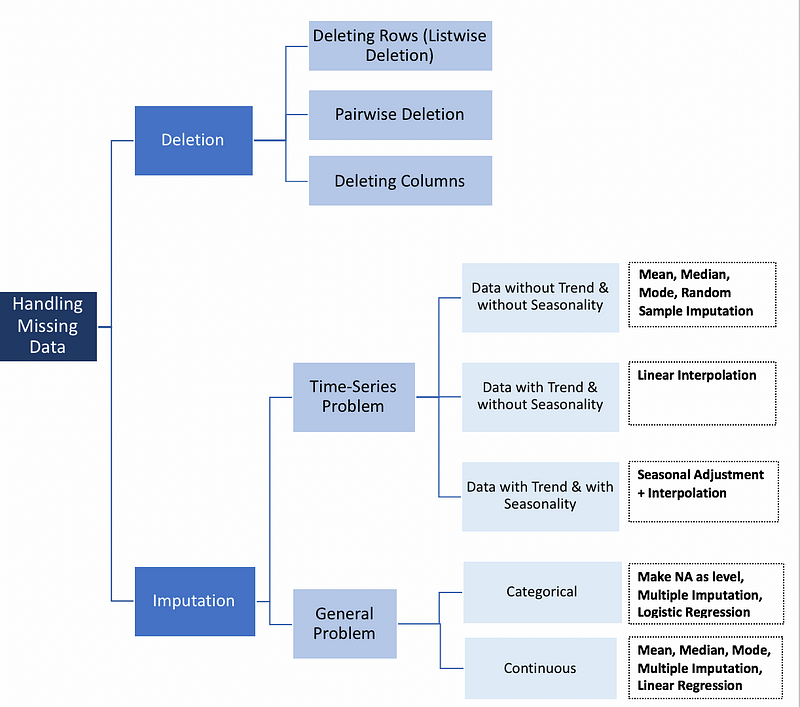
Berdasarkan pemetaan metode yang dapat digunakan dalam dataset pada gambar diatas, penulis memilih metode imputasi dengan feature statistik dikarenakan metode tersebut mudah digunakan, tujuan dari pengisian missing value adalah untuk mengurangi potensi bias atau miss-representasi pada dataset sehingga model dapat memprediksi secara optimal.
- Standarisasi Data
Standarisasi adalah menghilangkan mean (terpusat pada 0) dan menskalakan ke variansi (deviasi standar = 1), dengan asumsi data terdistribusi normal (gauss) untuk semua fitur. Perlu menskalakan kolom-kolom yang dibutuhkan. Perbedaan skala dapat menyebabkan kendala dengan estimator euclidean distance.
- Train Test Split
Train test split adalah salah satu metode yang dapat digunakan untuk mengevaluasi performa model machine learning. Metode evaluasi model ini membagi dataset menjadi dua bagian yakni bagian yang digunakan untuk training data dan untuk testing data dengan proporsi tertentu. Pada penelitian kali ini penulis menggunakan ratio 80:20, 80% untuk training set dan 20% untuk testing set.
Pada penelitian kualitas air berdasarkan unsur kimiawi, penulis melakukan 2 percobaan dengan perbedaan terletak pada missing value yang diisi dengan 0 dan missing value yang diisi dengan nilai mode. Model prediktif terbukti cukup membantu dalam memprediksi pertumbuhan bisnis di masa depan, karena memprediksi hasil menggunakan penambangan data dan probabilitas, di mana setiap model terdiri dari sejumlah prediktor atau variabel. Oleh karena itu, model statistik dapat dibuat dengan mengumpulkan data untuk variabel yang relevan. Dengan acuan performa yang dianalisis pada penelitan kali ini sebatas di metriks 2 akurasi tertinggi pada setiap percobaan :
- percobaan pertama pengimplementasian angka 0 pada missing values
| Model | Accuracy | |
|---|---|---|
| 0 | Logistic Regression | 0.640244 |
| 1 | Decision Tree | 0.586890 |
| 2 | Random Forest | 0.653963 |
| 3 | Xgboost | 0.635671 |
- percobaan kedua pengimplementasian nilai statistical - mode pada missing values
| Model | Accuracy | |
|---|---|---|
| 0 | Logistic Regression | 0.614329 |
| 1 | Decision Tree | 0.591463 |
| 2 | Random Forest | 0.666159 |
| 3 | Xgboost | 0.661585 |
Metriks yang digunakan pada penelitian ini adalah metriks akurasi, berikut deskripsi tentang metriks akurasi Akurasi adalah salah satu metrik untuk mengevaluasi model klasifikasi. Secara informal, akurasi adalah sebagian kecil dari prediksi model kami yang benar. Secara formal, akurasi memiliki definisi sebagai berikut:
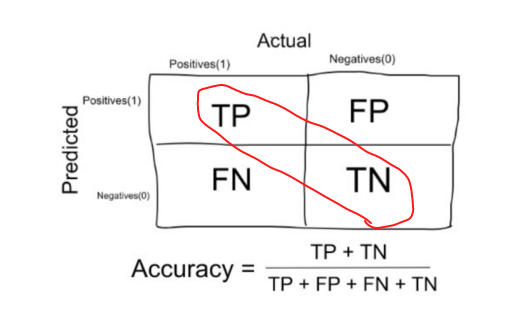
Dengan Deskripsi,
- TP = True Positives
- TN = True Negatives
- FP = False Positives
- FN = False Negatives.
- Hasil Perbandingan akhir dari 2 percobaan sebelumnya
| Condition | Random Forest | Xgboost | |
|---|---|---|---|
| 0 | Before Implement Statistical Feature | 0.653963 | 0.635671 |
| 1 | After Implement Statistical Feature | 0.666159 | 0.661585 |
Conclusion
Berdasarkan hasil yang telah dicapai model machine learning yang memiliki akurasi terbaik jatuh kepada model random forest & xgboost, kedua model tersebut menurut penulis cukup baik performanya apabila dibandingkan dengan model logistic atau decision tree dikarenakan random forest dan xgboost menerapkan boosting algorithm atau improvisasi dari model dasar sehingga keduanya memiliki akurasi yang lebih tinggi. Model random forest pada dasarnya sangat membutuhkan feature-feature data yang bervariasi sehingga setiap akar dari algoritma random forest dapat menganalisa semua feature dan setiap feature mendapatkan hasil prediksi yang optimal. Model Xgboost merupakan model machine learning terapan yang menerapkan implementasi boosting sehingga akurasi yang dicapai dapat optimal dari model machine learning dasar.
Terlepas dari hasil akurasi model machine learning, penulis juga mendapatkan beberapa informasi yang dapat diasumsikan ke dalam hasil akurasi yakni korelasi setiap feature rendah, hal tersebut dapat dilihat pada 2 visualiasi korelasi matrix dimana setiap feature memiliki korelasi sekitar angka 0, kemudian ada ratio data yang tidak 1:1 sehingga model memiliki kemungkinan memprediksi hasil yang kurang tepat / bias.
Future Work
Berikut beberapa asumsi metode yang dapat diimplementasikan pada pengembangan model machine learning selanjutnya terkait memprediksi kelayakan suatu air untuk di konsumsi berkaitan dengan unsur kimiawi.
- Pengimplementasian Imputasi Data
- Penerapan Parameter Tuning
- Merancang Kombinasi Model Statistik dengan Boosting Algorithm
- https://dsdap.bantenprov.go.id/upload/Advetorial/1.%202%20ARTIKEL%20AIR%20BERSIH%20(RDA)_EDITOR.pdf
- https://ichi.pro/id/korelasi-sederhana-dengan-seaborn-dan-panda-44816080728094
- https://ichi.pro/id/penskalaan-fitur-dalam-machine-learning-36136038374347
- https://id.wikipedia.org/wiki/Regresi_logistik
- https://en.wikipedia.org/wiki/Decision_tree_learning
- https://id.wikipedia.org/wiki/Random_forest
- https://qastack.id/datascience/16904/gbm-vs-xgboost-key-differences
- https://xgboost.readthedocs.io/en/latest/tutorials/model.html
- https://www.ibm.com/cloud/learn/exploratory-data-analysis
- https://www.analyticsvidhya.com/blog/2021/06/how-to-load-kaggle-datasets-directly-into-google-colab/
- https://courses.lumenlearning.com/introstats1/chapter/outliers/
- https://analyticsindiamag.com/what-is-predictive-model-performance-evaluation-and-why-is-it-important/
- https://dqlab.id/kursus-belajar-data-mengenal-apa-itu-missing-value
- https://mragungsetiaji.github.io/python/machine%20learning/2018/08/23/machine-learning-missing-value.html