一种 FAQ 向量语义检索解决方案
-
基于 Sklearn Kmeans 聚类的负采样
-
基于 Transformers 的 BertForSiameseNetwork(Bert双塔模型)微调训练
-
基于 TextBrewer 的模型蒸馏
FAQ 的处理流程一般为:
- 问题理解,对用户 query 进行改写以及向量表示
- 召回模块,在问题集上进行候选问题召回,获得 topk(基于关键字的倒排索引 vs 基于向量的语义召回)
- 排序模块,对 topk 进行精排序
本项目着眼于 召回模块 的 向量检索 的实现,适用于 小规模 FAQ 问题集(候选问题集<10万)的系统快速搭建
传统召回模块基于关键字检索
- 计算关键字在问题集中的 TF-IDF 以及 BM25 得分,并建立倒排索引表
- 第三方库 ElasticSearch,Lucene,Whoosh
随着语义表示模型的增强、预训练模型的发展,基于 BERT 向量的语义检索得到广泛应用
- 对候选问题集合进行向量编码,得到 corpus 向量矩阵
- 当用户输入 query 时,同样进行编码得到 query 向量表示
- 然后进行语义检索(矩阵操作,KNN,FAISS)
本项目针对小规模 FAQ 问题集直接计算 query 和 corpus 向量矩阵的余弦相似度,从而获得 topk 候选问题 $$ score = \frac{V_{query} \cdot V_{corpus}}{||V_{query}|| \cdot ||V_{corpus}||} $$ 句向量获取解决方案
| Python Lib | Framework | Desc | Example |
|---|---|---|---|
| bert-as-serivce | TensorFlow | 高并发服务调用,支持 fine-tune,较难拓展其他模型 | getting-started |
| Sentence-Transformers | PyTorch | 接口简单易用,支持各种模型调用,支持 fine-turn(单GPU) | using-Sentence-Transformers-model using-Transformers-model |
| 🤗 Transformers | PyTorch | 自定义程度高,支持各种模型调用,支持 fine-turn(多GPU) | sentence-embeddings-with-Transformers |
- Sentence-Transformers 进行小规模数据的单 GPU fine-tune 实验(尚不支持多 GPU 训练,Multi-GPU-training #311 ;实现了多种 Ranking loss 可供参考)
- Transformers 进行大规模数据的多 GPU fine-tune 训练(推荐自定义模型使用 Trainer 进行训练)
- 实际使用过程中 Sentence-Transformers 和 Transformers 模型基本互通互用,前者多了 Pooling 层(Mean/Max/CLS Pooling) ,可参考 Example
- 🔥 实际上线推荐直接使用 Transformers 封装,Sentence-Transformers 在 CPU 服务器上运行存在位置问题。
在句向量获取中可以直接使用 bert-base-chinese 作为编码器,但在特定领域数据上可能需要进一步 fine-tune 来获取更好的效果
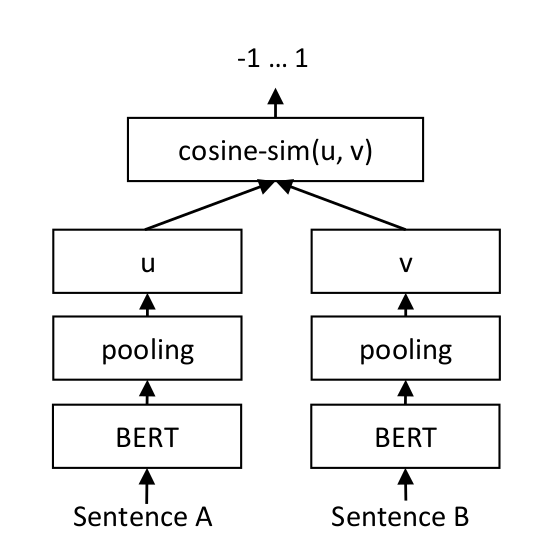
fine-tune 过程主要进行文本相似度计算任务,亦句对分类任务;此处是为获得更好的句向量,因此使用**双塔模型(SiameseNetwork ,孪生网络)**微调,而非常用的基于表示的模型 BertForSequenceClassification
BertForSiameseNetwork 主要步骤如下
- Encoding,使用(同一个) BERT 分别对 query 和 candidate 进行编码
- Pooling,对最后一层进行池化操作获得句子表示(Mean/Max/CLS Pooling)
- Computing,计算两个向量的余弦相似度(或其他度量函数),计算 loss 进行反向传播
模型训练使用的损失函数为 Ranking loss,不同于CrossEntropy 和 MSE 进行分类和回归任务,Ranking loss 目的是预测输入样本对(即上述双塔模型中
-
Contrastive Loss
来自 LeCun Dimensionality Reduction by Learning an Invariant Mapping
-
公式形式如下,其中
$u, v$ 为 BERT 编码的向量表示,$y$ 为对应的标签(1 表示正样本,0 表示负样本),$\tau$ 为超参数 $$ L(u_i, v_i, y_i) = y_i ||u_i, v_i|| + (1 - y_i) \max(0, \tau - ||u_i, v_i|| $$ -
公式意义为:对于正样本,输出特征向量之间距离要尽量小;而对于负样本,输出特征向量间距离要尽量大;但是若负样本间距太大(即容易区分的简单负样本,间距大于
$\tau$ )则不处理,让模型关注更加难以区分的样本
-
-
OnlineContrastive Loss
-
属于 online negative sampling ,与 Contrastive Loss 类似
-
参考 sentence-transformers 源码实现 ,在每个 batch 内,选择最难以区分的正例样本和负例样本进行 loss 计算(容易识别的正例和负例样本则忽略)
-
公式形式如下,如果正样本距离小于
$\tau_1$ 则不处理,如果负样本距离大于$\tau_0$ 则不处理,实现过程中$\tau_0, \tau_1$ 可以分别取负/正样本的平均距离值 $$ L(u_i, v_i, y_i) \begin{cases} \max (0, ||u_i, v_i|| - \tau_1) ,\ if \ y_i=1 & \ \max (0, \tau_0 - ||u_i, v_i||),\ if \ y_i =0 \end{cases} $$
-
本项目使用 OnlineContrastive Loss ,更多 Ranking loss 信息可参考博客 Understanding Ranking Loss, Contrastive Loss, Margin Loss, Triplet Loss, Hinge Loss and all those confusing names ,以及 SentenceTransformers 中的 Loss API 以及 PyTorch 中的 margin_ranking_loss
-
文本相似度数据集
-
FAQ数据集
-
内部给定的 FAQ 数据集形式如下,包括各种”主题/问题“,每种“主题/问题”可以有多种不同表达形式的问题
post,同时对应多种形式的回复resp -
检索时只需要将 query 与所有 post 进行相似度计算,从而召回最相似的 post ,然后获取对应的 “主题/问题” 的所有回复
resp,最后随机返回一个回复即可{ "晚安": { "post": [ "10点了,我要睡觉了", "唉,该休息了", ... ], "resp": [ "祝你做个好梦", "祝你有个好梦,晚安!", ... ] }, "感谢": { "post": [ "多谢了", "非常感谢", ... ], "resp": [ "助人为乐为快乐之本", "别客气", ... ] }, ... } -
内部FAQ数据包括两个版本
- chitchat-faq-small,主要是小规模闲聊FAQ,1500主题问题(topic)、2万多不同形式问题(post)
- entity-faq-large,主要是大规模实体FAQ(涉及业务问题),大约3-5千主题问题(topic)、12万不同形式问题(post)
-
对于每个 query,需要获得与其相似的 positve candidate 以及不相似的 negtive candidate,从而构成正样本和负样本作为模型输入,即 (query, candidate)
⚠️ 此处为 offline negtive sampling,即在训练前采样构造负样本,区别于 online negtive sampling,后者在训练中的每个 batch 内进行动态的负采样(可以通过相关损失函数实现,如 OnlineContrastive Loss)两种方法可以根据任务特性进行选择,online negtive sampling 对于数据集有一定的要求,需要确保每个 batch 内的 query 是不相似的,但是效率更高
对于 offline negtive sampling 主要使用以下两种方式采样:
- 全局负采样
- 在整个数据集上进行正态分布采样,很难产生高难度的负样本
- 局部负采样
- 首先使用少量人工标注数据预训练的 BERT 模型对候选问题集合进行编码
- 然后使用无监督聚类 ,如 Kmeans
- 最后在每个 query 所在聚类簇中进行采样
实验中对已有 FAQ 数据集中所有主题的 post 进行 9:1 划分得到训练集和测试集,负采样结果对比
chitchat-faq-small为需要上线的 FAQ 闲聊数据,entity-faq-large为辅助数据
| dataset | topics | posts | positive(sampling) | negative(sampling) | total(sampling) |
|---|---|---|---|---|---|
| chitchat-faq-small train |
1468 | 18267 | 5w+ | 5w+ | 10w+ |
| chitchat-faq-small test |
768 | 2030 | 2984 | 7148 | 10132 |
| chitchat-faq-small | 1500 | 20297 | - | - | - |
| entity-faq-large | - | 12w+ | 50w+ | 50w+ | 100w+ |
使用基于 Transformers 的模型蒸馏工具 TextBrewer ,主要参考 官方 入门示例 和cmrc2018示例
- Web 框架选择
- cache 缓存机制(保存最近的query对应的topic,命中后直接返回)
- Flask 相关
- flask-caching (默认缓存500,超时300秒),使用 set/get 进行数据操作;项目来源于 pallets/werkzeug (werkzeug 版本0.4以后弃用 cache)
- Python 3.2 以上自带(FastAPI 中可使用)
- 🔥 functools.lru_cache() (默认缓存128,lru策略),装饰器,缓存函数输入和输出
- Flask 相关
使用 Locust 编写压力测试脚本
主要依赖参考 requirements.txt
pip install -r requirements.txtpython sampling.py \
--filename='faq/train_faq.json' \
--model_name_or_path='./model/bert-base-chinese' \
--is_transformers=True \
--hyper_beta=2 \
--num_pos=5 \
--local_num_negs=3 \
--global_num_negs=2 \
--output_dir='./samples'主要参数说明
--filename,faq 数据集,按前文所述组织为{topic: {post:[], resp:[]}}格式--model_name_or_path,用于句向量编码的 Transformers 预训练模型位置(bert-base-chinese或者基于人工标注数据微调后的模型)--hyper_beta,聚类数超参数,聚类类别为n_cluster=num_topics/hyper_beta,其中num_topics为上述数据中的主题数,hyper_beta默认为 2(过小可能无法采样到足够局部负样本)--num_pos,正采样个数,默认 5(注意正负比例应为 1:1)--local_num_negs,局部负采样个数,默认 3(该值太大时,可能没有那么多局部负样本,需要适当调低正采样个数,保证正负比例为 1:1)--global_num_negs,全局负采样个数,默认 2--is_split,是否进行训练集拆分,默认 False(建议直接在 faq 数据上进行拆分,然后使用评估语义召回效果)--test_size,测试集比例,默认 0.1--output_dir,采样结果文件保存位置(sentence1, sentence2, label形式的 csv 文件)
-
参考 Sentence-Transformers 的 raining_OnlineConstrativeLoss.py 修改,适合单 GPU 小规模样本训练
-
模型训练
CUDA_VISIBLE_DEVICES=0 python sentence_transformers_train.py \ --do_train \ --model_name_or_path='./model/bert-base-chinese' \ --trainset_path='./lcqmc/LCQMC_train.csv' \ --devset_path='./lcqmc/LCQMC_dev.csv' \ --testset_path='./lcqmc/LCQMC_test.csv' \ --train_batch_size=128 \ --eval_batch_size=128 \ --model_save_path
-
主要参数说明
- 模型预测时则使用
--do_eval - 数据集为
sentence1, sentence2, label形式的 csv 文件 - 16G 显存设置 batch size 为 128
- 模型预测时则使用
-
-
使用 Transformers 自定义数据集和
BertForSiameseNetwork模型并使用 Trainer 训练,适合多 GPU 大规模样本训练CUDA_VISIBLE_DEVICES=0,1,2,3 python transformers_trainer.py \ --do_train=True \ --do_eval=True \ --do_predict=False \ --model_name_or_path='./model/bert-base-chinese' \ --trainset_path='./samples/merge.csv' \ --devset_path='./samples/test.csv' \ --testset_path='./samples/test.csv' \ --output_dir='./output/transformers-merge-bert'
-
使用 Transformers 的
BertForSequenceClassification进行句对分类对比实验CUDA_VISIBLE_DEVICES=0 python bert_for_seq_classification.py \ --do_train=True \ --do_eval=True \ --do_predict=False \ --trainset_path='./lcqmc/LCQMC_train.csv' \ --devset_path='./lcqmc/LCQMC_dev.csv' \ --testset_path='./lcqmc/LCQMC_test.csv' \ --output_dir='./output/transformers-bert-for-seq-classify'
使用 TextBrewer 以及前文自定义的 SiameseNetwork 进行模型蒸馏
CUDA_VISIBLE_DEVICES=0 python model_distillation.py \
--teacher_model='./output/transformers-merge-bert' \
--student_config='./distills/bert_config_L3.json' \
--bert_model='./model/bert-base-chinese' \
--train_file='./samples/train.csv' \
--test_file='./samples/test.csv' \
--output_dir='./distills/outputs/bert-L3'主要参数说明:
- 此处使用的
bert_config_L3.json作为学生模型参数,更多参数 student_config 或者自定义 - 3层应用于特定任务效果不错,但对于句向量获取,至少得蒸馏 6层
- 学生模型可以使用
bert-base-chinese的前几层初始化
-
服务启动(
gunicorn和uvicorn均支持多进程启动以及失败重启) -
压力测试 Locust ,实现脚本参考
locust_test.py
对于SiameseNetwork,需要在开发集上确定最佳阈值,然后测试集上使用该阈值进行句对相似度结果评价
句对测试集评价结果,此处为 LCQMC 的实验结果
| model | acc(dev/test) | f1(dev/test) |
|---|---|---|
| BertForSeqClassify 🚂 lcqmc |
0.8832/0.8600 | 0.8848/0.8706 |
| SiameseNetwork 🚂 lcqmc |
0.8818/0.8705 | 0.8810/0.8701 |
基于表示和基于交互的模型效果差别并不大
此处为 FAQ 数据集的召回结果评估,将训练集 post 作为 corpus,测试集 post 作为 query 进行相似度计算
| model | hit@1(chitchat-faq-small) | hit@1(entity-faq-large) |
|---|---|---|
| lucene bm25 (origin) | 0.6679 | - |
| bert-base-chinese | 0.7394 | 0.7745 |
| bert-base-chinese 👆 6 layers |
0.7276 | - |
| SiameseNetwork 🚂 chit-faq-small |
0.8567 | 0.8500 |
| SiameseNetwork 🚂 chitchat-faq-small + entity-faq-large |
0.8980 | 0.9961 |
| 👆 6 layers 🔥 | 0.9128 | 0.8201 |
- chitchat-faq-small
- 测试集 hit@1 大约 85% 左右
- 错误原因主要是 hflqa 数据问题
- 数据质量问题,部分 topic 意思相同,可以合并
- 一些不常用表达或者表达不完整的句子
- 正常对话的召回率还是不错的
- chitchat-faq-small + entity-faq-large
- 2000 chitchat-faq-small 测试集,6层比12层效果好一个点,hit@1 达到 90%
- 10000 entity-faq-large 测试集,12层 hit@1 达到 99%,6层只有 82%
- 底层学到了较为基础的特征,在偏向闲聊的 chitchat-faq-small 上仅使用6层效果超过12层(没有蒸馏必要)
- 高层学到了较为高级的特征,在偏向实体的 entity-faq-large 上12层效果远超于6层
- 另外,entity-faq-large 数量规模远大于 chitchat-faq-small ,因此最后几层分类器偏向于从 entity-faq-large 学到的信息,因此在 chitchat-faq-small 小效果略有下降;同时能够避免 chitchat-faq-small 数据过拟合
-
运行命令说明
总共 100 个模拟用户,启动时每秒递增 10 个,压力测试持续 3 分钟
locust -f locust_test.py --host=http://127.0.0.1:8889/module --headless -u 100 -r 10 -t 3m
-
⌛ 配置 4核8G CPU (6层小模型占用内存约 700MB)
- 小服务器上 bert-as-service 服务非常不稳定(tensorflow各种报错), 效率不如简单封装的 TransformersEncoder
- FastAPI 框架速度远胜于 Flask,的确堪称最快的 Python Web 框架
- cache 的使用能够大大提高并发量和响应速度(最大缓存均设置为500)
- 最终推荐配置 🔥 TransformersEncoder + FastAPI + functools.lru_cache
| model | Web | Cache | Users | req/s | reqs | fails | Avg | Min | Max | Median | fails/s |
|---|---|---|---|---|---|---|---|---|---|---|---|
| lucene bm25 (origin) | flask | werkzeug | 1000 | 271.75 | 48969 | 0 | 91 | 3 | 398 | 79 | 0.00 |
| BertSiameseNet 6 layers Transformers |
flask | flask-caching | 1000 | 24.55 | 4424 | 654 | 28005 | 680 | 161199 | 11000 | 3.63 |
| BertSiameseNet 6 layers Transformers |
fastapi | lru_cache | 1000 | 130.87 | 23566 | 1725 | 3884 | 6 | 127347 | 26 | 9.58 |
| lucene bm25 (origin) | flask | werkzeug | 100 | 27.66 | 4973 | 1 | 32 | 6 | 60077 | 10 | 0.01 |
| BertSiameseNet 6 layers bert-as-service |
flask | flask-caching | 100 | 5.49 | 987 | 0 | 13730 | 357 | 17884 | 14000 | 0.00 |
| BertSiameseNet 6 layers Transformers |
flask | flask-caching | 100 | 5.93 | 1066 | 0 | 12379 | 236 | 17062 | 12000 | 0.00 |
| BertSiameseNet 🔥 6 layers Transformers |
fastapi | lru_cache | 100 | 22.19 | 3993 | 0 | 824 | 10 | 2402 | 880 | 0.00 |
| BertSiameseNet 6 layers transformers |
fastapi | None | 100 | 18.17 | 1900 | 0 | 1876 | 138 | 3469 | 1900 | 0.00 |
使用 bert-as-service 遇到的一些问题:
- 老版本服务器上使用 tensorflow 报错解决方案 Error in `python': double free or corruption (!prev) #6968
- 报错 src/tcmalloc.cc:277] Attempt to free invalid pointer 0x7f4685efcd40 Aborted (core dumpe),解决方案,将 bert_as_service import 移到顶部
测试服部署时报错 src/tcmalloc.cc:277] Attempt to free invalid pointer,通过改变import顺序来解决,在
numpy之后 import pytorch
- 大规模问题集可以使用 facebookresearch/faiss (建立向量索引,使用 k-nearest-neighbor 召回)
- 很多场景下,基于关键字的倒排索引召回结果已经足够,可以考虑综合基于关键字和基于向量的召回方法,参考知乎语义检索系统 Beyond Lexical: A Semantic Retrieval Framework for Textual SearchEngine