Extraer datos puede ser una tarea tediosa de por sí, y más aún cuando la información no se encuentra digitalizada. En este ejemplo, he querido usar el paquete Tesseract para tomar datos de una tabla impresa e importarlos al programa.
Para instalar Tesseract, ejecutamos el siguiente código:
install.packages('tesseract')
Luego, ejecutamos el paquete:
library(tesseract)
A continuación, buscamos la ruta de la imagen para importar los datos:
data <- ocr_data(\\ruta\\del\\archivo.jpg)
Los datos deben aparecer en la columna word de la tabla recién generada. Los datos creados son de tipo caracter. Para transformarlos en datos numéricos usamos la función as.numeric. Si estos vienen separados por comas, usamos la función gsub para reemplazarlas por puntos:
var_num <- as.numeric(gsub(",",".",data$word))
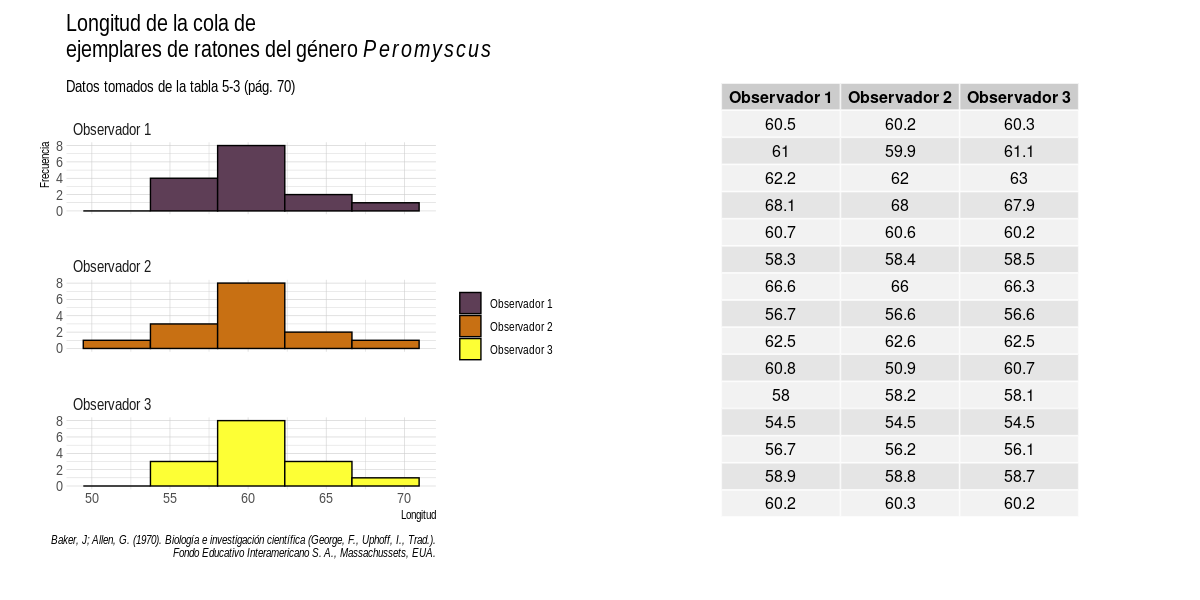
En el ejemplo, la tabla que estamos usando es la siguiente:
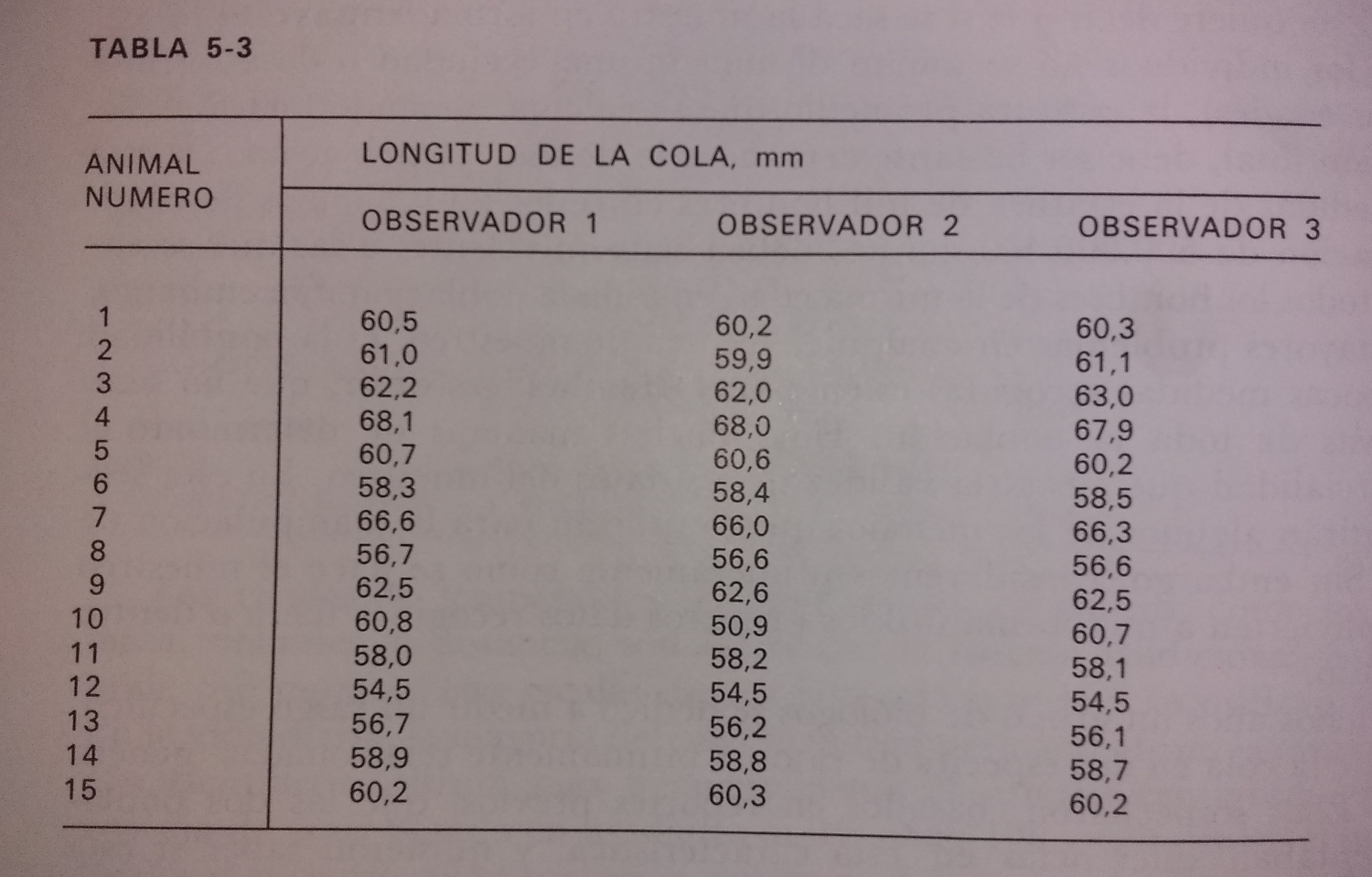
Al editarla, nos quedamos únicamente con los datos numéricos:

Finalmente, podemos importar los datos a un data frame e intentar hacer una gráfica de este tipo: